夏乙 栗子 编译自 Khanna.cc
量子位 报道 | 公众号 QbitAI

想要训练个深度神经网络,也准备好了可以直接用的数据,要从哪里开始上手?
来自美国的Harry Khanna,精心编织了一套六步法。大家可以瞻仰一下,然后决定要不要行动。
整个过程中,过拟合的问题时时刻刻都要注意。
1. 选个损失函数
选择怎样的损失函数,取决于需要解决怎样的问题。
如果是回归问题,就可以用均方误差 (MSE) 损失函数。

如果是分类问题,就用交叉熵 (Cross-Entropy) 损失函数。
只有两类的话,要用二值交叉熵 (Binary Cross-Entropy) 。
如果遇到了不常见的问题,比如一次性学习 (One-Shot Learning) ,可能就要自行定制一个损失方程了。
2. 选个初始架构
说到结构化学习,比如预测销售情况,从全连接的隐藏层开始,是个不错的选择。
这一层的激活数 (Number of Activations) ,要在输入神经元与输出神经元的数量之间。
两者取个平均数,就可以。
像下面这样的取法,也可以。
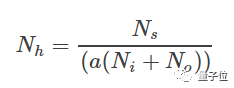
Ni,是输入神经元数。
No,是输出神经元数。
Ns,训练集里的样本数。
a,尺度因子,在2到10之间选。
对计算机视觉领域的小伙伴来说,像ResNet这样的架构,就很友好。
3. 拟合训练集
这一步,最重要的超参数,是学习率 (Learning Rate) (α) 。
不需要试错,fast.ai的库里面,有一个rate finder。

只要写两行代码,就可以得到一个学习率的曲线。
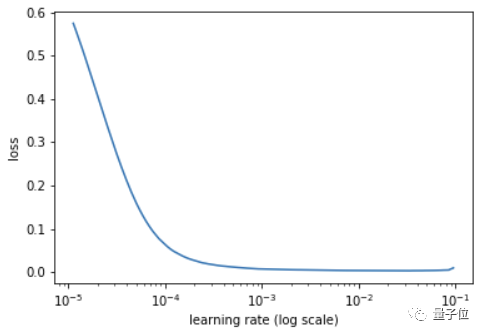
在损失还在明显下降的区域,选取学习率——
比如,最陡部分的旁边一点点,损失仍在剧烈下降,没有到平坦的地方。
上图的话,10-4就可以。
如果,模型训练还是很慢,或者效果不好的话,可以用Adam优化,代替初始架构里的随机梯度下降 (SGD) 优化。
这时候,如果模型还是不能和训练集愉快玩耍,考虑一下学习率衰减 (Learning Rate Decay) ——
有指数衰减,离散阶梯衰减 (Discrete Staircase Decay) ,甚至还有一些手动方法,人类可以在损失不再下降的时候,自己把学习率 (α) 往下调。
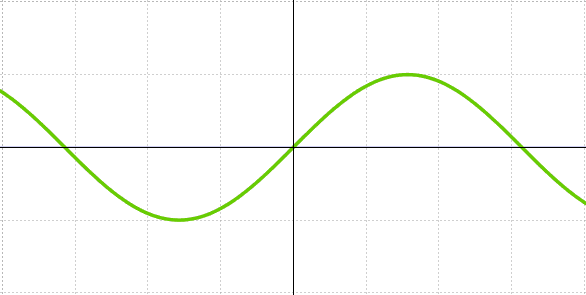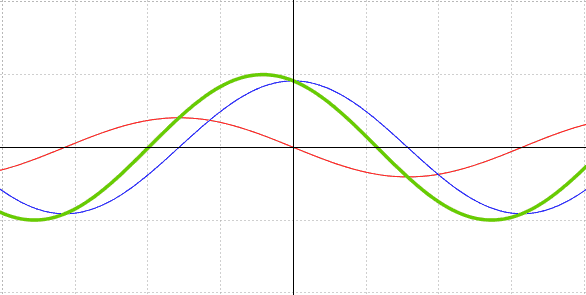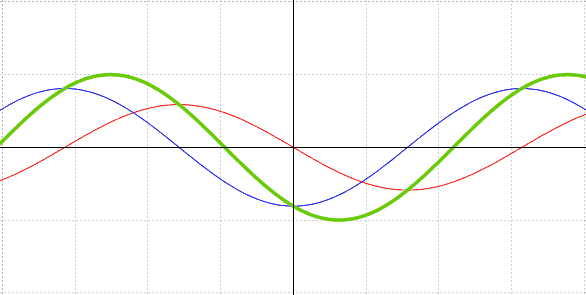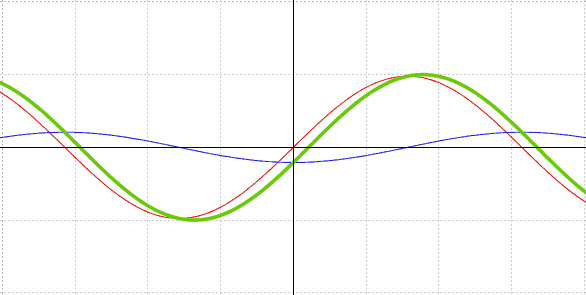
其中,余弦型 (Cosine) 衰减,在一个回合 (Epoch) 开始的时候,衰减最慢,中间最快,结束时又最慢。
然后,可以加上一个“重启 (Restart) ”功能。这样,每 (几) 个回合开始时,学习率都会回到没有衰减的状态。
迁移学习的话,要把开始几层解冻 (Unfreeze) ,然后用差分学习率来训练神经网络。
如果,训练集还是不开心,还有另外几个超参数可以调整——
· 隐藏层的unit数
· 小批量 (Minibatch) 的大小:64,128,256,512……
· 隐藏层数
还不行的话,就要看目标能不能再细化一下。

