
作者: 高级农民工
公众号:第2大脑
个人博客:https://www.makcyun.top/
摘要::最近在朋友圈看到一个很酷炫的动态数据可视化表,介绍了新中国成立后各省GDP的发展历程,非常惊叹竟然还有这种操作,也想试试。于是,照葫芦画瓢虎,在网上爬取了历年中国大学学术排行榜,制作了一个中国大学排名Top20强动态表。
由于本文中含有一些超链接,微信中无法直接打开,所以建议点击最左下角阅读原文阅读,体验更好,也可以复制链接到浏览器打开:
https://www.makcyun.top/Python_analysis1.html
1. 作品介绍
这里先放一下这个动态表是什么样的:
不知道你看完是什么感觉,至少我是挺震惊的,想看看作者是怎么做出来的,于是追到了作者的B站主页,发现了更多有意思的动态视频:
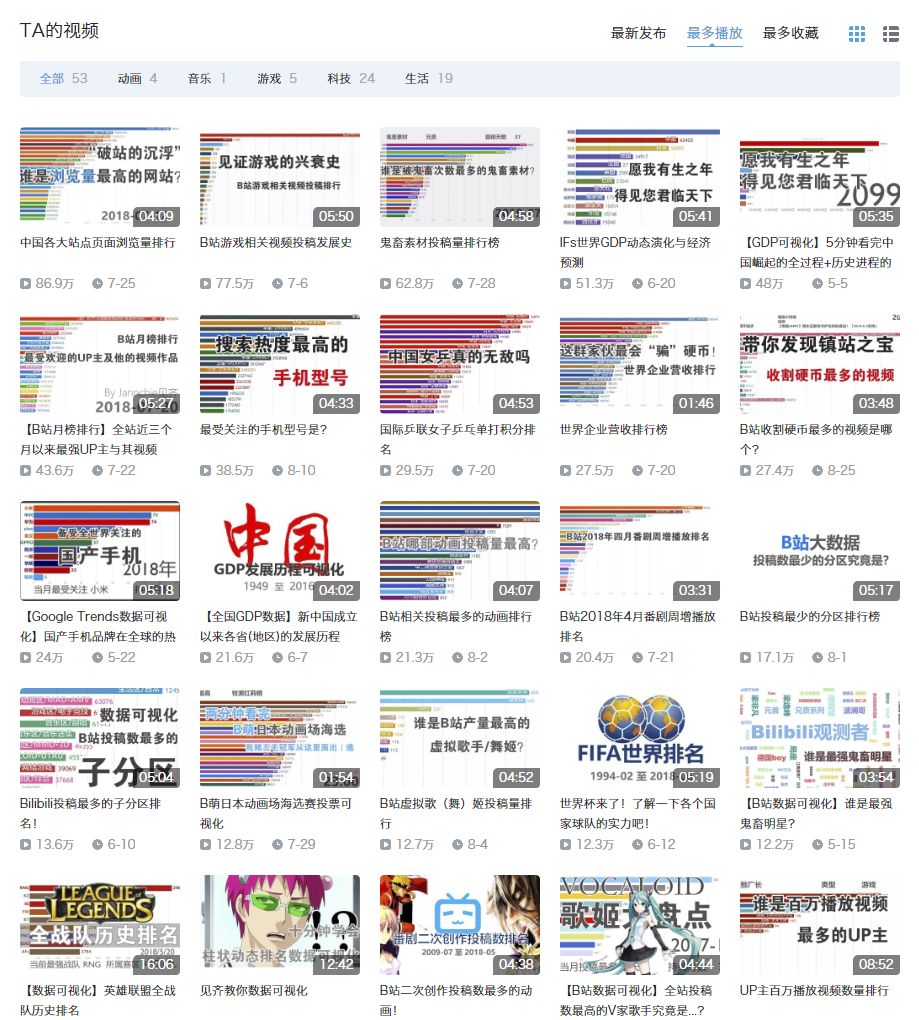
这些作品的作者是:@Jannchie见齐,他的主页:https://space.bilibili.com/1850091/#/video
这些会动的图表是如何做出来的呢?他用到的是一个动态图形显示数据的JavaScript库:D3.js,一种前端技术。难怪不是一般地酷炫。
那么,如果不会D3.js是不是就做不出来了呢?当然不是,Jannchie非常Open地给出了一个手把手的简单教程:
https://www.bilibili.com/video/av28087807
他同时还开放了程序源码,你只需要做2步就能够实现:
下面,我们稍微再说详细一点,实现这种效果的关键点是要有数据。观察一下上面的作品可以看到,横向柱状图中的数据要满足两个条件:一是要有多个对比的对象,二是要在时间上连续。这样才可以做出动态效果来。
看完后我立马就有了一个想法:想看看近十年中国的各个大学排名是个什么情况。下面我们就通过实例来操作下。
