对于模型来说,在训练集上的误差称为训练误差(training error)或经验误差(empirical error),测试集的误差称为测试误差(testing error),在新样本上的误差为泛化误差(generalization error)。
也就是说测试误差是用来评估模型对于新样本的学习能力,因此我们更关注的是测试误差,我们希望模型可以从现有的数据中学习到普遍规律而用于新样本。
因此我们需要将现有数据集(data set)划分为训练集(training set)和测试集(test set),其中训练集用来训练模型,而测试集用来验证模型对新样本的判别能力。那么,划分数据集有什么做法呢?
01
留出法
hold-out
直接将数据集D划分为两个互斥的集合:训练集S和测试集T(D = S∪T,S∩T = ∅),在S上训练模型,用T来评估其测试误差。
要点:
❶训练/测试集的划分要尽可能保持数据分布的一致性(进行分层划分stratified sampling),避免因为数据划分过程引入额外的偏差而对最终结果产生影响。例如:在二分类问题(binary classification)中,S与T中正负样本的比例应该接近。
❷单次使用留出法得到的估计往往不够稳定可靠,为得到合理的算法模型评估标准,应该进行多次数据集的随机划分,取评估结果平均值作为评判模型优劣的标准。
❸训练集太大,评估的结果可能不太准确稳定。训练集太小,会产生较大的偏差(high bias)。因此,实际中一般将大约2/3~4/5的样本用于训练(推荐S:T=7:3),剩余样本用于测试。
代码:
本文数据集来源于kaggle中breast cancer项目,根据数据预测肿瘤是良性(benign)还是恶性(malignant )
1import pandas as pd
2import os
3from sklearn.ensemble import RandomForestClassifier
4from sklearn import metrics
5os.chdir(r'C:\Users\o\Desktop\breast_cancer_data')
6data = pd.read_csv(r'data.csv')
7data.drop('Unnamed: 32',inplace = True,axis = 1)
8data.drop('id',inplace = True,axis=1)
9y = data['diagnosis']
10x = data.drop('diagnosis',axis = 1)
11model = RandomForestClassifier()
12
13from sklearn.model_selection import train_test_split
14x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.33, random_state=42)
15print(x_train.shape)
16print(x_test.shape)
17
18model.fit(x_train,y_train)
19prediction = model.predict(x_test)
20print(metrics.accuracy_score(prediction,y_test))
1
2(381, 30)
3(188, 30)
40.9521276595744681
02
交叉验证
cross-validation
在NG(吴恩达)的ML课程有提到:最佳的数据分类情况应当把数据集分为三个部分:训练集S、测试集T以及交叉验证集(cross validation set)CV,比例为S:T:CV=0.6:0.2:0.2。我们应当在S上训练模型,用CV代替T根据评价标准来选择模型。
实际上,CV与T的主要区别是:验证集用于进一步确定模型中的超参数(例如正则项系数、ANN中隐含层的节点个数等)而测试集只是用于评估模型的精确度(即泛化能力)!
首先要明确的一点是,交叉验证是用于模型选取(model selection)过程中的,而不是模型训练过程中的!!!
03
K折交叉验证
k-fold cross validation
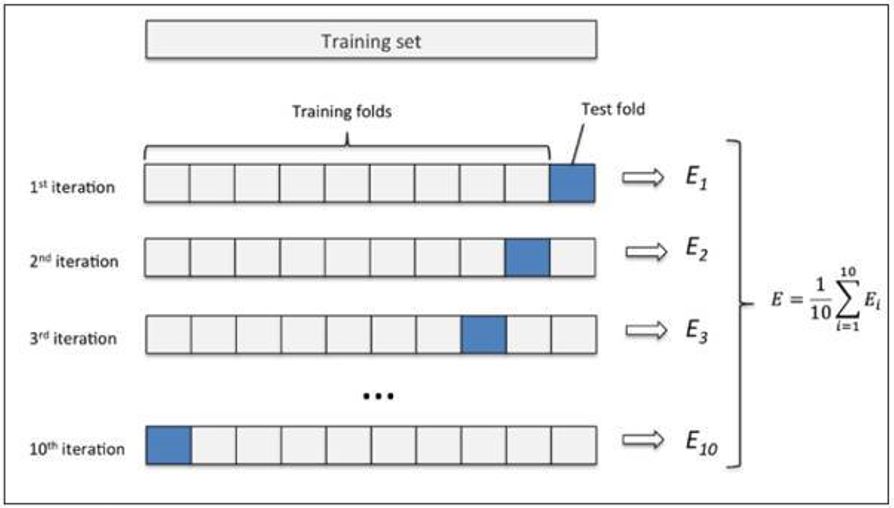
先将数据集D划分为k(一般而言k的取值为10,常用的还有5、20等)个大小相似的互斥子集.每个子集Di都尽可能保持数据分布的一致性,即从D中通过分层采样得到 。
然后每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集,这样就可以获得k组训练/测试集,从而可以进行k次训练和测试,最终返回的是这k个测试结果的均值。
代码:
Sklearn中K折交叉验证函数有:KFold,GroupKFold,StratifiedKFold,本篇介绍KFold
1import numpy as np
2from sklearn. model_selection import KFold
3kf = KFold(n_splits = 10)
4accuracy = [ ]
5for train_index,test_index in kf.split(x):
6 x_train,x_test = x.loc[train_index],x.loc[test_index]
7 y_train,y_test = y.loc[train_index],y.loc[test_index]
8 model.fit(x_train,y_train)
9 prediction = model.predict(x_test)
10 acc=metrics.accuracy_score(prediction,y_test)
11 accuracy.append(acc)
12print(accuracy)
13print(np.average(accuracy))
1
2[0.9122807017543859, 0.8771929824561403, 0.9649122807017544, 0.9824561403508771, 0.9649122807017544, 0.9649122807017544, 0.9649122807017544, 0.9649122807017544, 0.9649122807017544, 1.0]
30.956140350877193
04
留一法&留P法
LeaveOneOut&LeavePOut
