
作者:young2415 Python爱好者社区专栏作者
博客:https://blog.csdn.net/young2415
今天突然接到了媳妇儿的紧急求助电话,让我帮她弄一个表格。原来中秋节要到了,媳妇儿单位准备给员工发福利,福利分4个档次,不同的福利包含的东西不尽相同,每个部门的员工都有不同档次的福利,现在已经有了两个Excel表格,一个表格是每个员工发放哪个档次的福利,另一个表格是每个档次的福利包含什么东西,单位领导让我媳妇儿她们部门统计一下每个部门分别要买多少东西,汇总到一个表格上面,然后去采购。
现有的表格长这样:
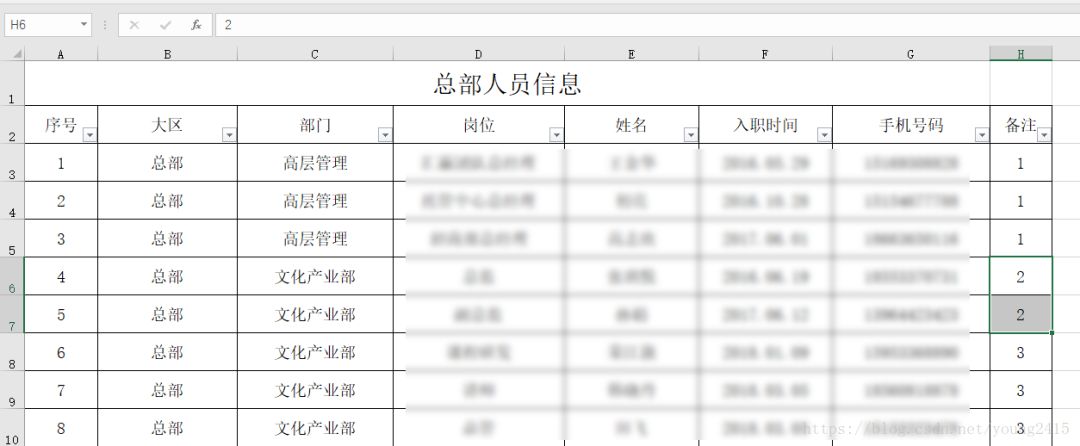
最后一栏的备注中的数字就是该员工应得的福利的档次。
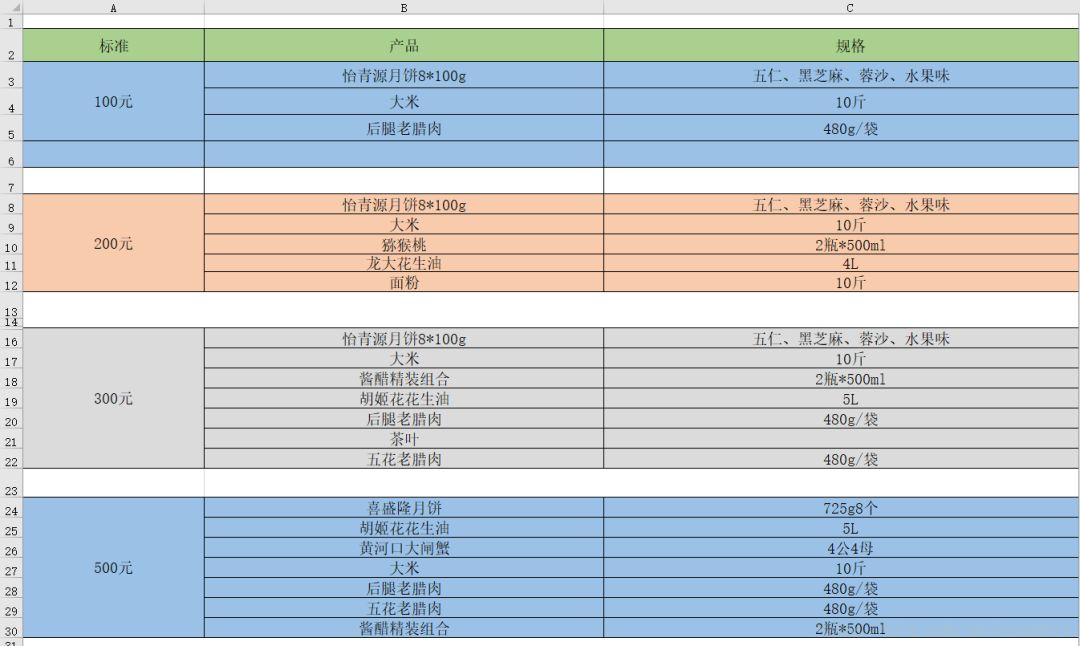
这张表格说明了每个档次的福利所包含的东西,1档福利是500元标准,2档福利是300元标准……以此类推。 最后单位领导想要的表格就是下面这样的,这是我最后做出的成果的截图,显示了每个部门分别要买多少东西:
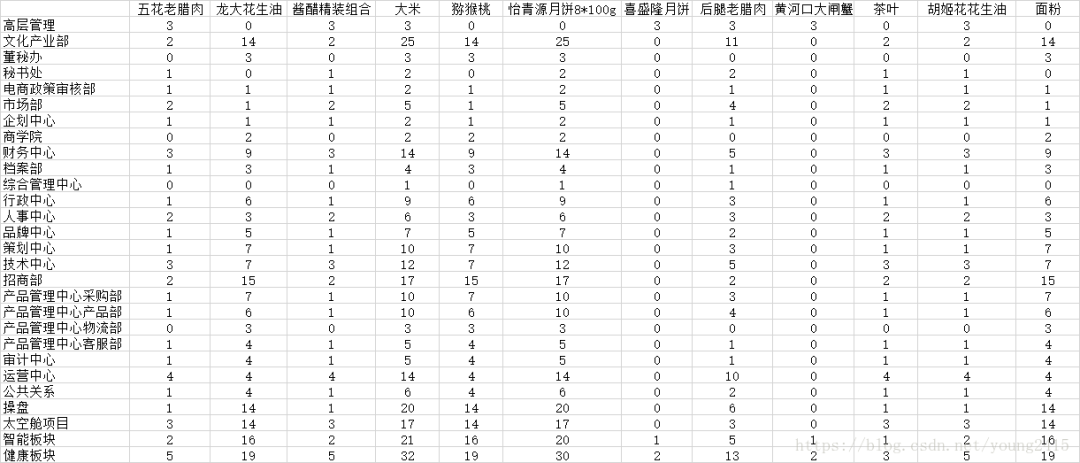
那么我是如何做到的呢? 听媳妇描述完情况之后,我第一反应就是可以用Python来做这件事。事实证明,Python并没有让我失望。在这个过程中,我用到了两个Python的模块,一个是用来读Excel文件的xlrd,另一个是用来向Excel文件中写入数据的xlsxwriter。
import xlrd
import xlsxwriter
首先获取两个Excel文件对象:
workbook1 = xlrd.open_workbook(r'details.xlsx') #这是第一张表
workbook2 = xlrd.open_workbook(r'plan.xlsx') #这是第二张表
sheet3 = workbook1.sheet_by_name('Sheet3') #第一张表的sheet
sheet1 = workbook2.sheet_by_name('Sheet1') #第二张表的sheet
然后读入第一个表中的部门和备注信息,每一条员工的所属部门和备注组成一个元组。
cols_bumen = sheet3.col_values(2)
cols_beizhu = sheet3.col_values(7)
res = list(zip(cols_bumen, cols_beizhu))
res = res[2:len(res)] #前两行是表头,我们所需信息从第三行开始
读入第二个表中的礼品信息。
lipin = [[],
["喜盛隆月饼","胡姬花花生油","黄河口大闸蟹","大米","后腿老腊肉","五花老腊肉","酱醋精装组合"],
["怡青源月饼8*100g","大米","酱醋精装组合","胡姬花花生油","后腿老腊肉","茶叶","五花老腊肉"],
["怡青源月饼8*100g","大米","猕猴桃","龙大花生油","面粉"],
["怡青源月饼8*100g","大米","后腿老腊肉"]]
lipin_list = ['五花老腊肉', '龙大花生油', '酱醋精装组合', '大米', '猕猴桃', '怡青源月饼8*100g',
'喜盛隆月饼', '后腿老腊肉', '黄河口大闸蟹', '茶叶'
, '胡姬花花生油', '面粉']
创建一个字典huizong,key是部门名,值是一个列表,列表中包含该部门所需的全部商品,假设需要两袋大米,那么列表中就会有两个“大米”。 最终字典的内容应该类似这样:
{'高层管理':['大米', '大米', '喜盛隆月饼'], '文化产业部':['茶叶', '茶叶', '五花老腊肉', '五花老腊肉']}
要做到这一点,我们需要遍历res
for i in res:
bumen = i[0] #获取部门名
lipin_level = int(i[1]) #获取该员工的福利档次
if huizong.get(bumen) == None: #如果字典中不存在这个键值对,就创建一个
huizong[bumen] = []
huizong[bumen].extend(lipin[lipin_level]) #在列表中添加对应的礼品名
最后遍历这个字典,把每个部门中的不同的商品数量通过list的count方法计算出来,将数据写到Excel表中,就大功告成了。
完整代码如下:
import xlrd
import xlwt
import xlsxwriter
workbook1 = xlrd.open_workbook(r'details.xlsx')
workbook2 = xlrd.open_workbook(r'plan.xlsx')
sheet3 = workbook1.sheet_by_name('Sheet3')
sheet1 = workbook2.sheet_by_name('Sheet1')
linpin = sheet1.col_values(1)
lipin = [[],
["喜盛隆月饼","胡姬花花生油","黄河口大闸蟹","大米","后腿老腊肉","五花老腊肉","酱醋精装组合"],
["怡青源月饼8*100g","大米","酱醋精装组合","胡姬花花生油","后腿老腊肉","茶叶","五花老腊肉"],
["怡青源月饼8*100g","大米","猕猴桃","龙大花生油","面粉"],
["怡青源月饼8*100g","大米","后腿老腊肉"]]