2. 案例操作:中国大学Top20强
2.1. 数据来源
世界上最权威的大学排名有4类,分别是:
原上海交通大学的ARWU
http://www.shanghairanking.com/ARWU2018.html
英国教育组织的QS
https://www.topuniversities.com/university-rankings/world-university-rankings/2018
泰晤士的THE
https://www.timeshighereducation.com/world-university-rankings
美国的usnews
https://www.usnews.com/best-colleges/rankings
关于,这四类排名的更多介绍,可以看这个:
https://www.zhihu.com/question/20825030/answer/71336291
这里,我们选取相对比较权威也比较符合国情的第一个ARWU的排名结果。打开官网,可以看到有英文版和中文版排名,这里选取中文版。 排名非常齐全,从2003年到最新的2018年都有,非常好。
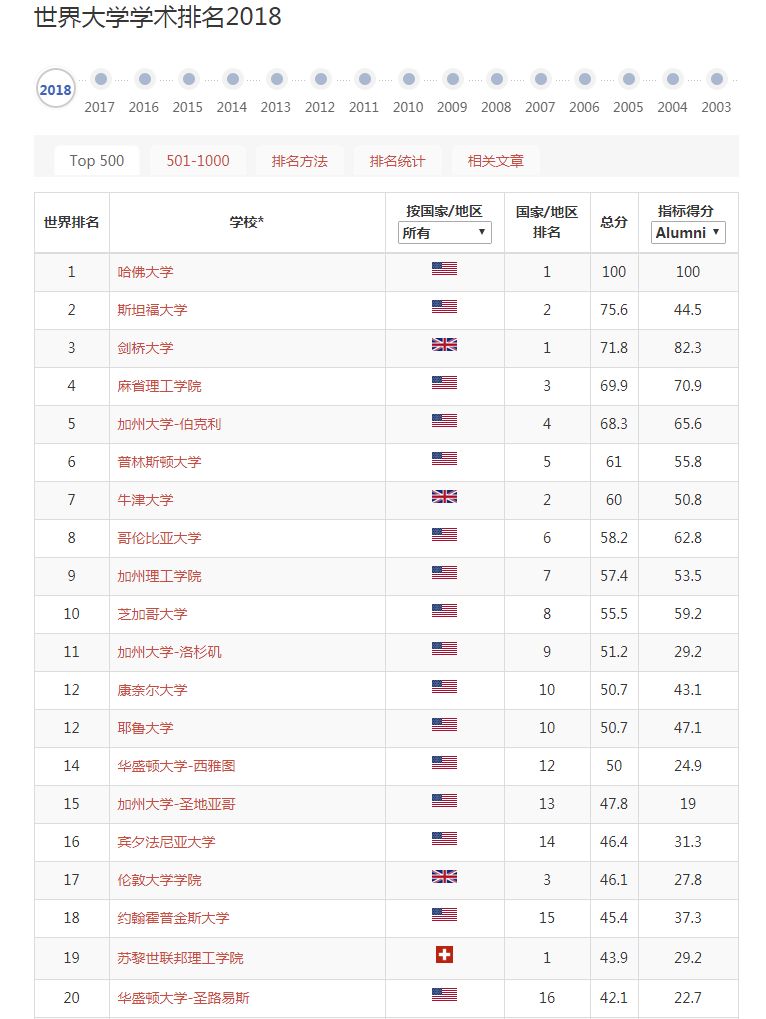
同时,可以看到这是世界500强的大学排名,而我们需要的是中国(包括港澳台)的大学排名。怎么办呢? 当然不能一年年地复制然后再从500条数据里一条条筛选出中国的,这里就要用爬虫来实现了。可以参考不久前的一篇爬取表格的文章:
10行代码爬取全国所有A股/港股/新三板上市公司信息
2.2. 抓取数据
2.2.1. 分析url
首先,分析一下URL:
1http://www.zuihaodaxue.com/ARWU2018.html
2http://www.zuihaodaxue.com/ARWU2017.html
3...
