zarten,互联网一线工作者。
博客地址:zhihu.com/people/zarten
概述
亚马逊网站验证码全部由英文字母组成,每个字母的形式也是多样的,通过Tesseract-OCR技术识别效率还是比较低,非常不理想。这里采用向量空间技术进行训练识别,经测试,识别率可达到95%,这个识别率通过训练库的不断增加还可继续提高。下面废话不多说,直接上干货。
技术详解
亚马逊验证码如下图:
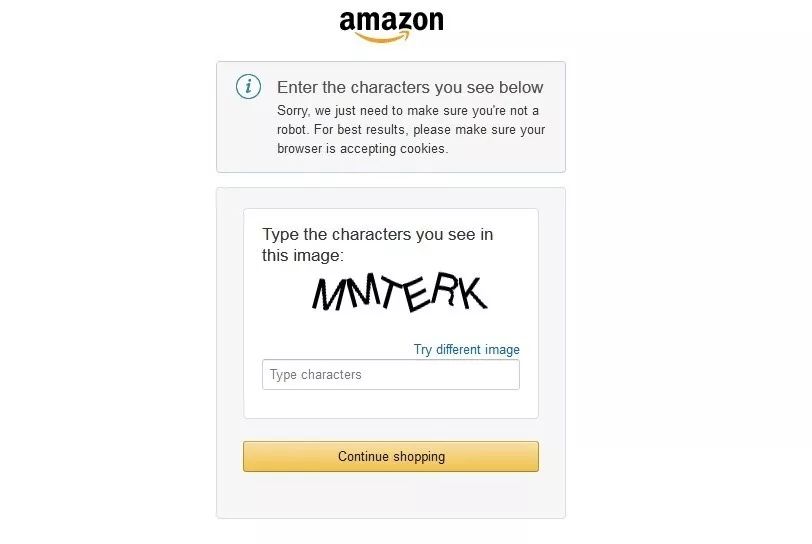
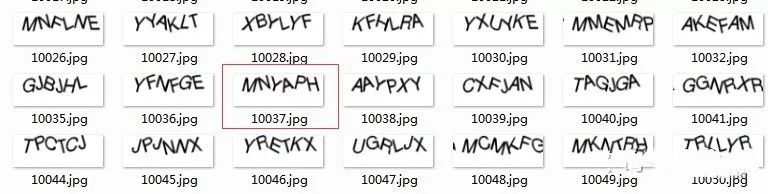
我这里收集了大量的亚马逊网站验证码,下面将随机抽一张验证码为mnyaph作详细讲解,如下图:
总体思路
1.将原图片作二值化等特殊处理转换得到低像素图片
2.分割出每个字母的图片,并加入到训练库中
3.每个字母图片在训练库中训练
4.将每个字母图片训练后的结果依次组合起来,就是最终验证码
使用技术库
PIL :图片处理库
scipy : 科学计算库
这里将jpg格式转换为更小容量的gif格式,方便后面处理,并将原图片中的黑色像素(0)拷贝到新的相同尺寸的白色图片上,得到新的Image对象。下图为处理后的图片

im = Image.open(image_file)
im = im.convert('P')
im_size = im.size
new_im = Image.new('P', im_size, 255)
im_width = im_size[0]
im_height = im_size[1]
for y in range(im_height):
for x in range(im_width):
pixel = im.getpixel((x, y))
if pixel ==0:
new_im.putpixel((x, y), pixel)
纵向切割出每个字母,切割规则为:依次纵向检索每个像素点,在横向(x轴)固定的前提下:若遇到像素值为0,则表示为黑色的字母;若整个纵向都没遇到黑色(0),则表示是分割点。我们可以得到一样图片的横向(x轴)的所有分割点的坐标,最后分割即可。如下图:
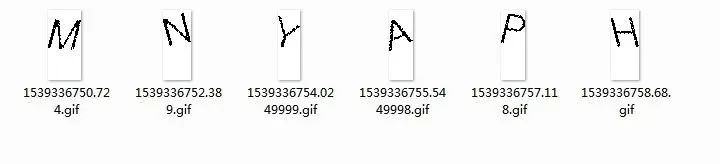
计算得到的切割坐标,如下:

def get_x_coord(image) -> '返回切割的x坐标':
image_width = image.size[0]
image_height = image.size[1]
crop_list = []
start_pos = 0
is_start_one_char = False
for x in range(image_width):
is_black_pos = False
for y in range(image_height):
pixel = image.getpixel((x,y))
if pixel == 0:
if is_start_one_char == False:
start_pos = x
is_black_pos = True
is_start_one_char = True
break
if is_start_one_char== True and is_black_pos == False:
end_pos = x
is_start_one_char = False
crop_list.append((start_pos, end_pos))
return crop_list
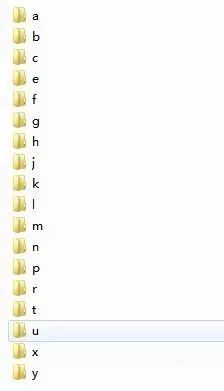
将分割出的每个字母图片加入到训练库中,方便后面训练匹配,训练库中的数量越多识别率越高。将每个字母分类放入不同的文件夹中,如下所示:
例如a文件夹中的图片如下:

拿到一张单个字母图片后,去训练库中匹配每个图片,计算出相似度最高的,记录出相应的字母文件夹即为最终的字母。
匹配算法:AI与向量空间算法,通俗点讲就是原图片的所有像素点与训练库中的每张图片的所有像素点计算余弦值,余弦值越大,相似度越高。
具体方法是:计算出原图片与训练库中的每张图片像素的余弦值,选出最大值对应的训练库中的文件夹名即为最终的字母。
如下为匹配的结果,与原图片完全吻合

match_captcha = []
for crop in crop_list:
crop_im = new_im.crop((crop[0], 0, crop[1], im_height))
filename = 'e:/crop/' + str(time.time()) + '.gif'
all_result = []
remove_letter = ['d', 'i', 'o', 'q', 's', 'v', 'w', 'z']
for letter in list(set(string.ascii_lowercase)- set(remove_letter)):
refer_image_dir = r'E:\training_library\%s' % letter
for refer_image in os.listdir(refer_image_dir):
refer_im = Image.open(os.path.join(refer_image_dir, refer_image))
crop_list = list(crop_im.getdata())
refer_list = list(refer_im.getdata())
min_count = min(len(crop_list), len(refer_list))
result = 1 - spatial.distance.cosine(crop_list[:min_count-1], refer_list[:min_count-1])
all_result.append({'letter' : letter, 'result' : result})
match_letter = max(all_result, key=lambda x: x['result']).get('letter')
match_captcha.append(match_letter)
print('验证码为:{0}'.format(''.join(match_captcha)))
经测试,每个字母图片的识别时间大约为1s左右,所以一张亚马逊验证码的识别时间大约为5-6s,这个时间是非常可以接受的。

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以公安部、工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。

▼ 点击下方阅读原文,免费成为社区会员







