In [1]: pd.array([1, 2, np.nan], dtype='Int64')
Out[2]:
[1, 2, NaN]
Length: 3, dtype: Int64
In [2]: pd.array(['a', 'b', 'c'], dtype='category')
Out[2]:
[a, b, c]
Categories (3, object): [a, b, c]
2、用于提取Series或Index数组的新方法
在老的pandas版本里,我们可以通过.values来提取Series或者DataFrame的数据数组,而从0.24版本开始,Pandas提供了两个新的方法.array或.to_numpy()。
In [3]: idx = pd.period_range('2000', periods=4)
In [4]: idx.array
Out[4]:
['2000-01-01', '2000-01-02', '2000-01-03', '2000-01-04']
Length: 4, dtype: period[D]
In [5]: pd.Series(idx).array
Out[5]:
['2000-01-01', '2000-01-02', '2000-01-03', '2000-01-04']
Length: 4, dtype: period[D]
老的方法每次返回的都是ndarray类型,而如果数据是Pandas自定义的数据类型就无法实现。所以在新版里,如果你想获取NumPy的ndarry,可以使用新办法:Series.to_numpy() or Index.to_numpy()来实现。
In [7]: idx.to_numpy()
Out[7]:
array([Period('2000-01-01', 'D'), Period('2000-01-02', 'D'),
Period('2000-01-03', 'D'), Period('2000-01-04', 'D')], dtype=object)
In [8]: pd.Series(idx).to_numpy()
Out[8]:
array([Period('2000-01-01', 'D'), Period('2000-01-02', 'D'),
Period('2000-01-03', 'D'), Period('2000-01-04'
, 'D')], dtype=object)
Pandas新版依然保留了.values的方法,但官方强烈建议用.array或.to_numpy()来替代.values。
3、read_html()功能改进
在之前的版本,如果是一个正常的html table,pandas的read_html方法可以快速的将表格数据读取为一个DataFrame。但是,如果html table带有colspan和rowspan属性的合并字段情况下,pandas会读取错误。
比如,我们这里有一个表格:
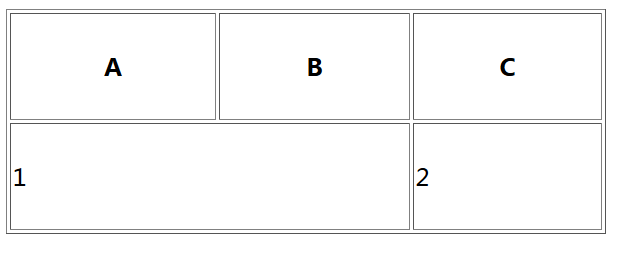
html代码是:
In [8]: result = pd.read_html("""
....:
....:
....:
....: A | B | C |
....:
|---|
....:
....:
....:
....: 1 | 2 |
....:
....:
....:
""")
....:
老版本read_html读取到的数据格式为:
In [9]: result
Out [9]:
[ A B C
0 1 2 NaN]
而新版pandas读取到的结果是:
In [10]: result
Out[10]:
[ A B C
0 1 1 2
[1 rows x 3 columns]]
可以看出,实际上旧版读取出来的数据是错误,而0.24版本进行了改进。
除了增加了新接口,在一些功能方面也做了一些调整,我只拿最重要的变化来举例,希望各位Pandas的重度用户注意一下这些变化。
1、时间周期对象的加减操作
对于时间类型的加减操作,在以前的版本,返回的是整形结果,比如说两个日期相减:
2、DataFrame广播运算的变化
对于DF的广播运算操作主要的变化有:
1)对于具有1行或1列的2维的DF运算操作,将以相同的ndarray方式进行广播。
2)DataFrame进行一个列表或元组运算,进行逐列操作,而不是行数全匹配。
来看一个实例:
In [87]: arr = np.arange(6).reshape(3, 2)
In [88]: df = pd.DataFrame(arr)
In [89]: df
Out[89]:
0 1
0
0 1
1 2 3
2 4 5
[3 rows x 2 columns]
以前的方式,如果不匹配,会抛出ValueError
In [5]: df == arr[[0], :]
...:
Out[5]:
0 1
0 True True
1 False False
2 False False
In [6]: df + arr[[0], :]
...
ValueError: Unable to coerce to DataFrame, shape must be (3, 2): given (1, 2)
In [7]: df == (1, 2)
...:
...:
...
ValueError: Invalid broadcasting comparison [(1, 2)] with block values
In [8]: df + (1, 2)
Out[8
]:
0 1
0 1 3
1 3 5
2 5 7
In [9]: df == (1, 2, 3)
...:
...:
Out[9]:
0 1
0 False True
1 True False
2 False False
In [10]: df + (1, 2, 3)
...
ValueError: Unable to coerce to Series, length must be 2: given 3
在新版里,是这样的效果:







