Uplift模型是因果学习中的重要方法,在业界有着丰富的应用场景。早在2018年,Uber的数据科学团队面临需要Uplift模型解决的问题,在没有找到合适的开源工具包的情况下,开发了CausalML,随后作为开源项目提供给更广泛的社区使用,也吸引来更多的开发者完善了这个工具包。目前,CausalML已有超过80万的下载量,开源项目组也在持续维护和升级这个工具包。2022年1月,由智源社区、集智俱乐部联合举办的因果科学与Causal AI读书会第三季邀请到CausalML创始团队的赵振宇,为我们介绍CausalML作为一个基于Python的开源项目的发展历程,核心方法,以及应用场景。本文是根据此次读书会整理的文字稿。
“因果科学”读书会第四季目前已经启动。读书会以“因果表征学习”为主题,聚焦因果科学相关问题,共学共研相关文献,自2022年12月27日开始,每周六晚20:00线上举行,为期十周。欢迎从事因果科学、人工智能与复杂系统等相关研究领域,或对因果表征学习的理论与应用感兴趣的各界朋友报名参与。
研究领域:因果学习,机器学习
赵振宇 | 讲者
Zejun | 整理
邓一雪 | 编辑
在互联网平台中,如果出现了成规模的用户流失,市场营销部门常常采用发放代金券的方式来召回流失用户。那么向哪些用户投放代金券效果最好呢?在数据科学时代,一个很常见的思路是采用机器学习方法来对用户建模,预测哪些用户最有可能回流,然后进行定向投放。但有时候实际结果表明,这种基于模型的投放组效果会不如随机投放组。

图表 1:代金券投放对照实验
从图1中可以看到投放是有效果的,预测也是准确的,那么为什么基于模型的投放组效果反而不如随机投放呢?原因其实很简单,自然回流概率高的用户,不管是否有代金券,都会回来。将代金券发给必定会回来的用户,并不能产生增益。为了解决这一问题,我们需要将现有的机器学习算法与因果推断相结合。本文要介绍的CausalML就是解决这一问题的有力工具。
CausalML是一个基于Python的因果学习开源项目。最早为Uber项目定制、内部开源,而后正式成为开源项目。其提供了丰富的模型选择,例如常用的Meta-Learner和因果树模型,方便在实践中作对比和选择。同时还提供例如模拟数据生成、模型可视化、模型评估等一系列配套工具。其目标是用于解决业务实践问题,尤其是在计算速度和数据规模方面能够达到业界标准并持续优化。
