机器之心原创
作者:Joshua Chou
审校:王灏
编译:机器之心编辑部
2018 年 7 月 9 日,深度学习大牛 Yoshua Bengio 在多伦多大学的 Bahen 中心发表了一篇题为《Computing Hardware for Emerging Intelligent Sensory Applications》(服务于新兴智能感官应用的计算硬件)的演讲,该演讲是 NSERC 战略网络的一部分,聚焦于缩小深度学习方法与其实际应用之间的差距。
2018 年 AlphaGo Zero 所需的计算量是 2013 年 AlexNet 的 30 万倍。当前数据集空前巨大,模型准确率也很高,在此背景下,深度学习算法的设计需要更多地考虑硬件。
1 QNN:量化神经网络
目前很多研究都聚焦于量化信息以实现低精度的神经网络,Bengio 等研究者的早期研究尝试在训练和推断过程中尽可能降低精度。他们团队在实验中将变量的精度由 32 位降低到 16 位,并尝试组合不同的精度以观察模型准确率在什么时候会导致模型无效。
Bengio 团队发现,当使用低精度的变量训练神经网络时,模型会学习适应这种低精度,这就令神经网络的激活值与权重可以通过量化技术由 32 或 16 位的精度降低到 1、2 或 3 位的精度。
Bengio 团队已经量化了前馈过程,但并不能量化梯度计算。在结束训练时,它们能获得允许在低精度参数上进行推断的神经网络。然而对于需要大量算力的训练过程来说,我们仍然需要高精度变量以计算梯度和反向传播。这主要是因为梯度下降非常慢,且每一次迭代都只能令参数朝着梯度减小的方向逐渐修正一点点,因此更高的精度才能令参数修正更准确。例如,如果系统是二值神经网络,其中权重要么是-1 要么是 1,且我们希望逐渐修正这些权重以获得更好的性能。那么这个「逐渐」的过程就要求我们使用更高的精度从 -1 到 1。
一旦完成训练,系统就不需要再使用高精度而只需要保留符号信息。因为降低了参数精度且保留相同的网络架构,系统会经历一些性能上的损失,而我们需要权衡的就是计算成本与模型准确率。

图 1:Bengio 等人研究的在训练过程中进行位宽缩减的方法。
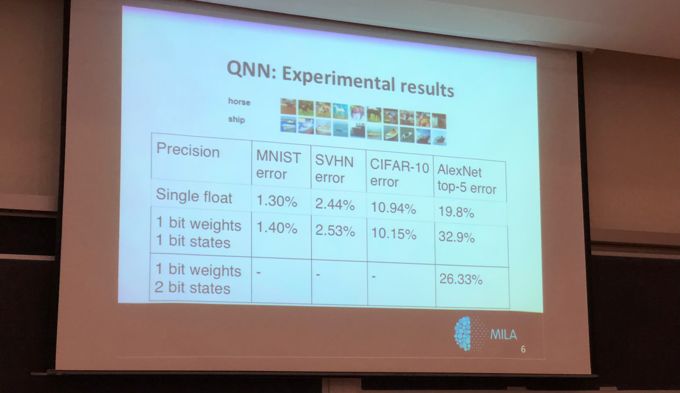
图 2:由 Bengio 提供的展示使用低精度方法得到的误差结果。
2 均衡传播和基于能量的模型
演讲的第二个主题是均衡传播,这是一个填补基于能量的模型(EBM)和反向传播之间鸿沟的模型。Bengio 认为,这是一个研究风险更大的领域(人少、资金少),但有可能给模拟计算系统的设计带来深刻影响。这一概念和方法的灵感来自物理系统,当收敛到静止状态时,合力为零,因此有了「均衡」一词。
2.1 什么是基于能量的模型(EBM)?
首先,简要介绍一下 EBM。EBM 的基础设定是一个动力学的物理系统,这个系统具有能量,即动能。此外,根据热力学定律,此系统将从高能构型变为低能构型。通过一个基于这些原理的神经网络和一个能控制结构随时间改变的能量函数,能量函数往往会收敛到低能构型。如果不同的结构对同一问题有不同解,那这种情况下,「学习」就意味着能量函数的形成,以使对应合适解的构型有更低的能量。
在这里,Bengio 将硬件更多地与问题联系起来。假设有一些物理机器,它们遵循一组微分方程。这些微分方程定义了上述物理系统的动力学。需要研究的数学问题是「如何计算衡量了此物理系统性能的代价函数的梯度」。因为对于这种系统,是无法使用反向传播的标准的基于图像模型(因为该系统具有多个微分方程,用来描述系统如何随时间变化)。为了回答这个问题,可以假设一个这样的能量函数——物理系统的动力学收敛于一些局部极小的能量。
2.2 EBM 中的优化问题
在这一节里,Bengio 向观众介绍了通常情况下如何定义和推导训练 EBM 的梯度。这基于能量函数可以被分解成两部分。第一部分叫作内部势能(internal potential),管理不同神经元彼此之间的相互作用。第二部分叫作外部势能(external potential),定义外部世界对神经元的影响。
任何系统的训练都是在进行某种优化,而 EBM 的梯度优化问题可以理解成: 在每一次的梯度运算后,所得值可代表系统中的能量。这一概念的解释见图 3。对于每个神经元,优化问题都需要处理内部势能和外部势能。训练将在两个阶段中推进:free phase 和 weakly clamped phase。free 阶段中网络尝试收敛至固定点 (優化問題的局部极小值),并读取网络输出的预测值。weakly clamped 阶段「推动」输出向目标的前进(目标和给定输入相关)、误差信号的传播,并找到其他固定点。这两个阶段是对标准反向传播中前向传输和反向传输的模拟。

