
大家好!又到了每周一狗熊会的深度学习时间了。在上一讲中,小编给大家详细介绍了大名鼎鼎的 word2vec 词向量模型,对 word2vec 的两种模型形式:CBOW 模型和 skip-gram 模型的进行了解读。本节小编将继续给大家介绍词向量的相关内容。本节的重点在于如何根据原始文本训练一个词向量模型,以及如何根据给定的词向量模型做一些简单的自然语言分析。

通常而言,训练一个词向量是一件非常昂贵的事情,我们一般会使用一些别人训练好的词向量模型来直接使用,很少情况下需要自己训练词向量,但这并不妨碍我们尝试来训练一个 word2vec 词向量模型进行试验。
在上一讲中,我们学习了 word2vec 的两种模型,一种是根据语境预测目标词的 CBOW 模型,另一种则是根据目标词预测语境的 skip-gram 模型。本节笔者将尝试使用 TensorFlow 根据给定语料训练一个 skip-gram 词向量模型。学习参考资料为 Andrew Ng deeplearningai 第五门课 assignment2 以及黄文坚所著的 TensorFlow 实战一书。
先来回顾一下 skip-gram 词向量模型的网络结构:
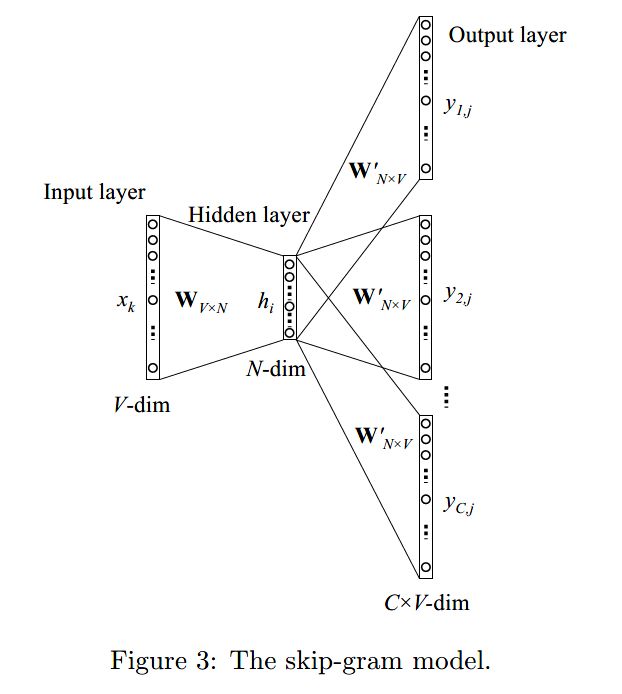
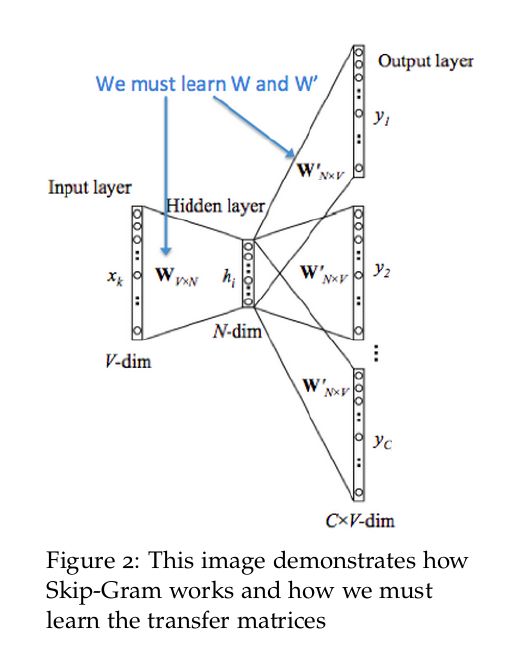
skip-gram 的模型细节小编在上一讲已经做了讲述,这里不再赘述,下面我们看如何训练一个 skip-gram 模型。总体流程是先下载要训练的文本语料,然后根据语料构造词汇表,再根据词汇表和 skip-gram 模型特点生成 skip-gram 训练样本。训练样本准备好之后即可定义 skip-gram 模型网络结构,损失函数和优化计算过程,最后保存训练好的词向量即可。我们来看完整过程。
这里先导入整个试验过程所需要的 python 库。
import collections
import math
import os
import random
import zipfile
import numpy as np
import urllib
import tensorflow as tf
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
准备语料
我们从 http://mattmahoney.net/dc/ 网站下载好目标语料 text8.zip,当然也可以通过 python 编写 urllib 爬虫函数进行下载。
语料下载代码如下:
url = 'http://mattmahoney.net/dc/'
def maybe_download(filename, expected_bytes):
if not
os.path.exists(filename):
filename, _ = urllib.request.urlretrieve(url + filename, filename)
statinfo = os.stat(filename)
if statinfo.st_size == expected_bytes:
print('Found and verified', filename)
else:
print(statinfo.st_size)
raise Exception('Failed to verify' + filename + '. Can you get to it with a browser?')
return filename
语料下载好后还是原始的文本,需要我们做一些进一步的处理。下面我们在读取压缩文件的同时调用 TensorFlow 的 compat.as_str 方法将语料转化为一个细分粒度以单词为单位的巨大列表:
def read_data(filename):
with zipfile.ZipFile(filename) as f:
data = tf.compat.as_str(f.read(f.namelist()[0])).split()
return data
words = read_data('text8.zip')
print('Data size', len(words))

可见整个语料被转化成了 17005207 个单词组成的巨大 list。这么大的单词数量我们肯定不能直接拿来做训练,需要进一步的对单词进行词频统计和转换。假设我们取词频 top 50000的单词作为词汇表,并将其放入 python 字典中,然后根据词汇表将列表中的每个单词根据频数排序给定一个编码,并取字典的反转形式(键值互换)。参考代码如下:
# 设定词汇表单词数量
vocabulary_size = 50000
def build_dataset(words):
count = [['UNK', -1]]
# 词汇频数统计
count.extend(collections.Counter(words).most_common(vocabulary_size-1))
dictionary = dict()
# 存入字典
for word, _ in count:
dictionary[word] = len(dictionary)
data = list()
unk_count = 0
# 遍历单词列表判断是否放入字典
for word in words:
if word in dictionary:
index = dictionary[word]
else:
index = 0
unk_count += 1
# 指定单词的频数编码
data.append(index)
count[0][1] = unk_count
# 反转字典
reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reverse_dictionary
data, count, dictionary, reverse_dictionary = build_dataset(words)
看一下词汇统计词频的前五个单词、字典中的前 10 个单词和对应的词频编码:

生成 skip-gram 训练样本
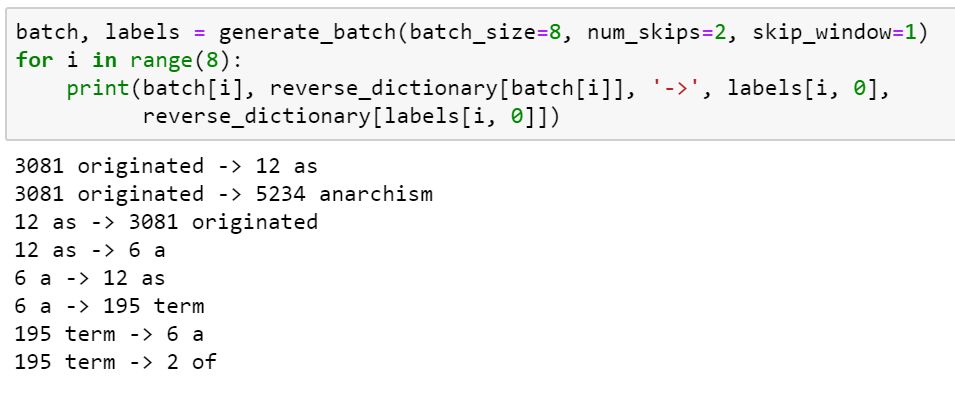
skip-gram 词向量模型是根据中间词来预测语境词,假设原始数据为 the quick brown fox jumped over the lazy dog. 现在我们需要将原始数据转化为 (quick,the)(quick,brown)(brown,quick)等词对的形式。然后我们需要定义几个关键变量:首先是生成每批训练数据的 batch_size,然后是每个单词向两边最远可以联系到距离,比如说 quick 只能和左右两个单词(quick,the)和(quick,brown) 进行联系,最后是每个单词能够生成的训练样本数量 skip_number。定义生成 skip-gram 生成样本函数如下:
# 生成训练样本,使用Skip-Gram模式
data_index = 0
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert
num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1
buffer = collections.deque(maxlen=span)
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
for i in range(batch_size // num_skips):
target = skip_window
targets_to_avoid = [skip_window]
for j in range(num_skips):
while target in targets_to_avoid:
target = random.randint(0, span - 1)
targets_to_avoid.append(target)
batch[i * num_skips + j] = buffer[skip_window]
labels[i * num_skips + j, 0] = buffer[target]
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
return batch, labels
生成训练样本示例如下所示:
搭建 skip-gram 模型训练过程
训练样本准备好后,便可以根据 skip-gram 模型结构进行模型搭建。同样先定义几个模型参数,第一个是训练批次 batch_size,这个我们之前在做图像处理的 CNN 模型训练的时候经常会碰到,我们训练批次为 128,然后的 embedding_size,这个是我们最后要生成词向量的维度,这里我们设置为 128,即我们要通过 skip-gram 算法将维度为 50000 的原始词汇表降维成 128 维的词向量。
然后是定义 skip-gram 模型结构。使用 tf.random_uniform 方法随机生成所有单词的词向量 embeddings,即初始化词嵌入矩阵,然后再使用 tf.nn.embedding_lookup 查找输入对应的 embed 向量。训练采用 NCE 损失函数作为优化目标,优化方法为 SGD,参考代码如下:
模型结构和初始化:
# 定义训练参数
batch_size = 128
embedding_size = 128
skip_window = 1
num_skips = 2
valid_size = 16
valid_window = 100
valid_examples = np.random.choice(valid_window, valid_size, replace=False)
num_sampled = 64
# 定义Skip-Gram Word2Vec模型的网络结构
graph = tf.Graph()
with graph.as_default():
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
with tf.device('/cpu:0'):
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
labels=train_labels,
inputs=embed,
num_sampled=num_sampled,
num_classes=vocabulary_size))
optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)
# 计算相似度
similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)
init = tf.global_variables_initializer()
执行训练:
# 定义最大迭代次数,创建并设置默认的session
num_steps = 100001
with tf.Session(graph=graph) as session:
init.run()
print("Initialized")
average_loss = 0
for step in range(num_steps):
batch_inputs, batch_labels = generate_batch(batch_size, num_skips, skip_window)