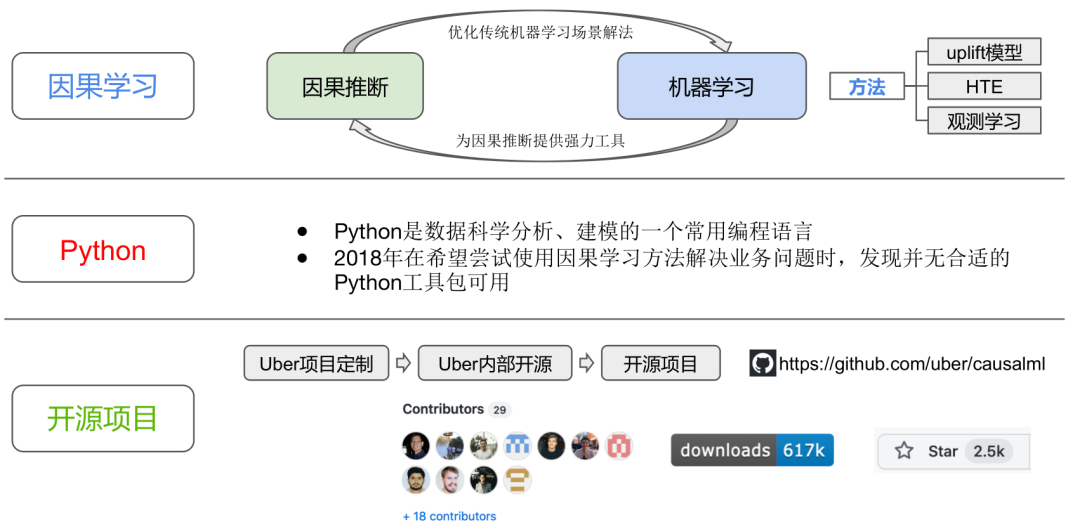
图表 2:CausalML图示

图表 3:CausalML模块概览
在介绍具体主要模块之前,我们先来介绍一下相关背景。和前面代金券的例子类似,在广告营销中,我们可以根据有无投递广告和是否购买产品来将用户划分成四类(见图四):总是购买、劝退用户、策略提升用户和总不购买。
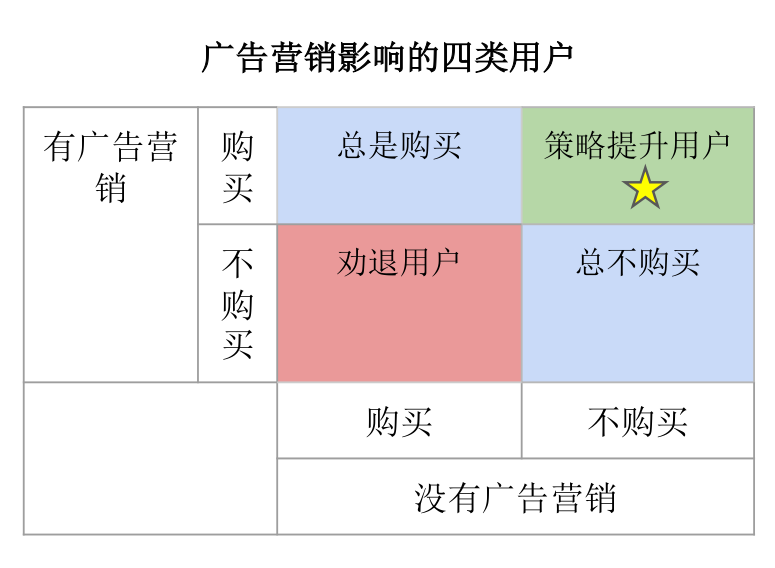
图表 4:广告营销影响的四类用户
如果我们将没被投放广告的用户设为对照组,将被投放广告的用户设为实验组。从整体上来评估,广告对购买率的提升效果 = 实验组购买率 – 对照组购买率,这实际上是因果推断中的ATE (Average Treatment Effect)。通过代金券发放的例子,我们知道这种评估方式是有误差的。作为改进,我们需要从个体角度来评估效果,为此就引入了HTE (Heterogeneous Treatment Effect) 的概念。简单来说,相比于ATE,HTE是一个更专注于个体差异化效果的指标。具体定义见下图:
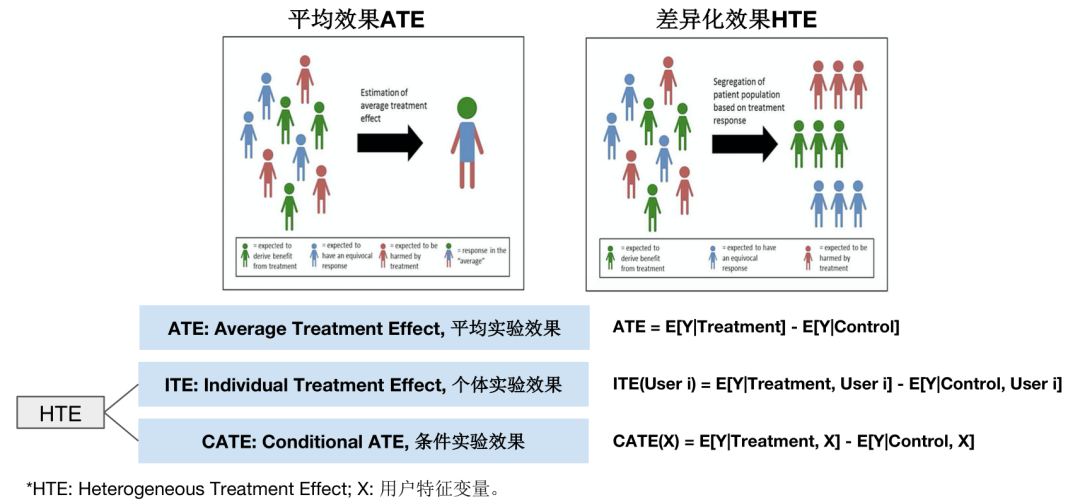
图表 5:HTE
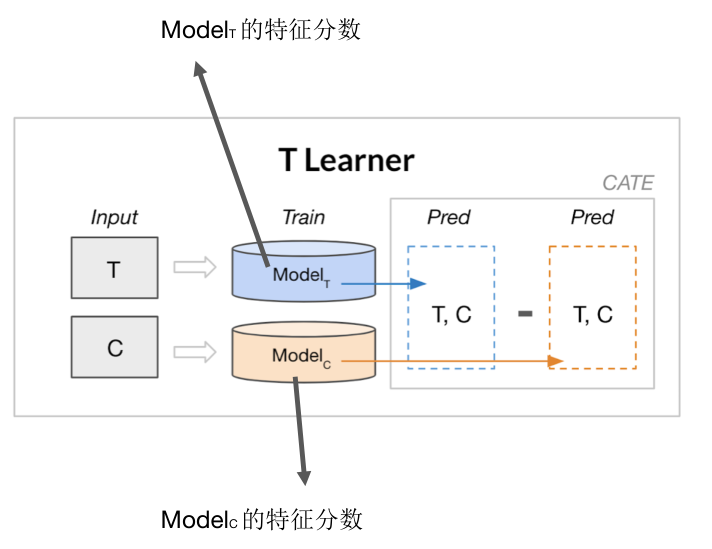
因为ITE是不能够通过观测得到的,所以我们采用CATE (Conditional ATE) 作为实际的指标:广告对用户i的效果 = E[Y|Treatment, Xi] - E[Y|Control, Xi]。Xi表示用户i所具有的相关特征。这就是Uplift模型的核心思想。有了CATE的概念,接下来要做的就是该如何估计CATE。常见的方法有Meta-learners和Uplift树模型两种。
Meta-learners的基本想法是组合既有的传统机器学习模型。首先定义一个base learner,一般就是一个传统的机器学习模型,任何一个给定X可以预测Y的模型都可以。然后采用不同的混合方式,比如S Learner,T Learner,X Learner,R learner。[1][2]见下图:

图表 6:Meta-learners
Uplift树模型的基本想法是通过改变树模型的损失函数来估计CATE(见图7)。与传统分类树的区别如下:


图表 7:Uplift图示
使用Uplift模型定位“策略提升用户”可以分成三个步骤:
