
凡是搞计量经济的,都关注这个号了
稿件:econometrics666@126.com
所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软
件都放在社群里.欢迎到计量经济圈社群交流访问.

金融领域的人工智能和机器学习:从文献计量分析中识别基础、主题和研究集群
正文
关于下方文字内容,作者:王越洋,澳大利亚新南威尔士大学金融科技,通讯邮箱:wyueyang1@163.comJohn W.Goodell, SatishKumar, Weng MarcLim, DebiduttaPattnaik. (2021). Artificial intelligence and machine learning in finance: Identifying foundations, themes, and research clusters from bibliometric analysis, Journal of Behavioral and Experimental Finance.
Artificial intelligence (AI) and machine learning (ML) are two related technologies that are emergent in financial scholarship. However, no review, to date, has offered a wholistic retrospection of this research. To address this gap, we provide an overview of AI and ML research in finance. Using both co-citation and bibliometric-coupling analyses, we infer the thematic structure of AI and ML research in finance for 1986–April 2021. By uncovering nine (co-citation) and eight (bibliometric coupling) specific clusters of finance that apply AI and ML, we further identify three overarching groups of finance scholarship that are roughly equivalent for both forms of analysis: (1) portfolio construction, valuation, and investor behavior; (2) financial fraud and distress; and (3) sentiment inference, forecasting, and planning. Additionally, using co-occurrence and confluence analyses, we highlight trends and research directions regarding AI and ML in finance research. Our results provide assessment of AI and ML in finance research.
金融领域的人工智能和机器学习:从文献计量分析中识别基础、主题和研究集群目录:
一,摘要
人工智能(AI)和机器学习(ML)是在金融学术界出现的两种相关技术。然而,到目前为止,还没有一篇评论对这一研究进行全面的回顾。为了解决这个问题,我们对金融领域的AI和ML研究进行了概述。利用共同引用和文献计量耦合分析,我们推断了1986-2021年4月金融领域人工智能和ML研究的主题结构。通过发现9个(共同引用)和8个(文献计量耦合)应用人工智能和ML的金融学具体集群,我们进一步确定了对两种分析形式大致相当的三组金融学研究:(1)投资组合构建、估值和投资者行为;(2)金融欺诈和困境;以及(3)情绪推理、预测和规划。此外,利用共同发生和汇合分析,我们强调了有关金融研究中AI和ML的趋势和研究方向。我们的结果提供了对金融研究中人工智能和ML的评估。二,引言
人工智能(AI)和机器学习(ML)在金融系统中的新兴应用正在颠覆和改变行业和社会(Li and Tang, 2020; Wall, 2018)。从传统的对冲基金管理公司、投资银行和零售银行,到当代金融科技(FinTech)服务提供商,如今许多金融公司都在大力投资于数据科学和ML专业知识的获取(Holzinger等人,2018;Wall,2018)。整个金融系统中机器可读数据的产生,在计算能力和存储的持续增长支持下,对金融业产生了重大影响。与这种 "数据驱动 "相伴而生的是对监管体系的不断重塑。作为一个具体的例子,2007-2008年的全球金融危机促使金融业的监管发生结构性变化,将重点放在 "数据驱动 "的监管上。这导致了对银行贷款合同条款的重新评估和分析,以及在整个欧洲和美国实施的交易簿压力测试计划(Flood等人,2016)。金融业专业人士对标准公司基本面、证券价格和宏观经济指标范围之外的 "替代数据 "越来越感兴趣。这包括语音记录、新闻文章、社交媒体上的帖子和卫星图像。这种特别大的数据来源现在对交易决策有重大影响(In等人,2019)。de Prado(2019)在探索这类数据集的属性时注意到,这类大型数据源对于传统方法来说是很尴尬的,通常是非数字性的、非结构化的、充满缺失值的和/或非分类的。因此,这类数据通常是高维的,变量(特征)的数量往往超过观察值的数量(另见Duan等人,2021;Makarius等人,2020)。鉴于这些异常情况,以线性建模为前提的经典计量经济学在使用替代数据得出预测性和去终端化模型方面没有什么用处(de Prado,2019)。大数据集中许多微妙的、但在经济上很重要的内在信息仍然没有被这种传统的建模所发现(Coulombe等人,2020)。例如,像协方差矩阵这样的几何结构不能区分替代数据集中的网络特征的拓扑学中的关系。另一方面,ML模型提供了在高维数据环境中破译复杂模式所需的计算能力和功能灵活性。此外,ML的最新进展使科学理论的应用变得合理,以确定变量特征之间的(相互)关系,进行更深入的探索、预测、因果推断和可视化(Dixon等人,2020)。ML是克服经典计量经济学模型在检测异常值、提取特征以及对复杂数据进行分类和回归方面的缺陷的合适补救措施。例如,在'n'个特征中可以存在2n-n-1个乘法交互作用,因此,一个交互作用(f1 f2)可以表现为两个特征(f1和f2),而四个交互作用(f1 f2、f1 f3、f2 f3和f1 f2 f3)可以在三个特征(f1、f2和f3)中展开,而对于小到10个特征的情况,总共可以有1013种交互作用。不幸的是,与ML不同,经典的计量经济学模型不能 "阅读和学习导致戏剧性的结果(Dixon等人,2020)。作为一个例子,考虑用Yt = X1,t + X2,t + εt来拟合Yt = X1,t + X2,t + X1,tX2,t + εt是根本不可能的。然而,ML算法,如决策树,可以很容易地将一个复杂的数据集划分为具有可识别的线性模式的子集。因此,与经典的线性回归不同,ML中的决策树算法可以快速识别模式,在这种情况下,X1,tX2,t效应,从而对复杂的情况产生合理的结果。人工智能相对于传统计量经济学模型的威力已经点燃了人们对ML应用于算法交易(Martínez等人,2019)、资产和衍生品定价(Houlihan和Creamer,2021)、自动化(Kokina等人。2020),金融建模(Chan和Hale,2020),欺诈检测(Teng和Lee,2019),贷款和保险承保(Bee等人,2021),预防金融风险(Gao,2021),风险管理(Li等人,2021),情感分析(Chen等人,2020),以及贸易结算(Omarova,2019)等。