
PDF诞生自Camelot项目。目的是创建一个通用的文档交流格式,以支持多种机器平台,操作系统和通信网络。其目标是使文档能够在任何显示器上可视,在任何现代打印机上可打印。PDF基于PostScript(一种页面描述语言)。该语言解决了在任意地方显示和打印的问题。PDF包含了文档“在任意地方可视和打印”所需的组件。比如,字符、字体、图表、图片等。
一个PDF文档包含许多放置文字(或其他组件)的指令。这些指令使用以页面左下角为原点的x、y坐标放置页面元素。一个单词通过将几个字符紧凑的放置在一起来模拟。同样的,空白通过使字符间隔更大来模拟。那怎样模拟一个表格呢?你猜对了-- 通过把字符摆放得跟一个电子表格一样来模拟。
PDF中没有一个内部的表示方式来表示一个表格。这使得表格数据很难被抽取出来做分析。不幸的是很多开放的数据是存储在pdf格式的文件中的。但是PDF格式在设计上并没有很好的支持表格数据。
Camelot: 一个友好的PDF表格数据抽取工具
今天,我们很高兴的发布了Camelot。一个python命令行工具,使任何人都能很轻松的从PDF文件中抽取表格数据。
安装 Camelot
安装非常简单! 在安装相关的依赖后,可以直接使用pip安装。
$ pip install camelot-py
怎样使用Camelot
使用Camelot从PDF文档提取数据非常简单
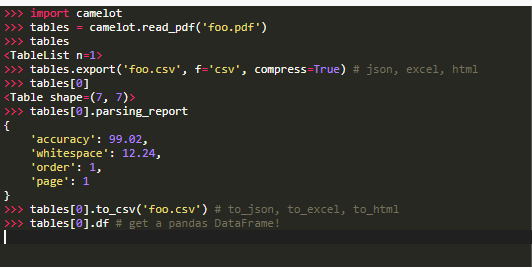
为什么使用Camelot
.Camelot允许你通过调整设置项来精确控制数据的提取过程
.可以根据空白和精度指标来判断坏的表格,并丢弃,而不必手动检查
.每一个表格数据是一个panda的dataframe,从而可以很方便的集成到ETL和数据分析工作流中
.可以把数据导出为各种不同的格式比如 CSV、JSON、EXCEL、HTML
好的,为什么不是其他的PDF表格数提取库?
Camelot为数据抽取过程提供全部的控制权
许多人使用开源的库或者商业库来做数据提取工作。但是这些库要么很完美的提取出数据,要么完全失败。而不是介于这两者之间。但是现实世界并不总是这么界限分明,包括PDF提取数据。而这导致了我们需要为每一个PDF定制专门的脚本。我们创建了Camelot库对提取数据的过程提供了完全的控制权。假如你用默认方式无法获取数据,你可以通过调整参数来适配。
延伸阅读
我们经常需要从pdf提取表格数据。我们刚开始使用工具是Tabula ,它有非常友好的操作方式。但是它要么能完美的处理数据,要么完全不可用。当处理失败时,要调整参数却异常困难。比如--- 影响表格识别或美化输出的 图片阈值参数。我们同样也尝试过商业工具 比如 smallpdf 和 pdftables。它们的表现比Tabula要好一些,但同样的,不允许我们调整参数并且要收费。(我们写一篇博文关于如何从PDF中提取表格数据)。
当那些成熟的工具无法工作时,我们尝试了 pdftotext (开源的PDF命令行工具).pdftotext把文本数据从PDF中提取出来,并保持了相应的布局。当获取到文本数据以后,我们使用python脚本,以正则匹配的方法来把文本数据转换成表格数据。但这个方法不具有扩展性,因为我们必须根据每个表格的布局来写正则表达式。
我们迫切需要一个新的PDF表格数据提取工具。因而,2015年开始我们启动了开发工作。我们从社区获得了非常多的开源工具的支持,所以我们一开始就打算把这个工具回馈给社区。
Tabula吧pdf表格分为两类,它使用两种不同的方法来为这两种类型的pdf提取数据。Lattice (提取使用分割线分隔单元格的表格),Stream (提取用空格分隔单元格的表格)。 我们在此沿用了Tabula的命名方式 Lattice 和 Stream。
针对Lattice,Tabula使用霍夫变换,一个侦测线条的图像处理技术。因为我们使用python。所以使用opencv处理图像成了显而易见的选择。然而opencv的 霍夫变换 只返回一个直线方程。通过更多的摸索,我们决定使用能直接返回一个线段的形态学变换,使用这个方法可以实现对PDF中表格的直接捕获。
想了解更多Camelot中Lattice和Stream工作细节,请查看文档
我们如何使用Camelot
我们将Camelot应用在许多项目中,并进行测试。在今年早些时候,我们开发了我们的联合国 SDG 解决方案。已帮助该组织跟踪和评估他们在 Agenda 2030中的贡献。针对印度,我们为17个可持续发展目标整理出数据(这些数据主要在PDF格式的文件中)。比如目标3("人民健康和幸福")是IPPS发布的国家家庭健康调查报告。为了从这个PDF中提取表格数据,我们在Camelot之上构建的一个web界面,这样我们的数据分析师通过上传pdf文档就能以自己想要的数据格式提取数据。
我们也建立了一个基于Apache Airflow的ETL工作流,来跟踪印度的疾病爆发。这个工作流从综合疾病监测计划(IIPS)网站获取每周的疾病爆发数据PDF文档,然后使用Camelot从中提取数据,然后向我们的团体发出告警,并且将数据存储到数据仓库中。
永不止步
Camelot也有一些限制。(我们已经开发了解决方案),有以下这些
当使用Stream时,表格无法被自动侦测到。Stream把整个页面当成一个table,这样当页面有多个表格时会产生错误的输出。
Camelot 只能使用基于文本的PDF文件而不能使用扫描文档。
你可以在各个方面为我们的项目作出贡献。可以贡献代码,文档、测试、报告问题提出改善建议。当然也可以在 issue tracker 中帮忙解决问题。
我们强烈建议使用数据友好的格式(比如csv)来发布公开数据。但是当表格数据包含在pdf文件中,记住Camelot 在你身边!
英文原文:https://blog.socialcops.com/technology/engineering/camelot-python-library-pdf-data/
译者:Sailor










