
来源:量子位
AutoML和神经架构搜索(NAS),是深度学习领域的新一代王者。这些方法能快糙猛地搞定机器学习任务,简单有效,高度符合当代科技公司核心价值观。
它们背后原理如何,怎样使用?
技术博客TowardDataScience有一篇文章,就全面介绍了关于AutoML和NAS你需要了解的一切。
要了解AutoML,还得从NAS说起。
在开发神经网络的过程中,架构工程事关重大,架构先天不足,再怎么训练也难以得到优秀的结果。
当然,提到架构,很多人会想到迁移学习:把ImageNet上训练的ResNet拿来,换个我需要的数据集再训练训练更新一下权重,不就好了嘛!

这种方法的确也可行,但是要想得到最好的效果,还是根据实际情况设计自己的网络架构比较靠谱。
设计神经网络架构,能称得上机器学习过程中门槛最高的一项任务了。想要设计出好架构,需要专业的知识技能,还要大量试错。
NAS就为了搞定这个费时费力的任务而生。
这种算法的目标,就是搜索出最好的神经网络架构。它的工作流程,通常从定义一组神经网络可能会用到的“建筑模块”开始。比如说Google Brain那篇NasNet论文,就为图像识别网络总结了这些常用模块:

其中包含了多种卷积和池化模块。
论文:Learning Transferable Architectures for Scalable Image Recognition
地址:https://arxiv.org/pdf/1707.07012.pdf
NAS算法用一个循环神经网络(RNN)作为控制器,从这些模块中挑选,然后将它们放在一起,来创造出某种端到端的架构。
这个架构,通常会呈现出和ResNet、DenseNet等最前沿网络架构一样的风格,但是内部模块的组合和配置有所区别。一个架构的好坏,往往就取决于选择的模块和在它们之间构建的连接。
接下来,就要训练这个新网络,让它收敛,得到在留出验证集上的准确率。这个准确率随后会用来通过策略梯度更新控制器,让控制器生成架构的水平越来越高。
过程如下图所示:
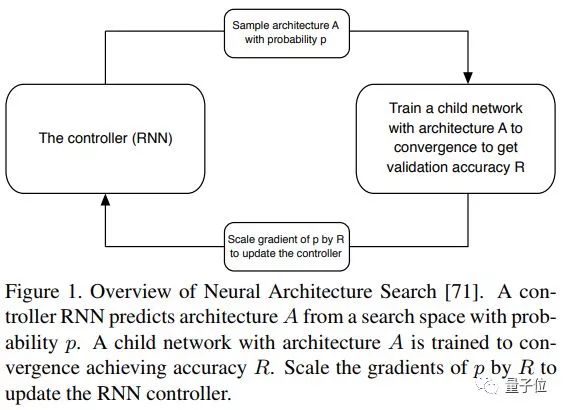
这个过程很直观了。简单来说,很有小朋友搭积木的风范:让一个算法挑出一些积木,然后把它们组装在一起,做成一个神经网络。训练、测试,根据这个结果来调整选积木的标准和组装的方式。

这个算法大获成功,NasNet论文展现出非常好的结果,有一部分原因是出于他们做出的限制和假设。
论文里训练、测试NAS算法发现的架构,都用了一个比现实情况小得多的数据集。当然,这是一种折衷的方法,要在ImageNet那么大的数据集上训练验证每一种搜索结果,实在是太耗费时间了。
所以,他们做出了一个假设:如果一个神经网络能在结构相似的小规模数据集上得到更好的成绩,那么它在更大更复杂的数据集上同样能表现得更好。