feed_dict = {train_inputs: batch_inputs, train_labels: batch_labels}
_, loss_val = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += loss_val
if step % 2000
== 0:
if step > 0:
average_loss /= 2000
print("Average loss at step ", step, ":", average_loss)
average_loss = 0
if step % 10000 == 0:
sim = similarity.eval()
for i in range(valid_size):
valid_word = reverse_dictionary[valid_examples[i]]
top_k = 8
nearest = (-sim[i, :]).argsort()[1: top_k + 1]
log_str = "Nearest to %s:" % valid_word
for k in range(top_k):
close_word = reverse_dictionary[nearest[k]]
log_str = "%s %s," % (log_str, close_word)
print(log_str)
final_embeddings = normalized_embeddings.eval()
训练过程如下图所示:

训练过程展示的 skip-gram 模型训练时的平均损失以及与验证集单词相似度最高的 8 个单词,可以看到与 may 语义相近的单词包括 can、would、will等词汇,可见由 skip-gram 模型训练得到的 word2vec 词向量表达质量是非常高的。
可视化展示和词向量保存
最后我们可以通过 t-SNE降维技术将 128 维的 skip-gram 词向量压缩到 2 维空间中进行展示,参考代码如下:
# 定义可视化Word2Vec效果的函数
def plot_with_labels(low_dim_embs, labels, filename='tsne.png'):
assert low_dim_embs.shape[0] >= len(labels), "More labels than embeddings"
plt.figure(figsize=(12, 12
))
for i, label in enumerate(labels):
x, y = low_dim_embs[i, :]
plt.scatter(x, y)
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.savefig(filename)
plt.show();
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_only = 100low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only, :])
labels = [reverse_dictionary[i] for i in range(plot_only)]
plot_with_labels(low_dim_embs, labels)
绘图效果如下:
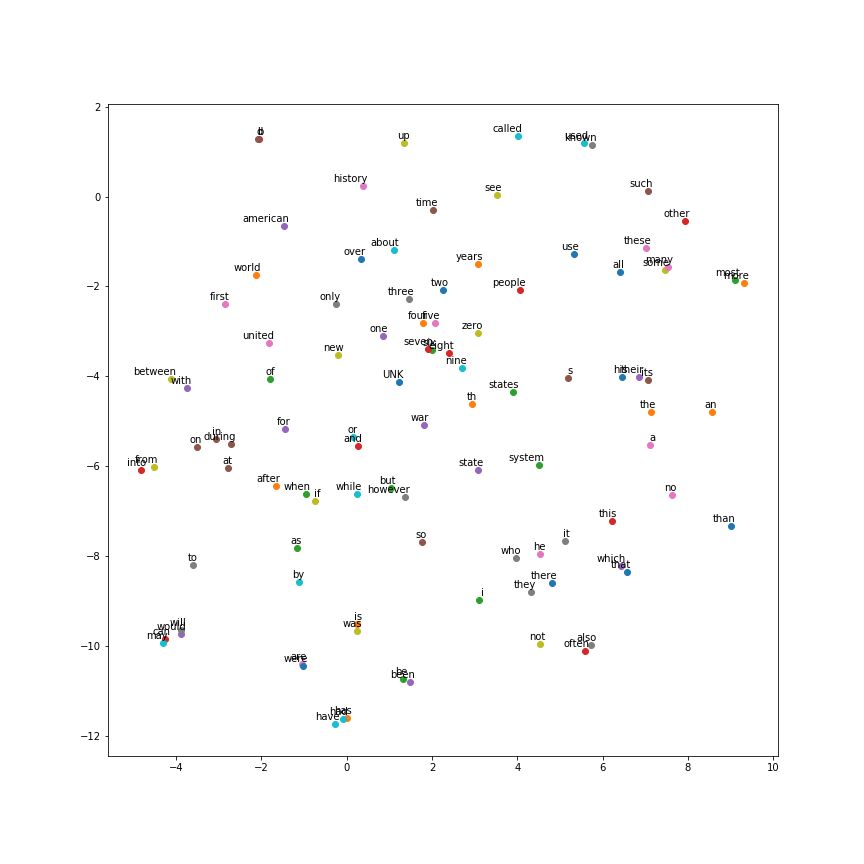
可以看到在 2 维的词向量空间上,语义相近的词都被聚集到了一起。词向量训练好之后我们可以将其保存下来写入 txt 中方便以后调用:
with open('skip-gram128.txt', 'a') as f:
for i in range(vocabulary_size):
f.write(labels[i] + str(list(final_embeddings[i])) + '\n')
f.close()
print('word vectors have written done.')