4http://www.zuihaodaxue.com/ARWU2009.html
可以看到,url非常有规律,只有年份数字在变,很简单就能构造出for循环。
格式如下:
1url = 'http://www.zuihaodaxue.com/ARWU%s.html' % (str(year))
下面就可以开始写爬虫了。
2.2.2. 获取网页内容
1import requests
2try:
3 url = 'http://www.zuihaodaxue.com/ARWU%s.html' % (str(year))
4
response = requests.get(url,headers = headers)
5 # 2009-2015用'gbk',2016-2018用'utf-8'
6 if response.status_code == 200:
7 # return response.text # text会乱码,content没有问题
8 return response.content
9 return None
10except RequestException:
11print('爬取失败')
上面需要注意的是,不同年份网页采用的编码不同,返回response.test会乱码,返回response.content则不会。关于编码乱码的问题,以后单独写一篇文章。
2.2.3. 解析表格
用read_html函数一行代码来抓取表格,然后输出:
1tb = pd.read_html(html)[0]
2print(tb)
可以看到,很顺利地表格就被抓取了下来:

但是表格需要进行处理,比如删除掉不需要的评分列,增加年份列等,代码实现如下:
1tb = pd.read_html(html)[0]
2# 重命名表格列,不需要的列用数字表示
3tb.columns = ['world rank','university', 2,3, 'score',5,6,7,8,9,10]
4tb.drop([2,3,5,6,7,8,9,10],axis = 1,inplace = True)
5# 删除后面不需要的评分列
6# rank列100名后是区间,需需唯一化,增加一列index作为排名
7tb['index_rank'] = tb.index
8tb['index_rank'] = tb['index_rank'].astype(int) + 1
9
10# 增加一列年份列
11tb['year'] = i
12# read_html没有爬取country,需定义函数单独爬取
13tb['country'] = get_country(html)
14return tb
需要注意的是,国家没有被抓取下来,因为国家是用的图片表示的,定位到国家代码位置:

可以看到美国是用英文的USA表示的,那么我们可以单独提取出src属性,然后用正则提取出国家名称就可以了,代码实现如下:
1# 提取国家名称
2def get_country(html):
3 soup = BeautifulSoup(html,'lxml')
4 countries = soup.select('td > a > img')
5 lst = []
6 for i in countries:
7 src = i['src']
8 pattern = re.compile('flag.*\/(.*?).png')
9 country = re.findall(pattern,src)[0]
10 lst.append(country)
11 return lst
然后,我们就可以输出一下结果:
1 world rank university score index_rank year country
20 1 哈佛大学 100.0 1 2018 USA
31 2 斯坦福大学 75.6 2 2018 USA
42 3 剑桥大学 71.8 3 2018 UK
53 4 麻省理工学院 69.9
4 2018 USA
64 5 加州大学-伯克利 68.3 5 2018 USA
75 6 普林斯顿大学 61.0 6 2018 USA
86 7 牛津大学 60.0 7 2018 UK
97 8 哥伦比亚大学 58.2 8 2018 USA
108 9 加州理工学院 57.4 9 2018 USA
119 10 芝加哥大学 55.5 10
2018 USA
1210 11 加州大学-洛杉矶 51.2 11 2018 USA
1311 12 康奈尔大学 50.7 12 2018 USA
1412 12 耶鲁大学 50.7 13 2018 USA
1513 14 华盛顿大学-西雅图 50.0 14 2018 USA
1614 15 加州大学-圣地亚哥 47.8 15 2018 USA
1715 16 宾夕法尼亚大学 46.4 16 2018 USA
18
16 17 伦敦大学学院 46.1 17 2018 UK
