通过 show engine innodb status 命令, 导出相关的死锁日志出来查看。下面为截取出来的死锁日志,为了脱敏对库名和关键信息做了一些处理,不影响对死锁的分析。
------------------------
LATEST DETECTED DEADLOCK
------------------------
2022-10-31 16:22:00 0x7fb7780d5700
*** (1) TRANSACTION:
TRANSACTION 272174, ACTIVE 0 sec fetching rows
mysql tables in use 1, locked 1
LOCK WAIT 18 lock struct(s), heap size 1136, 58 row lock(s), undo log entries 41
MySQL thread id 298, OS thread handle 140425685493504, query id 5479767 172.18.70.114 root updating
delete from session where id in (x'B41D1ACB485A4E599A687E4AB1C36648' , x'8B2845485D584A3EB38B6D7143AF0979' , x'72A0BF611835464B9F1F13E3A7EE9923' , x'B626729F75AA42CEBA86C07880F9A3DA' , x'4567EC174BAD41A5A7B6587B7FDB6DFD' , x'DB71BC0D218A46678FE9B64ABBCE7212' , x'338A697F27EC4EFC832BBFC109D34505' , x'3B3DE6A8C48940239907F7D4FAFB5418' , x'CF06F6E7AFC247BC914242E7F7D93FE3')
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 132 page no 3 n bits 120 index PRIMARY of table `session` trx id 272174 lock_mode X waiting
Record lock, heap no 52 PHYSICAL RECORD: n_fields 57; compact format; info bits 0
0: len 16; hex 965b1face74948039ab0dd8da6daa71d; asc [ IH ;;
..... // 省略一些不重要的字段信息 *** (2) TRANSACTION:
TRANSACTION 272193, ACTIVE 0 sec inserting
mysql tables in use 1, locked 1
7 lock struct(s), heap size 1136, 3 row lock(s), undo log entries 4
MySQL thread id 300, OS thread handle 140425969882880, query id 5479930 172.18.70.114 root update
insert into session_endpoint (...) values (...)
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 132 page no 3 n bits 120 index PRIMARY of table `session` trx id 272193 lock_mode X locks rec but not gap
Record lock, heap no 52 PHYSICAL RECORD: n_fields 57; compact format; info bits 0
0: len 16; hex 965b1face74948039ab0dd8da6daa71d; asc [ IH ;;
... // 省略一些不重要的字段信息
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 136 page no 3 n bits 88 index PRIMARY of table `session_endpoint` trx id 272193 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 4 PHYSICAL RECORD: n_fields 63; compact format; info bits 32
0: len 16; hex 4230c997ef754048ba46c254ac88d8c2; asc B0 u@H F T ;;
... // 省略一些不重要的字段信息
15: len 16; hex 72a0bf611835464b9f1f13e3a7ee9923; asc r a 5FK
... // 省略一些不重要的字段信息
*** WE ROLL BACK TRANSACTION (2)
------------
TRANSACTIONS
------------
从这份日志中,我们捕捉到一些关键信息:
delete from session where id in (x'B41D1ACB485A4E599A687E4AB1C36648' , x'8B2845485D584A3EB38B6D7143AF0979' , x'72A0BF611835464B9F1F13E3A7EE9923' , x'B626729F75AA42CEBA86C07880F9A3DA' , x'4567EC174BAD41A5A7B6587B7FDB6DFD' , x'DB71BC0D218A46678FE9B64ABBCE7212' , x'338A697F27EC4EFC832BBFC109D34505' , x'3B3DE6A8C48940239907F7D4FAFB5418' , x'CF06F6E7AFC247BC914242E7F7D93FE3')
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 132 page no 3 n bits 120 index PRIMARY of table `session` trx id 272174 lock_mode X waiting
Record lock, heap no 52
PHYSICAL RECORD: n_fields 57; compact format; info bits 0
*** (2) TRANSACTION:
TRANSACTION 272193, ACTIVE 0 sec inserting
mysql tables in use 1, locked 1
7 lock struct(s), heap size 1136, 3 row lock(s), undo log entries 4
MySQL thread id 300, OS thread handle 140425969882880, query id 5479930 172.18.70.114 root update
insert into session_endpoint (...) values (...)
