第七届国际学习表征会议 ICLR 2019 将于明年 5 月在美国新奥尔良举办,目前该会议的论文正处于双盲评议阶段。本文介绍的这篇论文介绍了一种通过浅度学习优化深度网络的方法,实验表明这种方法在某些任务上能达到端到端的深度学习方法的同等表现。
论文地址:https://openreview.net/pdf?id=r1Gsk3R9Fm

摘要:浅度的监督式的具有 1 个隐藏层的神经网络具有一些受人喜爱的性质,使得它们比深度网络更容易被解释、分析和优化;但它们的表征能力却不及深度网络。这里我们使用了具有 1 个隐藏层的学习问题来序列式地逐层构建深度网络,其能够继承浅度网络的属性。与之前的使用浅度网络的方法相反,我们关注的是有研究认为深度学习具有至关重要的价值的问题。因此,我们在两个大规模图像识别任务上研究了 CNN:ImageNet 和 CIFAR-10。使用一组简单的架构和训练的思路,我们发现求解序列式的具有 1 个隐藏层的辅助问题能使所得到的 CNN 的表现超越 AlexNet 在 ImageNet 上的表现。我们还对我们的训练方法进行了扩展,通过求解 2 和 3 个隐藏层的辅助问题来构建单个层,我们得到了一个 11 层的网络,其在 ImageNet 上优于 VGG-11,得到了 89.8% 的 top-5 单个裁剪识别准确度(single crop)。就我们所知,这是首个可扩展用于 ImageNet 且可媲美端到端的 CNN 训练的替代方法。我们进行了广泛的实验,研究了其在中间层上的性质。
引言
通过反向传播算法在大规模有监督数据上训练的深度卷积神经网络(CNN)已经成为了大多数计算机视觉任务中的主导方法(Krizhevsky et al., 2012)。这也推动了深度学习在其它领域的成功应用,比如语音识别(Chan et al., 2016)、自然语言处理(Vaswani et al., 2017)和强化学习(Silver et al., 2017)。但是,我们仍然还难以理解深度网络的行为以及它们表现出色的原因。这种困难的一大原因是网络的层中采用了端到端的学习方式。
监督式的端到端学习是神经网络优化的标准方法。但是其也存在一些值得考虑的潜在问题。首先,使用全局目标就意味着一个深度网络的单个中间层的最终函数行为只能以间接的方式确定:这些层是如何协同工作以得到高准确度的预测结果的,这一点却完全不明晰。有一些研究者认为并且通过实验表明 CNN 能够学习实现这样的机制:将不变性逐渐诱导成复杂但不相关的可变性(Mallat, 2016; Yosinski et al., 2015),同时增加数据的线性可分性(Zeiler & Fergus, 2014; Oyallon, 2017; Jacobsen et al., 2018)。
