

最近滑铁卢大学一位叫 Bai Li 的留学生(李白?应是中国同胞)在 medium 上分享了如何用 ML 中的逻辑回归方法帮自己找女票的神操作。像这么实用的技术,我们必须观摩学习一个。
这里插一嘴,以前老有人搞错滑铁卢大学,这里的滑铁卢在加拿大,不是比利时那个让拿破仑最后真的拿了破轮的滑铁卢。滑铁卢大学是加拿大一所著名高校,是北美地区最优大学之一,其数学、计算机科学和工程学科教学水平居世界前列,其中优势专业计算机科学名列 2017 年 usnews 世界大学排行榜第 18 位。
好了废话不说,我们观看少年的表演:
滑铁卢大学是出了名的缺少社交活动和很难找到对象。和我(原作者Bai Li——译者注)一样,滑大的很多计算机专业男生都觉得,找女票是不可能找到的,大概毕业前都不会找到的。找也不知道该怎么找,谈恋爱又不会,就只能敲敲代码才能维持得了生活这样子。

有些人觉得爱情这种东西是没法量化的,你只管“做你自己”就好了。不过,作为滑铁卢大学的一个数据科学家,我对此持不同意见。我就想了,既然是搞计算机的,干嘛不试试借助机器学习找女朋友呢?
方法论
心动不如行动,马上着手研究如何用机器学习技术找女票。
这个研究的核心问题是:具备哪些属性,能在滑铁卢大学众多男生中脱颖而出找到女朋友?
很多人觉得兜里有钱会更能吸引妹子,此外身高、有没有肌肉这些指标也会起作用。
我们下面就试着找出哪些是最有预测力的属性,哪些假设没有数据支撑。
我首先想到了下面这些属性:
约会(目标变量):有女朋友,或者过去5年内曾有过至少维持了半年感情的女朋友。
国籍:留学生(因为我也是留学生)
专业:CS,SE和ECE专业
事业:在学术上很成功,找到了薪水优渥的实习工作
有趣性:能说会道,总能找到有趣的谈资
社交性:外向性格,总想认识新朋友
自信:看着比较自信
身高:身高比我高(> 175 cm)
眼镜:戴眼镜(我也戴)
健身:定期去健身房,或者运动
时尚:注重外在形象,穿着有品位
加拿大:过去5年内基本生活在加拿大
亚洲人:来自东亚地区(因为我也是)
看到这里你应该会发现,上面有些属性非常主观,比如怎么证明一个人很有趣?

在上面这些情况中,我按照是否符合标准会赋予 1 或 0 这两个值。所以,我们是在衡量人们的上述属性和能找到对象之间的关系(当然是根据我自己的理解,不喜勿喷)。
