
AI 研习社按:本文为雷锋字幕组编译的技术博客,原标题 A Comprehensive Guide to Understand and Implement Text Classification in Python ,作者为 SHIVAM BANSAL 。
翻译 | 马力群 于泽平 校对 | 涂世文 整理 | MY
引言
文本分类作为自然语言处理任务之一,被广泛应用于解决各种商业领域的问题。文本分类的目的是将 文本/文档 自动地归类为一种或多种预定义的类别。常见的文本分类应用如下:
理解社交媒体用户的情感
识别垃圾邮件与正常邮件
自动标注用户的查询
将新闻按已有的主题分类
主要内容
在这篇文章中,我会讲解文本分类的知识并在 Python 中一步一步实现文本分类。
文本分类属于有监督机器学习任务,这是因为文本分类任务利用一个包含 文本/文档 及其对应类标的有标注数据集来训练一个分类器。一个端到端的文本分类流程包括三个主要环节:
数据集准备:第一步为数据准备,这一步包括数据加以及基本的预处理工作。数据集之后会被分割的训练集与验证集。
特征工程:第二步为特征工程,在这一步中,原始数据会转变为适用于机器学习模型的特征。这一步还包括从已有数据中构建新的特征的过程。
模型训练:最后一步为模型构建,在这一步中机器学习模型会在一个有标注数据集上进行训练。
提升文本分类器的性能:在这篇文章中,我们还会关注各种提升文本分类器性能的方法。
说明 : 这篇文章不会深入探讨自然语言处理任务。如果你想要温习基础知识后再阅读本文,你可以浏览这篇文章(链接:https://www.analyticsvidhya.com/blog/2017/01/ultimate-guide-to-understand-implement-natural-language-processing-codes-in-python/)。
准备工作
让我们通过一步一步实现的方式用 Python 搭建一个文本分类框架。首先,需要导入所需的 Python 库。
你需要一些必要的 Python 工具库来运行这一程序,你可以在这些第三方 Python 库的官方链接下安装它们。
Pandas
Scikit-learn
XGBoost
TextBlob
Keras
# 用于数据准备,特征工程,模型训练的库
from sklearn import model_selection, preprocessing, linear_model, naive_bayes, metrics, svm
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn import decomposition, ensemble
import pandas, xgboost, numpy, textblob, string
from keras.preprocessing import text, sequence
from keras import layers, models, optimizers
1. 数据集准备
根据本文的目标,我采用了亚马逊评论的数据集,这一数据集可以通过该链接(https://gist.github.com/kunalj101/ad1d9c58d338e20d09ff26bcc06c4235)下载。该数据集包含了 360 万文本评论及其对应的标签,我们只用其中的一小部分。为了准备数据,将下载好的数据加载到 pandas 的一个数据框中,该数据框包含两列——文本与标签。
# load the dataset
data = open('data/corpus').read()
labels, texts = [], []
for i, line in enumerate(data.split("\n")):
content = line.split()
labels.append(content[0])
texts.append(content[1])
# create a dataframe using texts and lables
trainDF = pandas.DataFrame()
trainDF['text'] = texts
trainDF['label'] = labels
接下来,我们将数据集分割为训练集与验证集,这样我们就可以训练和测试分类器。并且,我们将标签列进行编码使其可以用于机器学习模型。
train_x, valid_x, train_y, valid_y = model_selection.train_test_split(trainDF['text'], trainDF['label'])
encoder = preprocessing.LabelEncoder()
train_y = encoder.fit_transform(train_y)
valid_y = encoder.fit_transform(valid_y)
2. 特征工程
下一步为特征工程。在这一步中,原始数据会被转换为特征向量并且会从已有的数据中构建出新的特征。为了从我们的数据集中提取出相关的特征,我们会实现以下各种想法。
2.1 以计数向量为特征
2.2 TF-IDF 向量为特征
2.3 以词向量为特征
2.4 基于 文本/自然语言处理 的特征
2.5 以主题模型为特征
让我们详细了解这些想法的实现。
2.1 以计数向量为特征
计数向量是数据集的一种矩阵表示,在这一矩阵中每一行代表语料中的一个文档,每一列代表语料中的一个词项,每一个元素代表特定文档中特定词项的频率计数。
count_vect = CountVectorizer(analyzer='word', token_pattern=r'\w{1,}')
count_vect.fit(trainDF['text'])
xtrain_count = count_vect.transform(train_x)
xvalid_count = count_vect.transform(valid_x)
2.2 以TF-IDF向量为特征
TF-IDF 分数代表一个词项在某一文档与整个语料库中的相对重要程度。TF-IDF 值由两部分组成:第一部分为归一化词频 ( TF ) ,第二部分为逆文档频率 ( IDF ),逆文档频率由语料中的文档总数除以出现对应词项的文档的数量的结果取对数计算得到。
TF( t ) = (在某一文档中词项t出现的次数) / (该文档中词项总数)
IDF( t ) = log_e (文档总数 / 包含词项 t 的文档的数量)
TF-IDF 可以由不同级别的输入得到(词,字符,N-grams )
a. 词级 TF-IDF : 矩阵表示不同文档中各个词项 TF-IDF 值。
