AI前线导读:去年我们发布了基于 Python 的共指解析包之后,社区反馈非常热烈,大家开始在各式应用中使用它,有些应用场景与我们原来的对话用例非常不一样。
之后我们发现,虽然这个解析包的性能对于对话消息来说是足够的,但涉及到大篇幅新闻文章时就远远不够了。
更多干货内容请关注微信公众号“AI前线”,(ID:ai-front)
所以我决定好好处理这个问题,最后开发出了比之前版本(每秒几千单词)性能提升百倍的 NeuralCoref v3.0(https://github.com/huggingface/neuralcoref) ,同时还保持了同样水准的准确性和易用性。
本文中,我会分享在这个项目上总结的一些经验,重点包括:
这里我耍了点小花招,因为我们既要谈论 Python,同时还会涉及一些 Cython 内容——不过 Cython 是 Python 的一个超集(http://cython.org/) ,所以不要担心!
你现在写的 Python 程序已经是一个 Cython 程序了。
下面的一些场景可能对速度有很高的要求:
你正在使用 Python为 NLP 开发一个 生产模块;
你正在使用 Python 对一个大型 NLP 数据集进行 计算分析;
你正在为诸如 pyTorch/TensorFlow 这类深度学习框架 预处理大型训练集,或者深度学习模型采用的 批处理加载器加载了太多复杂逻辑,严重拖慢了训练速度。
开始之前再提一句,我还发布了一个 Jupyter notebook(https://github.com/huggingface/100-times-faster-nlp),其中包含了本文中讨论的所有示例,去试试吧!

首先你要知道,你的大部分代码在纯 Python 环境下可能都运行良好,但是其中存在一些 瓶颈函数,如果好好处理它们,运行速度就能提升一个数量级。
所以,应该首先检查你的 Python 代码,找出那些影响性能的部分。其中一种方法就是使用 cProfile(https://docs.python.org/3/library/profile.html) ,像这样:

你可能会发现影响性能的是一些循环或者使用神经网络时引入的 Numpy 数组操作。
那么该如何加速这些循环?
让我们通过一个简单的例子来解决这个问题。假设有一堆矩形,我们将它们存储成一个由 Python 对象(例如 Rectangle类实例)构成的列表。我们的模块的主要功能是对该列表进行迭代运算,从而统计出有多少个矩形的面积是大于所设定阈值的。
我们的 Python 模块非常简单,看起来像这样:
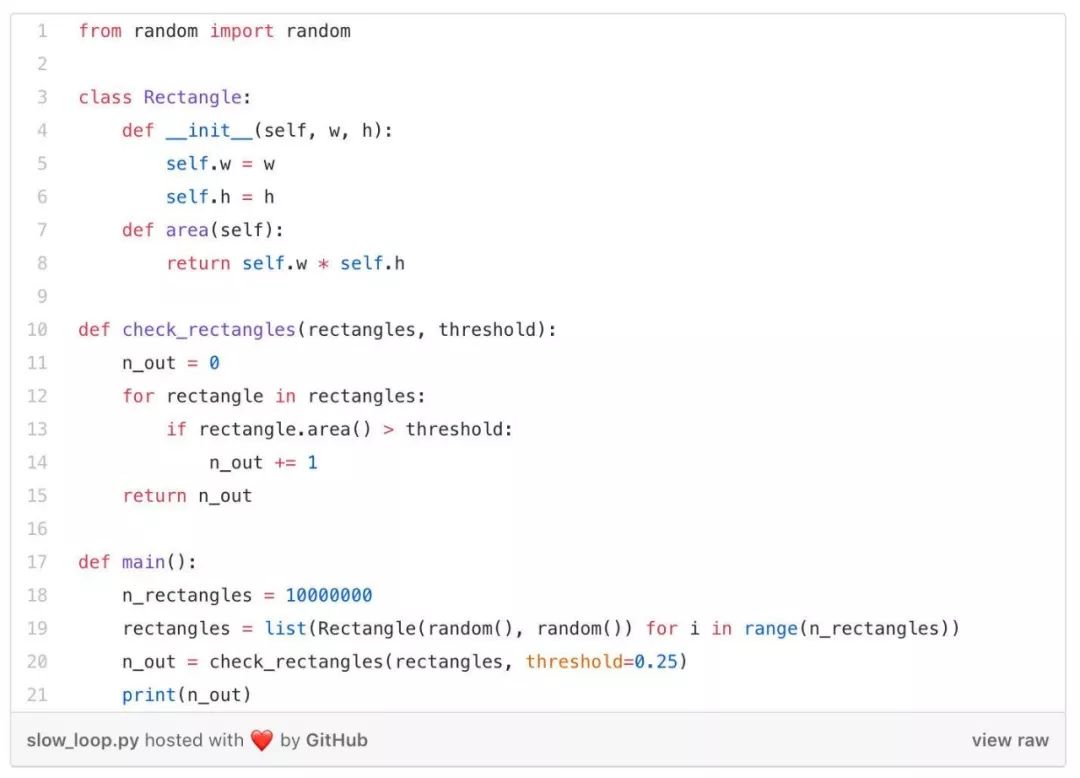
这个 check_rectangles 函数就是我们的瓶颈所在!它对大量 Python 对象进行循环检查,而因为 Python 解释器在每次迭代中都要做很多工作(比如在类中查找 area 方法、打包和解包参数、调用 Python API 等),这个循环就会非常影响性能。
这时就该引入 Cython 来帮助我们加速循环了。
Cython 语言是 Python 的一个超集,包含两种类型的对象:
所谓快速循环,就是在 Cython程序中只访问 Cython C 对象的循环。
设计这种循环最直接的办法就是,定义一个 C结构,其中包含计算过程中需要的所有内容:本例中就是矩形的长度和宽度。
然后我们可以将矩形对象的列表存储到这种 C 结构数组中,再将数组传递给 check_rectangle 函数。这个函数现在需要接收一个 C 数组作为输入,由此使用 cdef 关键字取代了 def(注意 cdef 也可以用于定义 Cython C 对象),将函数定义为一个 Cython 函数。
这是我们的 Python模块用更快的 Cython 版本重写后的样子:

这里我们使用了 C 指针的原始数组,但你也可以选择其它方案,特别是诸如向量、二元组、队列之类的 C++结构(http://cython.readthedocs.io/en/latest/src/userguide/wrapping_CPlusPlus.html#standard-library) 。在这段代码中,我还使用了 cymem(https://github.com/explosion/cymem) 的 Pool() 内存管理对象,以自动释放分配的 C 数组。当 Pool触发 Python的垃圾回收时,它会自动释放所分配对象使用的内存。
spaCy API 的 Cython 约定(https://spacy.io/api/cython#conventions)可以作为在实际应用中使用 Cython 执行 NLP任务的参考。
有很多办法可用于测试、编译和发布 Cython 代码!Cython 甚至可以像 Python 一样直接用在 Jupyter Notebook 内(http://cython.readthedocs.io/en/latest/src/reference/compilation.html#compiling-notebook )。
首先使用 pip install cython 命令安装 Cython。

使用 %load_ext Cython 在 Jupyter notebook 中加载 Cython 扩展。
现在就可以使用神奇的命令(http://cython.readthedocs.io/en/latest/src/reference/compilation.html#compiling-with-a-jupyter-notebook ) %%cython 来写 Cython代码了,就像写 Python代码一样。
如果在执行 Cython 单元时遇到了编译错误,一定要检查 Jupyter 终端输出的完整信息。
大多数情况下,可能是忘记在 %%cython之后加上 -+标签(比如当你使用 spaCy Cython API 时)。如果编译器报出了 Numpy相关的错误,那就是忘加 import numpy了。
正如我在一开始就提到的,请仔细查看这个 Jupyter notebook(https://github.com/huggingface/100-times-faster-nlp),它包含了我们讨论到的所有示例。
Cython 代码的文件后缀是 .pyx,这些文件被 Cython 编译器编译成 C 或 C++ 文件,再被系统的 C 编译器编译成字节码。之后 Python 解释器就能使用这些字节码文件。
可以使用 pyximport将一个 .pyx 文件直接加载到 Python 里:

还可以将 Cython 代码打包成 Python,然后像正常的 Python 包一样导入或发布,细节见此(http://cython.readthedocs.io/en/latest/src/tutorial/cython_tutorial.html) 。这种做法需要花费更多的时间,尤其是需要进行全平台发布的时候。如果需要参考,可以看看 spaCy 的安装脚本(https://github.com/explosion/spaCy/blob/master/setup.py)。
在开始讨论 NLP之前,还是先快速过一遍 def、cdef和 cpdef这三个关键字,因为它们是使用 Cython 时需要掌握的基础内容。
你可以在 Cython 程序中使用三种类型的函数:
Python 函数,使用 def关键字来定义,它们是可以作为输入和输出的 Python对象。在函数内可以使用 Python 和 C/C++ 对象,并且可以调用 Cython 和 Python 函数。
使用 cdef关键字定义的 Cython 函数,它们是可以作为输入(在内部使用)或输出的 Python 和 C/C++ 对象。这些函数不能从 Python 中访问(也就是 Python 解释器和其它可以导入 Cython 模块的纯 Python 模块),但是可以由其它 Cython 模块导入。
使用 cpdef关键字定义的 Cython 函数很像 cdef定义的 Cython 函数,但前者同时还带有 Python 包装器,所以能从 Python 中直接调用(用 Python 对象作为输入和输出),也可以从其它 Cython 模块中调用(用 C/C++ 或 Python 对象作为输入)。
cdef关键字的另一个用途是在代码中声明 Cython C/C++ 对象。除非你在代码中使用 这个关键字声明对象,否则它们都会被当做 Python 对象(结果导致访问速度变慢)。
这样看上去又快又好,但还没到 NLP这一步。比如没有字符串操作,没有 unicode 编码,我们在 NLP中用到的技巧一个都没涉及。
此外 Cython 的官方文档甚至建议不要使用 C 类型的字符串:
一般而言,除非你知道自己在做什么,否则就应该尽可能避免使用 C 字符串,而要使用 Python 的字符串对象。
那么我们在处理字符串时,要如何在 Cython 中设计高性能的循环呢?
spaCy 能解决这个问题。
spaCy 处理该问题的做法就非常明智。
spaCy 中所有的 unicode 字符串(一个节点文本、它的小写文本、它的引理形式、POS 标记标签、解析树依赖标签、命名实体标签等)都被存储在一个称为 StringStore的数据结构中,用一个 64 位哈希值进行索引,也就是 C 类型的 uint64_t(https://www.badprog.com/c-type-what-are-uint8-t-uint16-t-uint32-t-and-uint64-t)。
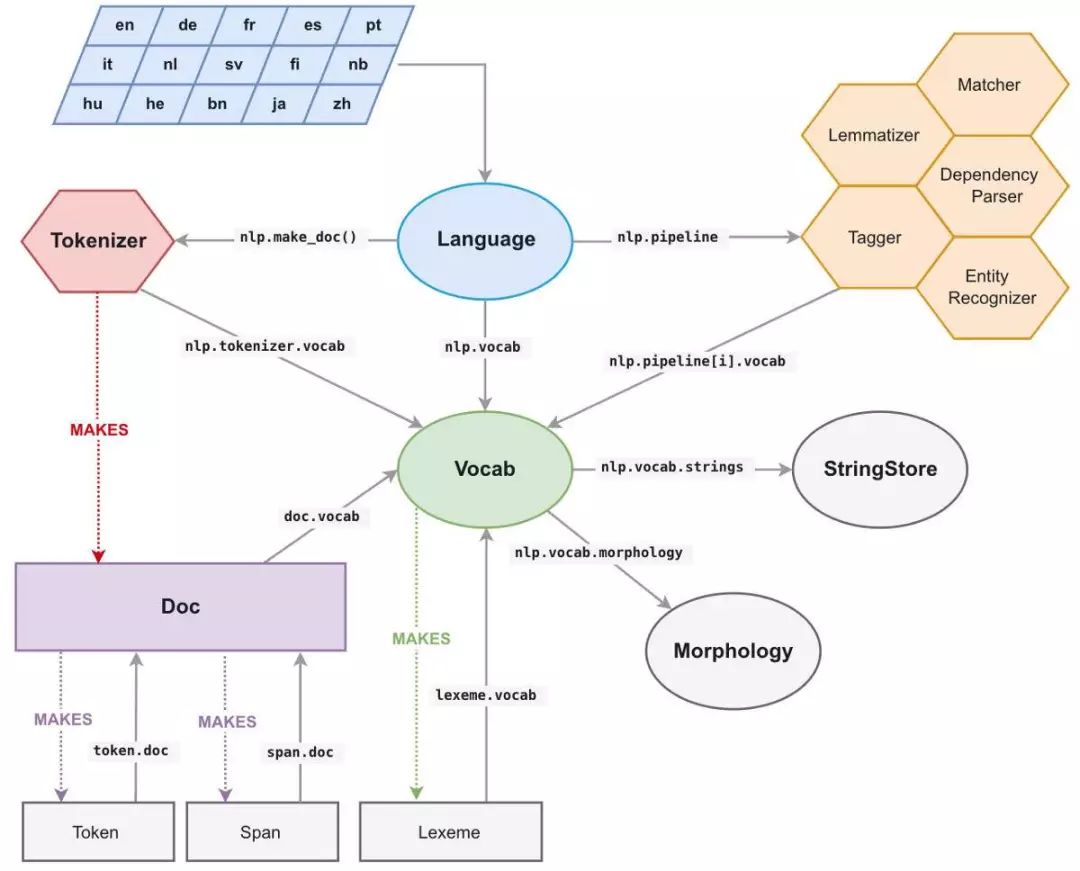
StringStore对象实现了 Python unicode 字符串与 64 位哈希值之间的映射。
我们可以从 spaCy 的任意位置和任意对象访问它,例如 npl.vocab.strings、doc.vocab.strings或 span.doc.vocab.string。
当一个模块需要在某些节点上获得更高的性能时,只要使用 C 类型的 64 位哈希值代替字符串即可。调用 StringStore映射表将返回与该哈希值相关联的 Python unicode 字符串。
但是 spaCy 还能做更多事情,它还能让我们访问到文档和词汇表的完整 C 类型结构,我们可以在 Cython 循环中使用这些结构,这样就不用自己从头构建了。
与 spaCy 文档关联的主要数据结构是 Doc(https://spacy.io/api/cython-classes#section-doc) 对象,它包含经过处理的字符串节点序列(“words”)以及它们在 C 类型对象中的所有注解,称为 doc.c(https://spacy.io/api/cython-classes#token_attributes) ,它是一个 TokenC 结构数组。
TokenC(https://spacy.io/api/cython-structs#section-tokenc) 结构包含了我们需要的每个节点的所有信息。这些信息被存储为 64 位哈希值,它可以与之前的 unicode 字符串重新关联。
如果想要准确地了解这些 C 结构中的内容,可以查看最近刚发布的的 spaCy 的 Cython API 文档(https://spacy.io/api/cython)。
接下来看一个简单的 NLP示例。
假设有一个文本文档的数据集需要分析。