尽管人工智能和ML的普及引发了最近大量的文献,但关于人工智能和ML在金融方面的学术总结仍然很缺乏。这方面的例外(Das,2014;Li,2020;Loughran和McDonald,2020)在很大程度上偏向于只关注金融中的文本分析应用。到目前为止,还没有一篇综述介绍了人工智能和ML在金融领域应用的最新情况。对新兴领域进行回顾的评论非常重要,因为它们有助于学者获得研究领域的结构和分类的概述(Donthu等人,2021)。鉴于人工智能和ML的重要性,以及整合这些技术在金融领域应用的现有文献的研究的匮乏,我们对人工智能和ML在金融领域的应用的现有文献进行了回顾。为了做到这一点,我们采用了文献计量学方法,其中包含了大量能够处理与文献相关的大型数据集的定量技术(Donthu等人,2021)。这样一来,我们对现存文献的文献计量审查确定了人工智能和ML在金融研究中应用的学术领域的主题和基础,为未来的调查提供了框架。利用共同引用和文献计量耦合分析,我们推断出1986-2021年4月人工智能和ML在金融领域的知识和主题结构。通过发现9个(共同引用)和8个(文献计量耦合)应用人工智能和ML的具体金融领域,我们进一步确定了对两种分析形式来说大致相当的三个金融学术集群:(1)投资组合构建、估值和投资者行为;(2)金融欺诈和困境;以及(3)情感推断、预测和规划。此外,共同发生和汇合分析突出了关于金融研究中人工智能和ML的趋势和研究方向。我们的结果为未来的研究人员提供了指导,也为评估金融研究中对人工智能和ML的日益重视提供了重点。三,人工智能和机器学习(ML)的背景
人工智能的概念起源于1955年的达特茅斯夏季研究项目提案(McCarthy等人,2006年)。1 这个团队后来的发展认为 "学习的每一个方面或智能的任何其他特征原则上都可以被精确地描述出来,从而使机器可以模拟它",以努力 "找到如何使机器使用语言,形成抽象和概念,解决现在留给人类的问题,并改善自己"(McCarthy等人。2 从那时起,人工智能已经发展成为一个致力于使机器具有处理复杂任务能力的研究领域。从此,逐渐出现了一种成功的模式。图灵测试评估了机器展示智能行为的能力(图灵,1995年),显示机器在解决复杂的判断相关问题方面往往优于人类,例如在高维空间内限制的大量候选变量中识别决策变量(DeepMind,2016年;Saygin等人,2000年)。事实上,在深度学习的指导下,ML已经在各种任务中取得了明显的成功(Dixon等人,2020)。然而,人工智能、ML和相关概念,如深度学习和数据科学,往往让很多人感到困惑(Wall,2018)。从本质上讲,ML是人工智能的一种具体表现,它开发的技术使机器能够识别数据集中的模式。相比之下,深度学习是ML的一个子集,使机器具备解决复杂问题所需的技术,数据科学是一个独立的研究分支,应用人工智能、ML和深度学习来得出可操作的结论。ML广泛涵盖了识别特征和决策的算法的各个方面。监督式ML处理的是有标签的数据,例如以成对形式出现的数据(X1, Y1 ... Xn, Yn,其中X1 ... Xn∈X,Y1 ... Yn∈Y),其中每个特征向量(X1)都被标记为一个响应(Y1)。相比之下,无监督ML处理的是未标记的数据(X1,X2,X3 ... Xn),其中的目标是收集探索性信息,并通过将观察结果分组到不同的聚类中来发现隐藏的模式。因此,无监督ML涉及聚类算法,如分层聚类、K-means聚类、高斯混合、自组织地图和经常被称为数据挖掘的隐马尔科夫模型。对于金融领域的有监督和无监督的ML,合适的数据可以来自于金融文件、金融时间序列、新闻报道、社交媒体帖子或重要事件的文本内容。无监督的ML也可以通过强化学习获得信息。3 与关注某一时间点的单一行动的监督学习不同,通过强化学习的无监督ML关注的是最佳行动序列,因此,属于动态编程的一种形式,可用于优化投资组合分配、优化特定范围内的资产清算和最佳交易执行等情况。
四,金融研究中人工智能和机器学习的应用
关于人工智能和ML在金融领域的蓬勃发展的文献已经吸引了之前的学者评论。例如,Das(2014)探讨了金融中预测分析和文本挖掘的再搜索。de Prado等人(2016)评估了关于信用风险和破产的研究,观察到金融研究越来越倾向于将传统建模(如判别分析、逻辑回归)与AI、神经网络和其他ML技术相结合的混合模型。West和Bhat- tacharya(2016)对金融欺诈检测方面的文献进行了全面的分析,并根据这些文献进行了分类。欺诈的类型、使用的算法和检测方法的性能。Elliott和Timmermann(2016)分析了经济和金融研究中部署的预测方法,得出结论,没有一种方法是单独足够的。他们认为,应该通过获取各自损失函数的生态学来选择适当的预测方法。Currie和Seddon(2017)揭露了2010年 "闪电风暴 "后高频算法交易的 "黑暗艺术",提供了分析高频交易的概念工具。Sangwan等人(2019)强调了金融科技研究中普遍存在的主题。最近的评论集中在文本分析上。Li(2020)强调了金融知识测量模型的局限性,而Loughran和McDonald(2020)对金融领域的文本分析进行了最新的回顾。Bhatia等人(2020)探讨了机器人咨询服务的优势,而Königstor- fer和Thalmann(2020)回顾了商业银行中人工智能的好处和挑战。Ciampi等人(2021)评估了100多项关于中小企业违约预测模型的研究,赞同采用人工智能和ML进行违约预测。综合来看,现有的关于金融领域人工智能和ML的评论一般都是狭义的,不同的方面都是单独而不是集体介绍的。值得注意的是,这些过去的评论都没有对人工智能和ML在金融中的应用进行全面的分类。因此,在这篇研究中,我们采用了整体的和包容性的方法,同时叙述了人工智能和ML在金融中的采用和实施的全面概述。五,研究方法
我们采用了一种文献计量学方法,包括使用定量工具来分析文献计量学和书目信息(Pritchard, 1969)。与经典的系统性文献综述不同,文献计量学综述有能力在以大量文献计量学和书目信息为特征的领域提供信息。具体来说,我们遵循Donthu等人(2021)的文献计量学评论的四重程序:(1)定义评论的目的和范围;(2)选择分析的技术;(3)收集分析的数据;以及(4)进行分析并报告结果。我们试图通过研究文章、期刊、作者、机构和国家的出版趋势的文献计量结构来推断AI和ML在金融研究中的知识形成。审查的范围足够大,因为人工智能和ML都是广泛存在于当今全球社会的变革性技术,特别是在金融应用中。我们采用了一系列的文献计量分析技术来解读金融研究中的人工智能和ML的结构。除了处理大型语料库的能力(Donthu等人,2021年),文献计量学分析还能识别出版趋势,辨别进步的主题,并建立主题演变的可视化。这允许回顾和设想未来的研究方向(Ciampi等人,2021;de Prado等人,2016;Kumar等人,2021a、b;Pattnaik等人,2021)。与Donthu等人(2021)的观点一致,我们对评论语料库进行了性能分析,采用了共引分析、书目耦合和共现(或共词)分析等文献计量学分析技术。共引分析对划分民族知识很有效(Boyack和Klavans,2010;Small,1973),而书目耦合对解释知识体系中的主题很有用(Andersen,2019;Waltman等人,2010),共现(共词)分析对揭示主题轨迹很有用(Andersen,2019;Cheng等人,2018;Pattnaik等人,2020a,b;Zupic和Čater,2015)。引用参考文献的共同引用、文章集群的书目耦合和词语的共同出现是利用以卢万算法(Blon-del等人,2008)为前提的网络节点的模块化来识别的。在这个算法中,节点分别代表参考引文、评论中的文章和作者指定的关键词。简单地说,模块化是对网络划分为不同模块别名组、社区或集群的强度的衡量(Blondel等人,2008)。模块化程度高的网络在一个模块内的节点之间有密集的连接,但在该模块之外(即不同模块的节点之间)有稀疏的连接。模块化也是一种用于检测社区的优化方法,其值在-0.5到+1之间。在一个加权网络中,可识别的链接数量,如一篇文章被评论中的文章引用的次数,两篇文章被共同引用的次数,或两个关键词共同出现的次数,被称为模块化(Q),定义为