LOO留一法是特殊的K折交叉验证,即k=m(m为样本总数量),就是说每次进行只留下一个样本用作测试集,其余m-1全为训练集,进行m次训练,取m次的评估结果的平均值进行模型选择。
LPO留P法是指:有m个样本,将每P个样本作为测试样本,其它m-P个样本作为训练样本,这样得到c(p,m)=m!/((m-p)!*p!)个train-test pairs,当P>1时,测试集将会发生重叠,当P=1的时候,就变成了留一法。
LOO的好处在于,不受样本随机划分带来的偏差,往往被认为比较准确,避免的数据的浪费,但是同时也拥有了更高的计算开销(如果你有一百万条数据,那么要进行一百万次训练,这个时间开销是难以忍受的),所以LOO较多使用在数据量小的数据集中 。
一般LOO相对于 K-Fold 而言,拥有更高的方差,但是对于方差占主导的情况时,LOO可能拥有比交叉验证更强的能力、
代码:
1from sklearn.model_selection import LeaveOneOut,LeavePOut
2loo = LeaveOneOut()
3accuracy = []
4for
train_index,test_index in loo.split(x):
5 x_train,y_train,x_test,y_test = x.loc[train_index],y.loc[train_index],x.loc[test_index],y.loc[test_index]
6 model.fit(x_train,y_train)
7 prediction = model.predict(x_test)
8 acc=metrics.accuracy_score(prediction,y_test)
9 accuracy.append(acc)
10print(np.average(accuracy))
05
自助法
bootstraping
我们希望评估的是用D训练出来的模型,但是留出法和交叉验证法中,由于保留了一部分样本用于测试,因此实际评估的模型所使用的训练集比D小,这必然会引入一些因训练样本规模不同而导致的估计偏差,为此提出自助法。
"Pull oneself up by one's bootstrap"
Bootstrap来源于这句很有趣的话,字面意思是拎着鞋带把自己提起来,翻译为自力更生。

给定包含m个样本的数据集D,我们对它进行采样产生数据集 D′:每次随机从D中挑选出一个样本,将其拷贝放入D′, 然后再将该样本放回初始数据集D中,使得该样本在下次采样时仍有可能被采样到;这个过程重复执行m次后,我们就得到可包含m个样本数据的数据集D′,这就是自助采样的结果.。
样本在m次采样中始终不被采到到概率为:
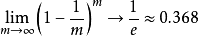
由此可知通过自助采样,初始数据集D中约有36.8%的样本未出现在采样数据集D′中。于是我们可将D′ 用作训练集,D∖D′(\为集合减法)用作测试集。
优缺点:自助法在数据集较小,难以有效划分训练/测试集时很有用,但是,自助法改变了初始数据集的分布,这会引入估计偏差,所以在数据量足够时,一般采用留出法和交叉验证法。
06
随机划分法
shuffle
Sklearn中的函数有:ShuffleSplit,GroupShuffleSplit,StratifiedShuffleSplit,本文使用ShuffleSplit
ShuffleSplit迭代器产生指定数量的独立的train-test pairs划分,首先对样本全体随机打乱,然后再划分出train-test pairs,可以使用随机数种子random_state来控制数字序列发生器使得讯算结果可重现
ShuffleSplit是KFlod交叉验证的比较好的替代,他允许更好的控制迭代次数和train/test的样本比例
代码:
1from sklearn.model_selection import ShuffleSplit
2rs = ShuffleSplit(n_splits = 10,test_size = 0.3)
3accuracy = []
4for train_index,test_index in rs.split(x):
5 x_train,y_train,x_test,y_test = x.loc[train_index],y.loc[train_index],x.loc[test_index],y.loc[test_index]
6 model.fit(x_train,y_train)
7 prediction = model.predict(x_test)
8 acc=metrics.accuracy_score(prediction,y_test)
9 accuracy.append(acc)
10print(accuracy)
11print(np.average(accuracy))
1
2[0.9649122807017544, 0.9649122807017544, 0.935672514619883, 0.935672514619883, 0.9590643274853801, 0.9824561403508771, 0.9590643274853801, 0.9473684210526315, 0.9532163742690059, 0.9064327485380117]
30.9508771929824562
下期主题:性能量度
后台回复“split”获取数据集以及代码
参考资料:
百度词条《抽样数据方式》
周志华《机器学习》
《Patttern Recognition and Machine Learning》
SklearnAPI文档
吴恩达《Machine Learning》公开课
写在最后
由于小编对机器学习比较感兴趣 ,然后现在重点也在自学机器学习。由于水平有限且刚学不久,难免会出现错误,相当于笔记的形式与大家分享交流,要是各位读者有更好的意见,可以在评论区提出来或者联系我哦~
-- the end --
如对文中内容有疑问,欢迎交流。PS:部分资料来自网络。文案&&代码:欧子铨(华中科技大学管理学院本科二年级 ,479284829@qq.com)指导老师:秦时明岳(华中科技大学管理学院,professor.qin@qq.com)
精彩文章推荐
你永远都不知道男生有多想和18岁女孩子谈恋爱!
"最萌身高差"究竟有多萌?
年薪百万的王宝强和月入三千的吴彦祖,你更愿意pick谁?
扫一扫,获取数据和模型
还有更多算法学习课件分享哟








