支持向量机(SVM)是个非常强大并且有多种功能的机器学习模型,能够做线性或者非线性的分类,回归,甚至异常值检测。机器学习领域中最为流行的模型之一,是任何学习机器学习的人必备的工具。SVM 特别适合复杂的分类,而中小型的数据集分类中很少用到。
本章节将阐述支持向量机的核心概念,怎么使用这个强大的模型,以及它是如何工作的。
线性支持向量机分类
SVM 的基本思想能够用一些图片来解释得很好,图 5-1 展示了我们在第4章结尾处介绍的鸢尾花数据集的一部分。这两个种类能够被非常清晰,非常容易的用一条直线分开(即线性可分的)。左边的图显示了三种可能的线性分类器的判定边界。其中用虚线表示的线性模型判定边界很差,甚至不能正确地划分类别。另外两个线性模型在这个数据集表现的很好,但是它们的判定边界很靠近样本点,在新的数据上可能不会表现的很好。相比之下,右边图中 SVM 分类器的判定边界实线,不仅分开了两种类别,而且还尽可能地远离了最靠近的训练数据点。你可以认为 SVM 分类器在两种类别之间保持了一条尽可能宽敞的街道(图中平行的虚线),其被称为最大间隔分类。
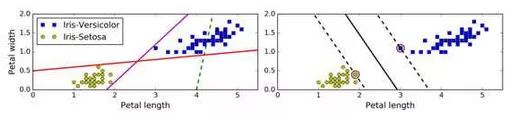
我们注意到添加更多的样本点在“街道”外并不会影响到判定边界,因为判定边界是由位于“街道”边缘的样本点确定的,这些样本点被称为“支持向量”(图 5-1 中被圆圈圈起来的点)
警告
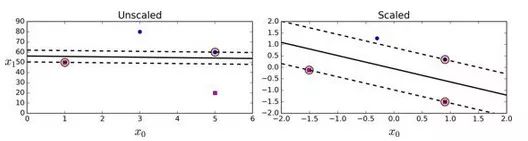
SVM 对特征缩放比较敏感,可以看到图 5-2:左边的图中,垂直的比例要更大于水平的比例,所以最宽的“街道”接近水平。但对特征缩放后(例如使用Scikit-Learn的StandardScaler),判定边界看起来要好得多,如右图。
软间隔分类
如果我们严格地规定所有的数据都不在“街道”上,都在正确地两边,称为硬间隔分类,硬间隔分类有两个问题,第一,只对线性可分的数据起作用,第二,对异常点敏感。图 5-3 显示了只有一个异常点的鸢尾花数据集:左边的图中很难找到硬间隔,右边的图中判定边界和我们之前在图 5-1 中没有异常点的判定边界非常不一样,它很难一般化。
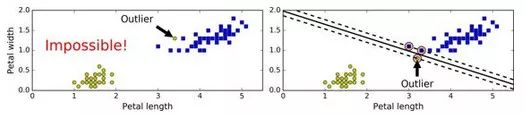
为了避免上述的问题,我们更倾向于使用更加软性的模型。目的在保持“街道”尽可能大和避免间隔违规(例如:数据点出现在“街道”中央或者甚至在错误的一边)之间找到一个良好的平衡。这就是软间隔分类。
在 Scikit-Learn 库的 SVM 类,你可以用C超参数(惩罚系数)来控制这种平衡:较小的C会导致更宽的“街道”,但更多的间隔违规。图 5-4 显示了在非线性可分隔的数据集上,两个软间隔SVM分类器的判定边界。左边图中,使用了较大的C值,导致更少的间隔违规,但是间隔较小。右边的图,使用了较小的C值,间隔变大了,但是许多数据点出现在了“街道”上。然而,第二个分类器似乎泛化地更好:事实上,在这个训练数据集上减少了预测错误,因为实际上大部分的间隔违规点出现在了判定边界正确的一侧。
提示
如果你的 SVM 模型过拟合,你可以尝试通过减小超参数C去调整。
以下的 Scikit-Learn 代码加载了内置的鸢尾花(Iris)数据集,缩放特征,并训练一个线性 SVM 模型(使用LinearSVC类,超参数C=1,hinge 损失函数)来检测 Virginica 鸢尾花,生成的模型在图 5-4 的右图。
import numpy as np
from sklearn import datasets
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris["data"][:, (2, 3)] # petal length, petal width
y = (iris["target"] == 2).astype(np.float64) # Iris-Virginica
svm_clf = Pipeline((
("scaler", StandardScaler()),
("linear_svc", LinearSVC(C=1, loss="hinge")),
))
svm_clf.fit(X_scaled, y)
Then, as usual, you can use the model to make predictions:
>>> svm_clf.predict([[5.5, 1.7]])
array([ 1.])