虽然 CNN 已经在实验中表现出了渐进的线性可分性,但我们仍不清楚这完全是由 CNN 所实现的其它策略所造成的结果,还是所观察的这些网络的优良表现的一个充分条件。其次,理解浅度神经网络和深度神经网络之间的联系是很困难的:尽管已有研究给出了具有 1 个隐藏层的神经网络的泛化、近似或优化结果(Barron, 1994; Bach, 2014; Venturi et al., 2018; Neyshabur et al., 2018; Pinkus, 1999),但这些研究也表明从理论上理解具有多个隐藏层的神经网络要困难得多。最后,在计算和内存资源方面,端到端的反向传播可能很低效(Jaderberg et al., 2016; Salimans et al., 2017)。此外,对于某些学习问题而言,完整梯度的信息量不及其它方法(Shalev-Shwartz et al., 2017)。
通过求解浅度监督学习问题而实现的 CNN 层的序列学习是一种可替代端到端反向传播的方法。这一策略可以直接指定每一层的目标,例如通过激励对表征的特定属性的精细化(Greff et al., 2016),比如渐进的线性可分性。然后,就可以根据对浅度子问题的理论理解来开发用于深度贪婪式方法的理论工具。实际上,Arora et al. (2018)、Bengio et al. (2006)、Bach (2014)、Janzamin et al. (2015) 表明了全局最优近似,同时还有其它研究表明基于 1 个隐藏层训练的网络在特定的假设下可以有不同种类的确定结果(Huang et al., 2017; Malach & Shalev-Shwartz, 2018; Arora et al., 2014):逐个贪婪层的方法允许将这些结果级联成更大的架构。
最后,贪婪方法对读取完整梯度的依赖要低得多。这有望避免出现类似 Shalev-Shwartz et al. (2017) 中的问题。从算法角度看,它们不需要保存大多数的中间激活,也无需计算大多数的中间梯度。这有益于内存有限的场景。不幸的是,之前的研究没能让人信服的证明逐层策略可以解决这种类型的大规模问题,而正是这些问题将深度学习带到了聚光灯下。我们提出了一种可直接简单地用于 CNN 的策略,并且表明该策略可以扩展和分析其构建的表征。