1. 数据收集实验:目标是为Uplift模型收集训练数据。给对照组所有用户不发促销,给实验组所有用户发促销。
2. 训练Uplift模型:收集实验数据和用户特征,训练Uplift模型。训练完成的Uplift模型可以根据用户特征X,估计实验效果CATE。
3. 验证模型效果实验:设置对照组为无促销,设置两个实验组,实验组1为随机选取10%用户发促销,实验组2位根据Uplift模型预测,选取预估实验效果在top10%的用户发促销。
根据以上步骤,在广告营销的场景中,最优策略是使用Uplift模型定位策略提升用户群(投放效果为正向),并针对这部分用户进行投放。这一策略和直接使用机器学习模型的不同见下图:

图表 8:Uplift模型 vs 机器学习模型
这一部分我们来介绍CausalML中特有的方法。首先是特征选择问题:当候选特征过多的时候,使用全部特征建模会造成模型过拟合。根据[Radcliffe & Surry 2011],目标是HTE的Uplift模型相比于直接估计Y的传统模型更容易过拟合。对特征进行筛选可以提高模型的准确性,同时降低线上数据管理成本。而传统的特征选择方法针对的是对Y有预测性的特征,而非HTE。所以我们设计了两种新方法:一是与模型无关的Filter Method(图9),通过计算单个特征分数的方式反应特征对HTE的关联。二是Embedded Method,在模型训练过程中,计算各个特征对模型目标函数的贡献值(图10)。[4]
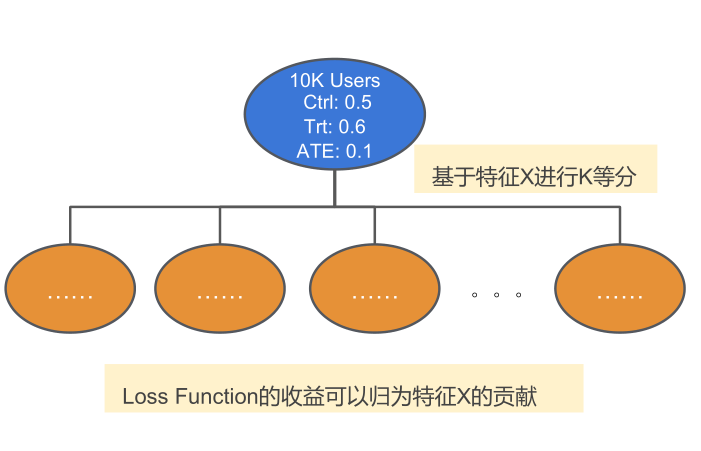
图表 9:Filter Method
图表 10:Embedded Method
有些场景下,存在多个实验组,且不同的实验组成本不相同。例如:
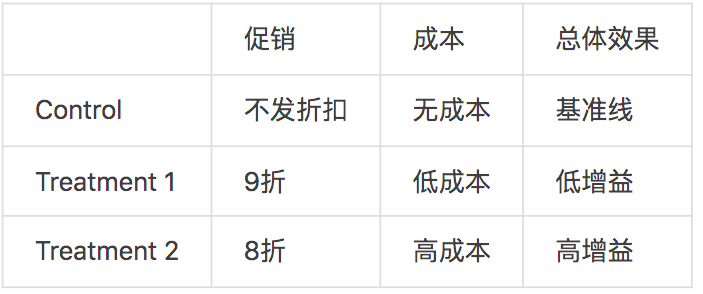
我们会希望在优化转化率的同时,也考虑成本:将9折优惠券发给对于9折实验效果敏感的用户,将8折优惠券发给只对8折实验效果敏感的用户。对于这种场景,CausalML也提供了对应的价值优化方法。方法的想法是考虑成本,将成本计入CATE中,用基于X Learner的方法,在多个实验组并存的情况下尝试将最优的实验组挑出来。[5]
只需要在命令行界面输入pip install causalml就可以完成下载。Causal开源了丰富的实操演示。包括不限于数据生成、CATE估计,Uplift曲线可视化,价值优化模型、倾向值匹配方法。
