
本文为 AI 研习社编译的技术博客,原标题 How GOAT Taught a Machine to Love Sneakers,作者为 Emmanuel Fuentes。
翻译 | Lamaric 校对 | 余杭 整理 | MY
在 GOAT(https://www.goat.com/),我们为买家和卖家创造了一个最大的运动鞋安全交易市场。帮助人们表达他们个人的风格和定位的运动鞋世界是 GOAT 的数据团队的主要动力。数据团队构建一系列工具和服务,利用数据科学和机器学习,尽可能减少该社区可能出现的问题。
当我加入 GOAT 时,我并不是一个运动鞋狂热爱好者。每天在处理新款运动鞋的同时,我更倾向于使每一个都有独一无二的视觉特征。我开始疑惑那些刚接触这种文化的人会以何种方式进入这个领域。我觉得,无论你对于运动鞋的审美水平如何,我们都可以传达他们的视觉吸引力。受我的经验启发,我决定构建一个工具,希望其他人会觉得它有用。

首先要开发一种用于描述所有运动鞋的通用语言。但是,这不是一项简单的任务。我们的产品目录中有超过 30,000 款运动鞋(并且数量正在增长),其中每款鞋独特的样式、轮廓、材料、颜色等都包含于整个目录,变得棘手。此外,每一款鞋子的版本都有可能改变我们谈论运动鞋的方式,这意味着我们必须更新它们的通用语言。因此我们需要通过从一开始就将它们包含在我们的语言中来接受变化和创新,而不是试图与现实作斗争。
解决方法之一是使用机器学习。为了跟上不断变化的运动鞋外观,我们使用可以找到对象之间关系的模型,而无需明确说明要查找的内容。在实践中,这些模型倾向于学习与人类相似的特征。我将在这篇文章中详细介绍我们如何使用这种技术构建视觉属性作为我们常见运动鞋语言的基础。
在 GOAT,我们使用人工神经网络(https://en.wikipedia.org/wiki/Artificial_neural_network)来近似我们的产品目录中最具说服力的视觉特征,即潜在的变异因素。在机器学习中,这属于流形学习的范畴。流形学习背后的假设通常是数据分布,例如:运动鞋的图像可以在局部类似于欧几里德空间的较低维度表示中表达,同时保留大部分有用信息。结果是将数百万个图像像素转换为可解释的细微差别特征,并将其封装为少量数字的列表。
想想你如何告诉你的朋友你家的路线。你永远不会描述如何通过一系列原始 GPS 坐标从他们的房子到你的房子。在这个比喻中,GPS 表示高维,宽域随机变量。相反,你很可能会以一系列街道名称的形式来使用这些坐标的近似值,并加上转向方向,即我们的流形,来编码它们的驱动器。
我们利用无监督模型,如变分自动编码器(VAE),生成性对抗网络(GAN)和 Wasserstein 自动编码器(WAE)来学习这种流形,且无需代价高昂的实体标签。这些模型为我们提供了一种方法,可以将我们的主要运动鞋照片转换为美学上的潜在因素,也可称之为嵌入。
在许多情况下,这些模型利用某种形式的自动编码器框架来推断潜在空间。模型的编码器将图像分解为其潜在向量,然后通过模型的解码器重建图像。在此过程后,我们测试模型重建输入的能力并计算其不正确性,即损失。该模型使用损失值迭代地压缩和解压缩更多图像,作为提高精度的信号。重建任务即为推动这个 bowtie looking 模型来学习对任务最有帮助的嵌入。与其他降维技术(如 PCA)类似,此技术通常会导致对数据集中的可变性部分进行编码。
原型自动编码器
仅仅能够重建图像通常是不够的。传统的自动编码器最终成泛化能力较弱的数据集 查找表。这是由于在样本之间的空间中具有 chasms/cliffs 的学习不佳的流形的结果。现在的模型正以各种方式解决这个问题。例如著名的 VAE,为损失函数添加了一个发散正则化项,以便将潜在空间约束到一些理论上的支持。更具体地说,这些类型的模型中的大多数惩罚与一些高斯或均匀先验不匹配的潜在空间,并试图通过选择发散度量来近似差异。在很多情况下,选择合适的模型可归结为发散测量,重建误差函数和强加先验的设计选择。设计选择的这些例子是 β-VAE 和 Wasserstein 自动编码器,它们分别利用了 Kullback-Leibler 发散和对抗性损失。根据您学习嵌入的用例,您可能会偏爱另一个,因为通常需要在输出质量和多样性之间进行权衡。