b. N-gram 级 TF-IDF: N-grams 为 N 个词项结合在一起的形式。这一矩阵表示 N-grams 的 TF-IDF 值。
c. TF-IDF 字符级 TF-IDF: 矩阵表示语料中字符级别的 N-grams 的 TF-IDF 值。
tfidf_vect = TfidfVectorizer(analyzer='word', token_pattern=r'\w{1,}', max_features=5000)
tfidf_vect.fit(trainDF['text'])
xtrain_tfidf = tfidf_vect.transform(train_x)
xvalid_tfidf = tfidf_vect.transform(valid_x)
tfidf_vect_ngram = TfidfVectorizer(analyzer='word', token_pattern=r'\w{1,}', ngram_range=(2,3), max_features=5000)
tfidf_vect_ngram.fit(trainDF['text'])
xtrain_tfidf_ngram = tfidf_vect_ngram.transform(train_x)
xvalid_tfidf_ngram = tfidf_vect_ngram.transform(valid_x)
tfidf_vect_ngram_chars = TfidfVectorizer(analyzer='char', token_pattern=r'\w{1,}', ngram_range=(2,3), max_features=5000)
tfidf_vect_ngram_chars.fit(trainDF['text'])
xtrain_tfidf_ngram_chars = tfidf_vect_ngram_chars.transform(train_x)
xvalid_tfidf_ngram_chars = tfidf_vect_ngram_chars.transform(valid_x)
2.3 词向量
词向量是一种利用稠密向量表示 词/文档 的形式。词在向量空间中的位置从文本中学习得到并且以该词附近出现的词为学习依据。词向量可以由输入语料自身学习得到或者可以利用预训练好的词向量生成,例如 Glove,FastText 和 Word2Vec。它们中的任意一个都可以下载并以迁移学习的形式使用。我们可以在这里阅读到更多关于词向量的内容。
下方的代码片段展示了如何在模型中利用预训练的词向量。有四个必要的步骤:
加载预训练的词向量
创建标记器对象
将文本文档转换为词条序列并对其进行填补。
创建词条与其对应的词向量之间的映射。
你可以从这里(https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec/)下载预训练好的词向量。
# load the pre-trained word-embedding vectors
embeddings_index = {}
for i, line in enumerate(open('data/wiki-news-300d-1M.vec')):
values = line.split()
embeddings_index[values[0]] = numpy.asarray(values[1:], dtype='float32')
# create a tokenizer
token = text.Tokenizer()
token.fit_on_texts(trainDF['text'])
word_index = token.word_index
# convert text to sequence of tokens and pad them to ensure equal length vectors
train_seq_x = sequence.pad_sequences(token.texts_to_sequences(train_x), maxlen=70)
valid_seq_x = sequence.pad_sequences(token.texts_to_sequences(valid_x), maxlen=70)
# create token-embedding mapping
embedding_matrix = numpy.zeros((len(word_index) + 1, 300))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
2.4 基于文本/自然语言处理的特征
还可以构建一些额外的基于文本的的特征,这些特征有时有助于提升文本分类模型性能。一些例子如下:
文档的词计数—文档中词总数
文档的字符计数—文档中字符总数
文档的平均词密度—文档中词的平均长度
整篇文章中的标点符号计数—文档中标点符号的总数
整篇文章中大写词计数—文档中大写词的总数
整篇文章中标题词计数—文档中合适的大小写(标题)词总数
词性标签的频率分布:
这些特征是实验性质的,只能根据特定的情况使用。
trainDF['char_count'] = trainDF['text'
].apply(len)
trainDF['word_count'] = trainDF['text'].apply(lambda x: len(x.split()))
trainDF['word_density'] = trainDF['char_count'] / (trainDF['word_count']+1)
trainDF['punctuation_count'] = trainDF['text'].apply(lambda x: len("".join(_ for _ in x if _ in string.punctuation)))
trainDF['title_word_count'] = trainDF['text'].apply(lambda x: len([wrd for wrd in x.split() if wrd.istitle()]))
trainDF['upper_case_word_count'] = trainDF['text'].apply(lambda x: len([wrd for wrd in x.split() if wrd.isupper()]))
pos_family = {
'noun' : ['NN','NNS','NNP','NNPS'],
'pron' : ['PRP','PRP$','WP','WP$'],