CausalML的应用场景可以归结如下三个方向:
1. 用户定向。定位对投放正向敏感用户群,从而优化投入产出比。除了我们前面介绍过的广告投放,还可以应用于客服中心电话联系潜在用户、APP信息推送频率等场景。
2. 个性化推荐。根据用户偏好,提供个性化体验。以Netflix的场景为例,我们可以先用A/B测试得到的ATE来选取全局最优封面,再根据HTE选取区域最优封面。
图表 11:个性化推荐示例
3. 观测数据的因果推断。当随机实验不可行时,通过因果推断方法基于观测数据估计因果效应。例如想评估APP进程崩溃对用户的影响,直接进行随机实验有较大的负面影响,但可以应用已经观测到的数据。因果推断的方法(比如匹配),控制混淆因子,进而做出更准确地分析。
CausalML会继续优化已有模型的计算性能,例如使用Cython来提升计算速度。同时添加新的模型与方法、完善文档示例,进一步增强易用性。
业界常用的实验方法可以总结成以下几种:A/B测试基本覆盖了大多数实验场景;网络效应实验适用于分流时用户之间存在干扰的情况,也即因果推断中的interference问题;Uplift模型适用于对HTE的估计;灰度放量试验适用于全量上线有风险,需要实时监控修正再逐步放开的情况;MAB即多臂老虎机,适用于在多实验组中进行价值优化;Interleaving基于同一个用户对于排序方法A和B的偏好,适用于评估排序算法对长尾查询的效果。
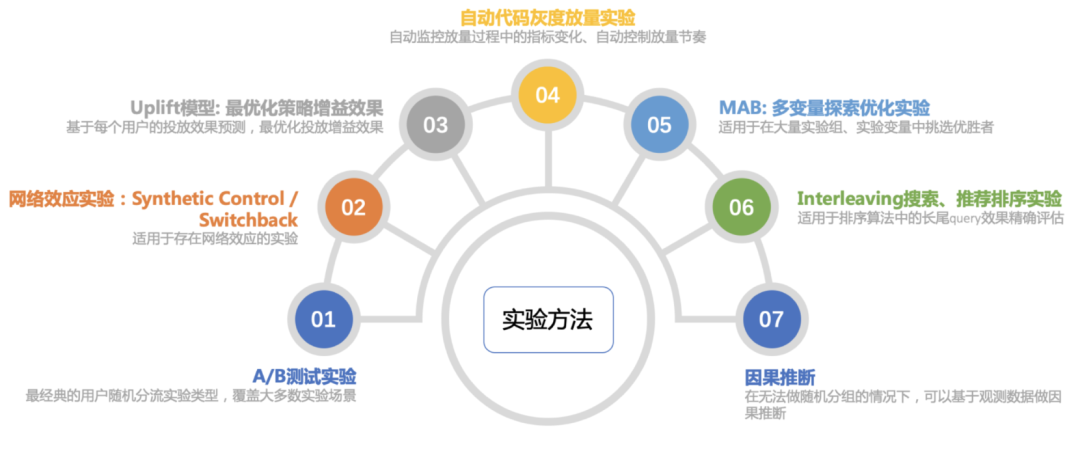
图表 12:业界实验领域概览
参考文献:
[1] Sören R Künzel, Jasjeet S Sekhon, Peter J Bickel, and Bin Yu. Metalearners for estimating heterogeneous treatment effects using machine learning. Proceedings of the National Academy of Sciences, 116(10):4156– 4165, 2019.
[2] Xinkun Nie and Stefan Wager. Quasi-oracle estimation of heterogeneous treatment effects. arXiv preprint arXiv:1712.04912, 2017.