输入的训练数据,可能并没有预测输出值所需的有效信息。
举个栗子,仅仅基于股票的历史价格,来预测未来走势,就很难。
4. 拟合验证集
这一步,是最难的,也最花时间。
怎样才能解决训练集上的过拟合问题?
丢弃 (Dropout)
把训练集中的一些神经元,随机清零。

那么,概率 (p) 要怎么设置?
虽然,没有万能之法,但还是有一些可以尝试的方法——
找到p=0.25的最后一个线性层,对这之前 (包含本层) 的那些层,执行随机抛弃。
然后,在把p往上调到0.5的过程中,实验几次。
如果还是不行,就给再往前的线性层,也执行随机丢弃操作,还是用p=0.25到0.5之间的范围。

并没有通天大法,所以有时候还是要试错,才能知道在哪些层里,取多大的p,更有效。
权重衰减/L2正则化 (Weight Decay/ L2 Regularization)
第二小步,加上权重衰减。就是在损失函数里面添加一项——
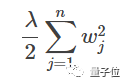
λ,是正则化超参数。
wj,是权重矩阵w里面的特征j。
n,是权重矩阵w里的特征数。
过拟合的其中一个原因,就是权重大。而权重衰减,可以有效打击大权重。
输入归一化 (Normalize Inputs)
减少过拟合的第三小步,就是把输入特征的均值和方差,各自除以训练集,归一化。
特征x1除以训练样本总数m,要等于0,方差要等于1。x2,x3…也一样。
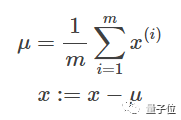
μ向量,维数等于单个训练样本的输入特征数。
x是一个n x m矩阵,n是输入特征数,m是训练样本数。
x-μ,就是x的每一列都要减掉μ。
标准差归一化的公式,看上去就比较熟悉了——
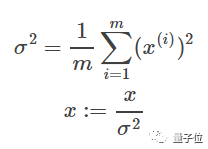
注意,要归一化的是,除以训练样本总数m,之后的均值和方差,不是除以每个样本的特征数n。
再注意,是用训练集的均值和方差,不是验证集。
批量归一化 (Batch Normalization)
上一小步,归一的是输入特征,而这里,要把隐藏层神经元的均值和方差归一化。
和之前一样的是,用了训练集的均值和方差,来调教验证集。

△ 不支持一次吃太多
不同的是,要一小批一小批地进行,并非整个训练集一步到位。
这种情况下,可以使用均值和方差的指数加权平均 (exponentially weighted average) ,因为有很多的均值,和很多的方差。
多点训练数据、数据扩增
根据经验,过拟合最好的解决办法,就是增加训练数据,继续训练。
如果没有太多数据,就只好做数据扩增。计算机视觉最爱这种方法,调光,旋转,翻转等等简单操作,都可以把一张图变成好几张。