'verb' : ['VB','VBD','VBG','VBN','VBP','VBZ'],
'adj' : ['JJ','JJR','JJS'],
'adv' : ['RB','RBR','RBS','WRB']
}
def check_pos_tag(x, flag):
cnt = 0
try:
wiki = textblob.TextBlob(x)
for tup in wiki.tags:
ppo = list(tup)[1]
if ppo in pos_family[flag]:
cnt += 1
except:
pass
return cnt
trainDF['noun_count'] = trainDF['text'].apply(lambda x: check_pos_tag(x, 'noun'))
trainDF['verb_count'] = trainDF['text'
].apply(lambda x: check_pos_tag(x, 'verb'))
trainDF['adj_count'] = trainDF['text'].apply(lambda x: check_pos_tag(x, 'adj'))
trainDF['adv_count'] = trainDF['text'].apply(lambda x: check_pos_tag(x, 'adv'))
trainDF['pron_count'] = trainDF['text'].apply(lambda x: check_pos_tag(x, 'pron'))
2.5 基于主题模型的特征
主题模型是一种从包含最佳信息的一批文档中辨别词所属组(被称作主题)的技术。我利用隐狄利克雷分布 ( Latent Dirichlet Allocation ) 生成主题模型特征。LDA 是一种迭代模型,迭代从固定数量的主题开始。每个主题被表示为一个词的概率分布,每个文档被表示为一个主题的概率分布。尽管词条自身是没有意义的,但是这些主题所代表的词的概率分布有种包含在文档中的不同概念的感觉。可以在这里阅读到更多关于主题模型的内容(https://www.analyticsvidhya.com/blog/2016/08/beginners-guide-to-topic-modeling-in-python/)。
让我们来看看它的实现:
lda_model = decomposition.LatentDirichletAllocation(n_components=20, learning_method='online', max_iter=20)
X_topics = lda_model.fit_transform(xtrain_count)
topic_word = lda_model.components_
vocab = count_vect.get_feature_names()
n_top_words = 10
topic_summaries = []
for i, topic_dist in enumerate(topic_word):
topic_words = numpy.array(vocab)[numpy.argsort(topic_dist)][:-(n_top_words+1):-1]
topic_summaries.append(' '.join(topic_words))
3. 模型建立
文本分类框架搭建的最后一步为利用前几步创建的特征训练一个分类器。机器学习模型有许多不同的选择,这些模型都可以用来训练最终的模型。为此,我们将会实现下列几种不同的分类器:
朴素贝叶斯分类器
线性分类器
支持向量机
Bagging 模型
Boosting 模型
浅层神经网络
深度神经网络
卷积神经网络 (CNN)
长短时记忆模型 (LSTM)
门控循环单元 (GRU)
双向循环神经网络
循环卷积神经网络 (RCNN)
其他深度神经网络的变种
让我们来实现这些模型并理解它们的实现细节。下方的函数是一个可以用于训练模型的实用函数。它以分类器、训练数据的特征向量、训练数据的标签和验证集的特征向量作为输入。模型利用这些输入进行训练与计算准确率。
def train_model(classifier, feature_vector_train, label, feature_vector_valid, is_neural_net=False):
classifier.fit(feature_vector_train, label)
predictions = classifier.predict(feature_vector_valid)
if is_neural_net:
predictions = predictions.argmax(axis=-1)
return metrics.accuracy_score(predictions, valid_y)
3.1 朴素贝叶斯
利用 sklearn 实现基于不同特征的朴素贝叶斯模型
朴素贝叶斯是一种基于贝叶斯理论的分类技术,它假设预测变量是独立的。朴素贝叶斯分类器假设类别中的特征与其他特征不相关。
# Naive Bayes on Count Vectors
accuracy = train_model(naive_bayes.MultinomialNB(), xtrain_count, train_y, xvalid_count)
print "NB, Count Vectors: ", accuracy
# Naive Bayes on Word Level TF IDF Vectors
accuracy = train_model(naive_bayes.MultinomialNB(), xtrain_tfidf, train_y, xvalid_tfidf)
print "NB, WordLevel TF-IDF: ", accuracy
# Naive Bayes on Ngram Level TF IDF Vectors
accuracy = train_model(naive_bayes.MultinomialNB(), xtrain_tfidf_ngram, train_y, xvalid_tfidf_ngram)
print "NB, N-Gram Vectors: ", accuracy
# Naive Bayes on Character Level TF IDF Vectors
accuracy = train_model(naive_bayes.MultinomialNB(), xtrain_tfidf_ngram_chars, train_y, xvalid_tfidf_ngram_chars)