1917 18 约翰霍普金斯大学 45.4 18 2018 USA
2018 19 苏黎世联邦理工学院 43.9 19 2018 Switzerland
2119 20 华盛顿大学-圣路易斯 42.1 20 2018 USA
2220 21 加州大学-旧金山 41.9 21 2018 USA
数据很完美,接下来就可以按照D3.js模板中的example.csv文件的格式作进一步的处理了。
2.3. 数据处理
这里先将数据输出为university.csv文件,结果见下表:

10年一共5011行×6列数据。接着,读入该表作进一步数据处理,代码如下:
1df = pd.read_csv('university.csv')
2# 包含港澳台
3# df = df.query("(country == 'China')|(country == 'China-hk')|(country == 'China-tw')|(country == 'China-HongKong')|(country == 'China-Taiwan')|(country == 'Taiwan,China')|(country == 'HongKong,China')")[['university','year','index_rank']]
4
5# 只包括内地
6df = df.query("(country == 'China')")
7df['index_rank_score'] = df['index_rank']
8# 将index_rank列转为整形
9df['index_rank'] = df['index_rank'].astype(int)
10
11# 美国
12# df = df.query("(country == 'UnitedStates')|(country == 'USA')")
13
14#求topn名
15def topn(df):
16 top = df.sort_values(['year','index_rank'],ascending = True)
17 return top[:20].reset_index()
18df = df.groupby(by =['year']).apply(topn)
19
20# 更改列顺序
21df = df[['university','index_rank_score','index_rank','year']]
22# 重命名列
23df.rename (columns = {'university':'name','index_rank_score':'type','index_rank':'value','year':'date'},inplace = True)
24
25
# 输出结果
26df.to_csv('university_ranking.csv',mode ='w',encoding='utf_8_sig', header=True, index=False)
27# index可以设置
上面需要注意两点:
打开输出的university_ranking.csv文件:

结果非常好,可以直接作为D3.js的导入文件了。
2.3.1. 完整代码
将代码再稍微完善一下,完整地代码如下所示:
1import pandas as pd
2import csv
3import requests
4from requests.exceptions import RequestException
5from bs4 import BeautifulSoup
6import time
7import re
8
9start_time = time.time() #计算程序运行时间
10# 获取网页内容
11def get_one_page(year):
12 try:
13 headers = {
14 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
15 }
16 # 英文版
17 # url = 'http://www.shanghairanking.com/ARWU%s.html' % (str(year))
18 # 中文版
19 url = 'http://www.zuihaodaxue.com/ARWU%s.html' % (str(year))
20 response = requests.get(url,headers = headers)
21 # 2009-2015用'gbk',2016-2018用'utf-8'
22 if response.status_code == 200:
23 # return response.text # text会乱码,content没有问题
24 # https://stackoverflow.com/questions/17011357/what-is-the-difference-between-content-and-text