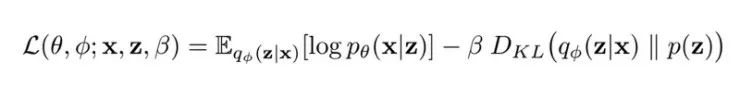
β-VAE 损失函数,重建和加权散度
对于我们的视觉运动鞋语言的美学运动鞋嵌入,我们更喜欢潜在因素,鼓励强大和多样化的潜在空间覆盖我们的大部分产品目录。换句话说,我们希望能够代表最广泛的运动鞋,而不是像 JS Wings 那样独特的风格。
我们训练了一个 VAE 来学习我们的主要产品照片的潜在空间。固定潜在向量,我们可以看到模型是如何随着时间的推移进行训练,以类似人类的方式构建复杂性和抽象层。
通过解码器生成的照片,每个图像都是一个在训练时期逐渐增加的固定潜在向量
该模型倾向于在每个维度中创建更多独立的人类可解释因子,称为解构。首先,该模型着重于重新创建最合适的轮廓,同时注意鞋底和鞋面之间的对比。从那里开始,它构建了整个轮廓的灰度渐变概念,直到它开始学习基本颜色。在了解轮廓类型后,例如启动与运动,高与低后,网络开始解决更复杂的设计模式和颜色,这将是最终的差异化因素。
为了展示学习过的流形并检查学习曲面的平滑度,我们可以通过插值进一步可视化。我们选择两个看似不同的运动鞋作为锚点,然后在潜在的空间中判断它们之间的过渡。沿插值的每个潜在向量被解码回图像空间以进行视觉上的检查,并与我们整个目录中最接近的实际产品相匹配。下面的动画说明了这些概念以映射模型怎样学习。
锚点运动鞋之间的插值和匹配
进一步探索潜在空间,我们使用单个运动鞋,并在每个方向一次修改一个因素,以观察它是如何变化的。表示中间到引导的因素和唯一的颜色只是网络学习的一些视觉上可感知的特征。根据模型,潜在因素的数量和它们彼此的独立性会有所不同。这种解构属性是我们研究的一个活跃领域,我们希望能够改进我们的嵌入。
潜在因素的探索,每一行使用相同的目标运动鞋改变一个因素,每列是修改量的重建潜在向量,先前是标准正态分布。
此外,我们可以在尺寸缩小的 2D / 3D 图中查看潜在向量的整个产品目录,以找到它们的宏观趋势。我们使用诸如 t-SNE 之类的工具将我们的潜在空间映射到用于检查和批量注释的可视化界面。
t-SNE 潜在空间探索
从逻辑上讲,如果每个运动鞋只是潜在因素的集合,则可以相对于彼此相加或相减这些因子。这是一个将两个运动鞋加在一起的例子。注意结果是如何保持第一个运动鞋的宽踝环和品牌标识,且唯一的整体轮廓和材料属于第二个。
运动鞋潜在空间算法
嵌入是创建可重用价值的绝佳工具,其固有属性类似于人类解释对象的方式。它们可以消除对变化变量的持续目录维护和归因的需要,并且适用于各种各样的应用程序。通过利用嵌入,可以找到群集来执行批量注释,计算推荐和搜索的最近邻居,执行缺失的数据插补,以及重用网络以热启动其他机器学习问题。
Auto-Encoding Variational Bayes
β -VAE: Learning Basic Visual Concepts with a Constrained Variational Framework
Understanding disentangling in β-VAE
Wasserstein Auto-Encoders
Visualizing Data using t-SNE
Sampling Generative Networks
Generative Adversarial Networks
原文链接:https://medium.com/engineeringatgoat/how-goat-taught-a-machine-to-love-sneakers-e4a97cda71b1
点击文末【阅读原文】即可观看更多精彩内容:
可以使用的深度学习模型
实例+代码,你还怕不会构建深度学习的代码搜索库吗
深度学习优化入门:Momentum、RMSProp 和 Adam
使用 Scikit-learn 理解随机森林
斯坦福CS231n李飞飞计算机视觉经典课程(中英双语字幕+作业讲解+实战分享)
等你来译:
剖析深度学习框架
7月最好的机器学习GitHub存储库和Reddit线程
如何基于 Keras, Python,以及深度学习进行多 GPU 训练
现代游戏理论和多代理式强化学习系统