不过,在结构化数据和自然语言处理中,数据扩增就没有什么栗子了。
梯度消失,梯度爆炸
梯度消失 (Vanishing Gradients) ,是指梯度变得很小很小,以至于梯度下降的学习效果不怎么好。
梯度爆炸 (Exploding Gradients) ,是指梯度变得很大很大,超出了设备的计算能力。
解决这两个问题,第一条路,就是用一种特殊的方式把权重矩阵初始化——名曰“He Initialization”。
不是第三人称,是出自何恺明等2015年的论文:
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification。
把权重矩阵W[l],变成一个均值为零的高斯分布。标准差长这样:
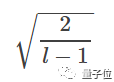
效果意想不到的好,梯度消失和爆炸,都少有发生了。
如果是训练自然语言处理RNN,LSTM是首选,也是一种减少梯度消失或爆炸的方式。
出现NaN,很可能就是梯度爆炸了。

一个简单粗暴的处理方式是,梯度裁剪 (Gradient Clipping) ,给梯度设一个上限。超出了限制,梯度就会被切。
神经网络架构搜索
有时候调整超参数没什么用,不管怎么调,验证集的loss还是比训练集高好多。
这时候就该好好看看神经网络的架构了。
输入里有太多特征、隐藏层太多激活数,都可能会导致神经网络拟合了训练集里的噪音。

这时候就要调整隐藏层的神经元数量,或者增减隐藏层的数量。
这个过程需要试错,可能要试过很多架构才能找到一个好用的。
5. 在测试集上检验性能
当神经网络在训练集和验证集上都表现良好,要保持警惕:优化过程中,有可能一不小心在验证集上过拟合了。
上一步拟合验证集时,超参数都向着在验证集上优化的方向调整。于是,这些超参数有可能将验证集中的噪音考虑了进去,模型对新数据的泛化能力可能很差。
所以,到了这一步,就要在一个没见过的测试集上来运行神经网络,确认还能取得和验证集上一样的成绩。

如果在测试集上表现不好,就要通过增加新数据或者数据增强(data augmentation)的方式,扩大验证集规模。
然后重复第4、5步。
注意:不要根据测试集损失来调整超参数!这样只能得到一个对训练集、验证集和测试集都过拟合了的模型。
6. 在真实世界中检验性能
如果你训练了一个猫片识别器,就喂它一些你的猫片;

如果你训练了一个新闻稿情绪识别器,就喂它一些微软最近的新闻。
如果这个神经网络在训练、验证、测试集上表现都不错,到了现实世界却是个渣渣,那一定出了什么问题。比如说,有可能过拟合了测试集。
这时候就需要换个验证集、测试集,看看模型表现怎么样。如果这个现实世界的渣渣依然表现良好,那么问题可能出在损失函数身上。
这种情况,还是挺少见的。
一般只要成功熬到第6步,模型在现实世界里都挺厉害的。
来,我们回顾一下
刚才讲的这么多,最后可以汇集成下面这个checklist:
第1步:损失函数
回归问题用MSE
多类别分类问题用交叉熵
二分类问题用二值交叉熵
第2步:初始神经网络架构
第3步:训练集
第4步:验证集
Dropout
L2正则化
输入特征归一化
批量归一化
数据扩增
为训练集补充数据
梯度消失或爆炸
调整神经网络架构
第5步:测试集
第6步:真实世界