25 return response.content
26 return None
27 except RequestException:
28 print('爬取失败')
29
30# 解析表格
31def parse_one_page(html,i):
32 tb = pd.read_html(html)[0]
33 # 重命名表格列,不需要的列用数字表示
34 tb.columns = ['world rank','university', 2,3
, 'score',5,6,7,8,9,10]
35 tb.drop([2,3,5,6,7,8,9,10],axis = 1,inplace = True)
36 # 删除后面不需要的评分列
37
38 # rank列100名后是区间,需需唯一化,增加一列index作为排名
39 tb['index_rank'] = tb.index
40 tb['index_rank'] = tb['index_rank'].astype(int) + 1
41 # 增加一列年份列
42 tb['year'] = i
43 # read_html没有爬取country,需定义函数单独爬取
44
tb['country'] = get_country(html)
45 # print(tb) # 测试表格ok
46 return tb
47 # print(tb.info()) # 查看表信息
48 # print(tb.columns.values) # 查看列表名称
49
50# 提取国家名称
51def get_country(html):
52 soup = BeautifulSoup(html,'lxml')
53 countries = soup.select('td > a > img')
54 lst = []
55 for i in countries:
56 src = i['src']
57 pattern = re.compile('flag.*\/(.*?).png')
58 country = re.findall(pattern,src)[0]
59 lst.append(country)
60
return lst
61 # print(lst) # 测试提取国家是否成功ok
62
63# 保存表格为csv
64def save_csv(tb):
65 tb.to_csv(r'university.csv', mode='a', encoding='utf_8_sig', header=True, index=0)
66
67 endtime = time.time()-start_time
68 # print('程序运行了%.2f秒' %endtime)
69
70def analysis():
71 df = pd.read_csv('university.csv')
72 # 包含港澳台
73 # df = df.query("(country == 'China')|(country == 'China-hk')|(country == 'China-tw')|(country == 'China-HongKong')|(country == 'China-Taiwan')|(country == 'Taiwan,China')|(country == 'HongKong,China')")[['university','year','index_rank']]
74 # 只包括内地
75
df = df.query("(country == 'China')")
76
77 df['index_rank_score'] = df['index_rank']
78 # 将index_rank列转为整形
79 df['index_rank'] = df['index_rank'].astype(int)
80 # 美国
81 # df = df.query("(country == 'UnitedStates')|(country == 'USA')")
82 #求topn名
83 def topn(df):
84 top = df.sort_values(['year','index_rank'],ascending = True)
85 return top[:20].reset_index()
86 df = df.groupby(by =['year']).apply(topn)
87 # 更改列顺序
88 df = df[['university','index_rank_score'
,'index_rank','year']]
89 # 重命名列
90 df.rename (columns = {'university':'name','index_rank_score':'type','index_rank':'value','year':'date'},inplace = True)