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 136 page no 3 n bits 88 index PRIMARY of table `session_endpoint` trx id 272193 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 4 PHYSICAL RECORD: n_fields 63; compact format; info bits 32
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 132 page no 3 n bits 120 index PRIMARY of table `session` trx id 272193 lock_mode X locks rec but not gap
Record lock, heap no 52 PHYSICAL RECORD: n_fields 57; compact format; info bits 0
另外,还可以得到一些其他的信息:
为方便说明,列出简化后的两个表的DDL如下
CREATE TABLE `session`( `id` binary(16) NOT NULL, `code` varchar(64) DEFAULT NULL, `topic` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `code_idx` (`code`)) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
CREATE TABLE `session_endpoint`( `id` binary(16) NOT NULL, `nickname` varchar(100) DEFAULT
NULL, `session_id` binary(16) DEFAULT NULL, PRIMARY KEY (`id`), KEY `session_id_idx` (`session_id`)) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
假设刚刚所说的先删session_endpoint记录,再插入一条session_endpoint的记录成立,那么它的处理流程是:

按理说,删除端点时,加的是记录锁,只会对删除的端点进行加锁,而插入端点时,会加插入意向锁,插入意向锁是INSERT过程中的一种特殊的间隙锁。虽然插入意向锁会和记录锁冲突,但是在这个例子中,事务1 加的记录锁,锁的是要被删除的记录,而插入意向锁锁的是即将要插入的间隙,这两个锁理论上是不冲突的。我们知道,MySQL在删除某一条记录的时候,并不是直接从页中删除,而是会把这条记录标记为已删除,已删除的记录仍然会保留在页中。所以,如果此时要插入的这条记录,刚好插入到已删除的记录上,那就会出现插入意向锁和记录锁冲突的情况了。
如何证明问题中的插入SQL刚好插入到已删除的记录上呢?可以从两个方面印证:
1)从事务2的等待锁的日志中可以看到:
RECORD LOCKS space id 136 page no 3 n bits 88 index PRIMARY of table `session_endpoint` trx id 272193 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 4 PHYSICAL RECORD: n_fields 63; compact format; info bits 32
事务2 在执行插入语句,但是要插入的位置,info bits 32 表示这条记录已经被标记为已删除。从MySQL 5.7 的源码中也可以知道,32是一个表示已删除的标志位
#define REC_INFO_DELETED_FLAG 0x20UL
0x20UL中的 UL 表示这是一个无符号Long类型的数字,0x20是16进制表示,换算成十进制刚好是32。
2)从事务1 删除的session中可以看到,通过主键删除的session中,有一个ID为 72a0bf611835464b9f1f13e3a7ee9923 的会议被删除了,而这个ID正好在事务2中被删除的session endponit记录中可以找到,和业务代码也是对应上的。
由此可以证明,事务2要插入的session endpoint记录,刚好就插在了事务1要删除的session endpoint的记录上,而事务1还没提交,也就是说,已删除的session endpoint记录上的记录锁还没释放,所以插入意向锁和记录锁冲突,导致了事务2在session endpoint这个表上插入SQL的等待。
按照上面的分析,只要能证明往session插入的记录,会阻塞session的批量删除操作,就能把整个死锁流程解释清楚了。为了弄清楚这个流程,需要对MySQL源码进行调试。
为尽可能真实地模拟出问题所在的场景,需要往数据库里面插入真正有问题的id值(曾经尝试过用字符串作为id去复现但并不能复现),模拟session的DDL在上面已经列出,现列出初始化的插入语句如下:
insert into `session`(id, code, topic) values(0x338A697F27EC4EFC832BBFC109D34505, '84709989', '84709989'),(0x3B3DE6A8C48940239907F7D4FAFB5418, '32700709', '32700709'),(0x4567EC174BAD41A5A7B6587B7FDB6DFD, '34106954', '34106954'),(0x72A0BF611835464B9F1F13E3A7EE9923, '50241728', '50241728'),(0x8B2845485D584A3EB38B6D7143AF0979, '23785170', '23785170'),(0xB41D1ACB485A4E599A687E4AB1C36648, '16264951', '16264951'),(0xB626729F75AA42CEBA86C07880F9A3DA, '38992827', '38992827'),(0xCF06F6E7AFC247BC914242E7F7D93FE3, '44151024', '44151024'),(0xDB71BC0D218A46678FE9B64ABBCE7212, '98073250', '98073250');
检查一下数据库隔离级别是否为可重复读,以及数据库的版本是否为5.7 (因为业务中使用的数据库版本为5.7)
select @@tx_isolation;select @@version;
一切准备就绪。下面针对先插入session,再批量删除session的场景设计SQL的执行过程。按上述分析,需要有两个事务T1和T2,T2先插入一条session记录,T1再批量删除session记录,如果此时批量删除session记录的SQL被阻塞的话,就说明上述的分析是成立的。由此可得到这样一个SQL执行流程:
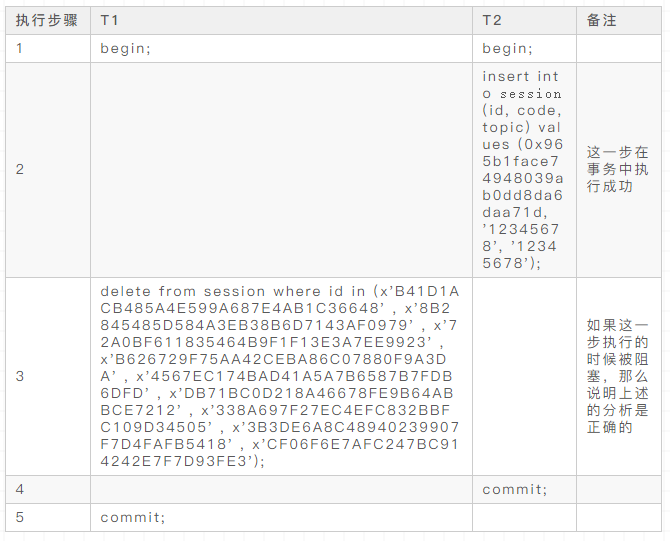
按照这样的流程执行下来,发现的确在执行第3步的SQL时被阻塞了:
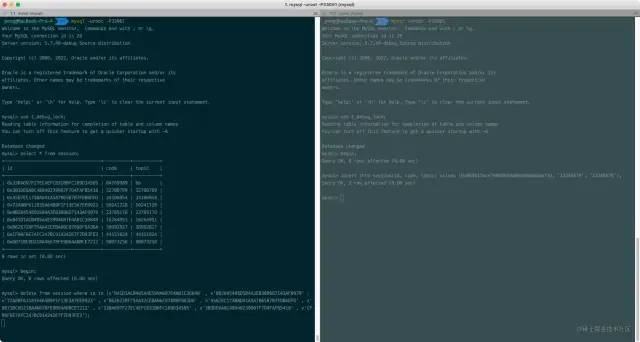
SQL被阻塞
从实验结果来看,在执行第3步的时候,的确被阻塞了,说明上面的分析是成立的。
可是在这个场景下,为什么会导致阻塞呢?这两个SQL执行时,对应的id都是不一样的。按MySQL批量删除的处理逻辑,MySQL会逐条记录遍历后再进行删除,既然执行这条SQL时阻塞住了,那么很可能在删除某条记录时在等待锁。为了找到这条记录,先对id进行排序(因为即使传入一个乱序的id列表,MySQL也会先对id列表进行排序再进行遍历,所以为了能找到删除哪条记录被阻塞,这里先人工进行排序),再逐步在T1中增加删除的主键,最终发现在删除这样一个主键记录集时会发生阻塞:
delete from session where id in (x'338A697F27EC4EFC832BBFC109D34505',x'3B3DE6A8C48940239907F7D4FAFB5418',x'4567EC174BAD41A5A7B6587B7FDB6DFD',x'72A0BF611835464B9F1F13E3A7EE9923');
问题的规模也缩小了一半,接下来就只能通过调试来对这个问题进行分析了。
在如下代码处加断点进行调试。
源码位置:storage/innobase/lock/lock0lock.cc
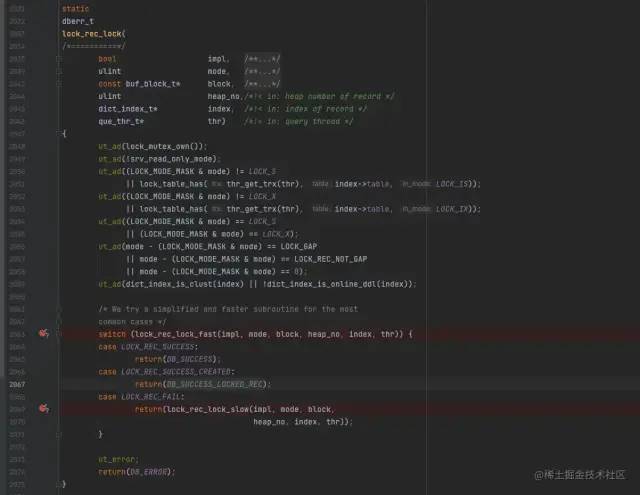
MySQL锁源码