图 3:训练基于能量的模型的概念解释。训练过程涉及寻找局部极小值,其中能量函数被最小化。
2.3 EBM 的作用
到底,基于能量的系统在构建模拟硬件的情况下起到了哪些作用?数字硬件的问题之一是它们是基于模拟硬件构建的。数字系统是模拟硬件的近似。为了使数字系统良好运行,该系统需要其组件按某些理想化原则运行。例如,按照 V-C 特性曲线为晶体管建模。追求這種理想化的后果之一就是它需要大量能量来使模拟组件保证正确运行。现在看一下当前的模拟硬件,一个问题是当电路构建完成时,不同的设备表现不同,且不完全按照完美的方式运行。此外,如果电路太小的话,还会出现大量噪声。因此,EBM 没有尝试量化这些带噪声信号,而是允许该系统把这些组件作为一个整体来处理。如图 4 所示,用户可以不用处理电路组件的输出,只需专注于整体输出值即可,整体输出值对应用户感兴趣的度量(在本案例中,该度量是能量)。

图 4:基于能量的模型的潜在优势。
3 文化演进
Bengio 最后讨论的话题和大脑神经元并不是很相关,而跟社会中的人类更加相关。深度学习中关于硬件的一个问题是研究者是否可以利用并行计算的优势。正如人们所知,GPU 工作得如此之好的原因是它们相比 CPU 能更好地实现并行计算。
更基本地,存在一个计算资源成本的问题。随着人们尝试建立更大规模、更复杂的系统,研究瓶颈变成了电路不同部分之间交流的能耗。这在 GPU 和 CPU 中最为明显,其中芯片必须从内存中迁移大量的数据到芯片的其它部分中。通常来说,这些信息传输过程的能耗相当大。
如图 5 所示,当前最优的分布式训练方式是通过参数服务器(Parameter Server)执行的同步随机梯度下降算法(SGD)。这是一种简单的分布式算法,其中存在一组节点,每个节点都拥有经过训练的神经网络的一个版本。这些节点通过一个服务器共享梯度和权重等信息。当试图扩展节点数量时,问题出现了。考虑到如今的问题涉及的巨大维度,当扩展节点数量(到什么级别)时,节点将不得不交流大量的信息。如何解决扩展性问题?一个可能的解决方案是文化演进。

图 5:以同步随机梯度下降为代表的分布式训练方式将在 10 年后过时,图为 2012 年 Jeff Dean 等人的 NIPS 研究。
3.1 什么是文化演进?
文化演进是一种高效通信的分布式训练方法,其灵感来自于人们在一个网络群体中发现的协作机制,这些网络正在(通过语言)学习和分享发现的概念。例如,假设人类是节点,每个人脑都有大量的突触权重。让两个大脑同步的方法不是分享它们的权重,而是交流想法。如何做到这一点?分享「表征」,这是神经元活动的离散总结。
Hinton 等人探索了通过传递激活而不是传递权重的方法同步两个网络。他们的想法大致为:有两个权重不同的网络,这两个网络将尝试同步它们正在计算的函数(而不是权重)。例如,从人类互动中获得灵感,A 的大脑与 B 的大脑运作方式不同,但是只要 A 和 B 的大脑都理解相同的概念,他们就能共享上下文,从而进行合作。
这种方法基于一个旧思路:训练一个能够总结多个网络知识的单个网络。做到这一点需要采用「teaching」网络的输出,然后在训练中使用这些输出作为网络的「targets」。文化演进的不同之处在于两种网络同时学习。Bengio 的团队已经试验过这些概念,他们观察到除了网络自己数据的 targets,让网络之间共享输出作为额外的 targets 能够极大地改进对网络群体的训练。下图对文化演进给出了简要总结。

图 6:文化演进总结。
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com