最后咱们的词向量如下:

虽然我们可以自己训练一个词向量,但在大规模语料的情况下,自己从头训练一个词向量并不是一个比较好的选择。所以,更多时候我们会选择一些别人训练好的词向量结果来用于我们的自然语言处理工作,这样的词向量也叫预训练的词向量模型。
小编基于 Andrew NG 在 deeplearningai 序列模型课程上给出的 Glove 词向量,示例如下:

导入相关的 package 并读入 Glove 词向量。Glove 词向量直译为全局的词向量表示,跟 word2vec 词向量一样本质上是基于词共现矩阵来进行处理的一种词向量模型,这里小编不详细展开,感兴趣的朋友可以参考文末的引用文献。
import numpy as np
from w2v_utils import *
words, word_to_vec_map = read_glove_vecs('data/glove.6B.50d.txt')
计算余弦相似度
为了衡量两个单词在语义上的相近性,我们采用余弦相似度来进行度量。余弦相似度的计算公式如下:
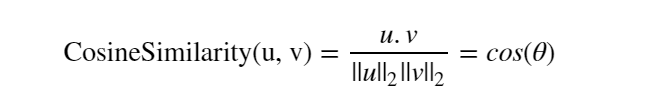
基于余弦相似度的词汇语义相似性度量:
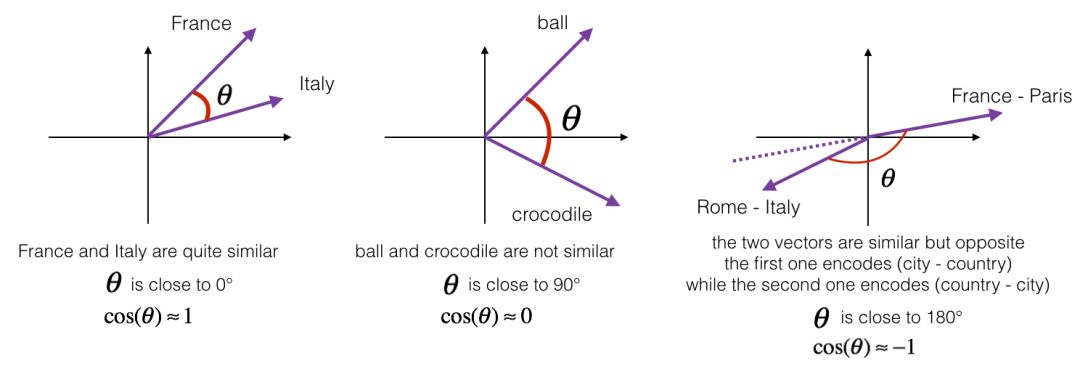
定义余弦相似度计算公式:
def cosine_similarity(u, v):
"""
Cosine similarity reflects the degree of similariy between u and v
Arguments:
u -- a word vector of shape (n,)
v -- a word vector of shape (n,)
"""
distance = 0.0
# Compute the dot product between u and v
dot = np.dot(u.T, v)
# Compute the L2 norm of u
norm_u = np.sqrt(np.sum(u**2))
# Compute the L2 norm of v
norm_v = np.sqrt(np.sum(v**2))
# Compute the cosine similarity defined by formula (1)
cosine_similarity = dot/(norm_u * norm_v)
return cosine_similarity计算示例如下:
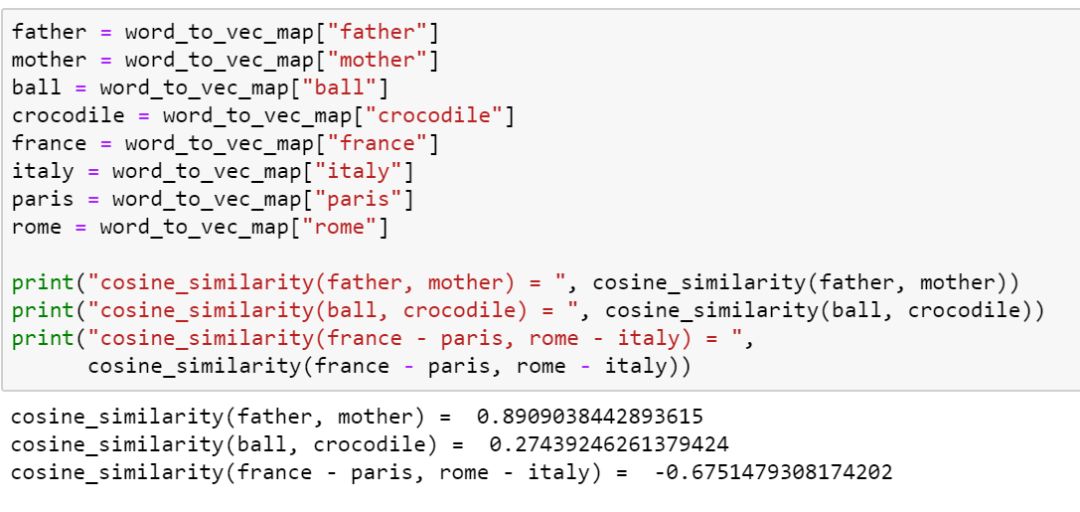
根据计算结果,我们可以看到,father 和 mother 之间有非常高的相似度,而 ball 和 crocodile 之间相似度较低。
语义类比
有了词汇之间的相似性度量之后,我们便可基于此做进一步分析,比如要解决 a is to b as c is to _ 这样的语义填空题。我们可以利用词汇之间的余弦相似性计算空格处到底填什么单词。
完整的函数定义如下:
def complete_analogy(word_a, word_b, word_c, word_to_vec_map):
"""
Performs the word analogy task as explained above: a is to b as c is to ____.
Arguments:
word_a -- a word, string
word_b -- a word, string
word_c -- a word, string
word_to_vec_map -- dictionary that maps words to their corresponding vectors.
Returns:
best_word -- the word such that v_b - v_a is close to v_best_word - v_c, as measured by cosine similarity
"""
# convert words to lower case
word_a, word_b, word_c = word_a.lower(), word_b.lower(), word_c.lower()
# Get the word embeddings v_a, v_b and v_c
e_a, e_b, e_c = word_to_vec_map[word_a], word_to_vec_map[word_b], word_to_vec_map[word_c]
words = word_to_vec_map.keys()
max_cosine_sim = -100
best_word = None
# loop over the whole word vector set
for w in words:
# to avoid best_word being one of the input words, pass on them.
if w in [word_a, word_b, word_c] :
continue
# Compute cosine similarity between the vector (e_b - e_a) and the vector ((w's vector representation) - e_c)
cosine_sim = cosine_similarity((e_b-e_a), (word_to_vec_map[w]-e_c))
# If the cosine_sim is more than the max_cosine_sim seen so far,
# then: set the new max_cosine_sim to the current cosine_sim and the best_word to the current word
if cosine_sim > max_cosine_sim:
max_cosine_sim = cosine_sim
best_word = w
return best_word
计算示例如下:
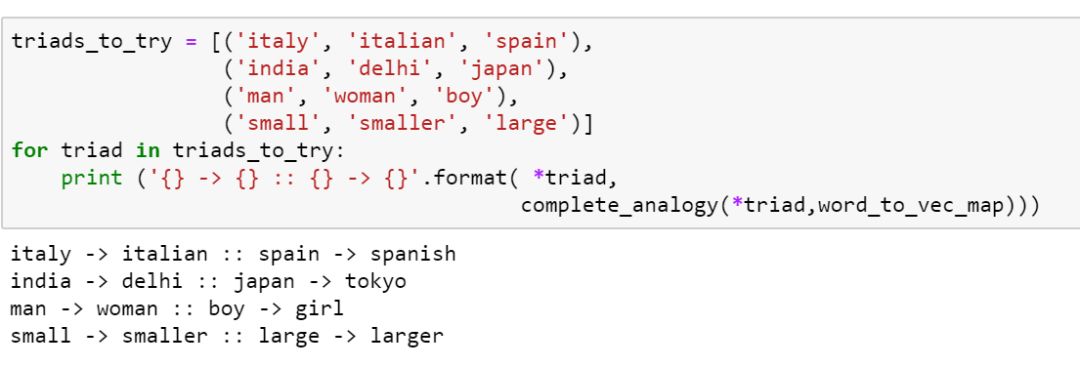
通过计算我们可以看到:
italy is to italian as spain is to spanish.
small is to smaller as large is to larger.
基本上能较好的契合语义。
以上便是本讲内容。
在本节内容中,小编和大家重点介绍了如何使用 Python 从头开始训练一个 word2vec 词向量并进行展示,以及如何使用预训练的词向量模型来直接进行一些简单的 NLP 分析。咱们下一期见!
【参考资料】
deeplearningai.com
黄文坚 TensorFlow实战
https://cndocr.github.io/text2vec-doc-cn/glove.html
https://nlp.stanford.edu/pubs/glove.pdf
鲁伟,狗熊会人才计划一期学员。目前在杭州某软件公司从事数据分析和深度学习相关的研究工作,研究方向为贝叶斯统计、计算机视觉和迁移学习。

识别二维码,查看作者更多精彩文章
识别下方二维码成为狗熊会会员!
友情提示:
个人会员不提供数据、代码,
视频only!
个人会员网址:http://teach.xiong99.com.cn