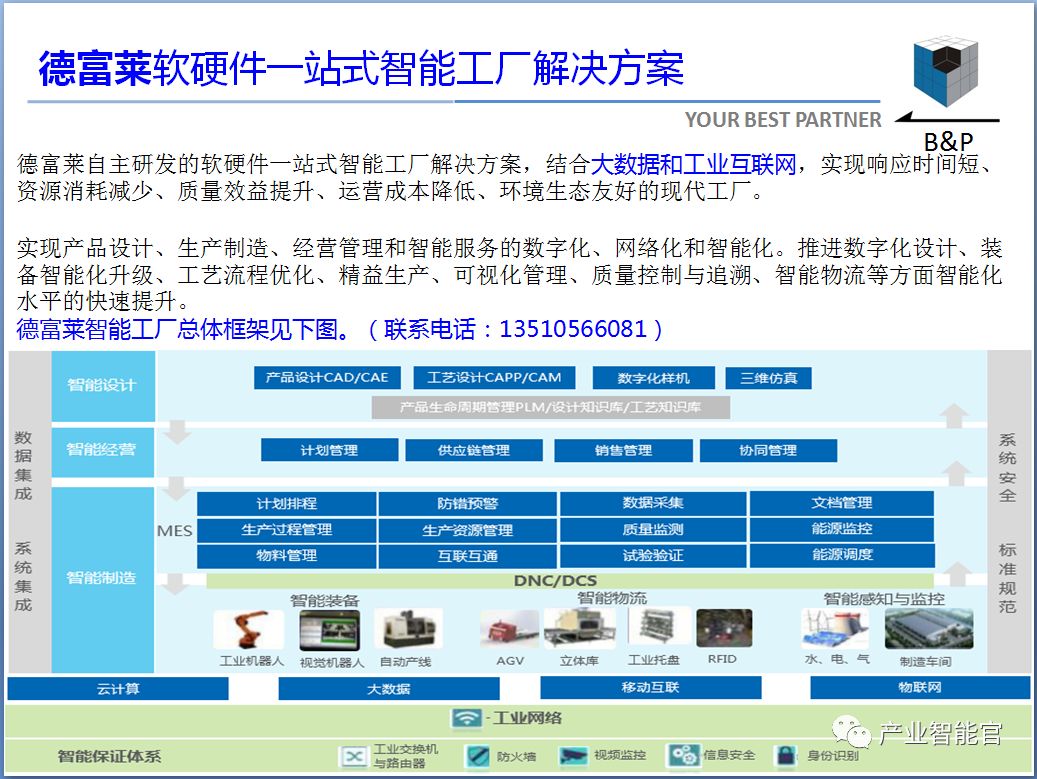
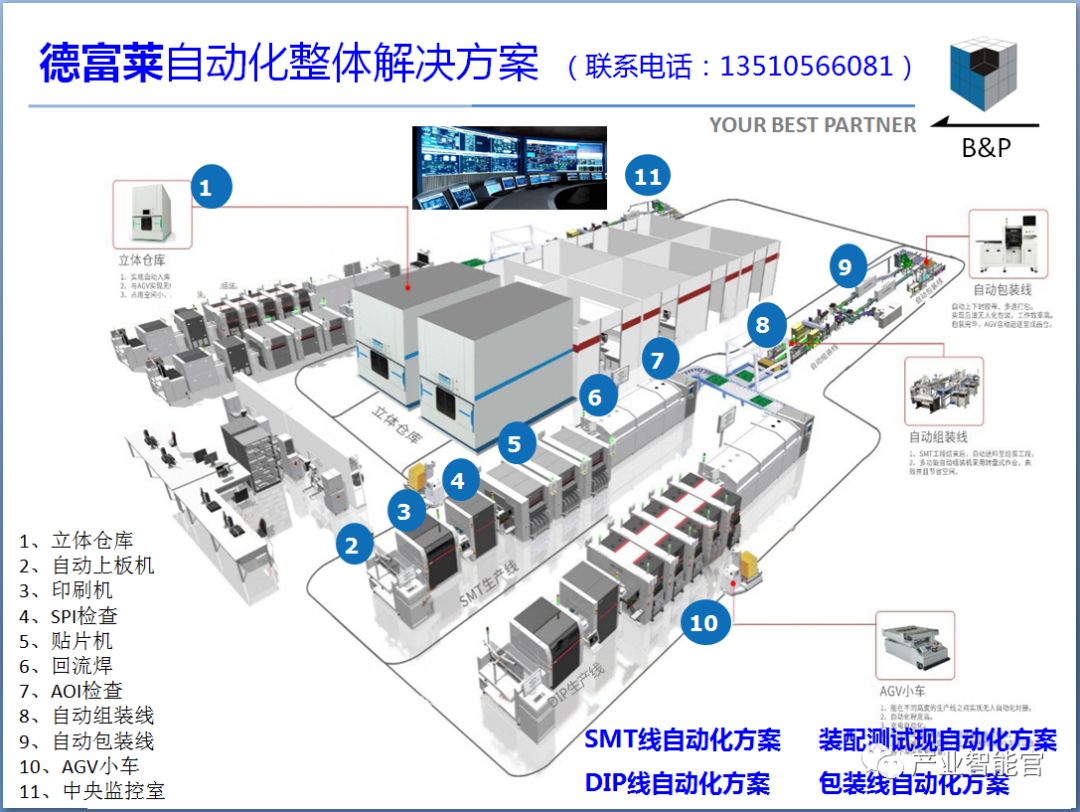

工业互联网操作系统
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业工业互联网操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com








