分类的准确度长期以来都是评价图像分类模型性能的最核心甚至唯一标准。但最近研究表明,即使是充分训练好的深度神经网络模型也很容易被对抗攻击算法攻破。对抗攻击是指在图像上加入特定的且人眼无法察觉的微量噪声,使得目标模型对加噪之后得到的对抗样本做出错误分类。
对抗样本有可能会导致财产损失乃至威胁生命。比如,Eykholt 等人 [1] 的研究表明一个经过稍加修改的实体停车标志能够使得一个实时的物体识别系统将其误识别为限速标志,从而可能造成交通事故。为了揭示深度神经网络模型的鲁棒性和准确性之间的关系,来自 IBM 研究院,加州大学戴维斯分校,麻省理工学院以及京东 AI 研究院的研究人员,系统性地度量了 18 个被学术界和工业界广泛接受并使用的 ImageNet 深度神经网络模型,如 AlexNet、VGG Nets、Inception Nets、ResNets、DenseNets、MobileNets、NASNets 等的鲁棒性。
该研究发现了多个非常有趣的现象,包括:1) 准确度越高的模型的普遍鲁棒性越差,且分类错误率的对数和模型鲁棒性存在线性关系;2) 相比于模型的大小,模型的结构对于鲁棒性的影响更大;3) 黑盒迁移攻击是一直以来都比较困难的任务,但在 VGG 系列模型上生成的对抗样本可以比较容易地直接攻击其它的模型。该项工作对于理解深度神经网络准确性和鲁棒性之间关系提供了一个较完备的图景。此项研究的论文「Is Robustness the Cost of Accuracy? – A Comprehensive Study on the Robustness of 18 Deep Image Classification Models」已被欧洲计算机视觉大会(ECCV 2018)接收,并且预印版和代码都已公开。
自从 2012 年 AlexNet 在 ImageNet 竞赛大放异彩之后,研究者们不断设计出更深和更复杂的深度神经网络模型以期获得更好的分类精度。虽然这些模型能够取得图像识别正确率的稳定增长,但它们在对抗攻击下的鲁棒性尚未得到充分研究。为了评估深度神经网络的鲁棒性,一个直观的方法是使用对抗攻击。这种攻击生成视觉上和原图难以察觉区别的对抗样本使得深度神经网络做出错误分类。一般来讲,对于一个深度神经网络,如果在其上构建对抗样本越容易、所添加的噪声越小、则该网络越不鲁棒。除了对抗攻击之外,神经网络的鲁棒性也可以用一种独立于攻击的方式来衡量。例如 Szegedy 等人 [2] 和 Hein 等人 [3] 使用神经网络模型的全局和局部的 Lipschitz 常量对某些简单模型的鲁棒性进行了理论分析。Weng 等人 [4] 提出使用极值理论来估计为了生成有效的对抗样本所需要的最小噪声的尺度。
