Docker 作为轻量级容器技术解决应用容器化已经为广大用户使用,涵盖了应用的编译、打包、部署、测试等整个周期。镜像为运行 Docker 容器提供了基础和重要的前提,Docker Registry 提供了一个存储、分发、管理 Docker 镜像的仓库服务,在某些场景下,如跨国部署场景,要求镜像仓库服务提供更高效的上传下载,同时降低复杂度和具备服务高可用。因此,本文设计了一种镜像仓库服务的去中心化的新思路。Docker 是一种面向应用开发和运维人员的开发、部署和运行的容器平台,相对于 Virtual Machine 更加轻量,底层使用 Linux Namespace(UTS、IPC、PID、Network、Mount、User)和 cgroups(Control Groups)技术对应用进程进行虚拟化隔离和资源管控,并拥有灵活性、轻量、可扩展性、可伸缩性等特点。Docker 容器实例从镜像加载,镜像包含应用所需的所有可执行文件、配置文件、运行时依赖库、环境变量等,这个镜像可以被加载在任何 Docker Engine 机器上。越来越多的开发者和公司都将自己的产品打包成 Docker 镜像进行发布和销售。
在 Docker 生态中,提供存储、分发和管理镜像的服务为 Docker Registry 镜像仓库服务,是 Docker 生态重要组成部分,我甚至认为这是 Docker 流行起来最重要的原因。用户通过 docker push 命令把打包好的镜像发布到 Docker Registry 镜像仓库服务中,其他的用户通过 docker pull 从镜像仓库中获取镜像,并由 Docker Engine 启动 Docker 实例。
Docker Registry 镜像仓库,是一种集中式存储、应用无状态、节点可扩展的 HTTP 公共服务。提供了镜像管理、存储、上传下载、AAA 认证鉴权、WebHook 通知、日志等功能。几乎所有的用户都从镜像仓库中进行上传和下载,在跨国上传下载的场景下,这种集中式服务显然存在性能瓶颈,高网络延迟导致用户 pull 下载消耗更长的时间。同时集中式服务遭黑客的 DDos 攻击会面临瘫痪。当然你可以部署多个节点,但也要解决多节点间镜像同步的问题。因此,可以设计一种去中心化的分布式镜像仓库服务来避免这种中心化的缺陷。
本文起草了一个纯 P2P 式结构化网络无中心化节点的新镜像仓库服务 Decentralized Docker Registry(DDR),和阿里的蜻蜓 Dragonfly、腾讯的 FID 混合型 P2P 模式不同,DDR 采用纯 P2P 网络结构,没有镜像 Tracker 管理节点,网络中所有节点既是镜像的生产者同时也是消费者,纯扁平对等,这种结构能有效地防止拒绝服务 DDos 攻击,没有单点故障,并拥有高水平扩展和高并发能力,高效利用带宽,极速提高下载速度。
Docker 是一个容器管理框架,它负责创建和管理容器实例,一个容器实例从 Docker 镜像加载,镜像是一种压缩文件,包含了一个应用所需的所有内容。一个镜像可以依赖另一个镜像,并是一种单继承关系。最初始的镜像叫做 Base 基础镜像,可以继承 Base 镜像制作新镜像,新镜像也可以被其他的镜像再继承,这个新镜像被称作 Parent 父镜像。
而一个镜像内部被切分称多个层级 Layer,每一个 Layer 包含整个镜像的部分文件。当 Docker 容器实例从镜像加载后,实例将看到所有 Layer 共同合并的文件集合,实例不需要关心 Layer 层级关系。镜像里面所有的 Layer 属性为只读,当前容器实例进行写操作的时候,从旧的 Layer 中进行 Copy On Write 操作,复制旧文件,产生新文件,并产生一层可写的新 Layer。这种 COW 做法能最大化节省空间和效率,层级见也能充分复用。一个典型的镜像结构如下:

alpine 是基础镜像,提供了一个轻量的、安全的 Linux 运行环境,Basic App1 和 Basic App2 都基于和共享这个基础镜像 alpine,Basci App 1/2 可作为一个单独的镜像发布,同时也是 Advanced App 2/3 的父镜像,在 Advanced App 2/3 下载的时候,会检测并下载所有依赖的父镜像和基础镜像,而往往在 registry 存储节点里,只会存储一份父镜像实例和基础镜像,并被其他镜像所共享,高效节省存储空间。
一个镜像内部分层 Layer 结构如下:
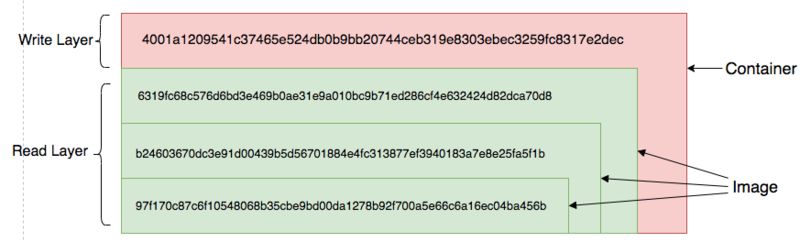
Advanced App1 内部文件分为 4 个 layer 层存储,每一个层 Layer 为 application/vnd.docker.image.rootfs.diff.tar.gzip 压缩类型文件,并通过文件 sha256 值标识,所有 layer 层的文件组成了最终镜像的内容,在容器从镜像启动后,容器实例看到所有 layer 层的文件内容。如其中一层 Layer 存储如下:
$ file /var/lib/registry/docker/registry/v2/blobs/sha256/40/4001a1209541c37465e524db0b9bb20744ceb319e8303ebec3259fc8317e2dec/data
data: gzip compressed data
$ sha256sum /var/lib/registry/docker/registry/v2/blobs/sha256/40/4001a1209541c37465e524db0b9bb20744ceb319e8303ebec3259fc8317e2dec/data
4001a1209541c37465e524db0b9bb20744ceb319e8303ebec3259fc8317e2dec
其中实现这种分层模型的文件系统叫 UnionFS 联合文件系统,实现有 AUFS、Overlay、Overlay2 等,UnionFS 分配只读目录、读写目录、挂载目录,只读目录类似镜像里的只读 Layer,读写目录类似可写 Layer,所有文件的合集为挂载目录,即挂载目录是一个逻辑目录,并能看到所有的文件内容,在 UnionFS 中,目录叫做 Branch,也即镜像中的 Layer。
使用 AUFS 构建一个 2 层 Branch 如下:
$ mkdir /tmp/rw /tmp/r /tmp/aufs
$ mount -t aufs -o br=/tmp/rw:/tmp/r none /tmp/aufs
创建了 2 个层级目录分别是 /tmp/rw 和 /tmp/r,同时 br= 指定了所有的 branch 层,默认情况下 br=/tmp/rw 为可写层,: 后面只读层,/tmp/aufs 为最终文件挂载层,文件目录如下:
$ ls -l /tmp/rw/
-rw-r--r-- 1 root root 23 Mar 25 14:21 file_in_rw_dir
$ ls -l /tmp/r/
-rw-r--r-- 1 root root 26 Mar 25 14:20 file_in_r_dir
$ ls -l /tmp/aufs/
-rw-r--r-- 1 root root 26 Mar 25 14:20 file_in_r_dir
-rw-r--r-- 1 root root 23 Mar 25 14:21 file_in_rw_dir