在深度学习领域,这个假设基本上是成立的。
上面还提到了一个限制,这指的是搜索空间其实很有限。他们设计NAS,就要用它来构建和当前最先进的架构风格非常类似的网络。
在图像识别领域,这就意味着用一组模块重复排列,逐步下采样,如下图所示:
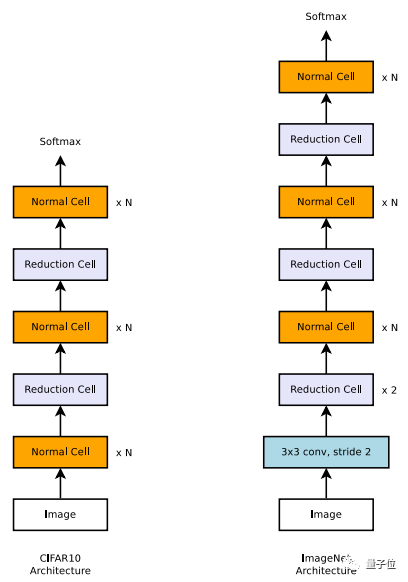
这些模块也都是当前研究中常用的。NAS算法在其中所做的新工作,主要是给这些模块换个连接方式。
下面,就是它发现的ImageNet最佳神经网络架构:
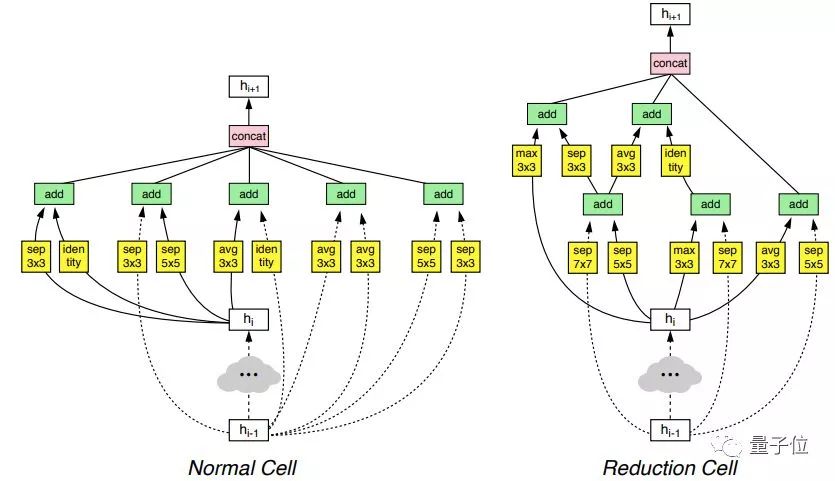
这篇NASNet论文带动了行业内的一次进步,它为深度学习研究指出了一个全新方向。
但是,用450个GPU来训练,找到一个优秀的架构也需要训练3到4天。也就是说,对于除了Google之外的普通贫民用户们,这种方法还是门槛太高、效率太低。

NAS领域最新的研究,就都在想方设法让这个架构搜索的过程更高效。
2017年谷歌提出的渐进式神经架构搜索(PNAS),建议使用名叫“基于序列模型的优化(SMBO)”的策略,来取代NASNet里所用的强化学习。用SMBO策略时,我们不是随机抓起一个模块就试,而是按照复杂性递增的顺序来测试它们并搜索结构。
这并不会缩小搜索空间,但确实用更聪明的方法达到了类似的效果。SMBO基本上都是在讲:相比于一次尝试多件事情,不如从简单的做起,有需要时再去尝试复杂的办法。这种PANS方法比原始的NAS效率高5到8倍,也便宜了许多。
论文:Progressive Neural Architecture Search
地址:https://arxiv.org/pdf/1712.00559.pdf
高效神经架构搜索(ENAS),是谷歌打出的让传统架构搜索更高效的第二枪,这种方法很亲民,只要有GPU的普通从业者就能使用。作者假设NAS的计算瓶颈在于,需要把每个模型到收敛,但却只是为了衡量测试精确度,然后所有训练的权重都会丢弃掉。
论文:Efficient Neural Architecture Search via Parameter Sharing
地址:https://arxiv.org/pdf/1802.03268.pdf
因此,ENAS就要通过改进模型训练方式来提高效率。
在研究和实践中已经反复证明,迁移学习有助在短时间内实现高精确度。因为为相似任务训练的神经网络权重相似,迁移学习基本只是神经网络权重的转移。
ENAS算法强制将所有模型的权重共享,而非从零开始训练模型到收敛,我们在之前的模型中尝试过的模块都将使用这些学习过的权重。因此,每次训练新模型是都进行迁移学习,收敛速度也更快。
下面这张表格表现了ENAS的效率,而这只是用单个1080Ti的GPU训练半天的结果。
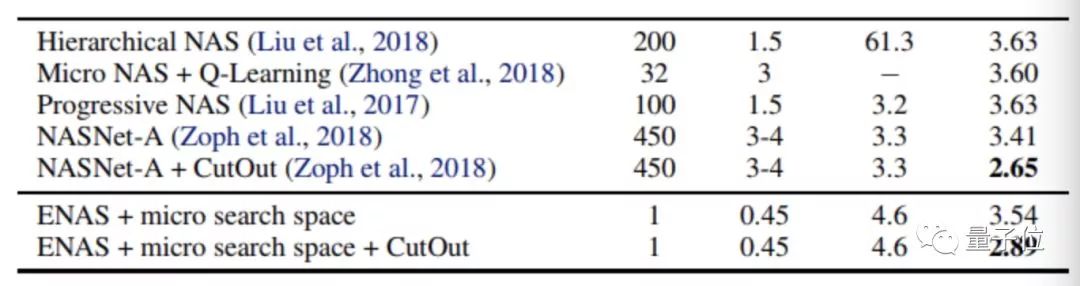
