
大数据文摘出品
编译:朱一辉、雪清、小鱼
短短10行代码就可以实现目标检测?!
本文作者和他的团队构建了一个名为ImageAI 的Python库,集成了现今流行的深度学习框架和计算机视觉库。本文将手把手教你构建自己的第一个目标检测应用,而且文摘菌已经帮你踩过坑了,亲测有效!
无人超市、人脸识别、无人驾驶,众多的使用场景及案例,使得【目标检测】正成为计算机视觉最有前景的方向。
听起来似乎是个很难实现的技术,需要大量训练数据和算法才能完成。事实上,本文作者开发了一个基于Python的函数库,可以用十行代码高效实现目标检测。
还不熟悉的读者,我们先来看看,目标检测到底是什么,以及软件开发人员面临的挑战。
目标检测是借助于计算机和软件系统在图像/场景中,定位目标并识别出每个目标的类别的技术。目前已广泛用于人脸检测、车辆检测、行人计数、网络图像、安全系统和无人驾驶汽车等领域。随着计算机技术不断发展和软件开发人员的不懈努力,未来目标检测技术将更广泛的普及开来。
在应用程序和系统中使用先进的目标检测方法,以及基于这些方法构建新的应用程序并不容易。早期目标检测是基于经典算法而实现的,如 OpenCV(广受欢迎的计算机视觉库)所支持的一些算法。然而,这些经典算法的性能会因条件而受到限制。
2012年,深度学习领域取得众多突破,学者们提出了一系列全新、高精度的目标检测算法和方法,比如R-CNN, Fast-RCNN, Faster-RCNN, RetinaNet,以及既快又准的SSD和YOLO等。要使用这些基于深度学习的方法和算法(当然深度学习也是基于机器学习),需要对数学和深度学习框架有很深的理解。数百万的软件开发人员致力于整合目标检测技术进行新产品的开发。但是想要理解这项技术并加以使用,对非深度学习领域的程序员来说并不容易。
一位自学了计算机的开发者Moses Olafenwa在几个月前意识到了这个问题,并与同伴一起开发了一个名叫ImageAI的Python函数库。
ImageAI可以让程序员和软件开发者只用几行代码,就能轻易地把最先进的计算机视觉技术整合到他们现有的以及新的应用程序里面。
用ImageAI实现目标检测,你只需要以下步骤:
1. 安装Python
2. 安装ImageAI和相关函数库
3. 下载目标检测模型文件
4. 运行示例代码(只有10行)
文摘菌测试环境为Windows 64位系统,Python版本为3.6。在大数据文摘后台回复“检测”可获取代码和模型文件~
1) 从Python官网下载并安装Python 3,并安装pip。
下载地址:
https://python.org
https://pip.pypa.io/en/stable/installing/
2)用pip安装下列依赖
找到Pyhthon安装目录下的Scripts文件夹,如C:\XXX \Python\Python36\Scripts,打开cmd命令窗口,依次输入下列安装命令即可。
1. Tensorflow:
pip install tensorflow
2.Numpy:
pip install numpy
3.SciPy
pip install scipy
4.OpenCV
pip install opencv-python
5.Pillow
pip install pillow
6.Matplotlib
pip install matplotlib
7. H5py
pip install h5py
8. Keras
pip install keras
9. ImageAI
pip install https:
注:在安装ImageAI时如果出现异常,可先下载.whl文件,并放在Scripts文件夹下,用下列命令进行安装:
pip install imageai-2.0.1-py3-none-any.whl
3) 下载用于目标检测的RetinaNet模型文件:
下载地址:
https://github.com/OlafenwaMoses/ImageAI/releases/download/1.0/resnet50_coco_best_v2.0.1.h5
准备工作到此结束,你可以写自己的第一个目标检测代码了。新建一个Python文件并命名(如FirstDetection.py),然后将下述代码写入此文件。接着将RetinaNet模型文件、FirstDetection.py和你想检测的图片放在同一路径下,并将图片命名为“image.jpg”。
下面是FirstDetection.py中的10行代码:
from imageai.Detection import ObjectDetection
import os
execution_path = os.getcwd()
detector = ObjectDetection()
detector.setModelTypeAsRetinaNet()
detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5"))
detector.loadModel()
detections = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"))
for eachObject in detections:
print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
然后,双击FirstDetection.py运行代码,并稍等片刻,识别结果就会在控制台打印出来。一旦结果在控制台输出,在包含FirstDetection.py的文件夹里,你会发现一张新保存的图片,文件名为“imagenew.jpg”。
注:如果运行代码时出现下列异常:
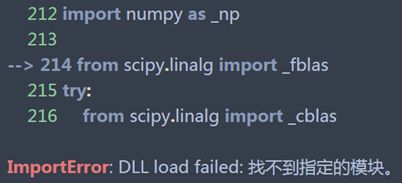
则需要安装Numpy+MKL依赖,下载对应的.whl文件并放在Scripts文件夹下,用pip安装.whl文件即可。
下载地址:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy
来看看下面这2张示例图片以及经过检测后保存的新图片。
检测前:


检测后:
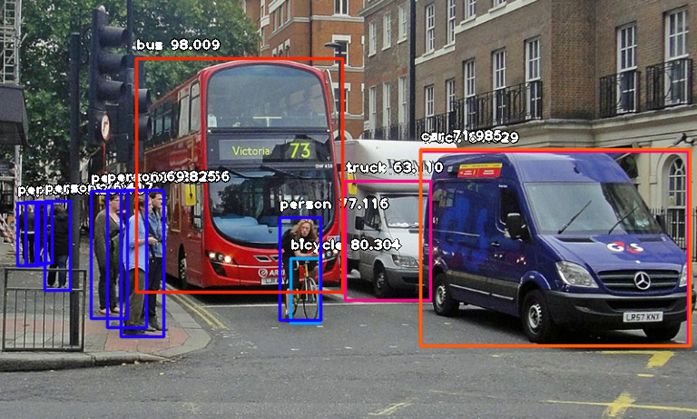
检测结果:
person : 55.8402955532074
person : 53.21805477142334
person : 69.25139427185059
person : 76.41745209693909
bicycle : 80.30363917350769
person : 83.58567953109741
person : 89.06581997871399
truck : 63.10953497886658
person : 69.82483863830566
person : 77.11606621742249
bus : 98.00949096679688
truck : 84.02870297431946
car : 71.98476791381836

检测结果:
person : 71.10445499420166
person : 59.28672552108765
person : 59.61582064628601
person : 75.86382627487183
motorcycle : 60.1050078868866
bus : 99.39600229263306
car : 74.05484318733215
person : 67.31776595115662
person : 63.53200078010559
person : 78.2265305519104
person : 62.880998849868774
person : 72.93365597724915
person : 60.01397967338562
person : 81.05944991111755
motorcycle : 50.591760873794556
motorcycle : 58.719027042388916
person : 71.69321775436401
bicycle : 91.86570048332214
motorcycle : 85.38855314254761
文摘菌测试了另外几张图片,结果如下:
检测前:



检测后:

检测结果:
car : 59.04694199562073
car : 50.62631368637085
car : 71.59191966056824
car : 52.60368585586548
person : 76.51243805885315
car : 56.73831105232239
car : 50.02853870391846
car : 94.18612122535706
car : 70.23521065711975
car : 75.06842017173767
car : 87.21032738685608
car : 89.46954607963562
person : 73.89532923698425
bicycle : 90.31689763069153
bus : 65.3587281703949
竟然可以检测出牛……
检测结果:
person : 55.15214800834656
person : 62.79672980308533
person : 69.01599168777466
person : 67.26776957511902
person : 75.51649808883667
person : 52.9820442199707
person : 67.23594665527344
person : 69.77047920227051
person : 83.80664587020874
person : 61.785924434661865
person : 82.354336977005
person : 93.08169484138489
cow : 84.69656705856323

检测结果:
person : 65.07909297943115
person : 65.68368077278137
person : 68.6377465724945
person : 83.80006551742554
person : 85.69389581680298
person : 55.40691018104553
person : 56.62997364997864
person : 58.07020664215088
person : 70.90385556221008
person : 95.06895542144775
下面我们来解释一下这10行代码的含义。
from imageai.Detection import ObjectDetection
import os
execution_path = os.getcwd()
上面3行代码中,第一行导入ImageAI的目标检测类,第二行导入Python的os类,第三行定义一个变量,用来保存Python文件、RetianNet模型文件和图片所在文件夹的路径。
detector = ObjectDetection()
detector.setModelTypeAsRetinaNet()
detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5"))
detector.loadModel()
detections = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"))
上面5行代码中,第一行定义目标检测类,第二行将模型类型设置为RetinaNet,第三行将模型的路径设为RetinaNet模型文件所在路径,第四行将模型载入目标检测类,然后第五行调用检测函数,并解析输入图片和输出图片的路径。
for eachObject in detections:
print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
上面2行代码中,第一行迭代所有detector.detectObjectsFromImage函数返回的结果,然后,第二行打印出模型检测出的图片中每个目标的类型和概率。
ImageAI还支持配置目标检测过程中的其他功能。例如,将检测到的每个目标的图片单独提取出来。通过简单地把extract_detected_objects=True写入detectObjectsFromImage函数,目标检测类就会为图片对象集新建一个文件夹,然后提取出每个图片,将它们存入这个文件夹,并返回一个数组用来保存每个图片的路径,如下所示:
detections, extracted_images = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"), extract_detected_objects=True)
我们用第一个示例图片提取出来的检测结果如图所示:

为了满足目标检测的生产需求,ImageAI提供了一些可配置的参数,包括:
Adjusting Minimum Probability(可调整最小概率阈值)
默认阈值为50%,如果检测结果的概率值低于50%,则不显示检测结果。你可以根据具体需求对该阈值进行修改。
Custom Objects Detection(自定义目标检测)
使用提供的CustomObject类,你可以让检测结果只显示特定类型的目标。
Detection Speeds(检测速度)
可以将检测速度设置为“fast”、“ faster”和“fastest”,以减少检测图片所需的时间。
Input Types(输入类型)
你可以解析并修改图像的文件路径,其中,Numpy数组,或是图片文件流都可以作为输入类型。
Output Types(输出类型)
你可以修改detectObjectsFromImage 函数的返回结果,例如返回图片文件或Numpy数组。
详细的说明文档在GitHub上,GitHub链接:
https://github.com/OlafenwaMoses/ImageAI
在大数据文摘后台回复“检测”可获取代码和模型文件~
动手试试吧,欢迎在留言区分享~
相关报道:
https://towardsdatascience.com/object-detection-with-10-lines-of-code-d6cb4d86f606