可以看到挂载目录 /tmp/aufs 下显示了 /tmp/rw 和 /tmp/r 目录下的所有文件,通过这种方式实现了镜像多层 Layer 的结构。除了 UnionFS 能实现这种模型,通过 Snapshot 快照和 Clone 层也能实现类似的效果,如 Btrfs Driver、ZFS Driver 等实现。
Docker Registry 镜像仓库存储、分发和管理着镜像,流行的镜像仓库服务有 Docker Hub、Quary.io、Google Container Registry。每一个用户可以在仓库内注册一个 namespace 命名空间,用户可以通过 docker push 命令把自己的镜像上传到这个 namespace 命名空间,其他用户则可以使用 docker pull 命令从此命名空间中下载对应的镜像,同时一个镜像名可以配置不同的 tags 用以表示不同的版本。
当要上传镜像时,Docker Client 向 Docker Daemon 发送 push 命令,并传入本地通过 docker tag 打包的上传地址,即 ://:,创建对应的 manifest 元信息,元信息包括 docker version、layers、image id 等,先通过 HEAD /blob/ 检查需要上传的 layer 在 Registry 仓库中是否存在,如果存在则无需上传 layer,否则通过 POST /blob/upload 上传 blob 数据文件,Docker 使用 PUT 分段并发上传,每一次上传一段文件的 bytes 内容,最终 blob 文件上传完成后,通过 PUT /manifest/ 完成元数据上传并结束整个上传过程。

当用户执行 docker pull 命令时,Docker Client 向 Docker Daemon 发送 pull 命令,如果不指定 host 名字,默认 docker daemon 会从 Docker hub 官方仓库进行下载,如果不指定 tag,则默认为 latest。首先向 Docker Hub 发送 GET /manifest/ 请求,Docker Hub 返回镜像名字、包含的 Layers 层等信息,Docker Client 收到 Layers 信息后通过 HEAD /blob/ 查询 Docker Registry 对应的 blob 是否存在,如果存在,通过 GET /blob/ 对所有 Layer 进行并发下载,默认 Docker Client 会并发对 3 个 blob 进行下载,最后完成整个下载过程,镜像存入本地磁盘。
P2P 网络从中心化程度看分为纯 P2P 网络和混合 P2P 网络,纯 P2P 网络没有任何形式中心服务器,每一个节点在网络中对等,信息在所有节点 Peer 中交换,如 Gnutella 协议。混合 P2P 网络的 Peer 节点外,还需要维护着一个中心服务器保存节点、节点存储内容等信息以供路由查询,如 BitTorrent 协议。
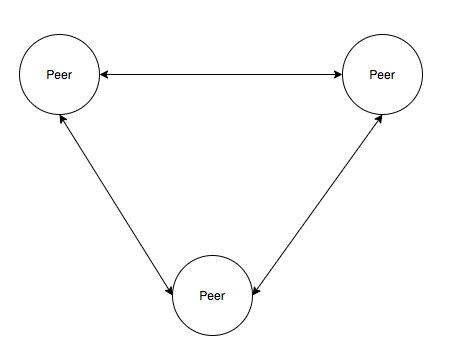
纯 P2P 网络
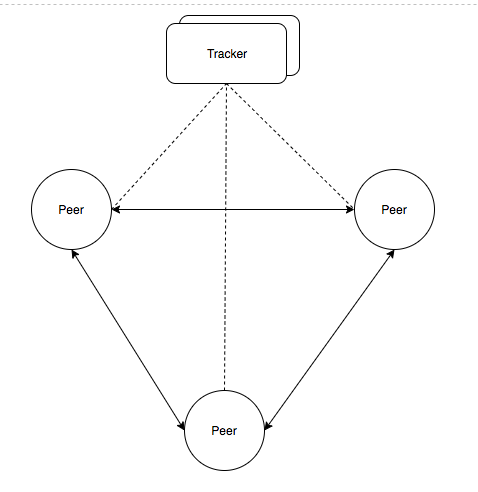
混合 P2P 网络
P2P 网络从网络组织结构看又分为结构化 P2P 网络和非结构 P2P 网络,Peer 节点之间彼此之间无规则随机连接生成的网状结构,称之为非结构 P2P,如 Gnutella 。而 Peer 节点间相互根据一定的规则连接交互,称之为结构 P2P,如 Kademlia。
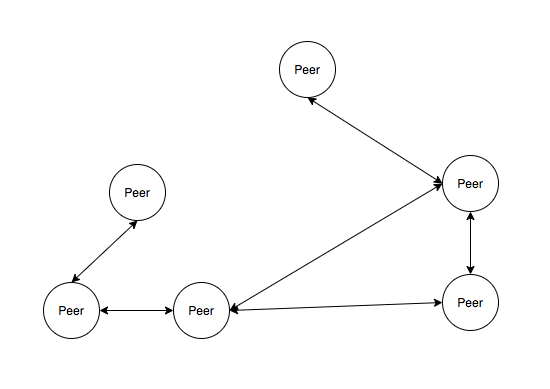
非结构 P2P,之间无序不规则连接
结构 P2P,按照一定的规则相互互联
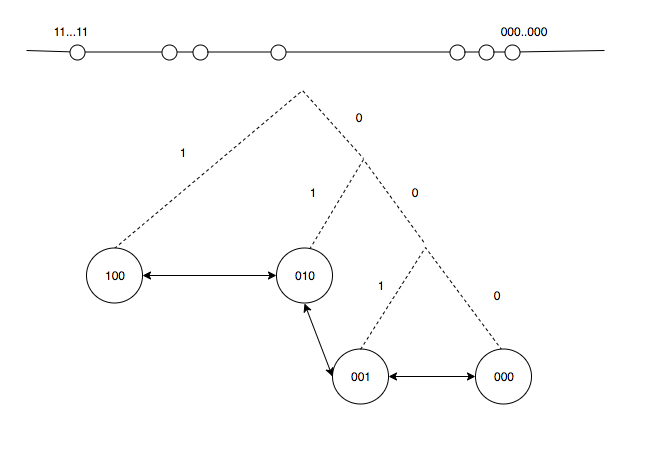
DDR 镜像仓库服务系统采用纯网络和 DHT(Distribution Hash Table) 的 Kademlia 结构化网络实现,根据 Kademlia 的算法,同样为每一个 Peer 节点随机分配一个与镜像 Layer 标示一致的 sha256 值标识,每一个 Peer 节点维护一张自身的动态路由表,每一条路由信息包含了元素,路由表通过网络学习而形成,并使用二叉树结构标示,即每一个 PeerID 作为二叉树的叶子节点,256-bit 位的 PeerID 则包含 256 个子树,每一个子树下包含 2^i(0<=i<=256) 到 2^i+1(0<=i<=255) 个 Peer 节点,如 i=2 的子树包含二进制 000...100、000...101、000...110、000...111 的 4 个节点,每一个这样的子树区间形成 bucket 桶,每一个桶设定最大路由数为 5 个,当一个 bucket 桶满时,则采用 LRU 规则进行更新,优先保证活跃的 Peer 节点存活在路由表中。根据二叉树的结构,只要知道任何一棵子树就能递归找到任意节点。
Kademlia 定义节点之间的距离为 PeerID 之间 XOR 异或运算的值,如 X 与 Y 的距离 dis(x,y) = PeerIDx XOR PeerIDy,这是“逻辑距离”,并不是物理距离,XOR 异或运算符合如下 3 个几何特性:
1. X 与 Y 节点的距离等于 Y 与 X 节点的距离,即 dis(x,y) = dis(y,x),异或运算之间的距离是对称的。
2. X 与 X 节点的距离是 0,异或运算是等同的。
3. X、Y、Z 节点之间符合三角不等式,即 dis(x,y) <= dis(x,z) + dis(z,y)
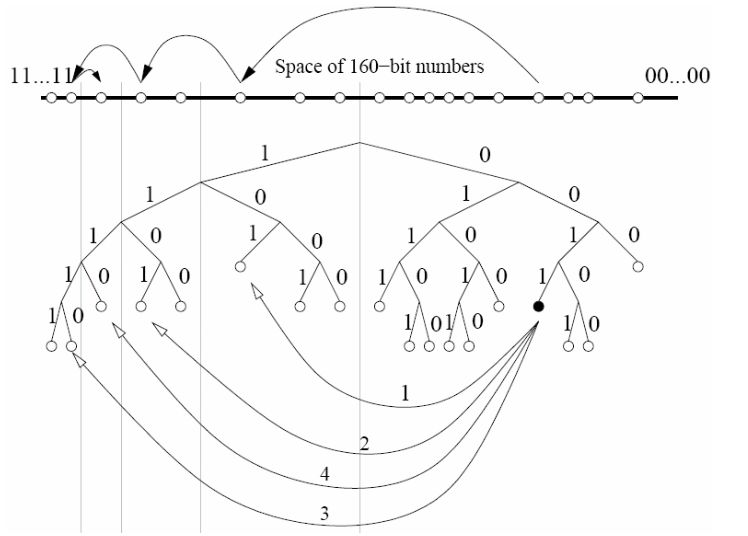
因此,Kademlia 寻址的过程,实际上不断缩小距离的过程,每一个节点 根据自身的路由表信息不断向离目的节点最近的节点进行迭代询问,直到找到目标为止,这个过程就像现实生活中查找一个人一样,先去询问这个人所在的国家,然后询问到公司,再找到部门,最终找到个人。
当节点需要查询某个 PeerID 时,查询二叉树路由表,计算目标 PeerID 在当前哪个子树区间(bucket 桶)中,并向此 bucket 桶中 n(n<=5) 节点同时发送 FIND_NODE 请求,n 个节点收到 FIND_NODE 请求后根据自己的路由表信息返回与目标 PeerID 最接近的节点 PeerID,源节点再根据 FIND_NODE 返回的路由信息进行学习,再次向新节点发送 FIND_NODE 请求,可见每一次迭代至少保证精确一个 bit 位,以此迭代,并最终找到目标节点,查询次数为 logN。
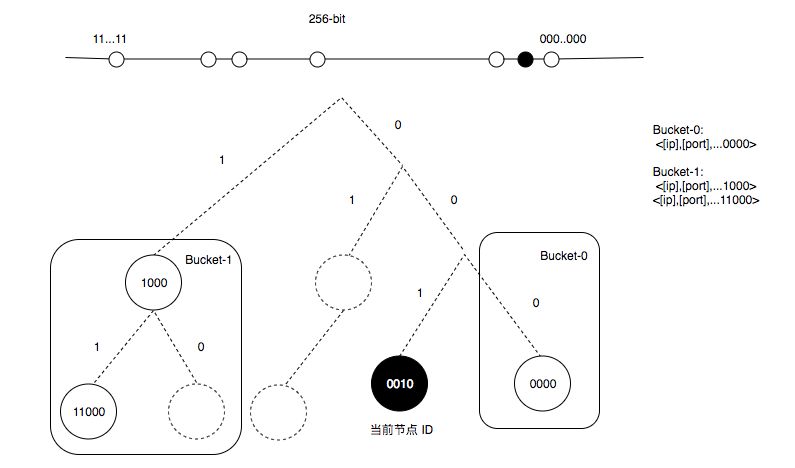
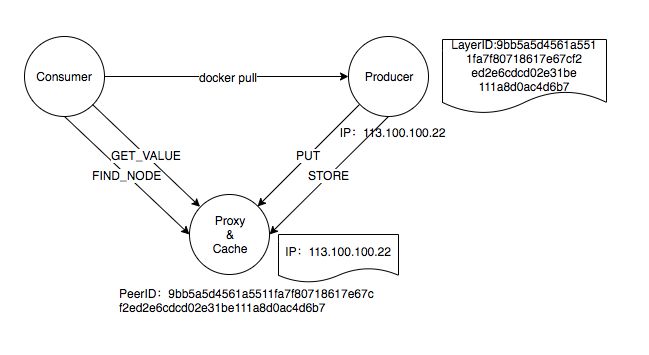
在 DDR 镜像服务中,需要在 Kademlia 网络中需要找到指定的镜像,而 Kademlia 查询只是节点 PeerID 查询,为了查找指定的 sha256 镜像,常用的做法是建立节点 PeerID 和文件 LayerID 的映射关系,但这需要依赖全局 Tracker 节点存储这种映射关系,而并不适合纯 P2P 模式。因此,为了找到对应的镜像,使用 PeerID 存储 LayerID 路由信息的方法,即同样或者相近 LayerID 的 PeerID 保存真正提供 LayerID 下载的 PeerID 路由,并把路由信息返回给查询节点,查询节点则重定向到真正的 Peer 进行镜像下载。