声明:本项目旨在学习Scrapy爬虫框架和MongoDB数据库,不可使用于商业和个人其他意图。若使用不当,均由个人承担。
PornHubBot
PornHubBot项目主要是爬取全球最大的小电影网站PornHub的视频标题、时长、mp4链接、封面URL和具体的PornHub链接
项目爬的是PornHub.com,结构简单,速度飞快
爬取PornHub视频的速度可以达到500万/天以上。具体视个人网络情况,因为我是家庭网络,所以相对慢一点。
10个线程同时请求,可达到如上速度。若个人网络环境更好,可启动更多线程来请求,具体配置方法见 [启动前配置]
有需要Python学习资料的小伙伴吗?小编整理一套Python资料和PDF,感兴趣者可以关注小编后私信学习资料(是关注后私信哦)反正闲着也是闲着呢,不如学点东西啦
环境、架构
使用说明
启动前配置
根据自己需要修改 Scrapy 中关于 间隔时间、启动Requests线程数等得配置
启动
python PornHub/quickstart.py
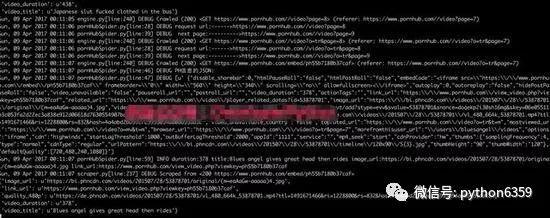
运行截图
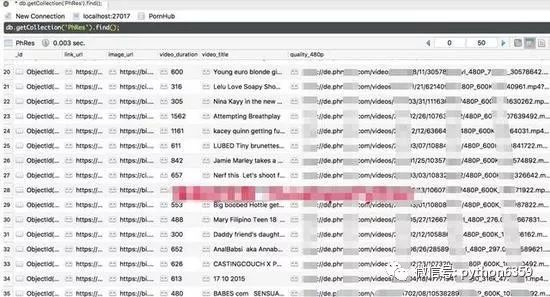
数据库说明
数据库中保存数据的表是 PhRes。以下是字段说明:
PhRes 表:
video_title:视频的标题,并作为唯一标识.
link_url:视频调转到PornHub的链接
image_url:视频的封面链接
video_duration:视频的时长,以 s 为单位
quality_480p: 视频480p的 mp4 下载地址
代码:GitHub:xiyouMc/WebHubBot











