

作者 Ctipsy,转载需授权
《我不是药神》是由文牧野执导,宁浩、徐峥共同监制的剧情片,徐峥、周一围、王传君、谭卓、章宇、杨新鸣等主演 。影片讲述了神油店老板程勇从一个交不起房租的男性保健品商贩程勇,一跃成为印度仿制药“格列宁”独家代理商的故事。
该片于2018年7月5日在中国上映。上映之后获得一片好评,不少观众甚至直呼“中国电影希望”,“《熔炉》、《辩护人》之类写实影片同水准”,诚然相较于市面上一众的抠图贴脸影视作品,《药神》在影片质量上确实好的多,不过我个人觉得《药神》的火爆还有以下几个原因:
影片题材稀少带来的新鲜感,像这类”针砭时弊” 类影视作品,国内太少。
顺应潮流,目前《手机》事件及其带来的影响和国家层面文化自信的号召以及影视作品水平亟待提高的大环境下,《药神》的过审与上映本身也是对该类题材一定程度的鼓励。
演员靠谱、演技扎实,这个没的说,特别是王传君的表现,让人眼前一亮。
本文通过爬取《我不是药神》和《邪不压正》豆瓣电影评论,对影片进行可视化分析。
截止7月13日:《我不是药神》豆瓣评分:8.9 分,猫眼:9.7 分,时光网:8.8 分 。
截止7月13日: 《邪不压正》 豆瓣评分:7.2 分,猫眼:7.4 分,时光网:7.3 分 。
豆瓣的评分质量相对而言要靠谱点,所以本文数据来源也是豆瓣。
0. 需求分析
获取影评数据
清洗分析存储数据
分析展示影评城市来源、情感
分时展示电影评分趋势
当然主要是用来熟练pandas和爬虫及可视化技能
1. 前期准备
1.1 网页分析
豆瓣从2017.10月开始全面禁止爬取数据,仅仅开放500条数据,白天1分钟最多可以爬取40次,晚上一分钟可爬取60次数,超过此次数则会封禁IP地址
tips发现
实际操作发现,点击影片评论页面的后页时,url中的一个参数start会加20,但是如果直接赋予’start’每次增加10,网页也是可以存在的!
1.2 页面布局分析
本次使用xpath解析,因为之前的博客案例用过正则,也用过beautifulsoup,这次尝试不一样的方法。
如下图所示,本此数据爬取主要获取的内容有:
评论用户ID
评论内容
评分
评论日期
用户所在城市
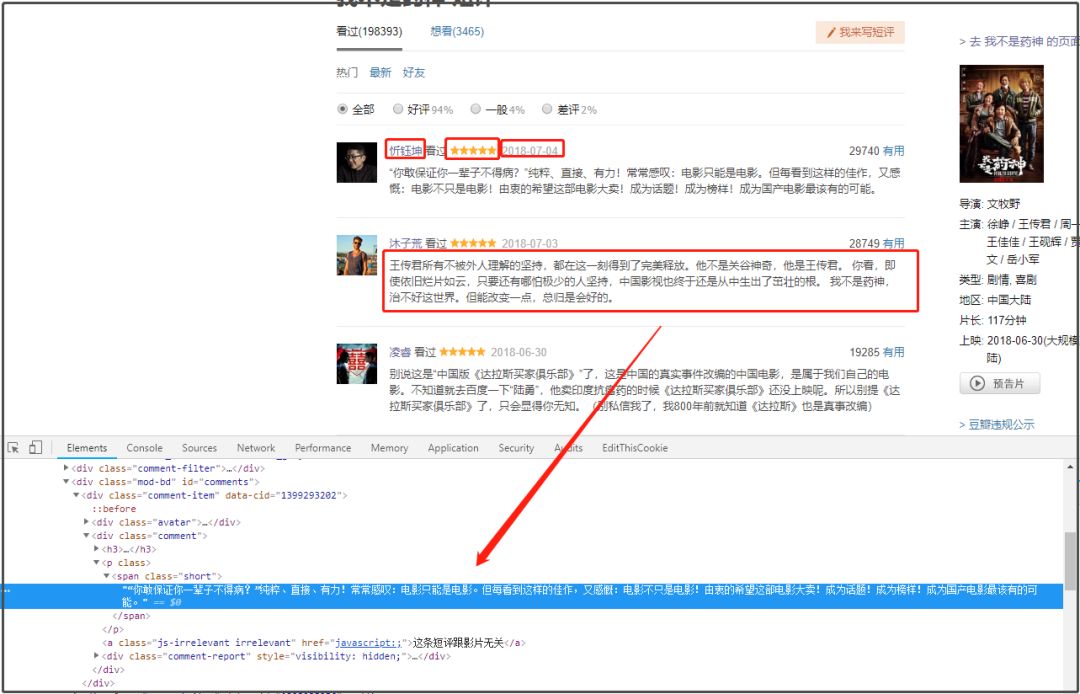
城市信息获取
评论页面没有城市信息,因此需要通过进入评论用户主页去获取城市信息元素。
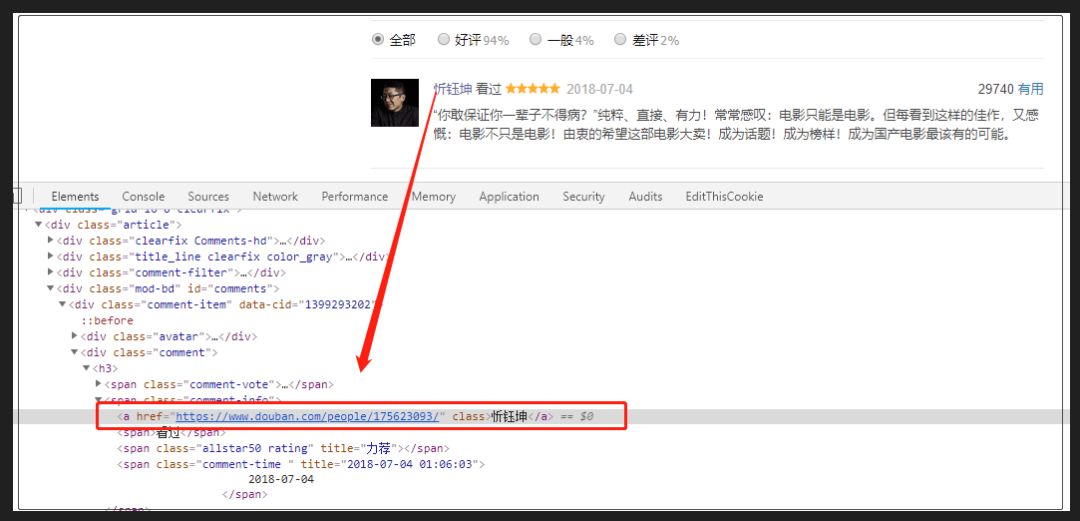
通过分析页面发下,用户ID名称里隐藏着主页链接!所以我的思路就是request该链接,然后提取城市信息。