在这个方法中,节点 Peer 可分为消费节点、代理节点、生产节点、副本节点 4 种角色,生产节点为镜像真正制作和存储的节点,当新镜像制作出来后,把镜像 Image Layer 的 sha256 LayerID 作为参数进行 FIND_NODE 查询与 LayerID 相近或相等的 PeerID 节点,并推送生产节点的 IP、Port、PeerID 路由信息。这些被推送的节点称为 Proxy 代理节点,同时代理节点也作为对生产节点的缓存节点存储镜像。当消费节点下载镜像 Image Layer 时,通过 LayerID 的 sha256 值作为参数 FIND_NODE 查找代理节点,并向代理节点发送 FIND_VALE 请求返回真正镜像的生产节点路由信息,消费节点对生产节点进行 docker pull 镜像拉取工作。
在开始 docker pull 下载镜像时,需要先找到对应的 manifest 信息,如 docker pull os/centos:7.2,因此,在生成者制作新镜像时,需要以 /: 作为输入同样生成对应的 sha256 值,并类似 Layer 一样推送给代理节点,当消费节点需要下载镜像时,先下载镜像 manifest 元信息,再进行 Layer 下载,这个和 Docker Client 从 Docker Registry 服务下载的流程一致。
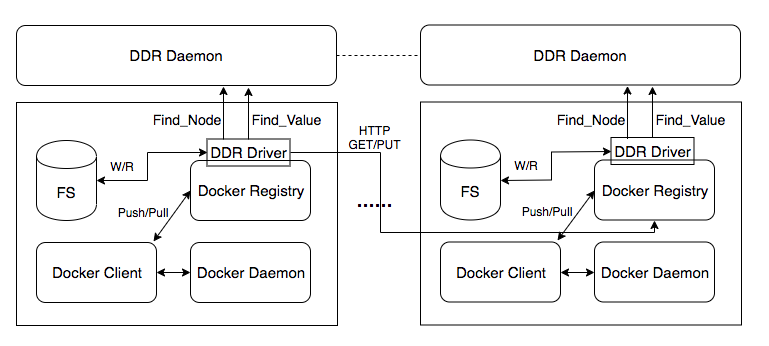
每一个节点都部署 Docker Registry 和 DDR,DDR 分为 DDR Driver 插件和 DDR Daemon 常驻进程,DDR Driver 作为 Docker Registry 的存储插件承接 Registry 的 blob 和 manifest 数据的查询、下载、上传的工作,并与 DDR Daemon 交互,主要对需要查询的 blob 和 manifest 数据做 P2P 网络寻址和在写入新的 blob 和 manifest 时推送路由信息给 P2P 网络中代理节点。DDR Daemon 作为 P2P 网路中一个 Peer 节点接入,负责 Peer 查询、Blob、Manifest 的路由查询,并返回路由信息给 DDR Driver,DDR Driver 再作为 Client 根据路由去 P2P 网络目的 Docker Registry 节点进行 Push/Pull 镜像。
docker registry 镜像仓库服务采用可扩展性的设计,允许开发者自行扩展存储驱动以实现不同的存储要求,当前仓库官方支持内存、本地文件系统、S3、Azure、swift 等多个存储,DDR Driver 驱动实现如下接口 (registry/storage/driver/storagedriver.go):
// StorageDriver defines methods that a Storage Driver must implement for a
// filesystem-like key/value object storage. Storage Drivers are automatically
// registered via an internal registration mechanism, and generally created
// via the StorageDriverFactory interface (https://godoc.org/github.com/docker/distribution/registry/storage/driver/factory).
// Please see the aforementioned factory package for example code showing how to get an instance