ENAS的表现和效率
很多人将AutoML称为深度学习的新方式,认为它改变了整个系统。有了AutoML,我们就不再需要设计复杂的深度学习网络,只需运行一个预先设置好的NAS算法。
最近,Google提供的Cloud AutoML将这种理念发挥到了极致。只要你上传自己的数据,Google的NAS算法就会为你找到一个架构,用起来又快又简单。
AutoML的理念就是把深度学习里那些复杂的部分都拿出去,你只需要提供数据,随后就让AutoML在神经网络设计上尽情发挥吧。这样,深度学习就变得像插件一样方便,只要有数据,就能自动创建出由复杂神经网络驱动的决策功能。
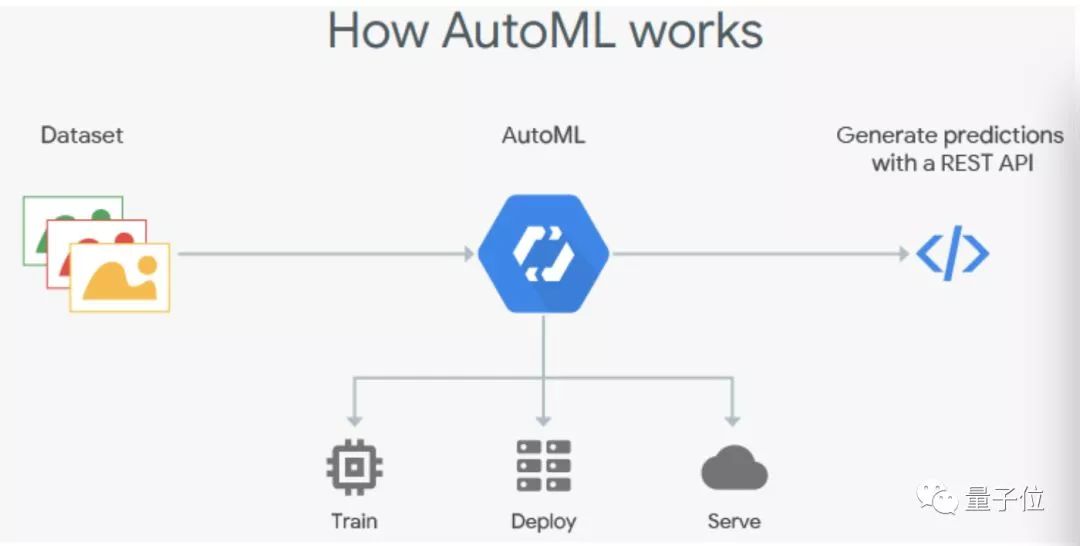
谷歌云的AutoML pipeline
不过,AutoML价格也并不算亲民,每小时收费20美元。此外,一旦你开始训练,则无法导出模型,并且得用谷歌提供的API在云上运行你的网络,这些限制看起来都不是很方便,
AutoKeras也是一个使用了ENAS算法的GitHub项目,可以使用pip安装。它是用Keras编写的,因此很容易控制和使用,甚至可以自己深入研究ENAS算法并尝试进行一些改动。
如果你喜欢用TensorFlow或者Pytorch,也有一些开源项目可用:
https://github.com/melodyguan/enas
https://github.com/carpedm20/ENAS-pytorch
总的来说,若你想使用AutoML,现在已经有很多不同的选择,这完全取决于你是否会使用你想要的算法,以及你对这件事的预算如何。
过去几年,在深度学习工作的自动化上,整个领域都在大步向前,让深度学习更贴近大众、更易用。
不过,进步的空间永远都有。
架构搜索已经越来越高效了,用ENAS,一个GPU一天就能找出一种新的网络架构。的确鹅妹子嘤,但是这个搜索空间依然非常有限,而且,现在NAS算法所用的基本结构和模块还是人工设计的,只是将组装的过程自动化了。
将来要想取得重大突破,在更广阔的搜索范围里搜索真正的新架构是一个重要方向。
如果这样的算法出现,甚至能为我们揭示庞大复杂深度神经网络中隐藏的秘密。
当然,要实现这样的搜索空间,需要设计出更高效的算法。
最后,附上原文传送门:
https://towardsdatascience.com/the-end-of-open-ai-competitions-ff33c9c69846
编辑:王怡蔺
本文经AI新媒体量子位(公众号 ID: QbitAI)授权转载,转载请联系出处。
区块链技术如何堵上深度学习的隐私漏洞
解救深度学习过拟合的神器:非线性系数
图网络:悄然兴起的深度学习新浪潮
关系式归纳偏好、深度学习和图网络
加入集智,一起复杂!