注
不同于 Logistic 回归分类器,SVM 分类器不会输出每个类别的概率。
作为一种选择,你可以在 SVC 类,使用SVC(kernel="linear", C=1),但是它比较慢,尤其在较大的训练集上,所以一般不被推荐。另一个选择是使用SGDClassifier类,即SGDClassifier(loss="hinge", alpha=1/(m*C))。它应用了随机梯度下降(SGD 见第四章)来训练一个线性 SVM 分类器。尽管它不会和LinearSVC一样快速收敛,但是对于处理那些不适合放在内存的大数据集是非常有用的,或者处理在线分类任务同样有用。
提示
LinearSVC要使偏置项规范化,首先你应该集中训练集减去它的平均数。如果你使用了StandardScaler,那么它会自动处理。此外,确保你设置loss参数为hinge,因为它不是默认值。最后,为了得到更好的效果,你需要将dual参数设置为False,除非特征数比样本量多(我们将在本章后面讨论二元性)
非线性支持向量机分类
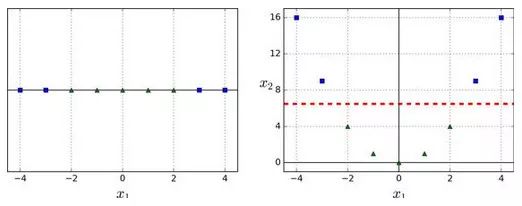
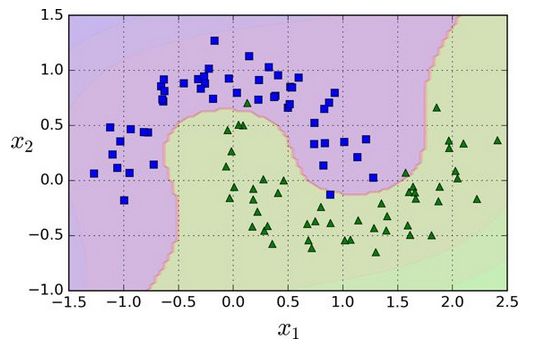
尽管线性 SVM 分类器在许多案例上表现得出乎意料的好,但是很多数据集并不是线性可分的。一种处理非线性数据集方法是增加更多的特征,例如多项式特征(正如你在第4章所做的那样);在某些情况下可以变成线性可分的数据。在图 5-5的左图中,它只有一个特征x1的简单的数据集,正如你看到的,该数据集不是线性可分的。但是如果你增加了第二个特征 x2=(x1)^2,产生的 2D 数据集就能很好的线性可分。
为了实施这个想法,通过 Scikit-Learn,你可以创建一个流水线(Pipeline)去包含多项式特征(PolynomialFeatures)变换(在 121 页的“Polynomial Regression”中讨论),然后一个StandardScaler和LinearSVC。让我们在卫星数据集(moons datasets)测试一下效果。
from sklearn.datasets import make_moons
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
polynomial_svm_clf = Pipeline((
("poly_features", PolynomialFeatures(degree=3)),
("scaler", StandardScaler()),
("svm_clf", LinearSVC(C=10, loss="hinge"))
))
polynomial_svm_clf.fit(X, y)
想要了解更多资讯,请扫描下方二维码,关注机器学习研究会

转自:人工智能爱好者社区