lipin_list = ['五花老腊肉', '龙大花生油', '酱醋精装组合'
, '大米', '猕猴桃', '怡青源月饼8*100g',
'喜盛隆月饼', '后腿老腊肉', '黄河口大闸蟹', '茶叶', '胡姬花花生油', '面粉']
cols_bumen = sheet3.col_values(2)
cols_beizhu = sheet3.col_values(7)
res = list(zip(cols_bumen, cols_beizhu))
res = res[2:len(res)]
huizong = {'高层管理':[]}
for i in res:
bumen = i[0]
lipin_level = int(i[1])
if huizong.get(bumen) == None:
huizong[bumen] = []
huizong[bumen].extend(lipin[lipin_level])
result = xlsxwriter.Workbook('result.xlsx')
worksheet = result.add_worksheet()
for i in range(0, len(lipin_list)):
worksheet.write(chr(66 + i) + '1', str(lipin_list[i]))
bumen = []
for i in res:
if bumen.count(i[0]) == 0:
bumen.append(i[0])
for i in range(0, len(bumen)):
worksheet.write('A{0}'.format(2+i), str(bumen[i]))
alphaBet = 66
number = 2
j = 0
for key in huizong:
count = 0
for i in range(0, len(lipin_list)):
count = huizong[key].count(lipin_list[i])
worksheet.write('{0}{1}'.format(chr(alphaBet+i), number+j), count)
j += 1
result.close()

Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复
“课程”即可获取:
小编的Python入门免费视频课程!!!
【最新免费微课】小编的Python快速上手matplotlib可视化库!!!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。