在这篇论文中,研究者们同时使用了上述两种方式评估了 18 个在 ImageNet 竞赛中脱颖而出的 DNN 模型,包括 AlexNet, VGG Nets, Inceptin Nets, ResNets, DenseNets, MobileNets 和 NASNets 等。这 18 个模型具有不同的大小,分类准确度和结构,因此具有充分的代表性,从而能更好地分析出影响模型鲁棒性的不同因素。在使用对抗攻击来评估鲁棒性的方式中,研究者们使用了目前最好最常用的几种攻击算法,包括 Fast Gradient Sign Method(FGSM)[5]、Iterative FGSM(I-FGSM)[6]、Carlini & Wagner(C&W)算法 [7],以及 Elastic-Net Attack under L1 norm(EAD-L1)算法 [8]。此外,在独立于攻击的鲁棒性评估方式中,研究者们选用了目前最为有效的 CLEVER Score[4] 来评估深度神经网络的鲁棒性。
这篇论文通过对 18 个 ImageNet 模型在 C&W 攻击和 I-FGSM 攻击下的鲁棒性的实验分析,发现当已有模型仅仅追求更高的分类准确度时,往往会牺牲在对抗攻击下的鲁棒性。图 1 展示了在 I-FGSM 的攻击下,生成对抗样本所带来的扭曲 (以 l-infinity 度量) 与模型的分类错误率的对数值呈现出线性关系。因此,当分类器具有非常低的分类错误率的时候,在对抗攻击下它将变得非常脆弱。所以本论文作者们建议 DNN 的设计者在构建网络的时候,应该参考本论文提出的准确度-鲁棒性的帕累托边界来评估其所构建模型的鲁棒性。
同时,图 1 也明确地揭示了属于同一网络结构家族的网络都有着相近的鲁棒性。这就意味着相比于网络的大小,网络结构对于鲁棒性的影响更大。
在对抗样本的黑盒转移攻击方面,研究者们对于 18 个 ImageNet 的模型之间的每一对模型(共计 306 对)都进行了在 FGSM, I-FGSM, C&W 和 EAD-L1 攻击下的黑盒转移攻击的实验。这是迄今为止在黑盒转移攻击上最大规模的实验。图 2 展示了对大多数网络来说,在它上面生成的对抗样本只能在本家族的网络之间有较好的黑盒转移攻击成功率。唯一的例外是 VGG 家族:基于 VGG 家族的网络生成的对抗样本在黑盒转移攻击其他的 17 个网络上都有着很高的成功率。这一发现也为逆向工程黑盒模型的结构提供了一定的曙光。
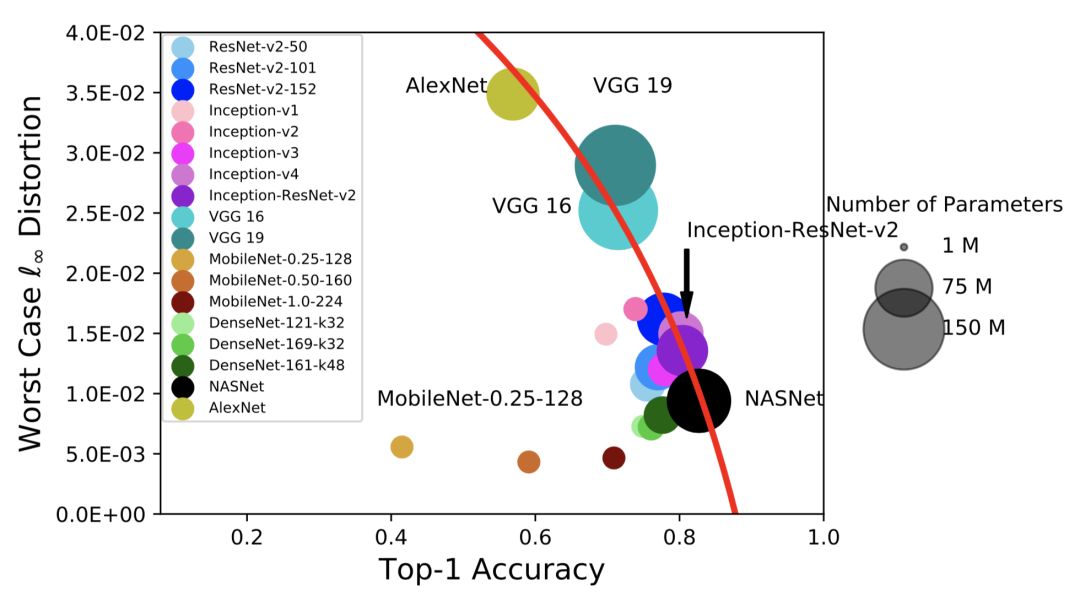
图 1:I-FGSM 攻击下,关于模型分类准确度(x 坐标)和模型鲁棒性度量 l-infinity distortion(y 坐标)之间的拟合的帕累托边界(红色曲线),即 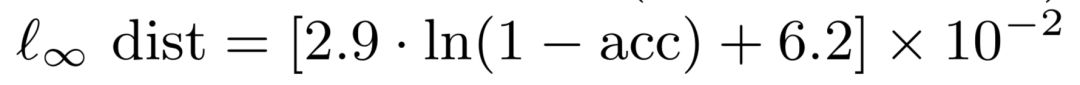
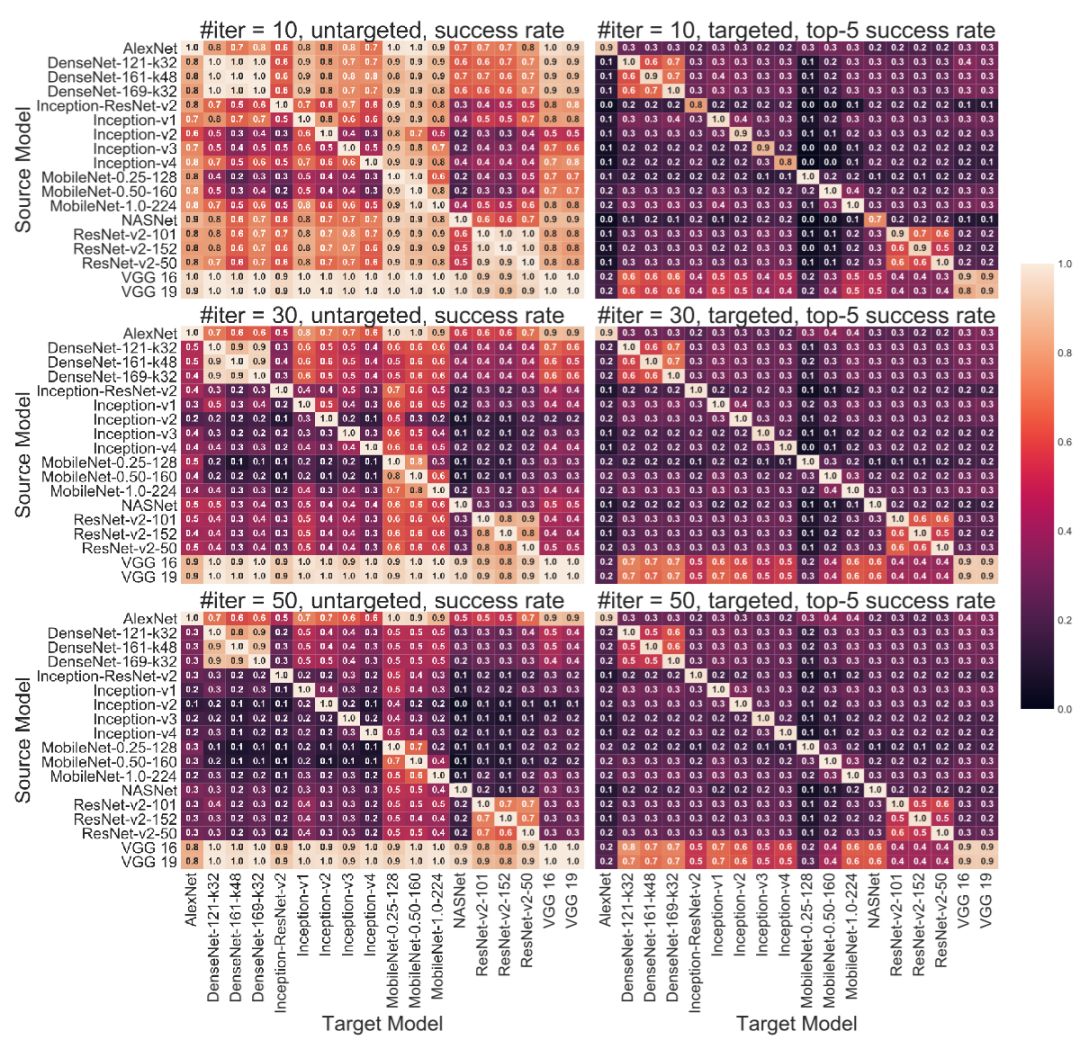