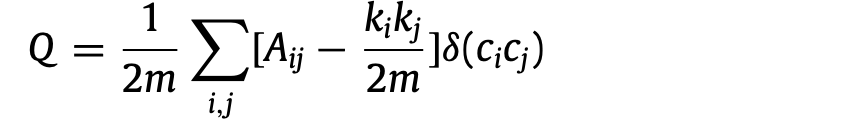
其中,Aij表示i和j之间的边(链接)的权重;ki = ∑j Aij表示连接到顶点I的边的权重总和;ci是顶点i被分配到的类或社区;δ函数δ(u,v)如果u = v,则分配为'1',否则为'0';m = 2/1∑j Aij。
用于社区检测的Louvain方法允许渐进式的模块化优化(Blondel等人,2008),其中网络中的每个节点首先被分配到它自己的社区,然后,对于每个节点i,模块化的变化(∆)是通过将i从它自己的社区替换到i所链接的每个邻近社区j来计算。由此产生的模块化变化被计算为在∑中的链接权重的总和;total是i要进入的社区中所有节点的权重之和;ki是i的加权度,其中度是指i的加权度。的所有链接的权重之和;ki是i的加权度,其中度是与节点i相关的链接数量的指标;ki,in是i与i所进入的社区中其他节点之间的链接的权重之和;m是网络中所有链接的权重之和。一旦计算出i所连接的所有社区节点的∆Q,i就会被放入导致最大模块性增加的社区。我们选择从Scopus获取数据,因为这是一个对金融领域的同行评审研究覆盖面最广的数据库(Pattnaik等人,2020a,b)--例如,与Web of Science(Valtakoski,2019)相比。按照最近的评论(例如,Garg等人,2021年;Mustak等人,2021年;Toorajipour等人,2021年),我们应用了广泛的搜索术语。表1说明了我们采用的系统程序,以得出283篇文章的最终语料库。从Scopus或任何其他搜索引擎获得的数据容易出现错误的文献计量和书目信息,这些信息是由后来的手稿中对原始手稿的报道引起的(Baker等人,2021)。因此,不进行数据清理就直接处理这些记录有可能造成不恰当的评估。因此,我们通过反省其参考文献来清理数据。正如Donthu等人(2021)和Zupic和Čater(2015)所建议的那样,这样的策略导致了对书目和书目数据的适当探索,其可视化,以及对结果的解释。我们还清理了许多出现在标题、摘要和作者指定的关键词中的术语,以利用VOSviewer中的自然语言处理(NLP)功能进行准确的主题分析。例如,我们将许多复数术语转换为单数形式(例如,"期权 "转换为 "选项","破产 "转换为 "破产","报告 "转换为 "报告","中小企业 "转换为 "中小企业",等等)。类似术语的多种表述也被统一(例如,'点对点'、'点对点'和'P2P'统一为'P2P';'风险价值'和'风险价值'统一为'风险价值',等等)。同样,短语和它们的扩展版本也被整合(例如,'中小企业'和'SME'统一为'SME';'风险价值'和'VAR'统一为'风险价值',等等)。这些清理策略能够为主题探索获得一套统一的术语。
六,研究结果
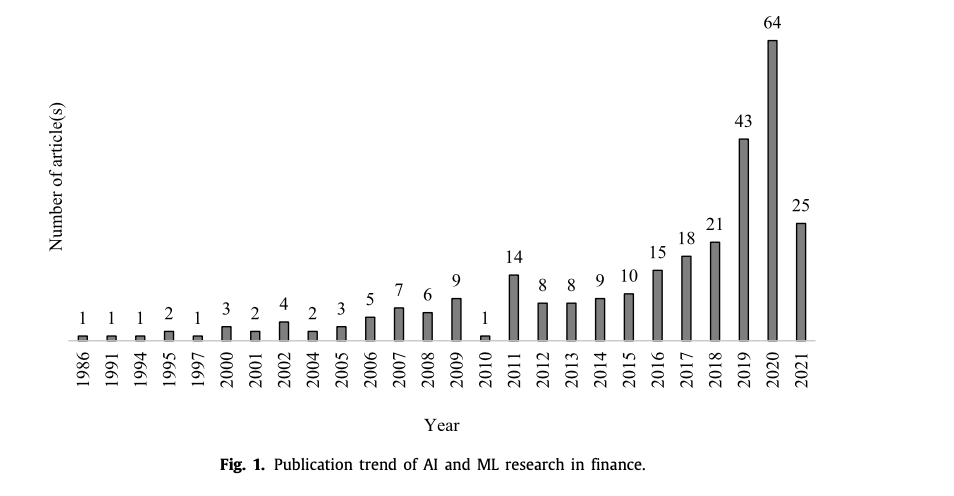
图1预示了金融领域人工智能和ML研究的出版趋势,其中文章的总数与它们各自的出版年份相对应。图1显示,金融领域的人工智能和ML并不新鲜,从1986年就开始出现了。然而,这些领域的金融研究只是在第四次工业革命出现后的最近几年才大量涌现。最多的年份是2020年(64篇文章)、2019年(43篇文章)、2018年(21篇文章)、2017年(18篇文章)和2016年(15篇文章)。这种上升趋势预计将持续到2021年以后,到2021年第一季度末,已经有25篇文章(或2020年文章总数的39%)发表。
ii) 金融领域AI和ML研究的顶级作者、机构和国家表2列出了金融领域人工智能和ML研究的顶尖作者,以及他们在写作时的机构和国家。根据引用次数,潘文超以950次引用成为金融领域人工智能和ML研究中最有影响的作者,其次是Sanjiv R. Das,引用次数为638次。就发表次数的生产力而言,Ashraf M. Elazouni是生产力最高的作者,发表了三篇文章。在机构中,根据收集到的引文,东方技术学院和圣克拉拉大学是最有影响力的机构,分别有950和638次引文。根据出版物的数量,香港大学是最有成效的机构,有8篇出版物。在各国中,美国在金融领域的人工智能和ML研究方面的智力贡献最大(80篇出版物),引用次数最高(1997)。
表3列出了发表金融领域AI和ML研究的顶级期刊。从引用率来看,《基于知识的系统》和《决策支持系统》是两个最有影响力的期刊,分别被引用1356次和790次。然而,就出版物而言,《定量金融》和《计算经济学》是两本最有成效的期刊,分别有29和18篇出版物。对不同时期的出版效率的映射表明,最近关于本评论主题的出版有上升趋势。量化金融学和计算经济学的情况尤其如此。有趣的是,在强调金融领域人工智能和ML的最重要期刊中,约有84%的期刊在澳大利亚商业院长委员会(ABDC)2019年期刊质量列表中被列为 "A*"或 "A"。这表明,首要期刊对发表与金融有关的人工智能和ML研究是乐于接受的。由于在顶级期刊上发表文章会激发学术界的兴趣(Baker等人,2021年;Pattnaik等人,2020年b),这些趋势表明未来在金融研究中涉及AI和ML的研究重点越来越多。然而,如果我们研究表3,关注金融分类期刊与非金融分类期刊(根据2018年学术期刊指南分类),我们会发现,到目前为止,金融期刊在发表AI和ML文章方面相对不那么积极。例外的是《定量金融》,它发表了29篇关于人工智能或ML和金融的文章7,《行为和实验金融》杂志8发表了6篇文章,都是在我们最近的子时期,还有《金融市场》杂志9发表了一些高引用率的文章。
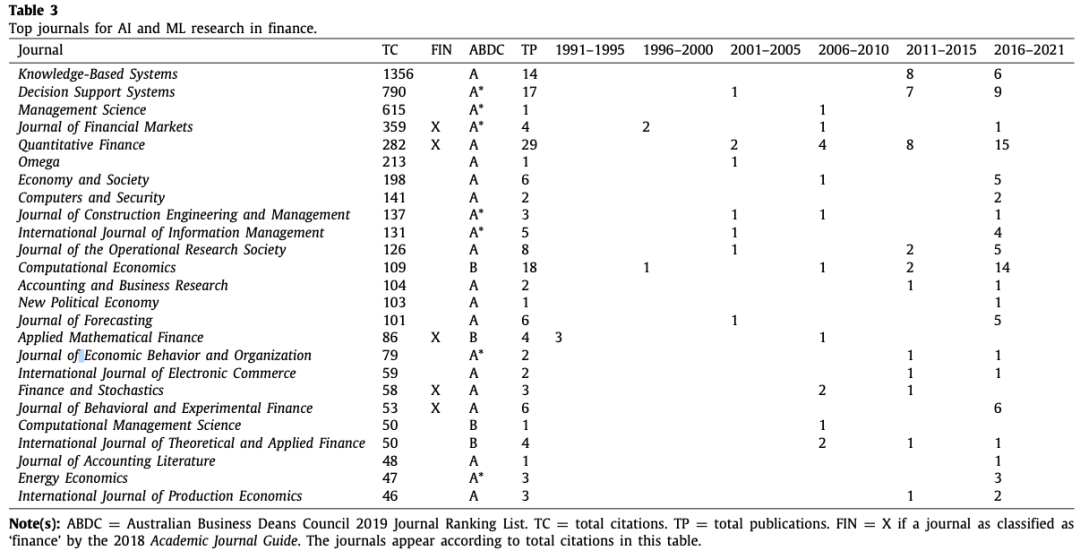
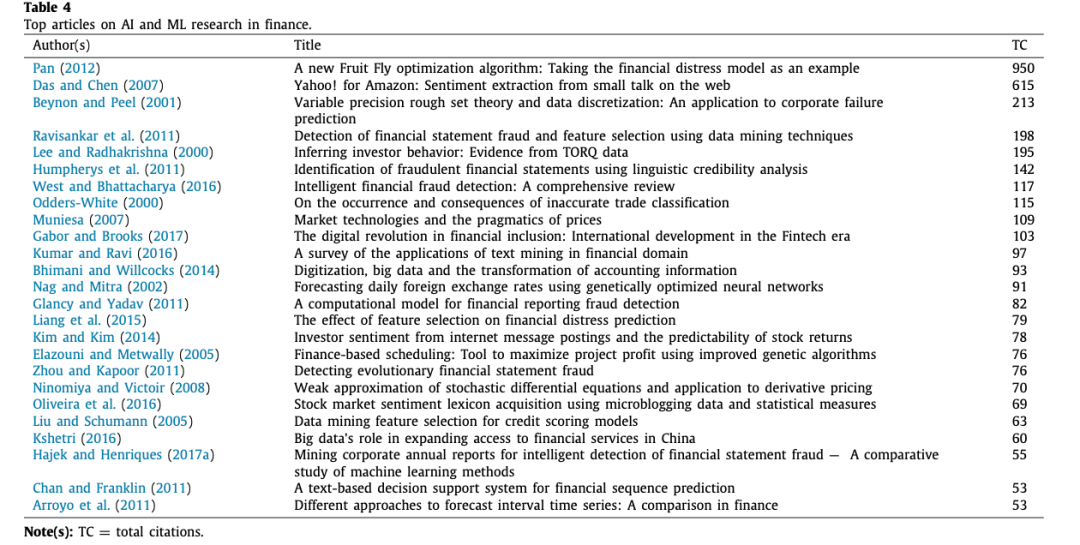
表4中列出了关于金融领域人工智能和ML研究的最高引用率的文章。Pan (2012)是Sco-pus中被引用次数最多的文章(950次),其次是Das和Chen (2007),被引用615次。Pan(2012)提出了一种简单而稳健的优化算法,称为 "果蝇优化",以解决学者们经常争论的优化问题。在对台湾企业的财务困境数据进行测试时,作者发现一般回归神经网络模型的均方根误差值可以很好地达到预期的阈值,同时表现出较高的收敛性、分类和预测能力。Das和Chen(2007)开发了一种方法来对股票留言板上的小投资者的情绪进行分类。作者提供了几种分类器算法,并结合投票方案,证明他们的算法的情绪准确性与更流行的贝叶斯分类器相当。这些提议的算法对于影响评估投资者对管理层公告、第三方新闻、新闻稿和监管变化的意见很有用。对金融领域人工智能和ML的最高引用率的进一步审查显示,财务困境预测(如Liang等人,2015;Pan,2012;)和情绪分析(如Chan和Franklin,2011;Das和Chen,2007;Kim和Kim,2014;Kumar和Ravi,2016;Oliveira等人,2016)领域的研究特别有影响力和影响性。最近,关于金融欺诈预测的人工智能和ML研究引起了学者的极大关注(例如,Glancy和Yadav,2011;Hajek和Hen- riques,2017a;Humpherys等人,2011;Ravisankar等人,2011;West和Bhattacharya,2016;Zhou和Kapoor,2011)。其他有影响的和有影响力的研究领域,如顶级引用的出版物列表所示,包括获得金融服务(Kshetri,2016),资产定价(Muniesa,2007),企业失败预测(Beynon和Peel,2001),信用评分(Liu和Schu- mann,2005),衍生品定价(Ninomiya和Victoir,2008)。金融科技(Gabor和Brooks,2017),外汇汇率预测(Nag和Mitra,2002),投资者行为分析(Lee和Radhakrishna,2000),管理会计信息(Bhi- mani和Willcocks,2014),调度(Elazouni和Metwally,2005),贸易分类(Odders-White,2000),以及波动性预测(Arroyo等人。, 2011).