[3] Chen, Huigang, Totte Harinen, Jeong-Yoon Lee, Mike Yung, and Zhenyu Zhao. "Causalml: Python package for causal machine learning." arXiv preprint arXiv:2002.11631 (2020).
[4] Zhao, Zhenyu, Yumin Zhang, Totte Harinen, and Mike Yung. "Feature Selection Methods for Uplift Modeling." arXiv preprint arXiv:2005.03447 (2020).
[5] Zhao, Zhenyu, and Totte Harinen. "Uplift modeling for multiple treatments with cost optimization." In 2019 IEEE International Conference on Data Science and Advanced Analytics (DSAA), pp. 422-431. IEEE, 2019.

赵振宇,腾讯数据科学总监。先后在Yahoo,Uber,腾讯任职。负责实验、因果推断、机器学习、产品分析、平台建设、开源软件、应用研究方面的工作。CausalML发起者之一,《关键迭代可信赖的线上对照实验》译者之一。
随着“因果革命”在人工智能与大数据领域徐徐展开,作为连接因果科学与深度学习桥梁的因果表征学习,成为备受关注的前沿方向。以往的深度表征学习在数据降维中保留信息并过滤噪音,新兴的因果科学则形成了因果推理与发现的一系列方法。随着二者结合,因果表征学习有望催生更强大的新一代AI。
集智俱乐部组织以“因果表征学习”为主题、为期十周的读书会,聚焦因果科学相关问题,共学共研相关文献。读书会自2022年12月27日开始,每周六晚20:00线上举行。欢迎从事因果科学、人工智能与复杂系统等相关研究领域,或对因果表征学习的理论与应用感兴趣的各界朋友报名参与。集智俱乐部已经组织三季“因果科学”读书会,形成了超过千人的因果科学社区,因果表征学习读书会是其第四季,现在加入读书会即可参与因果社区各类线上线下交流合作。

点击“阅读原文”,报名读书会