所以,假如你是想看那种超硬核又严格统计的研究,那么后面的内容可能不是你的菜。
为了收集数据,我把自己能想到的每个人都列在表格里,在每个属性里会以 0 或 1 给他们打分。最终,数据集有 N=70 行。如果你过去两年待在滑大,和我认识,多半这个表格上有你。
分析
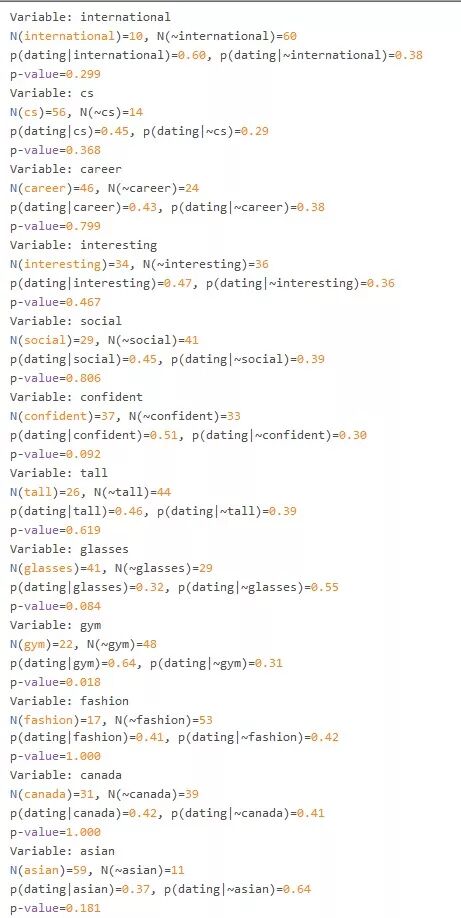
首先,我们将精确概率法(Fisher’s Exact Test)对目标约会变量和所有的说明变量进行分析,发现其中有 3 个变量影响最为显著:
健身:定期去健身房或运动的人有女朋友的概率会高出两倍以上(P值=0.02)
眼镜:不戴眼镜的人有女朋友的概率比戴眼镜的人会高出 70%(P值=0.08)
自信:有自信心的人有朋友的概率更高(P 值=0.09)
和我预期的一样,有肌肉有自信的小伙更有吸引力。不过我对戴眼镜与否影响这么大感到很意外,好奇是不是因为戴眼镜一般会给人产生“书呆子”的印象。所以我又查了些资料,发现还真有这么一回事,有篇研究论文讲到大多数人认为不管男性还是女性,戴眼镜会降低自身吸引力。
有些变量对于能否成功约会可能比较有预测力,不过很难确定,因为样本较小:
留学生比加拿大本地学生的约会成功率要高
亚洲人和其它人种相比约会机会更少
纵览其它因素,虽然女生很少,计算机专业的男生似乎并不处于劣势
剩下的变量(身高/事业/有趣性/社交性/时尚/居住地)这些和成功约会的关系不是很大。不好意思,哪怕你在 Facebook 上班,该没女票还是没有。
本次实验的完整结果:
接着我们检查各变量之间的关系,这可以帮我们识别出不正确的模型假设。红色表示正相关,蓝色表示负相关。我们只展示统计显著性 <0.1 的相关性,因此大部分变量之间的关系为空白。
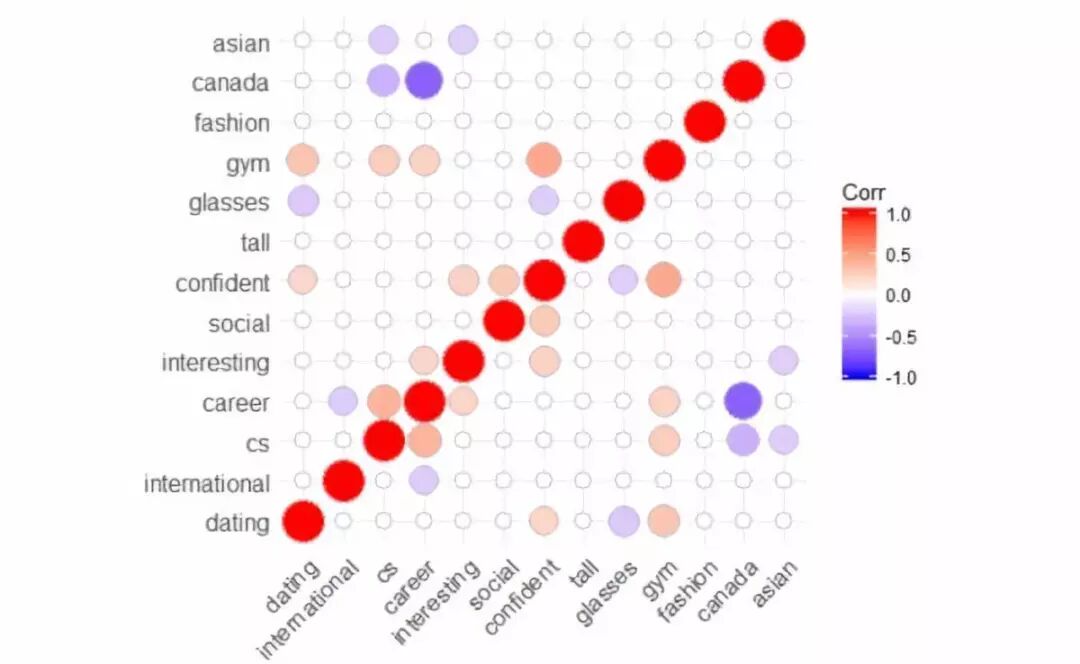
从图中看起来{有女朋友,看起来自信,去健身房,不戴眼镜}有相互关系。
在接着往下看之前,我得强调一下我的这些朋友不能代表滑铁卢大学的整体情况。我平时都是在课堂上或工作中认识的他们(虽然什么样的人都有,但都是从事计算机相关的事情),要么是熟人(虽然来自不同专业,但大部分来自东亚地区,在加拿大生活)。
用这些数据训练后的模型也会反应这些偏差,未来我也会扩大调查范围,收集更多数据。
用逻辑回归预测找女票
要是有个算法能够预测你有多大几率可以找到女票,岂不美哉?我们试试!