因为这是一个比较底层的锁函数,在SQL执行的过程中,MySQL需要对SQL进行统计,将统计数据插入系统表里面,也会经过这个函数,所以干扰的数据会比较多。所以这里加了一个条件断点,只有我们自己的表执行到这里的时候,才会停在断点处:
(size_t) strcmp(index->table_name, "t_debug_lock/session") == 0
然后执行批量删除的SQL时,可以看到断点停留在了设置的位置上
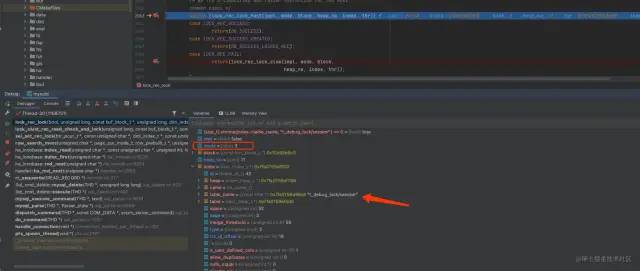
MySQL源码调试
从图中可以看到,此时的mode值是3,mode的值其实是等于 锁类型 和 锁模式 进行或运算得到的。对于锁类型和锁模式的定义,在源码中是这样的:
enum lock_mode { LOCK_IS = 0, LOCK_IX, LOCK_S, LOCK_X, LOCK_AUTO_INC, LOCK_NONE, LOCK_NUM = LOCK_NONE, LOCK_NONE_UNSET = 255 };
#define LOCK_MODE_MASK 0xFUL#define LOCK_TABLE 16#define LOCK_REC 32#define LOCK_TYPE_MASK 0xF0UL#if LOCK_MODE_MASK & LOCK_TYPE_MASK # error "LOCK_MODE_MASK & LOCK_TYPE_MASK" #endif #define LOCK_WAIT 256 #define LOCK_ORDINARY 0 #define LOCK_GAP 512 #define LOCK_REC_NOT_GAP 1024
#define LOCK_INSERT_INTENTION 2048 #define LOCK_PREDICATE 8192#define LOCK_PRDT_PAGE 16384
而在断点处显示,模式mode=3,则说明此时的 mode = LOCK_X | LOCK_ORDINARY。这个算法并不是猜测出来的,而是有代码为证:
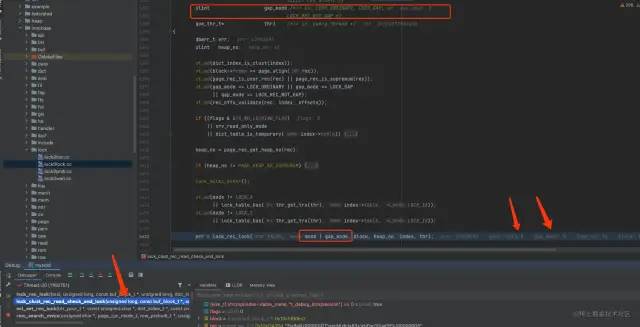
LOCK_X
从堆栈可以看出,在进入断点处代码之前,mode值正是LOCK_X和LOCK_ORDINARY进行或运算得到的。
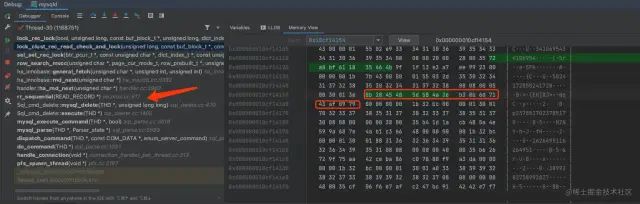
这只能证明执行删除的时候,会加上LOCK_X锁,还需要继续找到代码阻塞的位置才行。因为这删除的是一个id列表,会执行很多相似的流程,而在删除最后一条记录的时候会阻塞,我们需要找到最后一条记录的执行流程。可是这个session表里的id是binary格式,并不能很好地从调试信息中辨别出来,因此只能通过调试信息中的这个字段来进行对比:
先复制这个rec字段的地址,然后通过 MemoryView,打印出这个地址下的16进制数字。
MemoryView16进制数字
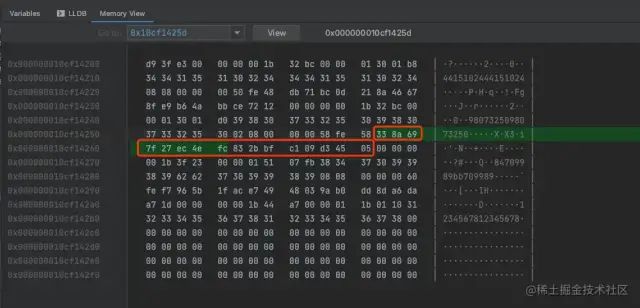