图 2:I-FGSM 攻击下 18 个模型(306 对)之间的黑盒转移攻击的成功率。每一行的子图分别对应了 I-FGSM 轮数为 10,30 和 50。第一列的子图对应于非针对性(untargeted)攻击,第二列子图对应于针对性(targeted)攻击。在每一幅热力图中,第 i 行第 j 列上的数值是用第 i 个模型生成的对抗样本来攻击第 j 个模型的成功率。对角线上的值就等价于模型在白盒攻击下成功率。对于非针对性攻击,报告的数值是成功率。对于针对性攻击,报告的数值是 top-5 匹配率。与其他模型相比,VGG-16 和 VGG-19(每张图中最下两行)展现出了明显更高的转移攻击的成功率。

参考文献:
[1] Eykholt, K., Evtimov, I., Fernandes, E., Li, B., Rahmati, A., Xiao, C., Prakash, A., Kohno, T., Song, D.: Robust physical-world attacks on deep learning visual classification. CVPR 2018.
[2] Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., Fergus, R.: Intriguing properties of neural networks. ICLR 2014.
[3] Hein, M., Andriushchenko, M.: Formal guarantees on the robustness of a classifier against adversarial manipulation. NIPS 2017.
[4] Weng, T.W., Zhang, H., Chen, P.Y., Yi, J., Su, D., Gao, Y., Hsieh, C.J., Daniel, L.: Evaluating the robustness of neural networks: An extreme value theory approach. ICLR 2018.
[5] Goodfellow, I., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples. ICLR 2015.
[6] Kurakin, A., Goodfellow, I.J., Bengio, S.: Adversarial machine learning at scale. ICLR 2017.
[7] Carlini, N., Wagner, D.A.: Towards evaluating the robustness of neural networks. Oakland 2017.
[8] Chen, P.Y., Sharma, Y., Zhang, H., Yi, J., Hsieh, C.J.: Ead: Elastic-net attacks to deep neural networks via adversarial examples. AAAI 2018.
想要了解更多资讯,请扫描下方二维码,关注机器学习研究会

转自: 机器之心









