机器学习作为近几年的一项热门技术,不仅凭借众多“人工智能”产品而为人所熟知,更是从根本上增能了传统的互联网产品。在近期举办的2018
ArchSummit全球架构师峰会上,个推首席数据架构师袁凯,基于他在数据平台的建设以及数据产品研发的多年经验,分享了《面向机器学习数据平台的设计与搭建》。
一、背景:机器学习在个推业务中的应用场景
作为独立的智能大数据服务商,个推主要业务包括开发者服务、精准营销服务和各垂直领域的大数据服务。而机器学习技术在多项业务及产品中均有涉及:
1、个推能够提供基于精准用户画像的智能推送。其中用户标签主要是基于机器学习,通过训练模型后对人群做预测分类;
2、广告人群定向;
3、商圈景区人流量预测;
4、移动开发领域经常出现虚假设备,机器学习能够帮助开发者识别新增的用户的真伪;
5、个性化内容推荐;
6、用户流失以及留存周期的预测。
二、具体开展机器学习的过程
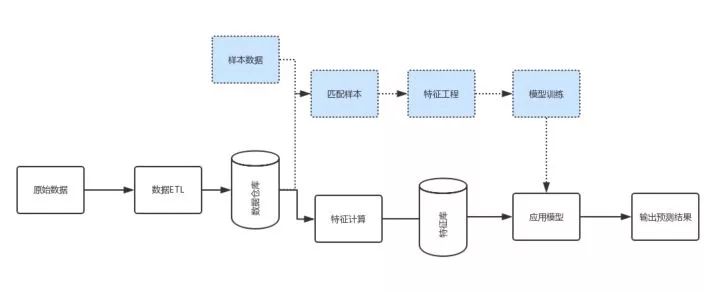
1、原始数据经过数据的ETL处理,入库到数据仓里。
2、上面蓝色部分代表机器学习:首先把样本数据与我们的自有数据进行匹配,然后洞察这份数据并生成特征,这个过程叫特征工程。接下来基于这些特征,选择合适的算法训练后得到模型,最终把模型具体应用到全量的数据中,输出预测的结果。
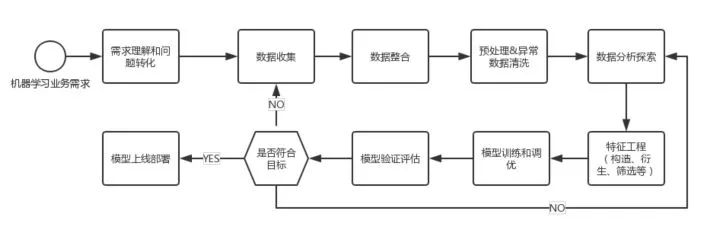
标准的机器学习工作流:针对业务上产生的具体问题,我们把它转化成数据问题,或者评估它能否用数据来解决。将数据导入并过滤后,我们需要将数据与业务问题和目标进行相关性分析,并根据具体情况对数据做二次处理。
下一步我们进行特征工程。从数据里找出跟目标有关的特征变量,从而构建或衍生出一些特征,同时要把无意义的特征剔除掉。我们大概需要花80%的时间在特征工程这个环节。选出特征之后,我们会用逻辑回归和RNN等算法进行模型的训练。接下来需要对模型做验证,判断其是否符合目标。不符合目标的原因有可能是数据和目标不相关,需要重新采集;也有可能是我们在探索的时候,工作不到位,因而需要对现有的数据重新探索,再进行特征工程这些步骤。如果最终模型符合业务预期,我们会把它应用在业务线上面。
三、机器学习项目落地的常见问题
虽然上面的流程很清晰,但在具体落地的过程中也会遇到很多问题,这里我就之前的实践经验谈几点。
1、现在大部分公司都已经进入大数据的时代,相比于以往的小数据级的阶段,在机器学习或者数据挖掘等工作方面,对我们的建模人员、算法专家的技能要求变高,工作难度也大大地提升了。
以往大家自己在单机上就可以完成机器学习的数据预处理、数据分析以及最终机器学习的分析和上线。但在海量数据情况下,可能需要接触到Hadoop生态圈。
2、做监督学习时,经常需要匹配样本。数据仓库里面的数据可能是万亿级别,提取数据周期非常长,大把的时间要用于等待机器把这些数据抽取出来。
3、大多数情况下,很多业务由一两个算法工程师负责挖掘,因而经常会出现不同小组的建模工具不太统一或实现流程不规范的情况。不统一会造成很多代码重复率高,建模过程并没有在团队里很好地沉淀下来。