v) 关于金融领域人工智能和ML研究的顶级参考文献在这一节中,我们更仔细地研究了金融领域的人工智能和ML研究语料库中最常被引用的出版物,以揭示人工智能和ML研究的基础性问题。这一分析也提供了一个机会,以确认在我们的主要搜索中可能被忽略的重要文章,因为它们是小众主题或非金融主题。表5列出了基于本地和全球引文的最高引文出版物。本地引用指的是一篇文章被金融领域的人工智能和ML研究的其他文章所引用的次数。全球引文指的是一篇文章被引用的次数。
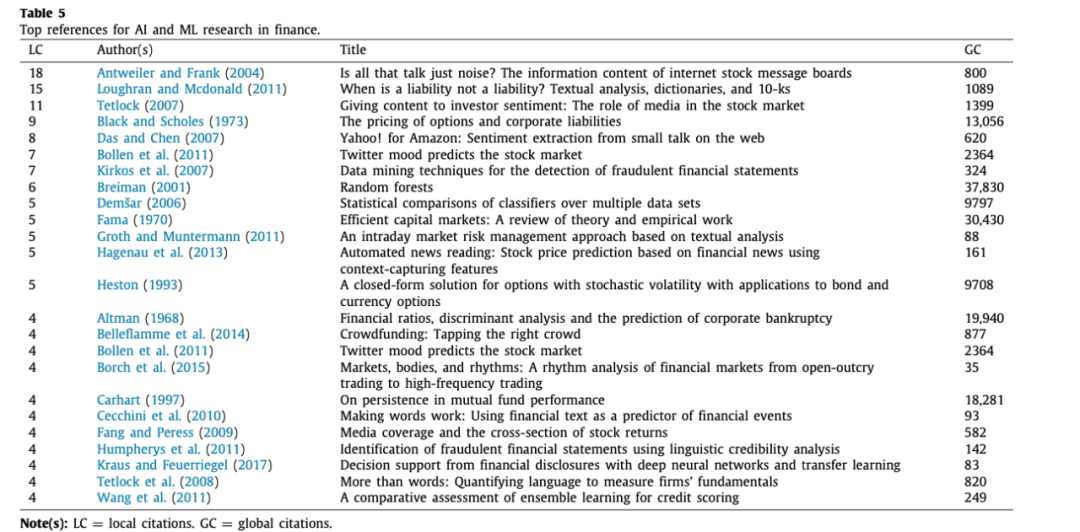
也许在金融领域的人工智能和ML领域之外,一篇文章被金融领域的人工智能和ML文章所引用的次数。在被引用最多的出版物中,Antweiler和Frank(2004)以及Loughran和Mcdonald(2011)分别被引用了18次和15次。Breiman(2001)和Fama(1970)分别以37,830和30,430的引用率在我们的全球引用研究列表中占主导地位。关于市场效率的半成品文章,虽然明显是切题的,但研究金融领域人工智能和ML的研究人员在制定定价和估值的假设时广泛引用了Fama(1970)这篇开创性的市场效率文章(例如,Feuerriegel和Gordon,2018;Li等人,2018;Yang等人,2018)。Antweiler和Frank(2004)对雅虎财经和愤怒的公牛发布的150多万条互联网股票信息进行了情绪分析,这些信息涉及道琼斯工业平均指数中的45家公司。作者发现,关于一只股票的较高的信息发布可以预测其随后的负收益,导致市场波动,尽管这种影响在经济上是很小的。他们的研究也成功地激励了新的研究,分析了他们研究中的情绪特点(例如,Das和Chen,2007;Hill和Ready-Campbell,2011;Kim和Kim,2014;Kumar和Ravi,2016;Oliveira等人,2016)。Loughran和Mcdonald(2011)证明,在金融生态学的专门语境中,《哈佛词典》中表示的否定词是有功能的非否定词。他们建立了一个此类负面词汇与金融情感的对应分类。作者提出的这个新分类已被应用于本评论的语料库中的股指预测研究(Feuerriegel和Gordon,2018)、企业报告的自然语言处理研究(Lewis和Young,2019)和财务困境预测研究(Tang等人,2020)。Breiman(2001)的文章在我们的榜单中名列前茅,具有最高的全球影响力,是bootstrap ag-gregation概念的延伸。作者提出了一种新的随机森林算法来克服分类准确度的问题,这种想法在金融领域得到了广泛的应用,尤其是在处理分类问题的研究,如金融欺诈的检测(如Hajek和Henriques,2017a)和客户流失的预测(如Shirazi和Mohammadi,2019)。II. 金融领域人工智能和ML研究的知识和影响结构
i) 通过共同引文分析,金融领域人工智能和ML研究的知识基础通过共引分析发现的共引参考文献的语义关联描绘了该领域的知识基础(Donthu等人,2021;Small,1973)。图2展示了被评论语料库中的文章至少引用三次的参考文献的共引图。
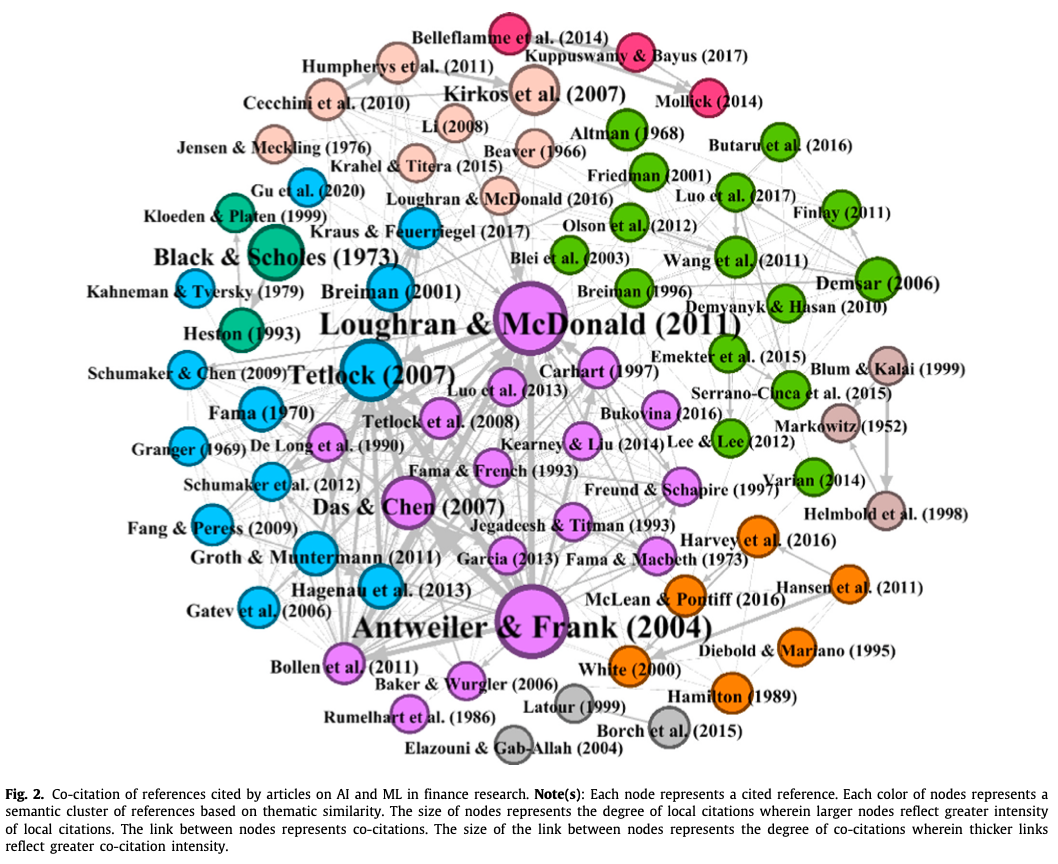
总体而言,共同引用的参考文献的共同引用分析显示,金融领域的人工智能和ML研究借鉴了九个基础集群的现有研究,即资产定价和估值(紫色节点)、文本挖掘和情感分析(蓝色节点)、期权定价和估值(深绿色节点)。金融欺诈检测分析(粉色节点)、众筹(红色节点)、金融风险、信用风险、企业倒闭和破产(瓶绿色节点)、投资组合优化(桃色节点)、预测分析(橙色节点)以及算法和高频交易(灰色节点)。有趣的是,最大的基础集群与资产定价和估值(紫色节点),文本挖掘和情感分析(蓝色节点),以及金融风险,信贷风险,企业倒闭和破产(瓶绿色节点)有关。进一步研究这些主题分组,我们发现这九个基础性集群汇聚成三个总体性的国家集群。具体来说,深绿色、灰色、紫色、红色和桃色节点汇聚为金融资产来源、估值和优化,而瓶绿色和粉红色节点汇聚为金融欺诈、风险和失败,蓝色和橙色节点汇聚为推断情绪和预测。这些总体性的基础集群代表了金融领域人工智能和ML研究的知识基础。ii) 通过书目耦合识别金融领域人工智能和ML研究的主题集群在前一节发现的知识基础上,我们通过书目耦合进一步研究与金融领域人工智能和ML研究相关的知识体系。与共引分析不同的是,共引分析考虑的是被引用的出版物,从而反映出专注于该领域高引用率出版物的开创性知识(Donthu等人,2021),书目耦合依赖于引用出版物来解释该领域的现存知识(Kessler,1963)。在这个意义上,书目图谱耦合囊括了开创性的、利基的和最新的知识-边缘。因此,它突出了那些可以理解为还没有得到很多引用的作品,因此很可能在共同引用分析中被忽略(Donthu等人,2021)。在关于金融研究的文献计量审查中,书目耦合已经成为一种既定的技术(例如,Baker等人,2021;Pattnaik等人,2020a,b)。九个主题集群的概述,支撑着人工智能和ML研究的知识结构。表6列出了通过书目耦合揭示的金融领域人工智能和ML研究的九个主题群。
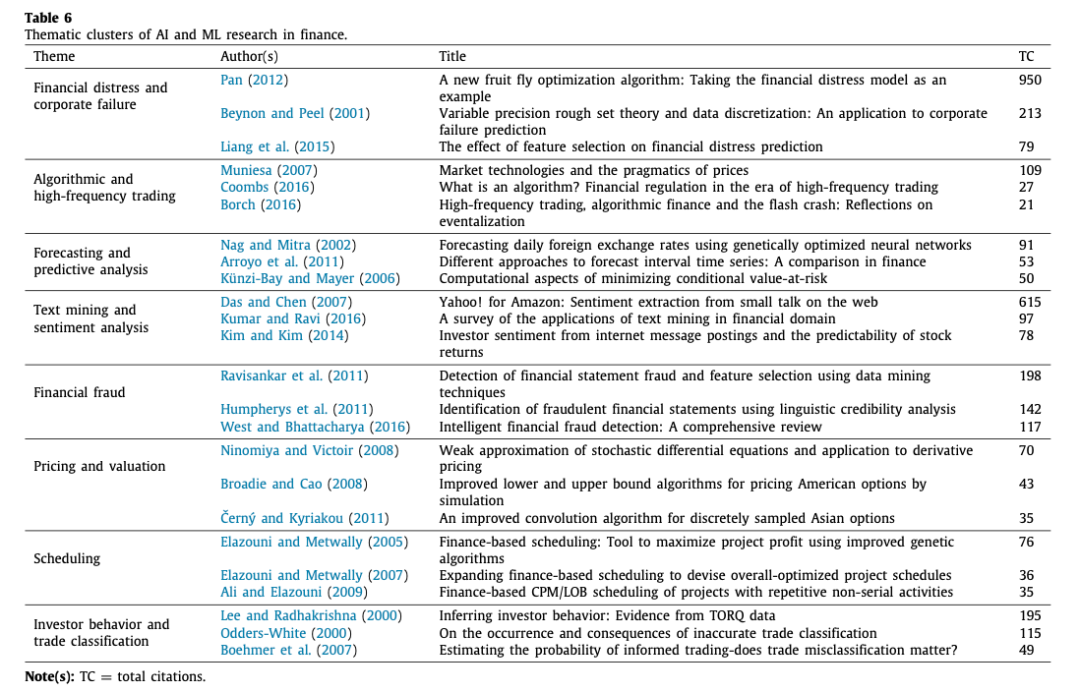