print "NB, CharLevel Vectors: ", accuracy
NB, Count Vectors: 0.7004
NB, WordLevel TF-IDF: 0.7024
NB, N-Gram
Vectors: 0.5344
NB, CharLevel Vectors: 0.6872
3.2 线性分类器
实现线性分类器(逻辑回归)
逻辑回归使用 logisitic/sigmoid 函数估计概率,并以此估计因变量与一个或多个自变量之间的关系。
# Linear Classifier on Count Vectors
accuracy = train_model(linear_model.LogisticRegression(), xtrain_count, train_y, xvalid_count)
print "LR, Count Vectors: ", accuracy
# Linear Classifier on Word Level TF IDF Vectors
accuracy = train_model(linear_model.LogisticRegression(), xtrain_tfidf, train_y, xvalid_tfidf)
print "LR, WordLevel TF-IDF: ", accuracy
# Linear Classifier on Ngram Level TF IDF Vectors
accuracy = train_model(linear_model.LogisticRegression(), xtrain_tfidf_ngram, train_y, xvalid_tfidf_ngram)
print "LR, N-Gram Vectors: ", accuracy
# Linear Classifier on Character Level TF IDF Vectors
accuracy = train_model(linear_model.LogisticRegression(), xtrain_tfidf_ngram_chars, train_y, xvalid_tfidf_ngram_chars)
print "LR, CharLevel Vectors: ", accuracy
LR, Count Vectors: 0.7048
LR, WordLevel TF-IDF: 0.7056
LR, N-Gram Vectors: 0.4896
LR, CharLevel Vectors: 0.7012
3.3 支持向量机模型
支持向量机(SVM)是一种监督学习算法,可用在分类或回归任务中。此模型提取了分离两个类别的最佳超平面/线。
# SVM on Ngram Level TF IDF Vectors
accuracy = train_model(svm.SVC(), xtrain_tfidf_ngram, train_y, xvalid_tfidf_ngram)
print "SVM, N-Gram Vectors: ", accuracy
SVM, N-Gram Vectors: 0.5296
3.4 Bagging
实现随机森林模型。
随机森林模型是集成模型中的一种,更精确地说,是 bagging 模型中的一种。它是基于树的模型之一。
# RF on Count Vectors
accuracy = train_model(ensemble.RandomForestClassifier(), xtrain_count, train_y, xvalid_count)
print "RF, Count Vectors: ", accuracy
# RF on Word Level TF IDF Vectors
accuracy = train_model(ensemble.RandomForestClassifier(), xtrain_tfidf, train_y, xvalid_tfidf)
print "RF, WordLevel TF-IDF: ", accuracy
RF, Count Vectors: 0.6972
RF, WordLevel TF-IDF: 0.6988
3.5 Boosting
实现 xgboost 模型。
Boosting 模型是另一种基于树的集成模型。Boosting 是一种机器学习集成元算法,用来减小监督学习中的偏差与方差,它可以将弱分类器转化为强分类器。弱分类器指的是与正确类别轻微相关的分类器(比随机猜测要好一些)。
# Extereme Gradient Boosting on Count Vectors
accuracy = train_model(xgboost.XGBClassifier(), xtrain_count.tocsc(), train_y, xvalid_count.tocsc())
print "Xgb, Count Vectors: ", accuracy
# Extereme Gradient Boosting on Word Level TF IDF Vectors
accuracy = train_model(xgboost.XGBClassifier(), xtrain_tfidf.tocsc(), train_y, xvalid_tfidf.tocsc())
print "Xgb, WordLevel TF-IDF: ", accuracy
# Extereme Gradient Boosting on Character Level TF IDF Vectors
accuracy = train_model(xgboost.XGBClassifier(), xtrain_tfidf_ngram_chars.tocsc(), train_y, xvalid_tfidf_ngram_chars.tocsc())
print "Xgb, CharLevel Vectors: ", accuracy
/usr/local/lib/python2.7/dist-packages/sklearn/preprocessing/label.py:151: DeprecationWarning: The truth value of an empty array is ambiguous. Returning False, but in future this will result in an error. Use `array.size > 0` to check that an array is not empty.