// of a StorageDriver
type StorageDriver interface {
Name() string
GetContent(ctx context.Context, path string) ([]byte, error)
PutContent(ctx context.Context, path string, content []byte) error
Reader(ctx context.Context, path string, offset int64) (io.ReadCloser, error)
Writer(ctx context.Context, path string, append bool) (FileWriter, error)
Stat(ctx context.Context, path string) (FileInfo, error)
List(ctx context.Context, path string) ([]string, error)
Move(ctx context.Context, sourcePath string, destPath string) error
Delete(ctx context.Context, path string) error
URLFor(ctx context.Context, path string, options map[string]interface{}) (string, error)
Walk(ctx context.Context, path string, f WalkFn) error
}
Docker Client 向本地 Docker Registry 上传一个镜像时会触发一系列的 HTTP 请求,这些请求会调用 DDR Driver 对应的接口实现,DDR 上传流程如下:
Client 通过 HEAD /v2/hello-world/blobs/sha256:9bb5a5d4561a5511fa7f80718617e67cf2ed2e6cdcd02e31be111a8d0ac4d6b7 判断上传的 blob 数据是否存在,如果本地磁盘不存在,Registry 返回 404 错误;
POST /v2/hello-world/blobs/uploads/ 开始上传的 blob 数据;
PATCH /v2/hello-world/blobs/uploads/ 分段上传 blob 数据;
PUT /v2/hello-world/blobs/uploads/ 完成分段上传 blob 数据,DDR 根据 blob 文件的 sha256 信息寻找 P2P 网络中与目标 sha256 值相近的 k 个代理节点,发送包含 blob sha256 的 STORE 消息,对端 Peer 收到 sha256 信息后,存储源 Peer 节点 IP、Port、blob sha256 等信息,同时也向代理节点 PUT 上传内容;
HEAD /v2/hello-world/blobs/sha256:9bb5a5d4561a5511fa7f80718617e67cf2ed2e6cdcd02e31be111a8d0ac4d6b7 确认上传的数据是否上传成功,Registry 返回 200 成功;
PUT /v2/hello-world/manifests/latest 完成 manifest 元数据上传,DDR Driver 按照 /manifest/ 做 sha256 计算值后,寻找 P2P 网络中与目标 sha256 值相近的 k 个代理节点,发送包含 manifest sha256 的 STORE 消息,对端 Peer 收到 sha256 信息后,存储源 Peer 节点 IP、Port、blob sha256 等信息同时也向代理节点 PUT 元信息内容;