第一组由50篇关于财务困境和企业失败的文章组成,根据Scopus的数据,这些文章被引用了1874次。该群组中被引用次数最多的三篇文章是Pan(2012)、Beynon和Peel(2001)以及Liang等人(2015),引用次数分别为950、213和79次。如前所述,Pan(2012)开发了将果蝇优化算法应用于财务困境数据。Beynon和Peel(2001)通过修正的可变精度粗糙集(VPRS)模型研究了英国公司的失败预测。有趣的是,虽然粗糙集理论是一种基于决策的技术,自1982年以来一直存在,但以前对其在金融研究中的实证有效性知之甚少。重要的是,VPRS与经典的Logit多变量判别规则分析和非参数决策树方法的比较结果表明其在涉及分类的预测问题上具有实用性。Liang等人(2015)在金融困境预测的背景下研究了基于过滤器和包装器的特征选择方法的影响。通过将三种基于过滤器和两种基于包装器的特征选择方法与其他六种预测模型一起,作者比较了特征选择对预测模型的影响。对四个不同数据集的分析结果表明,在特征选择方法中没有最佳组合。进行特征选择并不一定能提高预测性能,即使逻辑回归和遗传算法似乎能在数据集上提供更好的预测结果。第二组由23篇关于算法和高频交易的文章组成,根据Scopus,这些文章被引用了275次。该群组中被引用次数最多的三篇文章是Muniesa(2007)、Coombs(2016)和Borch(2016),引用次数分别为109、27和21次。特别是,Muniesa(2007)通过研究产生收盘价的技术配置,扩展了Peirce的收盘价迹象理论。作者主张务实地采用算法进行定价和估值--类似于高频交易算法,这些算法经常被指责为操纵市场,以及重新被指责的闪电崩盘。库姆斯(2016)建议,给算法贴上规则标签,为交易公司建立道德准则。这样的规定可能会阻碍闪崩事件的发生 Borch(2016)深入研究了闪崩事件导致散户投资者对技术反感的关键性问题。第三组由67篇关于预测和预测分析的文章组成,被引用了631次。该群组中被引用次数最多的三篇文章是Nag和Mitra(2002),Arroyo等人(2011),以及Künzi-Bay和Mayer(2006),分别被引用91次、53次和50次。Nag和Mitra(2002)承认各种经典计量经济学模型在预测货币汇率方面的失败,主张采用基于神经网络和遗传算法的混合人工智能技术。这种算法被证明在与各种非线性统计模型的比较中具有优势。Arroyo等人(2011)在比较了VAR、指数平滑、多层感知器和K-NN算法的方法后,提出了一种预测区间时间序列波动的新方法。考虑到通过最小化风险条件值进行优化的问题,Künzi-Bay 和 Mayer(2006)提出了一种两阶段的随机编程方法。他们提出的算法在涉及五个随机变量的投资组合优化问题中优于预期。它的比较效力由一个涉及50个变量的随机生成的测试来证明。第四组由33篇关于文本挖掘和情感分析的文章组成,被引用了1260次。该群组中被引用次数最多的三篇文章是Das和Chen(2007)、Kumar和Ravi(2016)以及Kim和Kim(2014),分别被引用了615次、97次和78次。Das和Chen(2007)提出了一种与投票方案相结合的算法,从股票留言板中提取情绪。该算法实现了与广泛使用的贝叶斯分类器相类似的准确度,而且假阳性的程度较低。Kumar和Ravi(2016)对文本挖掘在金融领域的各种应用提供了全面的再认识,如外汇交易、股票市场的预测、客户关系管理和网络安全。Kim和Kim(2014)分析了雅虎金融中报告的3200万条信息,研究这些信息是否可以预测股票收益、交易量和波动性。作者确定,投资者情绪与股票价格表现呈正相关关系。第五组由29篇关于金融欺诈的文章组成,被引用了903次(Scopus)。该群组中被引用次数最多的三篇文章是Ravisankar等人(2011)、Humpherys等人(2011)以及West和Bhattacharya(2016),引用次数分别为198、142和117。Ravisankar等人(2011)应用一系列的数据挖掘方法(多层前馈神经网络、遗传编程、支持向量机、数据处理的分组方法、概率神经网络、逻辑回归)来追踪进行财务报表欺诈的公司。作者的结论是概率神经网络优于不涉及特征选择的技术,而遗传编程和概率神经网络优于所有其他涉及特征选择的技术。Humpherys等人(2011年)研究了管理性金融欺诈中的语言线索,发现欺诈性披露往往是字斟句酌、形象化的,与较少的词汇多样性相关,并使用更多的激活语言。West和Bhattacharya(2016)通过对金融欺诈检测研究的回顾,阐明了基于计算智能的金融欺诈检测技术。第六组由39篇关于定价和估值的文章组成,在Scopus中被引用了423次。该群组中被引用次数最多的三篇文章是Ninomiya和Victoir(2008)、Broadie和Cao(2008)以及Černý和Kyriakou(2011),引用次数分别为70、43和35次。Ninomiya和Victoir(2008)提出了一种二阶算法,并发现该算法有效地逼近了Heston随机波动率模型下的亚洲期权定价的弱随机微分方程。相比之下,Broadie和Cao(2008)引入了一种新的方差减少算法,并对美式期权定价的蒙特卡罗方法进行了计算上的改进。而Černý和Kyriakou(2011)提出了一种改进的FFT定价算法,用于亚洲期权的定价,并以有限差分、前向密度卷积算法和蒙特卡洛模拟为基准。第七组和第八组,分别由三篇关于调度和投资者行为以及交易分类的文章组成,在Scopus中分别被引用147次和359次。这些群组中被引用次数最多的文章是Elazouni和Met- wally(2005)以及Lee和Radhakrishna(2000)。Elazouni和Metwally(2005)应用遗传算法技术来开发基于财务的时间表,通过最小化融资和间接成本来最大化建设项目的盈利能力。Lee和Radhakrishna(2000)从交易数据中校准了几种技术来对投资者的行为进行预测。他们开发了一个针对公司的交易规模的代理,该代理被证明在分离机构和个人投资者的交易活动方面非常有效。他们的发现对于在分析市场交易时考虑买入和卖出的决定是很有用的。有趣的是,我们观察到,我们通过书目耦合确定的八个主题集群向三个总体主题集群靠拢,这些集群与使用共同引用分析确定的基础集群非常相似。具体来说,第2、6和8个聚类是金融资产和投资者行为,而第1和5个聚类是金融困境、欺诈和失败,第3、4和7个聚类是推断情绪、预测和规划。综合来看,这些总体性的主题集群代表了金融领域人工智能和ML研究的知识体系和主题。iii) 通过共现分析探讨金融领域人工智能和ML研究的主题趋势在共同引文分析和书目耦合所揭示的基础和主题的基础上,本节我们通过共同发生分析进一步探索金融领域人工智能和ML研究的主题趋势。共同发生分析是利用作者的关键词(即作者在其文章中列出的关键词)进行的。这些关键词通过一个时间长度来揭示在我们的评论语料库中至少有两篇文章出现的金融主题的演变。图3-7中报告了这种主题演变。在这些图中,主题(专题)与平均出版年份(APY)同时呈现,后者被认为是主题趋势的指标(Andersen,2019;Pattnaik等人,2021)。具体来说,APY表示为
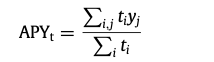
2020年出现三篇,2021年出现四篇,那么它的APY值就是2020.2[即(2X2019)+(3X2020)+(4X2021)/9]。图3-7,我们看到在APY 1986.0和2009.0(图3),金融领域的人工智能和ML研究集中在算法和高频交易上,包括建筑管理、财务管理和调度(深绿色节点);涉及不完全市场、数学金融和随机模型的定价和估值(瓶绿色节点);使用反向传播和马尔科夫切换模型的投资组合优化(橙色节点);以及与粗糙集理论和交易成本分析相结合的文本挖掘和感官分析(紫色节点)。在APY 2009.1和2012.0之间(图4),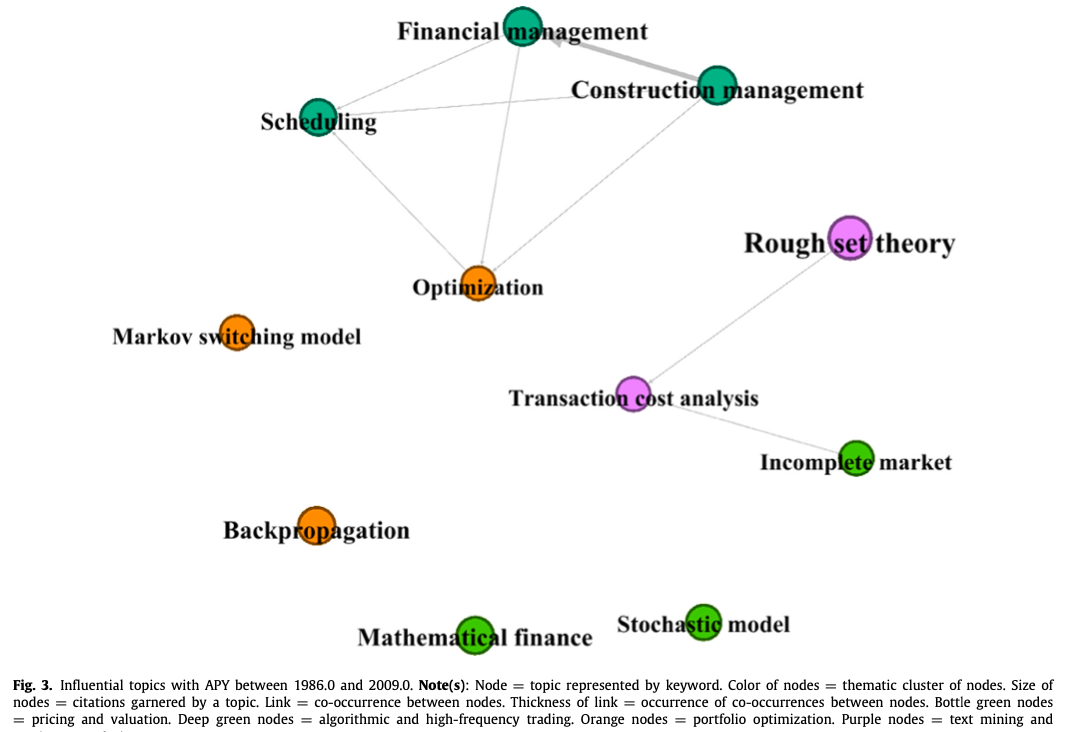
金融领域的人工智能和ML研究主要集中在一系列的定价和估值主题上,如资产定价、对冲、期权定价和风险价值,使用了应用数学金融、数学编程算法、数值算法、前景理论、随机差分方程和随机金融模型(瓶装绿色节点)。这一时期的研究还揭示了基于遗传算法、投资者行为和神经网络的投资组合操作(橙色节点);利用参数估计和文本分类的风险预测和预测分析(黑色节点);以及用于股票预测的文本挖掘和情感分析(紫色节点)。在APY 2012.1和2015.0之间(图5),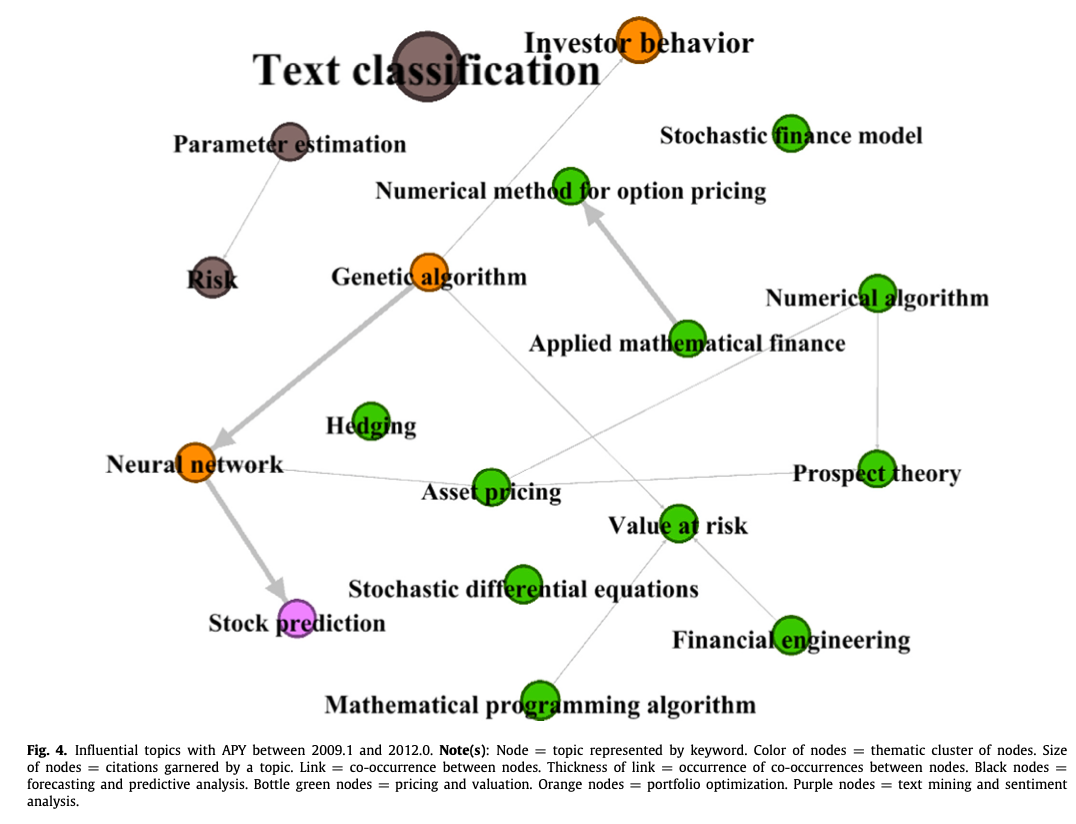
金融领域的人工智能和ML研究强调定价和估值主题,如美式期权、期权定价和投资组合优化,以及一系列技术,如Black Scholes和其他衍生品定价模型、金融数学、自由边界问题、Heston建模、蒙特卡洛模拟和波动率表面问题(瓶子绿色节点)。这一时期的研究重点是利用贝叶斯网络和EM算法对银行业务、外汇、违约和运营风险进行投资组合优化(橙色节点);对金融欺诈和财务报表欺诈进行文本挖掘和情感分析,以及利用分类、数据挖掘、特征选择和模拟技术进行客户关系管理(紫色节点)。算法和高频交易,通过社会视角与算法相结合(深绿色节点);保险和市场效率的预测和预报分析(黑色节点);以及投资的大数据分析和金融科技(蓝色节点)。在APY2015.1和2018.0之间(图6),
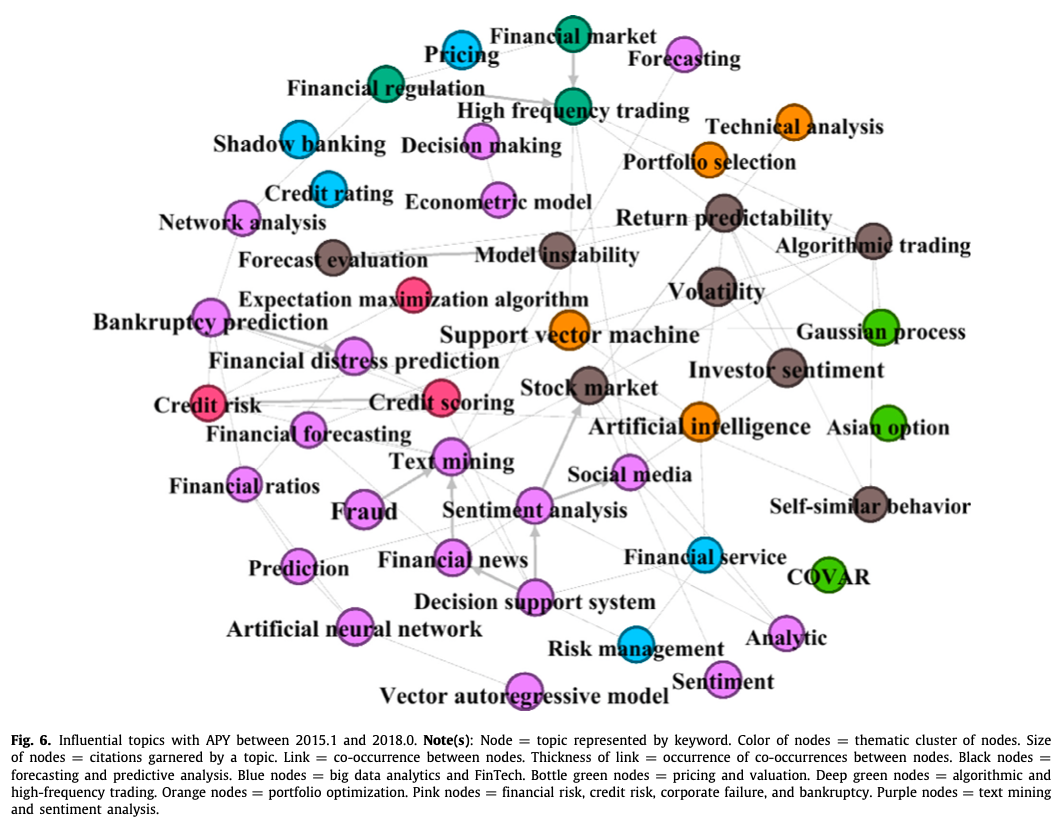
金融领域的AI和ML研究主要集中在对金融新闻、财务比率和社交媒体的文本挖掘和情感分析,主题包括破产预测、财务困境预测、欺诈和决策等,并结合人工神经网络、计量经济学建模和网络分析(紫色节点)。这一时期在金融领域的人工智能和ML的再搜索还研究了投资者情绪、股票市场、与算法交易相关的回报波动性、预测评估和自相似行为(黑色节点);大数据分析和金融科技涉及信用评级、金融服务、定价、风险管理和影子银行(蓝色节点)。使用COVAR和高斯过程对亚洲期权进行定价和估值(瓶绿色节点);金融市场和金融监管背景下的算法和高频交易(深绿色节点);以及使用AI、支持向量机和技术分析进行投资组合优化(橙色节点)。
在APY 2018.1和2021.0之间(图7),

金融领域的AI和ML研究强调大数据分析和FinTech,涉及行为金融、区块链、商业银行、企业金融、众筹、加密货币、数字化、数字转型、首次代币发行、创新、金融化、金融包容性、融资成功因素、互联网金融、P2P贷款、软信息、使用贝叶斯方法、大数据和数据分析的供应链金融(蓝色节点)。7),金融领域的AI和ML研究强调大数据分析和FinTech,涉及行为金融、区块链、商业银行、企业金融、众筹、加密货币、数字化、数字转型、首次代币发行、创新、金融化、金融包容性、融资成功因素、互联网金融、P2P贷款、软信息、使用贝叶斯方法、大数据和数据分析的供应链金融(蓝色节点)。以及利用数据可视化、深度学习、高频数据、Lévy、自然语言处理、ML、网络分析、强化学习、统计套利和文本分析对年度报告、经济政策和股票指数进行文本挖掘和情感分析,用于消费金融、早期预警、金融风险评估和交易策略(紫色节点)。这一时期的研究重点是利用GDPR、在线ML、粒子群优化、机器人顾问和弱聚合算法对在线和通用投资组合进行优化。在其他领域中,金融风险、信用风险、企业倒闭和破产涉及违约预测、小额贷款和中小企业使用文献分析(粉色节点);而预测性分析使用基于代理的建模(黑色节点)。结果表明,早期金融领域的人工智能和ML研究零星地分布在算法和高频交易、投资组合优化、定价和估值以及文本挖掘和情感分析等主题上(APY 1986.0和2009.0)。后来,在更近的时期,涉及人工智能和ML与金融的研究更多集中在定价和估值(APY 2009.1和2015.0之间),文本挖掘和情感分析(APY 2015.1和2021.0之间),以及大数据分析和金融科技(APY 2018.1和2021.0之间)。iv) 金融领域的人工智能和ML研究的主题和方法的汇合在通过共同引用分析、书目耦合和共同发生分析的视角对金融领域的人工智能和ML研究进行映射的基础上,本节研究了研究主题和研究方法的并列关系。交叉分析 表7列出了金融、人工智能和ML中经常被研究的主题与研究方法的交叉对比。在表7中,主题是根据我们在前几节的结果确定的。本表中表示的频率并不相互排斥,因为在一项研究中应用一些ML技术来评估一种技术比另一种技术的优越性是很常见的。