if diff:
/usr/local/lib/python2.7/dist-packages/sklearn/preprocessing/label.py:151: DeprecationWarning: The truth value of an empty array is ambiguous. Returning False, but in future this will result in an error. Use `array.size > 0` to check that an array is not empty.
if diff:
Xgb, Count Vectors: 0.6324
Xgb, WordLevel TF-IDF: 0.6364
Xgb
, CharLevel Vectors: 0.6548
/usr/local/lib/python2.7/dist-packages/sklearn/preprocessing/label.py:151: DeprecationWarning: The truth value of an empty array is ambiguous. Returning False, but in future this will result in an error. Use `array.size > 0` to check that an array is not empty.
if diff:
3.6 浅层神经网络
神经网络是一种被设计成与生物神经元和神经系统类似的数学模型,可用来识别标注数据中的复杂关系。一个浅层神经网络主要包含三个层——输入层,隐藏层和输出层。
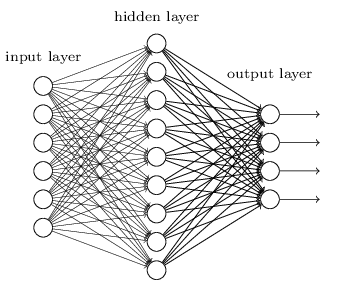
def create_model_architecture(input_size):
input_layer = layers.Input((input_size, ), sparse=True)
hidden_layer = layers.Dense(100, activation="relu")(input_layer)
output_layer = layers.Dense(1, activation="sigmoid")(hidden_layer)
classifier = models.Model(inputs = input_layer, outputs = output_layer)
classifier.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy')
return classifier
classifier = create_model_architecture(xtrain_tfidf_ngram.shape[1])
accuracy = train_model(classifier, xtrain_tfidf_ngram, train_y, xvalid_tfidf_ngram, is_neural_net=True)
print "NN, Ngram Level TF IDF Vectors", accuracy
Epoch 1/1
7500/7500 [==============================] - 1s 67us/step - loss: 0.6909
NN, Ngram Level TF IDF Vectors 0.5296
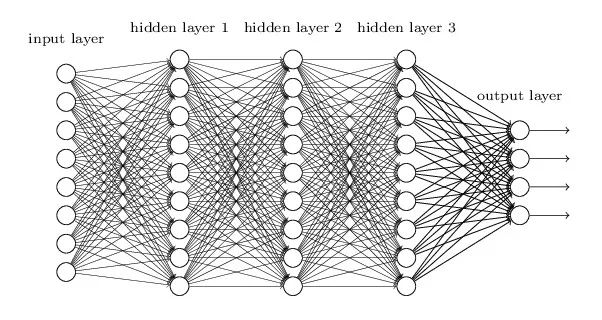
3.7 深层神经网络
深层神经网络是更复杂的神经网络,它的隐藏层执行比 sigmoid 或 relu 激活函数更复杂的操作。许多类型的深层神经网络都可应用于文本分类问题中。
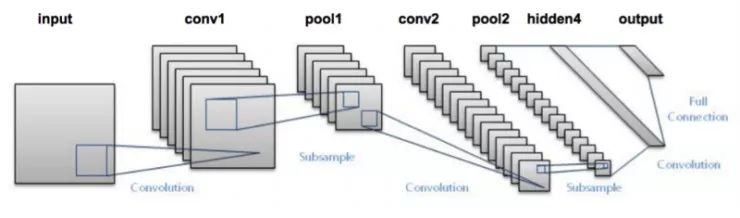
3.7.1 卷积神经网络
在卷积神经网络中,作用于输入层上的卷积操作被用于计算输出。卷积神经网络使用局部连接,输入的每一个区域都连接到输出的神经元上。每一层使用不同的过滤器并将结果组合起来。
def create_cnn():
input_layer = layers.Input((70, ))
embedding_layer = layers.Embedding(len(word_index) + 1, 300, weights=[embedding_matrix], trainable=False)(input_layer)
embedding_layer = layers.SpatialDropout1D(0.3)(embedding_layer)
conv_layer = layers.Convolution1D(100, 3, activation="relu")(embedding_layer)
pooling_layer = layers.GlobalMaxPool1D()(conv_layer)
output_layer1 = layers.Dense(50, activation="relu")(pooling_layer)
output_layer1 = layers.Dropout(0.25)(output_layer1)
output_layer2 = layers.Dense(1, activation="sigmoid")(output_layer1)
model = models.Model(inputs=input_layer, outputs=output_layer2)
model.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy')
return model
classifier = create_cnn()
accuracy = train_model(classifier, train_seq_x, train_y, valid_seq_x, is_neural_net=True)
print "CNN, Word Embeddings", accuracy
Epoch 1/1
7500/7500 [==============================] - 12s 2ms/step - loss: 0.5847
CNN, Word Embeddings 0.5296
3.7.2 循环神经网络——LSTM
与前馈神经网络激活函数只在一个方向传播的方式不同,循环神经网络的激活函数的输出在两个方向传播(从输入到输出,从输出到输入)。这产生了循环网络结构中的循环,充当神经元中的“记忆状态”。这种状态使神经元记忆迄今为止所学到的东西。
循环神经网络中的记忆单元比传统的神经网络更有优势,但梯度消失问题随之产生。当层数很多时,神经网络很难学习并调整前面层数的参数。为了解决这个问题,一种名为LSTM(长短期记忆)的新型RNN模型被发明出来。
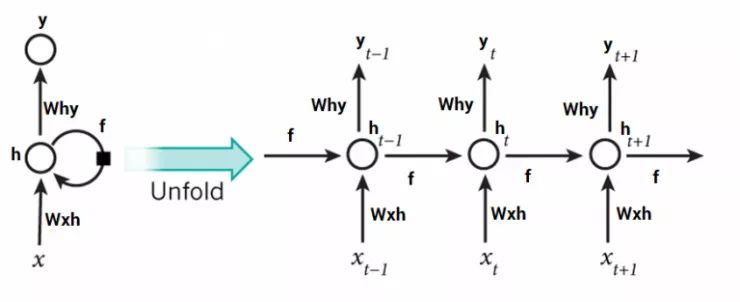
input_layer = layers.Input((70, ))
embedding_layer = layers.Embedding(len(word_index) + 1, 300, weights=[embedding_matrix], trainable=False)(input_layer)
embedding_layer = layers.SpatialDropout1D(0.3)(embedding_layer)
lstm_layer = layers.LSTM(100)(embedding_layer)
output_layer1 = layers.Dense(50, activation="relu")(lstm_layer)
output_layer1 = layers.Dropout(0.25)(output_layer1)
output_layer2 = layers.Dense(1, activation="sigmoid")(output_layer1)
model = models.Model(inputs=input_layer, outputs=output_layer2)
model.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy')
return model
classifier = create_rnn_lstm()
accuracy = train_model(classifier, train_seq_x, train_y, valid_seq_x, is_neural_net=True)
print "RNN-LSTM, Word Embeddings", accuracy
Epoch 1/1
7500/7500 [==============================] - 22s 3ms/step - loss: 0.6899
RNN-LSTM, Word Embeddings 0.5124
3.7.3 循环神经网络——GRU
门控循环单元(GRU)是另一种循环神经网络。我们在网络中添加一个GRU层来代替LSTM。
input_layer = layers.Input((70, ))
embedding_layer = layers.Embedding(len(word_index) + 1, 300, weights=[embedding_matrix], trainable=False)(input_layer)
embedding_layer = layers.SpatialDropout1D(0.3)(embedding_layer)
lstm_layer = layers.GRU(100)(embedding_layer)
output_layer1 = layers.Dense(50, activation="relu")(lstm_layer)
output_layer1 = layers.Dropout(0.25)(output_layer1)
output_layer2 = layers.Dense(1, activation="sigmoid")(output_layer1)
model = models.Model(inputs=input_layer, outputs=output_layer2)
model.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy')
return model
classifier = create_rnn_gru()
accuracy = train_model(classifier, train_seq_x, train_y, valid_seq_x, is_neural_net=True)
print "RNN-GRU, Word Embeddings", accuracy
Epoch 1
/1
7500/7500 [==============================] - 19s 3ms/step - loss: 0.6898
RNN-GRU, Word Embeddings 0.5124
3.7.4 双向循环神经网络
RNN层可以被封装在双向层中,我们来把GRU层封装在双向层中。
input_layer = layers.Input((70, ))
embedding_layer = layers.Embedding(len(word_index) + 1, 300, weights=[embedding_matrix], trainable=False)(input_layer)
embedding_layer = layers.SpatialDropout1D(0.3)(embedding_layer)