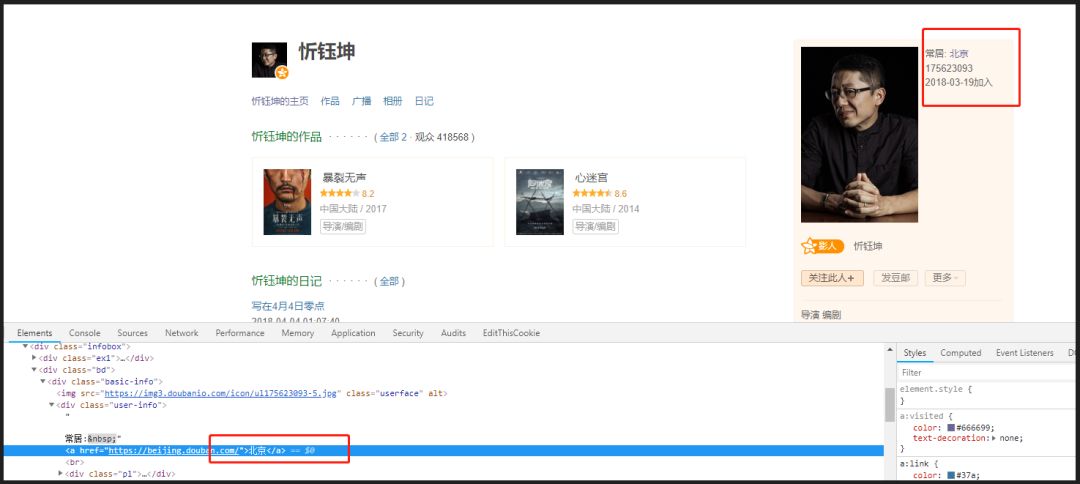
2. 数据获取-爬虫
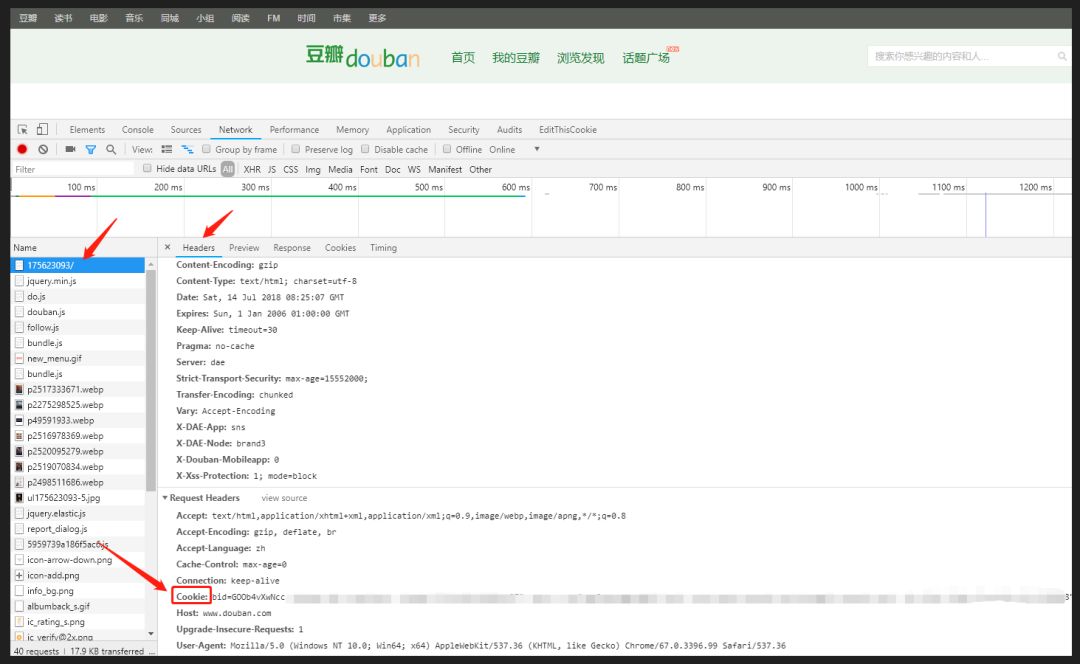
2.1 获取cookies
因为豆瓣的爬虫限制,所以需要使用cookies作身份验证,通过chrome获取cooikes位置如下图:
2.2 加载cookies与headers
下面的cookie被修改了,诸君需要登录后自己获取专属cookieo(∩_∩)o
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
cookies = {'cookie': 'bid=GOOb4vXwNcc; douban-fav-remind=1; viewed="27611266_26886337"; ps=y; ue="citpys原创分享@163.com"; " \
"push_noty_num=0; push_doumail_num=0; ap=1; loc-last-index-location-id="108288"; ll="108288"; dbcl2="187285881:N/y1wyPpmA8"; ck=4wlL'}
url = "https://movie.douban.com/subject/" + str(id) + "/comments?start=" + str(page * 10) + "&limit=20&sort=new_score&status=P"
res = requests.get(url, headers=headers, cookies=cookies)
res.encoding = "utf-8"
if (res.status_code == 200):
print("\n第{}页短评爬取成功!".format(page + 1))
print(url)
else:
print("\n第{}页爬取失败!".format(page + 1))
一般刷新页面后,第一个请求里包含了cookies。
2.3 延时反爬虫
设置延时发出请求,并且延时的值还保留了2位小数(自我感觉模拟正常访问请求会更加逼真…待证实)。
time.sleep(round(random.uniform(1, 2), 2))
2.4 解析需求数据
这里有个大bug,找了好久!
因为有的用户虽然给了评论,但是没有给评分,所以score和date这两个的xpath位置是会变动的。
所以需要加判断,如果发现score里面解析的是日期,证明该条评论没有给出评分。
name = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/text()'.format(i))
# 下面是个大bug,如果有的人没有评分,但是评论了,那么score解析出来是日期,而日期所在位置spen[3]为空
score = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/span[2]/@title'.format(i))
date = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/span[3]/@title'.format(i))
m = '\d{4}-\d{2}-\d{2}'
match = re.compile(m).match(score[0])
if match
is not None:
date = score
score = ["null"]
else:
pass
content = x.xpath('//*[@id="comments"]/div[{}]/div[2]/p/span/text()'.format(i))
id = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/@href'.format(i))
try:
city = get_city(id[0], i) # 调用评论用户的ID城市信息获取
except IndexError:
city = " "
name_list.append(str(name[0]))
score_list.append(str(score[0]).strip('[]\'')) # bug 有些人评论了文字,但是没有给出评分
date_list.append(str(date[0]).strip('[\'').split(' ')[0])
content_list.append(str(content[0]).strip())
city_list.append(city)
2.5 获取电影名称
从url上只能获取电影的subject的8位ID数值,引起需要自行解析网页获取ID号对应的电影名称,该功能是后期改进添加的,因此为避免现有代码改动多(偷个懒),采用了全局变量赋值给movie_name,需要注意全局变量调用时,要加global声明一下。








