H2O是一个基于Java完全开源的分布式内存机器学习平台,具有线性可扩展性。H2O支持最广泛使用的统计和机器学习算法,包括梯度提升、广义线性模型、深度学习等。H2O还具有行业领先的AutoML功能,可自动运行所有算法及优化参数,以生成最佳模型的排行。H2O平台已被全球14,000多家组织使用,并且在R&Python社区中非常受欢迎。
领先的算法:针对分布式计算开发的算法,包括随机森林、广义线性模型、梯度提升、XGBoost、GLRM、Word2Vec等监督和非监督算法。
丰富的API接口:可使用市面上广泛的编程语言(如R、Python等)在H2O中构建模型;同时,H2O Flow也提供基于图形化的交互式用户界面,不需要任何编码。
AutoML:自动化机器学习流程,其中包括在用户指定的时间内自动训练和调整各种模型。其中,集成算法能自动训练各个模型并加以集合,以生成高度预测的集合模型,在大多数情况下,集成模型在AutoML产出的算法排行榜中表现最佳。
分布式内存处理:运用节点和集群之间快速序列化的内存处理可支持海量数据集。 通过细粒度并行计算,大数据的分布式处理可提升处理速度高达100倍,实现最佳效率而不降低计算精度。
简单部署:支持训练模型导出成POJO和MOJO(Model-Optimized Java Objects),从而支持在任何环境中快速部署并对新数据提供快速预测评分。
支持多种数据源和数据格式:除了可对Microsoft Excel、R Studio、Tableau等来源的大数据提供了便捷的数据建模和分析方式,也支持HDFS、S3、传统SQL数据库及多种NoSQL数据库的数据源。
GartnerMagic Quadrant在2018发布的对数据科学和机器学习平台的评测中,也给了H2O极具竞争力的评价:
3. 以分布式H2O Frame格式从HDFS返回数据
2. 启动H2O
library(h2o)
h2o.init(nthreads = -1) #使用全部核
3. 读取、处理数据并拆分数据集:
dfpath = "http://s3.amazonaws.com/h2o-public-test-data/smalldata/gbm_test/titanic.csv") #读取数据框并转化为H2O.ai可识别的数据格式
dim(df)
response "survived"
df[[response]] [[response]])
## 是否生存作为响应变量
predictors "name"))
## 除名字以外其他变量作为预测变量
splits data = df,
ratios = c(0.6,0.2), ## 设定训练集、验证集、测试集比例
destination_frames = c("train.hex", "valid.hex", "test.hex"), seed = 1234
)
train [[1]]
valid [[2]]
test [[3]] ##拆分数据集
summary(train)##数据概况
*/ h2o.randomForest(x = x, y = y, training_frame, ntrees, nfolds, fold_assignment,keep_cross_validation_predictions,seed)*/
df.rf<-h2o.randomForest(x=predictors,y=response,training_frame = train, ntrees
= 500)
深度学习假设神经网络是多层的,首先用非监督学习网络的结构,然后再通过监督学习学习网络的权值
/*h2o.deeplearning(x, y, training_frame, model_id,nfolds,
fold_column ,ignore_const_cols, score_each_iteration, weights_column ,seed) */
df.dl
结果中AUC和混淆矩阵结果相对于随机森林都有了提升
*/h2o.gbm(x,y,training_frame,model_id,ntrees,distribution,max_depth,stopping_metric,balance_classes,learn_rate)*/
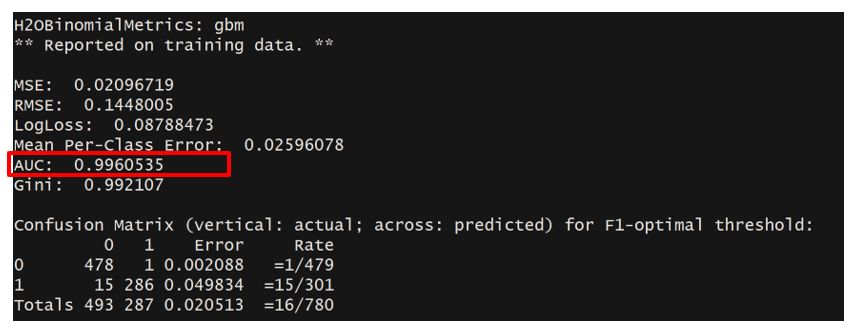
df.gbm
GBM结果AUC高达.996,混淆矩阵中错误率也降低到了.02
除了以上算法,H2O中的AUTOML可实现自动化机器学习,在限定的时间自动训练和调整模型,集合优化各种算法生成最优解。
调用公式:
aml = H2OAutoML(max_runtime_secs = 360)
aml.train(x = predictors, y = response,
training_frame = train,
leaderboard_frame = test)
表现最好的集合模型结果比起GBM又有了很大的提升,混淆矩阵错误率降低到了.006。从产生的模型排行榜上看,集合模型和GBM类算法表现最好,也符合我们以上测评的几种算法结果。

上述只是列举了H2O一些基本操作,关于H2O更为详细的资料列举如下:






