
我最近在Kattis上研究了很多非常棘手的编程问题。Kattis是我最喜欢的在线编程裁判系统,并且我一直非常享受在爱尔兰记分牌上排名攀升的感觉,现在是时候去重新赢回第一名的荣耀了。
今天我特别要讲的是Pivot问题。这是一个相当小的、简单的、独立的问题,但是在尝试优化我的答案的过程中,我学到了一些有趣的东西。
以下是这个问题陈述的要点:
一个复杂度为O(n)的分区算法计划把一个数组A围绕一个基准元素(基准也是A的一个成员)分成三个部分:一个左子列,其中包含所有小于等于基准的元素,基准本身,和一个右子列,包含所有大于基准的元素。
现在这个问题的实际工作是这样的:从一个有n个不同整数的数组A开始,我们用A中的一个元素作为基准对A进行分区,从而生成一个变换后的数组A "。给定这个变换后的数组A ",你的工作是计算有多少个整数可以是被选中的基准。
简单地说,我们得到一个分区的输出,并且必须计算列表中可能用作基准的值的数量。
我们被告知,元素的数量n的范围是3≤n≤100000。我们还知道所有输入的数字都是32位有符号整数(但是在Python中,这并没有太大的区别)。
现在,让我们进入解决这个问题的无底洞,然后尝试着再进一步。
朴素的解决方案
我不是说这是你的错/尽管你本可以做得更多
在分解问题的时候,我们可以看到我们是在试图找到输入列表中的每一个数字 (我将称之为D),条件是当ji时,小于所有D[k]。这个想法的实现如下。
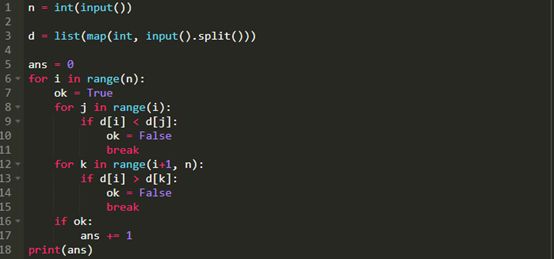
这个解决方案的时间复杂度O (n ^ 2),而且超过了Kattis第四个测试用例的1秒时间限制。简单地说就是还不够快。
这是因为,对于(多达)100万个输入数字中的每一个,我们要迭代(在最坏的情况下)每一个数字。这是需要很长时间的。
你可以做一些小的优化,比如跳过循环k(如果ok已经为假),但是我怀疑这些优化能否在限制时间内完成。然而如果实在没有其他的想法的话,这些优化还是值得的,毕竟你还在编程比赛中,并且极度渴望得到一些额外的分数。
完美的 O (n)
当我明白- 10 ^ 12的比较问题是不可能在一秒内完成,我就知道O (n ^ 2)是不够的。我立刻意识到这个问题可以在O(n)时间内解决。
你不需要把每个数和它之前的每个数进行比较,看它是否大于或等于每一个数。你只需要将该数字与它之前的最大数字进行比较。同样地,你也只需要将数字与它之后的最小数字进行比较。
你可以在O(n)时间内构建一个列表,我在下文将其称为左列,含义是“元素左边的最大数字”。
你可以类似的方式构建“该元素右边的最小数字”的等效列表右列。
阅读代码可能比我在这里东拉西扯更容易理解。这是我提交的首个解决方案。
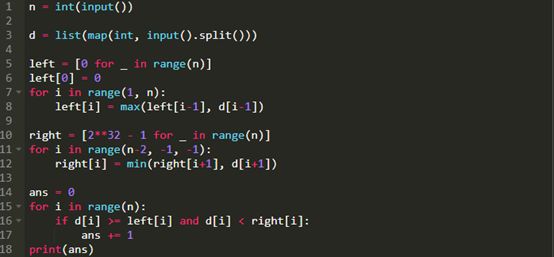
Kattis告诉我这个运行了0.16秒,远远低于时间限制,可以得到这个问题的满分。工作完成!
Kattis有一个很好的特性,它可以按语言分类地显示每个问题的前10个最快解决方案的计分板。我经常在解决一个问题后去看看这个表格,看看我的解决方案排名如何。
当我扫了一眼这个问题的记分牌时,我的心被射伤了。Python 3提交的最快时间仅仅是0.06秒,并且它是由我的同学/劲敌/竞争对手Cian Ruane提交的。这太可怕了!我无法忍受他比我快十分之一秒;想象一下如果他看到这些,他会有多么得意!我必须要做得更好。
加速# 1
嫉妒也是促人进步的动力。
很快(实际上,我在1分18秒之后提交了新的解决方案),我意识到我做了两倍于我需要做的工作。我不需要构建左边的列表,只需要在最后迭代列表以计算结果时,对目前为止看到的最大数字保持一个运行计数即可。这将使解决方案节约大约一半的空间,节省整个数组的迭代,并肯定会提高我的速度。
也许这就是Cian成绩更好的原因?以下是我提交的新方案。
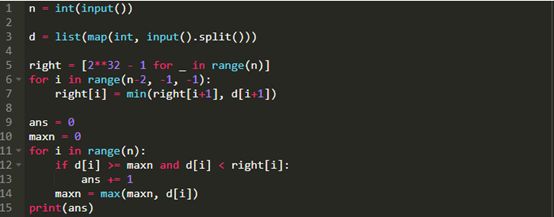
它跑了0.14秒。甚至还没有快到能在积分榜上排到第10名,更别提第一名了。
从以往的经验来看,我发现最简单的Python问题只需要0.02秒。我假设这是启动Python解释器、解析程序等的时间成本。一旦问题想要在小于0.05秒左右的时间内运行,可能就没有多少空间可以提高速度了。然而,我们还远没有达到这个极限。此外,我可以看到其他人在0.06秒内完成了它,而计分板的其余排名都在0.07秒- 0.09秒,所以它一定是可行的!
过了4分钟,快了0.04秒
2分45秒后,我提交了以下文件:
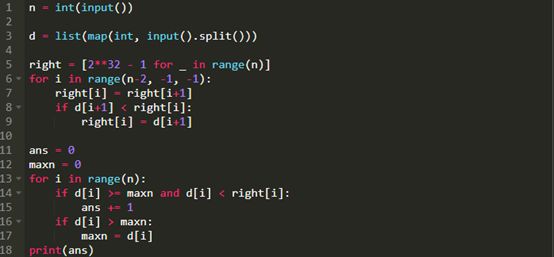
我在很多地方看到人们避免使用Python内置的max和min,而在研究这个问题时,我没有看到任何其他明显的潜在加速的可行性。对我来说,这些可能比简单的if语句还要慢;不仅每次调用函数都有开销,而且这些函数还支持从迭代器中获取最大值或最小值,因此必须有一些逻辑来确定这些函数是否有需要避免被使用。
这个解决方案花费了0.12秒。
Cian的解决方案只花了一半的时间。我的好奇心被激起来了;他是怎么做到的?我试图通过阅读他的解决方案来找出答案——这可以教会我很多东西。
偷窥
我到github上看了看他的Kattis解决方案:

他的解决办法是……和我的差不多一样。他列出的清单和我的顺序正好相反,但这应该没什么区别吧?
在他所写的最后的循环中,少了一步比较——也许就是因为这样? 他在一个列表而不是一个映射中构建他的输入值列表——这可能会更理想一些? 也许我在他的迭代命令中遗漏了一些东西,而正是这些东西秘密的进行了智能加速?
我窃取了他的一些想法,并提交了以下内容。

这次花费了 0.09s.
WTF
承认失败后,我给Cian发了个短信。
Noah: @Cian Ruane,关于Pivot问题,我的解决方案和你的差不多,但是你的快了0.03秒
Cian:真是难以置信
…
Noah: if __name__ == "__main__"这行代码是不是有神奇的加速效果
Noah:是不是碰巧服务器加载的很快
…
Cian:试着把它变成一个函数
Noan:那肯定会更慢
Cian:也许它会产生意想不到的效果呢
好吧,为什么不试试呢?我提交了以下内容。

这次解决方案运行花费了0.06秒。
WTF 2:机械舞
为什么将代码放入函数中会加快速度?跳转到函数的开销肯定会使代码变慢,而不是变快吗?Cian说的对吗,还是说JIT里有一些其他东西?
并不是-但Stack Overflow有答案:
Scharron:只是一种直觉,不确定是否正确:我猜是因为作用域。在这种情况下,函数将创建一个新的作用域(即一种将变量名绑定到其值的散列)。如果没有函数,变量是在全局范围内的,当你需要寻找很多东西时,因此会减慢循环
katrielalex:@Scharron,你说对了一半。它是关于作用域的,在局部变量中更快的原因是,局部范围实际上是作为数组而不是字典实现的(因为在编译时知道它们的大小)。
然后,katriealex详细介绍了关于变量作用域的更有趣的细节。
ecatmur还查看了字节码,并展示它如何在解释器中显示出来。
超级有趣。
事后剖析
在说了这么多以后,我从中学到了什么?
1.将我的脚本放在函数中而不是全局范围中,没有什么大的缺点,但是有一个潜在的优点。
就像我在这里看到的,它更快。我想,当脚本中的变量访问更少时,这种加速就不那么明显了。
这里的一些答案提到了代码不运行在模块导入上的好处。
(在我看来)它创造了更干净的代码。我只是太懒了,不愿意放弃之前的有竞争力的编程解决方案。
2.如果我只比较两个值,并且担心性能,我应该考虑使用if而不是max和min。
3.我应该从katriealex链接的页面了解python性能技巧。那里有一些关于Python内部的详细信息。
4.我应该站在Cian一边,这样他就能继续留在我的队伍里,而不是跑去跟我竞争的队伍里。也就是说,我在以前的一些比赛中做得比他好,而且我将永远让他牢记这一点。
英文原文:http://mycode.doesnot.run/2018/04/11/pivot/
译者:任宇は神様