Docker Client 向本地 Docker Registry 下载镜像时会触发一系列的 HTTP 请求,这些请求会调用 DDR Driver 对应的接口实现,DDR 下载交互流程如下:
GET /v2/hello-world/manifests/latest 返回下某个 的 manifest 源信息,DDR Driver 对 hello-world/manifest/latest 进行 sha256 计算,并向 P2P 网路中发送 FIND_NODE 和 FIND_VALUE 找到代理节点,通过代理节点找到生产节点,并向生产节点发送 GET 请求获取 manifest 元信息。
Client 获取 manifest 元信息后,通过 GET /v2/hello-world/blobs/sha256:e38bc07ac18ee64e6d59cf2eafcdddf9cec2364dfe129fe0af75f1b0194e0c96 获取 blob 数据内容,DDR Driver 以 e38bc07ac18ee64e6d59cf2eafcdddf9cec2364dfe129fe0af75f1b0194e0c96 作为输入,向 P2P 网络中发送 FIND_NODE 和 FIND_VALUE 找到代理节点,通过代理节点找到生产节点,并向生产节点发送 GET 请求获取 blob 数据。
以上就是整个 DDR 完全去中心化 P2P Docker 镜像仓库的设计,主要利用纯网络结构化 P2P 网络实现镜像的 manifest 和 blob 数据的路由存储、查询,同时每一个节点作为一个独立的镜像仓库服务为全网提供镜像的上传和下载。
Docker Registry 在 push/pull 下载的时候需要对 Client 进行认证工作,类似 Docker Client 需要在 DDR Driver 同样采用标准的 RFC 7519 JWT 方式进行认证鉴权。
参考链接:
阿里巴巴 Dragonfly:
https://github.com/alibaba/Dragonfly
腾讯 FID:
https://ieeexplore.ieee.org/document/8064123/
Btrfs Driver:
https://docs.docker.com/storage/storagedriver/btrfs-driver/
ZFS Driver:
https://docs.docker.com/storage/storagedriver/zfs-driver/
JWT:https://jwt.io/
作者简介:
yangjunsss,曾就职于 IBM、青云 QingCloud,现就职于华为,研究方向:容器微服务、IaaS、P2P 分布式。所有文章仅代表个人观点,与所在的公司无关。邮箱 cj.yangjun@gmail.com
活动推荐
面对百万台服务器、千万张网卡、海量的配置项和监控点,怎么第一时间知道故障点在哪里?如何快速判断分析当前故障的影响面和修复途径?怎样在不影响业务的情况下快速修复?也许你早就抛弃了 SSH 和 CLI 的方式去运维一套庞大的基础设施,开始尝试写一些自动化脚本和配置。或者已经搭建了一套自动化的监控平台,并在这条前行的路上不断的踩坑成长。
QCon 上海 2018 邀请到一批与你志同道合的同学,基于实际的项目和开发,分享在大规模基础设施 DevOps 领域的新思路,新架构,新技术。大会8 折报名中,立减 1360 元。有任何问题欢迎咨询票务经理 Hanna,电话:010-84782011,微信:qcon-0410。