一般来说,我们观察到人工智能、有监督的ML和NLP已被广泛用于预测分析和预测,尽管这一趋势最近正转向大数据分析和深度学习(例如,Craja等人,2020;Li和Tang,2020;Tang等人,2020;Uthayakumar等人,2020)。Craja等人(2020)应用层次注意网络(HAN)来分析年度报告中管理层讨论部分的文本特征,其中模型的架构既能捕捉到管理层评论的内容,也能捕捉到其背景,因此,作为检测欺诈性报告的补充预测因素。Li和Tang(2020)提出了一个综合小波变换、滤波周期分解和多拉格神经网络(WT- FCD-MLGRU)模型,在股指预测建模中产生最小的预测误差。
Uthayakumar等人(2020)提出了一个蚂蚁群优化(ACO)金融危机预测(FCP)模型,该模型结合了特征选择和数据分类算法来进行预测。该模型在五个不同的定性和定量数据集上进行了测试,实验结果确立了该算法相对于其他人工智能和传统计量经济学技术的优越性。Tang等人(2020)采用了基于包装的特征选择框架,这是一种混合形式的文本分析,揭示了中国上市公司的财务困境特征,以提供财务风险的早期信号。此外,我们在表8-10中报告了针对有监督和无监督的ML和NLP的金融研究课题。总的来说,我们发现在金融研究中,有监督的ML比无监督的ML技术更受欢迎。我们还观察到,人工神经网络(ANN)算法已被广泛地应用于涉及预测和预报的金融研究。例如,正如已经提到的,Pan(2012)应用果蝇优化算法进行财务困境预测,Feuer- riegel和Gordon(2018)利用与监管披露有关的新闻的预测能力进行股票估值的预测。有趣的是,NLP技术也被广泛应用于金融新闻和媒体报道的预测分析和情感分析(例如,Chan和Franklin,2011;Feuerriegel和Gordon,2018;Hill和Ready-Chambell,2011)。
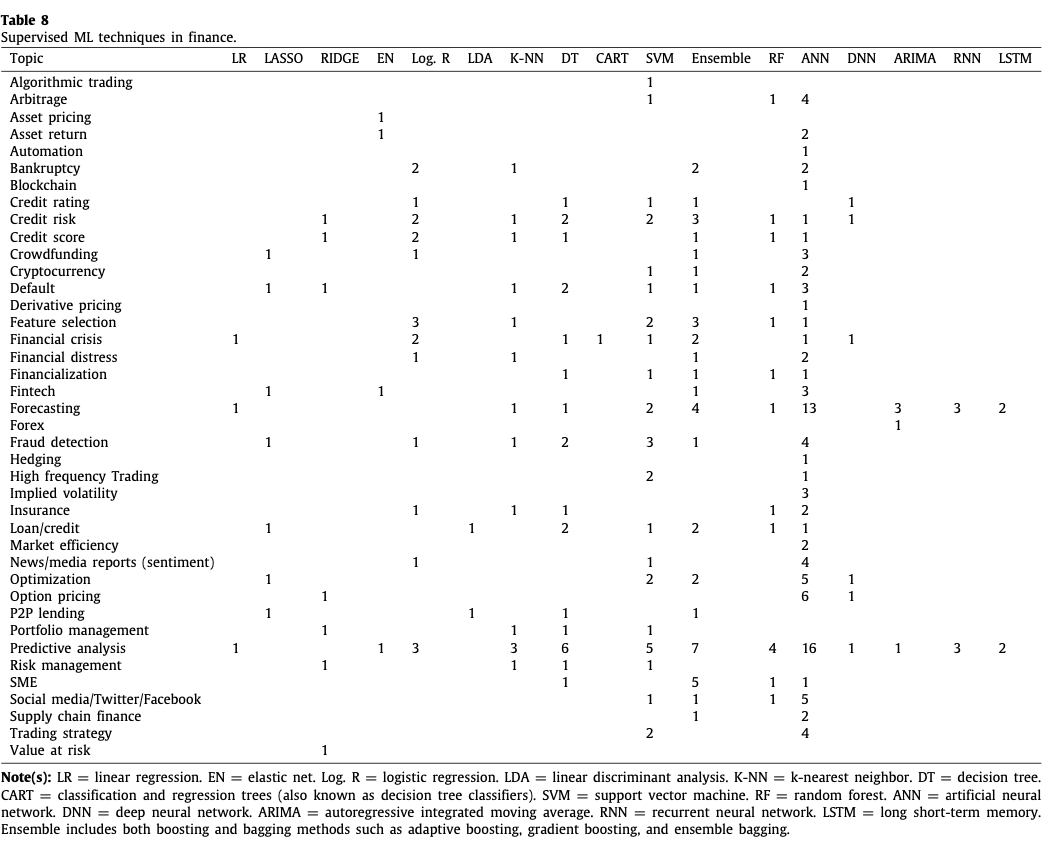
综合来看,汇合分析表明,尽管人工智能和ML确实在金融研究中得到了广泛的应用,但未来研究的途径仍然很多,从表8-10中可以看出的研究主题和方法的差距。 我们希望我们的发现和回顾将促进人工智能和ML研究在金融领域有意义的进展。在接下来的章节中,我们概述了未来研究的几个潜在方向。根据Dixon等人(2020年)的研究,金融领域的人工智能和ML被置于几个新兴学科和成熟学科的交叉点,如动态编程、金融经济计量学、模式识别、概率编程和统计计算。在大型数据集的计算能力提高的推动下,ML已经发展成为一个核心的计算工程领域,通过开放资源使即插即用的算法民主化(Corbet等人,2021)。显然,随着人工智能和ML渗透到金融业的广阔领域,学术研究的需求和机会都非常大。资产定价方面的金融研究正朝着经验驱动的模型发展,其中包括应用更丰富的公司特定因素集。这方面的背景包括通过对预期收益进行综合分析,对市场股票风险溢价的动态进行建模(Gu等人,2020)。Harvey等人(2016)探索了316个共同和公司特定的因素来描述股票回报行为。由于风险溢价的评估或对未来超额收益预期的测量是预测分析的一个基本问题,能够可靠地归因于超额收益的方法提供了效用。在这方面,ML提供了非线性的经验方法来模拟公司特征的可实现的资产回报。将神经网络投向典型的资产定价研究,未来有机会构建资产定价模型的研究。人工智能和ML与大数据的兴起导致了金融科技行业的诞生,该行业包括数字创新和技术支持的金融创新商业模式(Dixon等人,2020)。金融科技的核心创新实例包括区块链和加密货币、数字咨询和交易系统、股权众筹、点对点借贷和移动支付服务。此外,机器人顾问等创新,可以提供投资组合管理服务和财务咨询,而不需要大量的人力发明。然而,需要更多的研究来了解金融科技的无数方面以及人工智能和ML在这个新领域的影响。众所周知,金融犯罪是一个具有巨大经济意义的全球性问题。检测金融欺诈,或通过设计警报模型来预防金融欺诈,为金融系统提供了人工智能和ML的巨大效用。Naïve Bayes模型和支持向量机是欺诈检测中的两种有效方法(Ravisankar等人,2011)。此外,电子交易的兴起将可能导致更新的市场操纵和金融欺诈形式。因此,电子交易的变化和交易将需要被仔细检查,以有效地应对新的金融欺诈威胁。这一领域的新发展也可能包括对区块链安全的研究,或许还有对区块链的监督。金融科技的发展无疑将推动使用人工智能和ML的研究,以调查金融欺诈的主题。七,研究结论
了解机器可读数据的应用对金融系统和金融研究都有影响。例如,金融服务业越来越依赖计算方法,在复杂的硬件和软件进步的支持下,高功率计算使机器能够建立高维复杂模型,从而对新信息进行强有力的评估。特别是,人工智能和ML的采用正从根本上改变着交易和投资决策。同时,金融研究也在回应更好地理解人工智能和ML的经济影响的需要。此外,金融研究也正在发现人工智能和ML程序的效用,作为进一步调查既定主题和研究问题的工具。人工智能(AI)和机器学习(ML)是在金融学术界出现的两种新技术。然而,到目前为止,还没有一篇评论对这一研究进行全面的回顾,而鼓励金融学术界提高我们对人工智能和ML对金融系统的影响的理解是重要的需求。为了解决这个问题,我们概述了金融领域的人工智能和ML研究。利用共同引用和文献计量学分析,我们推断了1986-2021年4月金融领域人工智能和ML研究的知识和主题结构。通过发现9个(共同引用)和8个(文献计量学耦合)应用人工智能和ML的具体金融领域,我们进一步确定了对两种分析形式大致相当的三个金融学术集群:(1)投资组合构建、估值和投资者行为;(2)金融欺诈和困境;以及(3)敏感性推理、预测和规划。此外,利用共同发生和汇合分析,我们强调了金融研究中有关人工智能和ML的趋势和研究方向。我们的结果为研究人员提供了指导,以评估金融研究中对人工智能和ML的日益重视。
关于机器学习,参看:1.机器学习之KNN分类算法介绍: Stata和R同步实现(附数据和代码),2.机器学习对经济学研究的影响研究进展综述,3.回顾与展望经济学研究中的机器学习,4.