lstm_layer = layers.Bidirectional(layers.GRU(100))(embedding_layer)
output_layer1 = layers.Dense(50, activation="relu")(lstm_layer)
output_layer1 = layers.Dropout(0.25)(output_layer1)
output_layer2 = layers.Dense(1, activation="sigmoid")(output_layer1)
model = models.Model(inputs=input_layer, outputs=output_layer2)
model.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy')
return model
classifier = create_bidirectional_rnn()
accuracy = train_model(classifier, train_seq_x, train_y, valid_seq_x, is_neural_net=True)
print "RNN-Bidirectional, Word Embeddings", accuracy
Epoch 1/1
7500/7500 [==============================] - 32s 4
ms/step - loss: 0.6889
RNN-Bidirectional, Word Embeddings 0.5124
3.7.5 循环卷积神经网络
我们尝试过基本的结构了,现在可以试试它们的变种循环卷积神经网络(RCNN)。其它变种有:
1. 层次注意力网络(HAN)
2. 具有注意力机制的序列-序列模型
3. 双向RCNN
4. 更多层的CNN与RNN
input_layer = layers.Input((70, ))
embedding_layer = layers.Embedding(len(word_index) + 1, 300, weights=[embedding_matrix], trainable=False)(input_layer)
embedding_layer = layers.SpatialDropout1D(0.3)(embedding_layer)
rnn_layer = layers.Bidirectional(layers.GRU(50, return_sequences=True))(embedding_layer)
conv_layer = layers.Convolution1D(100, 3, activation="relu")(embedding_layer)
pooling_layer = layers.GlobalMaxPool1D()(conv_layer)
output_layer1 = layers.Dense(50, activation="relu")(pooling_layer)
output_layer1 = layers.Dropout(0.25)(output_layer1)
output_layer2 = layers.Dense(1, activation="sigmoid")(output_layer1)
model = models.Model(inputs=input_layer, outputs=output_layer2)
model.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy')
return model
classifier = create_rcnn()
accuracy = train_model(classifier, train_seq_x, train_y, valid_seq_x, is_neural_net=True)
print "CNN, Word Embeddings", accuracy
Epoch 1/1
7500
/7500 [==============================] - 11s 1ms/step - loss: 0.6902
CNN, Word Embeddings 0.5124
提升模型的性能
虽然上述的框架可以应用在许多文本分类问题中,但为了达到更高的准确率,可以在整体结构上进行改进。例如,以下是一些可以提升文本分类模型性能的技巧:
1. 文本清洗 : 文本清洗可以帮助减小文本数据中的噪声,如停用词,标点符号,后缀等。
2. 将不同的特征向量组合起来: 在特征工程部分,我们得到了许多不同特征,把它们组合到一起可以提高分类准确率。
3. 模型中的调参 : 调参是一个很重要的步骤,可以对一些参数(树的长度、叶子节点个数、神经网络参数等)进行微调,获得最佳拟合的模型。
4. 集成模型 : 将不同的模型结合到一起并组合它们的输出可以提升结果。
结束语
在这篇文章中,我们讨论了如何准备文本数据集,如清洗、创建训练集与测试集。使用不同的特征工程如词频、TF-IDF、词向量、主题模型以及基本的文本特征。然后我们训练了许多分类器,如朴素贝叶斯、逻辑回归、支持向量机、神经网络、LSTM 和 GRU。最后我们讨论了提升文本分类器性能的多种方法。
你觉得这篇文章有用吗?请在评论中分享你的看法。
你也可以在 Analytics Vidhya 的 Android APP中阅读本文。
原文链接:
https://www.analyticsvidhya.com/blog/2018/04/a-comprehensive-guide-to-understand-and-implement-text-classification-in-python/

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据资料】
采用通用语言模型的最新文本分类介绍
▼▼▼