我写了一个脚本,创建一个包含 10 个文档(经过 spaCy处理)的列表,每个文档有大约 17 万个单词。当然,我们也可以做 17 万个文档(每个文档包含 10 个单词),但是创建这么多文档会很慢,所以我们还是选择 10 个文档。
我们想要在这个数据集上执行一些 NLP任务。例如,我们想要统计数据集中单词“run”作为名词出现的次数(也就是被 spaCy 标记为“NN”)。
用 Python 循环来处理非常简单和直观:
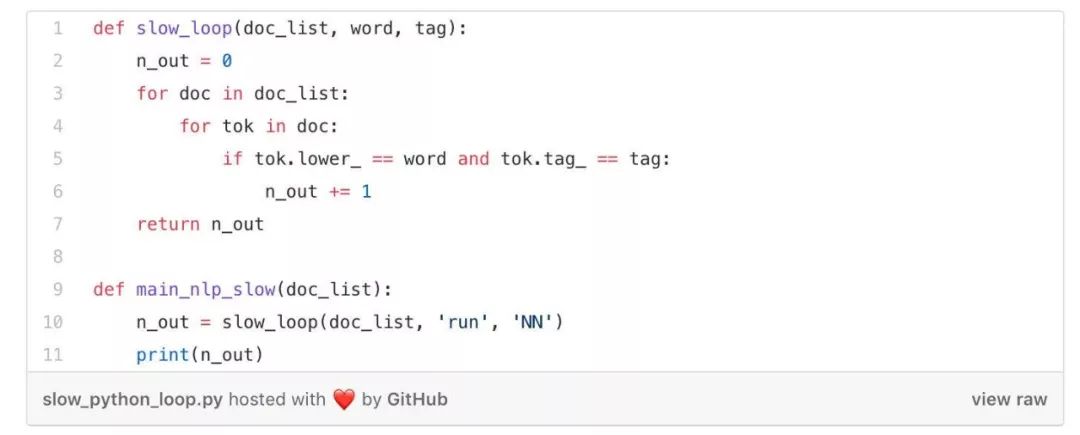
但它也非常慢!这段代码在我的笔记本上需要运行 1.4 秒才能获得结果。如果我们的数据集中包含数以百万计的文档,我们也许要花费 一天以上才能看到结果。
我们可以使用多线程来提速,但在 Python 中这往往不是最佳方案(https://youtu.be/yJR3qCUB27I?t=19m29s) ,因为你还需要处理全局解释器锁(GIL https://wiki.python.org/moin/GlobalInterpreterLock )。需要注意的是, Cython 也可以使用多线程(https://cython.readthedocs.io/en/latest/src/userguide/parallelism.html) !Cython 在底层可以直接调用 OpenMP。这里我没时间更加深入探讨并行处理,可以参考这里(https://cython.readthedocs.io/en/latest/src/userguide/parallelism.html)获取更多信息。
现在我们尝试使用 spaCy 和 Cython 来加速 Python 代码。
首先,我们要确定使用哪种数据结构。我们需要一个 C 类型的数组存放数据集,其中用指针指向每个文档的 TokenC 数组。还要将测试字符(“run”和“NN”)转成 64 位哈希值。
当所有需要处理的数据都变成了 C 类型对象,我们就能以纯 C 语言的速度迭代数据集。
下面展示这个例子如何写成 Cython 和 spaCy 的形式:

代码有点长,因为我们必须在调用 Cython 函数 [*](https://medium.com/huggingface/100-times-faster-natural-language-processing-in-python-ee32033bdced#a220) 之前在 main_nlp_fast中声明和计算 C 结构。
但它的性能得到大幅提升!在我的 Jupyter notebook中,这部分 Cython 代码大概只用 20 毫秒就运行完毕,比之前的纯 Python 循环快了 大概 80 倍。
使用 Jupyter notebook 单元编写模块的速度很惊人,它可以与其他 Python 模块和函数发生交互:在 20 毫秒内扫描大约 170 万个单词,这意味着我们每秒能够处理高达 8 千万个单词。
对使用 Cython 加速 NLP的介绍到此为止,希望大家喜欢。
关于 Cython 还有很多其它的东西可以介绍,但是已经大大超出了这篇文章的范围。接下来最好的参考资料也许是这份 Cython 教程(http://cython.readthedocs.io/en/latest/src/tutorial/index.html),它提供了综述内容,以及 spaCy 的 Cython 页面(https://spacy.io/api/cython),它提供了 NLP相关的内容。
如果你在代码中需要多次使用底层结构,比每次计算 C 结构更优雅的做法是,在 Python代码的底层使用 Cython 扩展类型(http://cython.readthedocs.io/en/latest/src/userguide/extension_types.html) 来包装 C 类型结构。这就是大多数 spaCy 代码所采用的结构,它非常优雅,兼具高效、低内存开销和易于交互的特性。
英文原文:
https://medium.com/huggingface/100-times-faster-natural-language-processing-in-python-ee32033bdced
今日荐文
点击下方图片即可阅读

苹果无人车野心因泄密而暴露:5000+员工参与,VR技术加持!
8 月 18 日,InfoQ 将举办一场面向技术人的区块链大会!超过二十个区块链落地案例,区块链前沿技术剖析,区块链生态、服务盘点和解读,尽在 BCCon2018!点击查看原文进入大会官网了解更多信息。


如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!