91
92 # 输出结果
93 df.to_csv('university_ranking.csv',mode ='w',encoding='utf_8_sig', header=True, index=False)
94 # index可以设置
95
96def main(year):
97 # generate_mysql()
98 for i in range(2009,year): #抓取10年
99 # get_one_page(i)
100 html = get_one_page(i)
101 # parse_one_page(html,i) # 测试表格ok
102 tb = parse_one_page(html,i)
103 save_csv(tb)
104 print(i,'年排名提取完成完成')
105 analysis()
106# # 单进程
107if __name__ == '__main__':
108 main(2019)
109 # 2016-2018采用gb2312编码,2009-2015采用utf-8编码
至此,我们已经有university_ranking.csv基础数据,下面就可以进行可视化呈现了。
2.4. 可视化呈现
首先,到作者的github主页:
https://github.com/Jannchie/Historical-ranking-data-visualization-based-on-d3.js
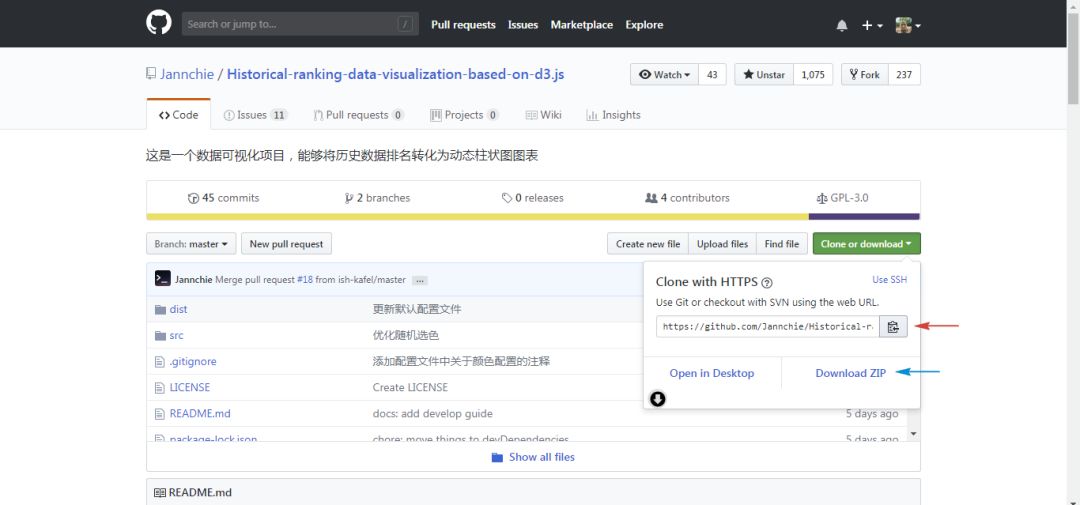
2.4.1. 克隆仓库文件
如果你平常使用github或者Git软件的话,那么就找个合适文件存放目录,然后直接在 GitBash里分别输入下面3条命令就搭建好环境了:
1# 克隆项目仓库
2git clone https://github.com/Jannchie/Historical-ranking-data-visualization-based-on-d3.js
3# 切换到项目根目录
4cd Historical-ranking-data-visualization-based-on-d3.js
5# 安装依赖
6npm install
如果你此前没有用过上面的软件,你可以直接点击Download Zip下载下来然后解压即可,不过还是强烈建议使用第一种方法,因为后面如果要自定义可视化效果的话,需要修改代码然后执行npm run build命令才能够看到效果。
2.4.2. 效果呈现
好,所有基本准备都已完成,下面就可以试试看效果了。
任意浏览器打开bargraph.html网页,点击选择文件,然后选择前面输出的university_ranking.csv文件,看下效果:
可以看到,有了大致的可视化效果,但还存在很多瑕疵,比如:表顺序颠倒了、字体不合适、配色太花哨等。可不可以修改呢?
当然是可以的,只需要分别修改文件夹中这几个文件的参数就可以了:
config.js 全局设置各项功能的开关,比如配色、字体、文字名称、反转图表等等功能;
color.css 修改柱形图的配色;
stylesheet.css 具体修改配色、字体、文字名称等的css样式;
visual.js 更进一步的修改,比如图表的透明度等。
知道在哪里修改了以后,那么,如何修改呢?很简单,只需要简单的几步就可以实现:
最后,再添加一个合适的BGM就可以了。以下是我优化之后的效果:
BGM:ツナ覚醒
如果你不太会调整,没有关系,我会分享优化后的配置文件。
以上,就是实现动态可视化表的步骤。 同样地,只要更改数据源可以很方便地做出世界、美国等大学的动态效果,可以看看:
中国(含港澳台)大学排名:
http://pc1lljdwb.bkt.clouddn.com/Greater_China_uni_ranking.mp4
美国大学排名:
http://pc1lljdwb.bkt.clouddn.com/USA_uni_ranking.mp4
文章所有的素材,在公众号后台回复大学排名就可以得到,或者到我的github下载:
https://github.com/makcyun/web_scraping_with_python
感兴趣的话就动手试试吧。
本文完。

Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,“Python爱好者社区”
,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”
,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门免费视频课程!!!
【最新免费微课】小编的Python快速上手matplotlib可视化库!!!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。