我们的贡献如下:(1)首先,我们在第 3 节设计了一种简单且可扩展的用于学习逐层 CNN 的方法。(2)然后,第 4.1 节通过实验表明:通过序列式地求解具有 1 个隐藏层的问题,我们可以达到与基于 ImageNet 的 AlexNet 相媲美的表现。这为那些研究具有 1 个隐藏层的网络及其序列式训练的同等网络的文献提供了支持。(3)我们在第 4.2 节表明逐层训练的层能表现出渐进的线性可分性。(4)尤其需要指出,我们借此通过浅度的具有 k 个隐藏层的辅助问题(k>1)来激励逐层 CNN 层的学习。使用这一方法,我们的序列式训练的具有 3 个隐藏层的模型的表现能够达到 VGG-13 的水平(第 4.3 节)。(5)我们提出了一种方法,可以在这些网络的训练过程中轻松降低模型的大小。
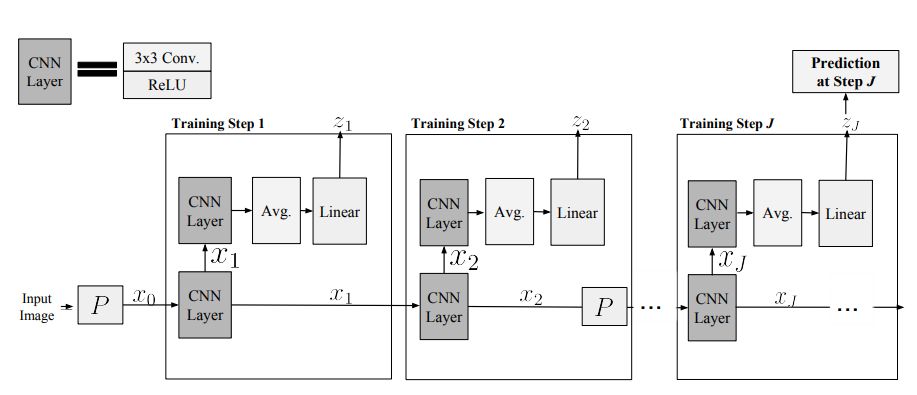
图 1:我们的逐层学习框架的高层面图示,使用了 k=2 个隐藏层。输入图像以及 j=2 时都使用了下采样 P(Jacobsen et al., 2018)
实验和讨论
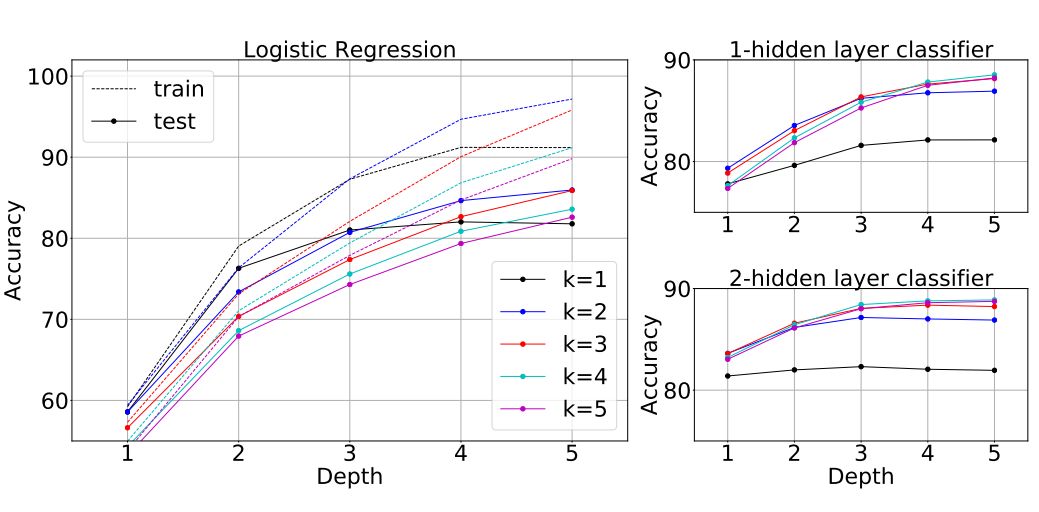
图 2:CIFAR-10 模型的(左)线性和(右)CNN-p 可分性随网络深度的变化。对于线性可分性,我们聚合了 M = 64, 128, 256 的结果,附录 C 给出了各个结果,相对趋势也很大程度上没有变化,但更大的 M 中的整体准确度也更高。对于 CNN-p 探针,所有的模型都在第 1 或 2 层实现了 100% 的训练准确度,所以这里仅给出了测试准确度。
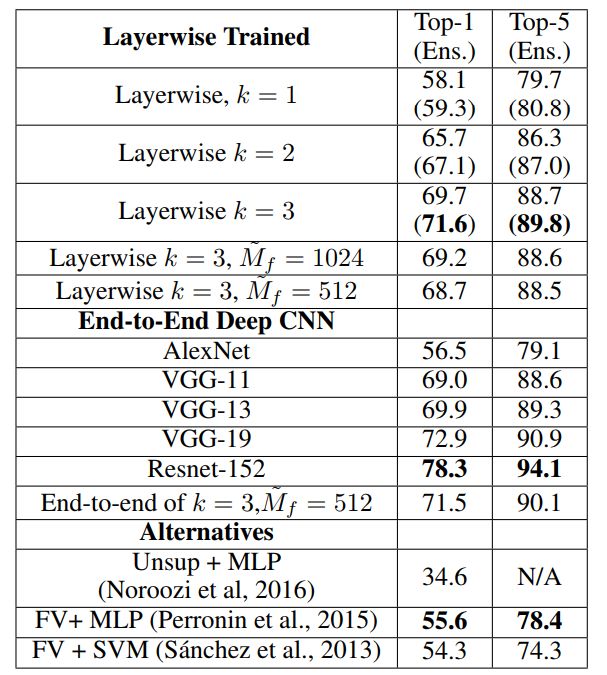
表 1:在 ImageNet 上的单个裁剪验证准确度。我们的模型使用了 J=8。括号中的数据是集成预测结果。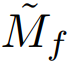 指定了模型的辅助网络,其替代了最后一个辅助网络。相对于原来的更大的辅助网络,它们仅表现出了少量损失。逐层模型与类似的没有使用 skip 连接的基准方法表现相当,并且优于所有其它端到端方法。
指定了模型的辅助网络,其替代了最后一个辅助网络。相对于原来的更大的辅助网络,它们仅表现出了少量损失。逐层模型与类似的没有使用 skip 连接的基准方法表现相当,并且优于所有其它端到端方法。
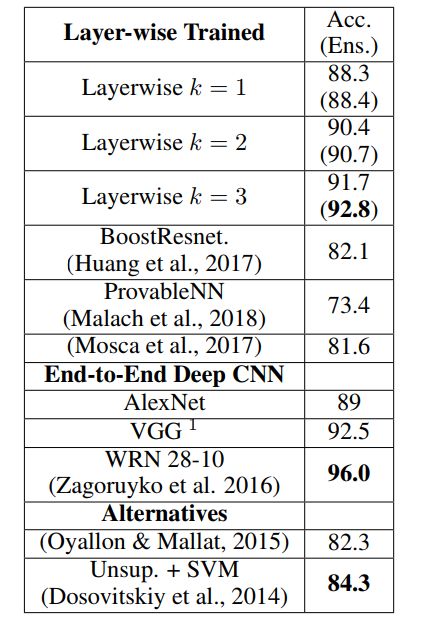
表 2:在 CIFAR-10 上的结果。相比于几种已有的方法,我们仅使用逐层训练方案就实现了显著的性能提升。整体而言,我们的模型和相似的未使用 skip 连接的著名基准模型的表现相当。
架构的数学形式
我们的架构有 J 个模块(见图 1),它们是连续训练的。根据输入信号 x,一个初始表征 x0,x 传播通过 j 个卷积,得到 xj。每个 xj 都输入一个辅助分类器,得到预测结果 zj,其计算的是一个中间的分类输出。在深度 j 处,用 Wθj 表示一个带有参数 θj 的卷积算子,用 Cγj 表示所有参数为 γj 的辅助分类器,用 Pj 表示下采样算子。这些参数对应于具有偏置项的 3×3 卷积核。从形式上看,对于 xj 层,我们以如下方式构建 {xj+1, zj+1}:
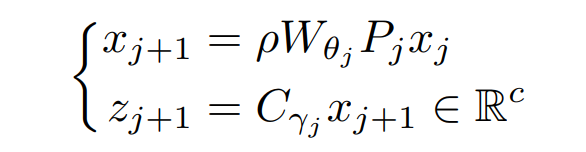
其中 c 是类别的数量。对于池化算子 P,我们选择的是 Dinh et al. (2017) 中描述的可逆的下采样运算,其中包括将初始的空间通道重组成 4 个以空间方式抽取的副本,这些副本可通过 2×2 的空间子采样获得,从而将分辨率降低 2 倍。我们决定不使用跨步池化、平均池化和非线性最大池化,因为这些池化方法会显著加剧信息损失。作为 CNN 中的标准做法,P 被应用在了特定的层中(Pj=P),但在其它层中没有使用(Pj=Id)。分类器 Cγj 是一个 CNN,可以写成:
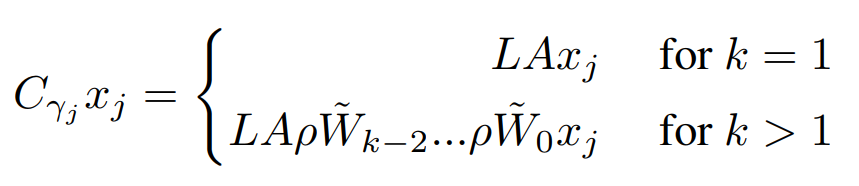
其中 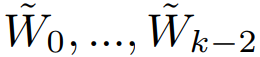 是宽度恒定的卷积层,A 是一个空间平均算子,L 是一个输出维度为 c 的线性算子。需要指出,这个平均操作在早期层中对于维持可扩展性而言是很重要的。可以看到,当 k=1 时,Cγj 只是一个简单的线性模型,在这种情况下,我们的架构将会由带有 1 个隐藏层的 CNN 的一个序列来训练。
是宽度恒定的卷积层,A 是一个空间平均算子,L 是一个输出维度为 c 的线性算子。需要指出,这个平均操作在早期层中对于维持可扩展性而言是很重要的。可以看到,当 k=1 时,Cγj 只是一个简单的线性模型,在这种情况下,我们的架构将会由带有 1 个隐藏层的 CNN 的一个序列来训练。
想要了解更多资讯,请扫描下方二维码,关注机器学习研究会

转自: 机器之心