16进制数字
通过红框里面的16进制数字和删除SQL中的id:338A697F27EC4EFC832BBFC109D34505 进行对比,两者完全一致。可以确定此时正在执行第一条记录的删除。通过这种方式,我们可以直接定位到最后一条记录(0x72A0BF611835464B9F1F13E3A7EE9923)被删除的流程。
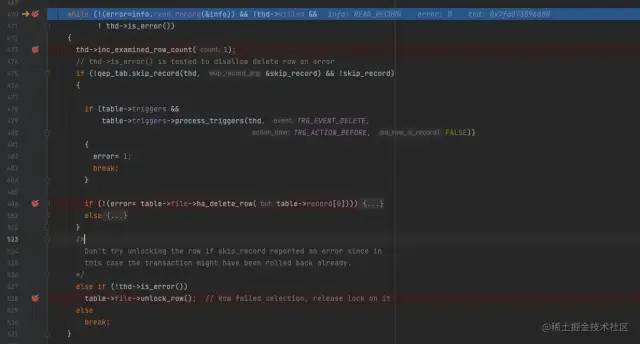
通过多次对比删除记录列表里面的流程发现,其主要流程集中在sql/sql_delete.cc中。核心代码如下所示:
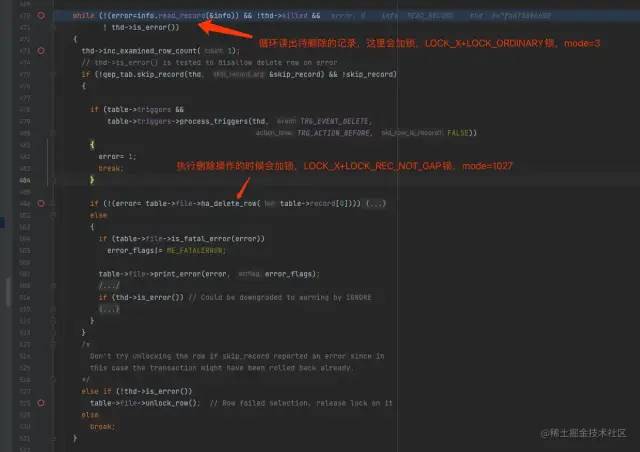
sql_delete核心代码
当执行到最后一条记录时,发现并没有阻塞,而是紧接着在循环中调用 info.read_record函数读取到了下一条记录(0x8B2845485D584A3EB38B6D7143AF0979):
read_record
而这一条记录正是我们删除记录列表里面,排在0x72A0BF611835464B9F1F13E3A7EE9923记录后面的下一条记录。同样地,也对0x8B2845485D584A3EB38B6D7143AF0979这条记录加了LOCK_X锁。但是这条记录并不是我们想要删除的记录,所以跳过了ha_delete_row函数的执行,并执行了unlock_row函数。
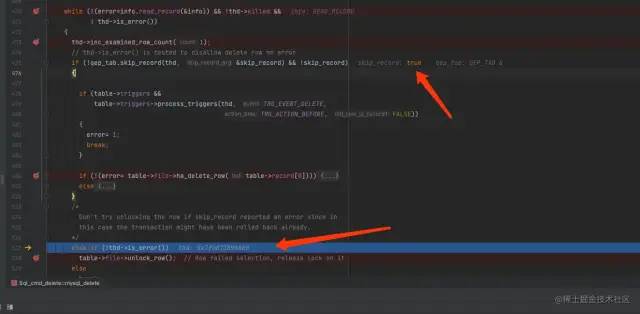
unlock_row
这个时候还没进入到代码阻塞的地方,关键点来了,在unlock_row执行完之后,并没有执行break,而是会继续读取新纪录:
继续读取新纪录
那这个时候会读取到事务2插入的新session记录(0x965b1face74948039ab0dd8da6daa71d),还是会读取到这条记录 0x8B2845485D584A3EB38B6D7143AF0979 的下一条记录呢?代码继续往下执行,此时进入到一个关键函数中 row_search_mvcc

row_search_mvcc
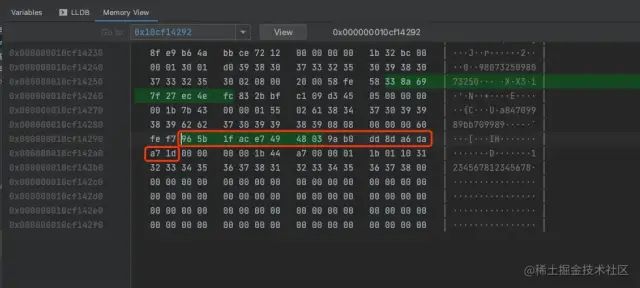
在row_search_mvcc函数中,会执行到这一行,对聚簇索引上的记录进行检查。

row_search_mvcc
观察到此时的rec已经指向了事务2插入的新纪录0x965b1face74948039ab0dd8da6daa71d,说明上面继续读取新纪录时,读取到的是由事务2插入的新纪录。这个时候正是要对这个记录进行加锁(mode=LOCK_X, gap_mode=0, 即加了LOCK_X+LOCK_ORDINARY锁)。

记录进行加锁
记录进行加锁
因为这条记录已经被事务2加了记录锁,所以这个时候想要再对同一条记录加锁,就会导致阻塞。从源码上也可以看到,在检测到锁冲突的时候,会导致阻塞。最终阻塞的代码位置,在这个地方:
源码位置:storage/innobase/lock/lock0lock.cc 的 lock_rec_lock_slow 函数
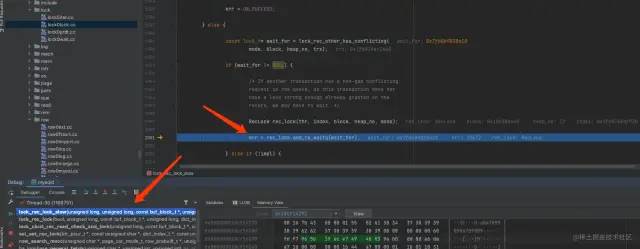
lock_rec_lock_slow
从调试的结果可以看到,当T2插入了一条新记录,T1再进行批量删除,就有可能导致T1阻塞。这也印证了一开始的猜想,从而还原了整个死锁的流程。
至此,死锁的问题原因已经找到,那如何解决呢?这里再贴一下死锁形成的过程:

既然死锁是由于两个事务对两个表操作的顺序不一致造成的互相等待,那么可以将T1对两个表的操作顺序调换一下,即第一步和第三步进行调换,最终变成这样:

理论上先验证下是否产生死锁:
1)假设T1先删除session,T2插入session时发生了阻塞,那么T2的插入session_endpoint无法继续进行,但不影响T1继续删除session_endpoint,所以T1可以继续执行直到事务提交。此时处于session记录上的锁被释放,T2可以获取到锁继续执行插入session_endpoint,因此不会造成死锁。
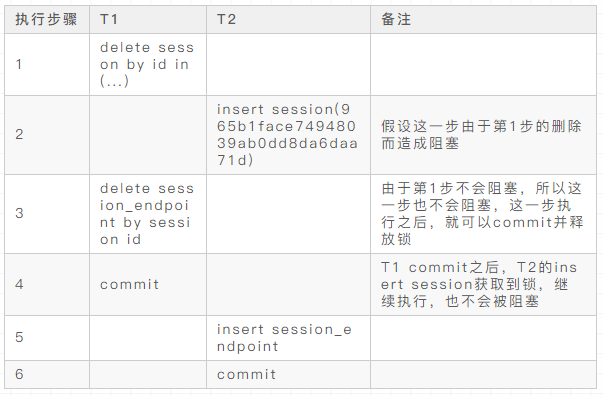
2)假设T2先插入session,T1再批量删除session,从上述的调试实验可以知道这里会造成T1阻塞,T1无法继续执行删除session_endpoint的操作。但是不影响T2继续执行,T2在插入session之后会继续插入session_endpoint,因为T1并没有事先删除session_endpoint,所以也就不会出现在一条标记为已删除的记录上插入的问题。因此T2可以完成session_endpoint的插入,最终T2事务提交,释放了持有的锁。T1获取锁之后,也可以继续执行,不会造成死锁。

实际要修改的业务代码也很简单,只需要调换一下代码的执行顺序,先批量删除session记录,再批量删除session_endpoint记录
@Transactional(rollbackFor = Exception.class)public void clearSessions(List sessionIds) { sessionRepository.deleteSessionByIds(sessionIds); sessionEndpointRepository.deleteSessionEndpointBySessionIds(sessionIds);
}
这么修改之后,还要写一个简单的自动化测试脚本来进行验证。大致步骤如下:
至此,整个数据库死锁的问题已经得到了解决。解决这个问题改动的代码非常简单,但是整个问题的分析、推理和验证,都比较曲折。这其中也走了不少弯路,包括一度怀疑是使用的数据库ORM框架做了什么骚操作导致的,但是最终也通过查看数据库binlog日志的方式快速排除了这个可能性。网上的文章不一定都是正确的,还是要自己动手调试源码,静下心来阅读源码中的注释和文档,才能找到问题的原因所在。