最新: 运用机器学习和合成控制法研究武汉封城对空气污染和健康的影响! 5.Top, 机器学习是一种应用的计量经济学方法, 不懂将来面临淘汰危险!6.Top前沿: 农业和应用经济学中的机器学习, 其与计量经济学的比较, 不读不懂你就out了!7.前沿: 机器学习在金融和能源经济领域的应用分类总结,8.机器学习方法出现在AER, JPE, QJE等顶刊上了!9.机器学习第一书, 数据挖掘, 推理和预测,10.从线性回归到机器学习, 一张图帮你文献综述,11.11种与机器学习相关的多元变量分析方法汇总,12.机器学习和大数据计量经济学, 你必须阅读一下这篇,13.机器学习与Econometrics的书籍推荐, 值得拥有的经典,14.机器学习在微观计量的应用最新趋势: 大数据和因果推断,15.R语言函数最全总结, 机器学习从这里出发,16.
机器学习在微观计量的应用最新趋势: 回归模型,17.机器学习对计量经济学的影响, AEA年会独家报道,18.回归、分类与聚类:三大方向剖解机器学习算法的优缺点(附Python和R实现),19.关于机器学习的领悟与反思,
20.机器学习,可异于数理统计,21.前沿: 比特币, 多少罪恶假汝之手? 机器学习测算加密货币资助的非法活动金额! 22.利用机器学习进行实证资产定价, 金融投资的前沿科学技术! 23.全面比较和概述运用机器学习模型进行时间序列预测的方法优劣!24.用合成控制法, 机器学习和面板数据模型开展政策评估的论文!25.更精确的因果效应识别: 基于机器学习的视角,26.
一本最新因果推断书籍, 包括了机器学习因果推断方法, 学习主流和前沿方法,27.如何用机器学习在中国股市赚钱呢? 顶刊文章告诉你方法!28.机器学习和经济学, 技术革命正在改变经济社会和学术研究,29.世界计量经济学院士新作“大数据和机器学习对计量建模与统计推断的挑战与机遇”,30.机器学习已经与政策评估方法, 例如事件研究法结合起来识别政策因果效应了!31.重磅! 汉森教授又修订了风靡世界的“计量经济学”教材, 为博士生们增加了DID, RDD, 机器学习等全新内容!32.几张有趣的图片, 各种类型的经济学, 机器学习, 科学论文像什么样子?33.机器学习已经用于微观数据调查和构建指标了, 比较前沿!34.两诺奖得主谈计量经济学发展进化, 机器学习的影响, 如何合作推动新想法!35.前沿, 双重机器学习方法DML用于因果推断, 实现它的code是什么?
关于金融学研究,参看:1.2022年诺贝尔经济学奖: 表彰Bernanke, Diamond和Dybvig对银行和金融危机的研究贡献,2.基于文本大数据分析的会计和金融研究综述, 附24篇相关讲解文章!
3.一篇说“可能重新改写经济学基本公式和金融数学推算”的投稿,4.中文顶刊上关于零工经济的研究, 思路和方法借鉴的是这篇金融TOP刊文章?5.从耶鲁到香港, 从金融到历史后, 陈志武教授第一篇TOP刊文章是OLS+IV组合!6.TOP5刊, 我国政府为什么对金融市场进行定期和密集的干预? 7.中国数字普惠金融的测度及其影响研究: 一个文献综述,8.Top金融,经济与会计期刊中的文本分析, 一项长达2万字的综述性调查,9.经济金融学研究中的大数据革命, 将来的实证研究该何去何从?10.合作者把代码弄丢了! 只能撤稿! 发表在最TOP金融期刊上, 但用代码复制不出结果! 11.金融, 管理和会计, 中国人在哪个领域做得最好呢?基于TOP国际期刊的发现,12.前沿: 大数据对经济金融研究的致命影响, 那又该如何推动这些领域的前沿研究呢?13.华人金融学术女神为运用工具变量估计方法做因果推断的学者提供了如下宝贵建议!14.推荐"数字普惠金融指数", 省市县三级面板数据可做很多实证研究,15.利用机器学习进行实证资产定价, 金融投资的前沿科学技术! 16.金融学文本大数据挖掘方法与研究进展, 金融学者看过来!17.权威前沿: 大数据时代经济学和金融学中的预测方法和实践, 不看就不要提前沿!
18.诺奖得主五因子定价模型的国际检验, 做金融的得学起来了!19.神器! 统计和金融计算器, 词云和情感分析器强大到无敌!20.最全: 深度学习在经济金融管理领域的应用现状汇总与前沿瞻望, 中青年学者不能不关注!21.前沿: 机器学习在金融和能源经济领域的应用分类总结,22.疫情期Wind资讯金融终端操作指南,23.疫情期间CSMAR数据库使用指南!金融财务管理必备数据库!24.金融领域三大中文数据库, CSMAR, CCER, Wind和CNRDS,25.Luigi Zingales: 金融有益于社会吗?26.经济金融领域第一位华人当选美国艺术与科学学院院士,27.时间序列数据分析的思维导图一览, 金融经济学者必备工具,28.研究创意的来源在哪里?顶级国际金融期刊主编如是说,29.金融人如何用好统计分析学, 金融视角下的统计分析,30.金融计量模型:误差修正模型(Error Correction Model,ECM)
推荐一份超级大礼包资源, 里面有丰富的Stata学习材料, 写文章作报告找工作的指南,①
134篇各种方法的code, 代码和程序文章合集, 必须收藏!②今年最诚意的主流计量方法与Stata操作的视频教程, 一定要收藏学习!③《经济研究》期刊上所有文章按照"计量方法"进行分类汇总,有选择性地学习计量方法,④120篇DID双重差分方法的文章合集, 包括代码,程序及解读, 建议收藏!⑤Stata数据管理,绘图,检验,实证方法操作,结果输出的187篇文章!⑥CFPS 2020, CHFS 2019数据都公布了! 最新数据用起来做研究!
下面这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。
4年,计量经济圈近1000篇不重类计量文章,
可直接在公众号菜单栏搜索任何计量相关问题,
Econometrics Circle
计量经济圈组织了一个计量社群,有如下特征:热情互助最多、前沿趋势最多、社科资料最多、社科数据最多、科研牛人最多、海外名校最多。因此,建议积极进取和有强烈研习激情的中青年学者到社群交流探讨,始终坚信优秀是通过感染优秀而互相成就彼此的。