我训练了一个逻辑回归广义线性模型,根据我们前文列举的这些说明变量预测是否会有女票。借助 R 语言中的 glmnet 和 caret 包,我用弹性网络正则化训练了这个广义线性模型。然后用标准网格搜索法优化了超参数,在每次迭代中使用留一交叉验证法,并优化 kappa 系数。
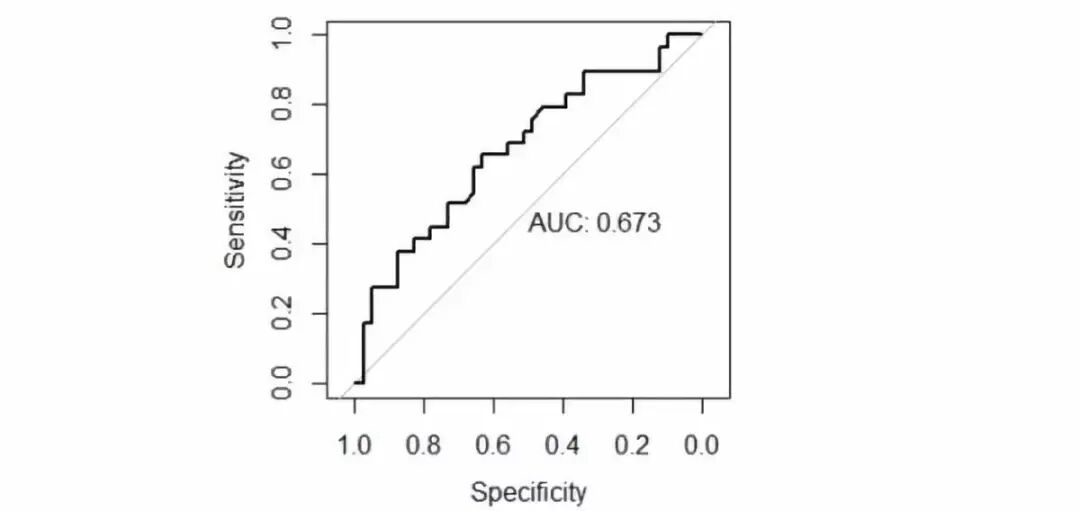
最终模型的交叉验证 ROC AUC 分数为 0.673,也就是说模型在预测你找到女票的几率方面,比你凭感觉乱猜还是更靠谱些。当然了,生活中总会有些偶然的不确定因素,人生也会有惊喜嘛。
好了不说了,我去健身房了,还要努力摘掉眼镜!
后话:小哥在原文中将自己的模型分享了出来(很可能已经找到另一半所以也不藏私了),用它就能测试自己在滑铁卢大学找到女票的概率。奈何打开链接后,目前已无法获取模型。如果后期能正常访问,我们会把这款能预测你“姻缘”的模型分享给大家。当然了,如果你能自己创建一款这样可以预测桃花运概率的AI“半仙”,那是坠吼滴!
参考资料: Learning to find a Girlfriend at the University of Waterloo by Logistic Regression
https://medium.com/@uw_data_scientist/learning-to-find-a-girlfriend-at-the-university-of-waterloo-by-logistic-regression-18a0d22da896
识别下图二维码,加“数盟社区”为好友,回复暗号“入群”,加入数盟社区交流群,群内持续有干货分享~~

媒体合作请联系:
邮箱:xiangxiaoqing@stormorai.com