4、很多机器学习算法工程师的背景存在专业的局限性,他们可能在代码工程化意识和经验上相对会薄弱一些。常见的做法是:算法工程师会在实验阶段把特征生成代码和训练代码写好,交给做工程开发的同学,但这些代码无法在全量数据上运行起来。之后工程开发同学会把代码重新实现一遍,保证它的高可用和高效。但即便如此,也常常出现翻译不到位的情况,导致沟通成本高,上线应用周期长。
5、机器学习领域的一大难题在于对数据的使用,它的成本非常高,因为我们把大量时间用于探索数据了。
6、个推有多项业务在使用机器学习,但并不统一,会造成重复开发,缺少平台来沉淀和共享。这就导致已经衍生出来的一些比较好用的特征,没有得到广泛的应用。
四、个推针对机器学习问题的解决方案
首先说一下我们这个平台的目标:
第一点,我们希望内部的建模流程规范化。
第二点,我们希望提供一个端到端的解决方案,覆盖从模型的开发到上线应用整个流程。
第三点,我们希望平台的数据,特别是开发出的特征数据可以运营起来并在公司内不同团队间共享使用。
第四点,这个平台不是面向机器学习零基础的开发人员,更多的是面向专家和半专家的算法工程师,让他们提高建模的效率。同时这个平台要支持多租户,确保保障数据安全。
以下是我们自己的整体方案,主要分成两大块:
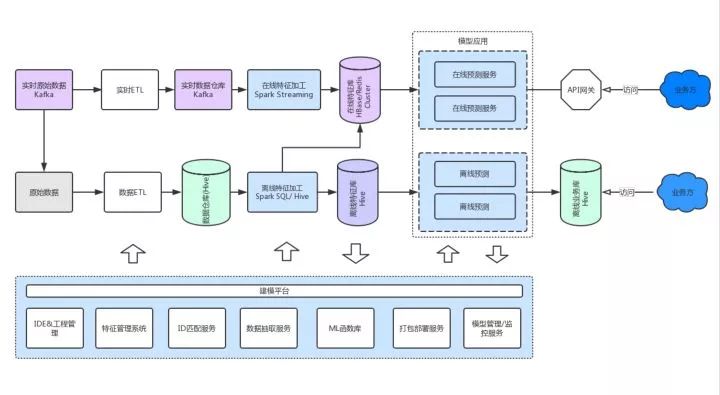
下半部分是建模平台,也叫实验平台,它主要供算法工程师使用,建模平台包含:
1、对应IDE。在这个平台上进行数据探索、做数据的实验,并且它能支持项目的管理和共享。
2、我们希望把已经开发好的特征数据管理起来,方便所有平台用户看到数据资产的情况。
3、样本匹配时候,样本ID可能与内部ID不统一,这个时候需要做统一的ID匹配服务。
4、帮助算法工程师从万亿级数据里快速地抽取所需数据,这也是非常重要的一点。
5、做机器学习的过程中,除了基本的算法,实际上还有很多代码是重复或者相似的,我们需要把这些常用代码进行函数化封装。
6、支持对模型服务进行打包部署。
7、模型还要支持版本管理。
8、在实际业务中应用模型,需要实时监控起来,跟进模型的可用性、准确性等。
上半部分是生产环境,运行着数据处理pipeline,同时与数据建模平台对接着。
在生产环境中,模型对应的特征数据分两类:
一类是实时特征数据,比如数据实时采集,生成一些实时的特征,根据不同的业务需求存储在不同的集群里。
另一类是离线特征数据,离线数据加工后存到Hive,供模型应用侧进行使用。
在生产环境中,我们可以提供在线的预测API或 离线预测好的数据 供业务线使用。
五、方案实践具体要点
第一点,我们讲讲jupyter这块:
选择Jupyter作为主要建模IDE而不是自研可视化拖拽建模工具,这样的好处是可以做交互式的分析,建模效率也很高,扩展方便,研发成本低。当然类似微软Azure这样的可视化拖拽建模平台,可以非常清晰地看到整个流程,适合入门级同学快速上手。但我们的目标用户是专家和半专家群体,所以我们选择了最合适的Jupyter。
使用Jupyter时候,为了支持多租户,我们采用Jupyterhub。底层机器学习框架我们用了Tensorflow、Pyspark、Sklearn等。数据处理探索时候,结合sparkmagic,可以非常方便地将写在Jupyter上的Spark代码运行到Spark集群上。
对于Jupyter没有现成的版本管理控制和项目管理, 我们结合git来解决。
另外为了提高建模人员在Jupyter上的效率,我们引入了比较多的插件,例如:把一些典型挖掘pipeline做成Jupyter模板,这样需要再做一个类似业务的时候只需要基于模板再扩展开发,比较好地解决了不规范的问题,避免了很多重复代码,也为实验代码转化为生产代码做好了基础。
第二点,说下工具函数:
我们内部提供了主要机器学习相关的函数库和工具:
1)标准化的ID Mapping服务API。
2)创建数据抽取的API,无论是哪种存储,分析人员只要统一调这个API就可。
3)可视化做了标准化的函数库和工具类。
4)Jupyter2AzkabanFlow: 可以把原本在Jupyter上写好的代码或者脚本自动转化成AzkabanFlow,解决了特征工程阶段的代码复用问题。
第三点,关于使用Tensorflow:
使用Tensorflow时,我们的选型是TensorflowOnSpark,原生的Tensorflow的分布式支持不够好,需要去指定一些节点信息,使用难度较大。
TensorflowOnSpark能够解决原生Tensorflow Cluster分布式问题,代码也很容易迁移到TensorflowOnSpark上,基本不用改。
同时利用yarn可以支持GPU和CPU混部集群,资源易复用。
第四点,关于模型交付应用:
在模型交付的问题上,我们把整个预测代码框架化了,提供了多种标准的框架供分析人员直接选用。对输出的模型文件有格式进行要求,例如:只能选择
pmml格式或者tensorflow pb格式。标准化之后,只要使用标准的预测函数库,就可以把建模人员的工作和系统开发人员的工作解藕出来。
最后分享下我们的一些经验:
第一,TensorflowOnSpark上的PS数量有限制,而且Worker和PS节点资源分配不是很灵活,都是等大。
第二,Jupyter在使用的时候,需要自己做一些改造,一些开源库版本兼容性有问题。
第三,使用PMML有性能瓶颈,一些是java对象反复重建,还有一些是格式转化损耗,具体大家可以抓取下jvm信息分析优化。
第四,在落地过程使用Spark、Hive的问题上,需要提供易于使用的诊断工具,建模人员并不是Spark、Hive的专家,不一定熟悉如何诊断优化。
第五,要把模型和特征库当成一个资产来看待,对它的价值定期做评估,要管理好它的生命周期。
第六,一些更偏底层的问题,比如: 硬件的选型可能要注意带宽、内存、GPU平衡。
最后,需要平衡技术栈增加和维护代价,避免引入太多新工具新技术,导致运维困难。
出处:https://zhuanlan.zhihu.com/p/39931551
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
架构文摘
ID:ArchDigest
互联网应用架构丨架构技术丨大型网站丨大数据丨机器学习

更多精彩文章,请点击下方:阅读原文








