
目录
前言
很早之前发过一篇关于某拼车平台爬虫的文章,因为工作比较忙,一直没有下文。最近年底稍微空了些,加上碰上春节返乡大潮,刚好再拿过来写一下数据分析的思路。
本次数据样本共13041条,本别采集了北京、上海、广州、深圳、杭州的某一天出行数据,由于手动操作难以保证取样的公平性,所以不能对全部数据结果的准确性做保证,本文以提供思路参考为主,先放一张路线图:
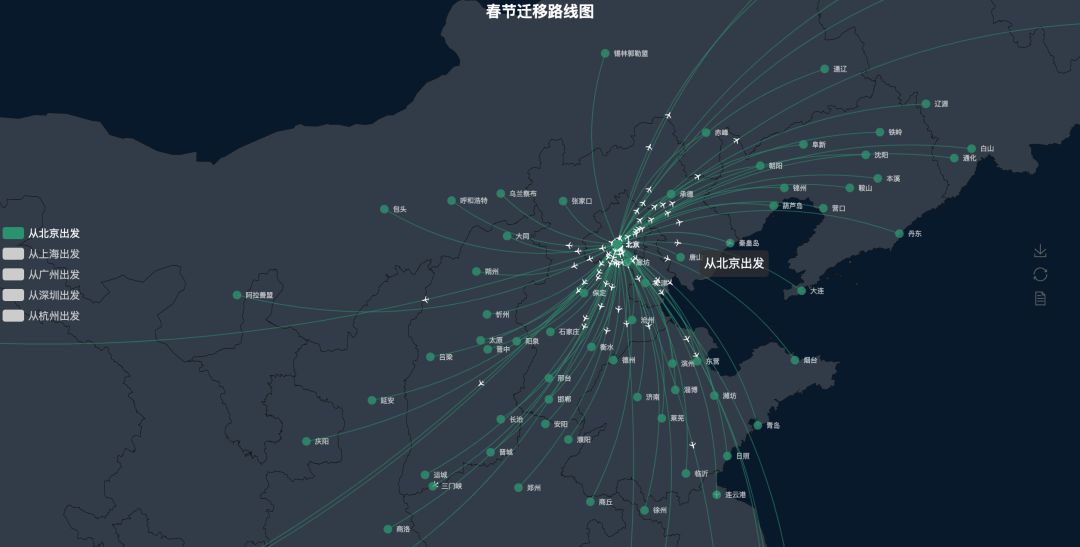
统计结果
好了知道大家比较关心结果,所以先把结果放一放,后面再接着讲分析过程。
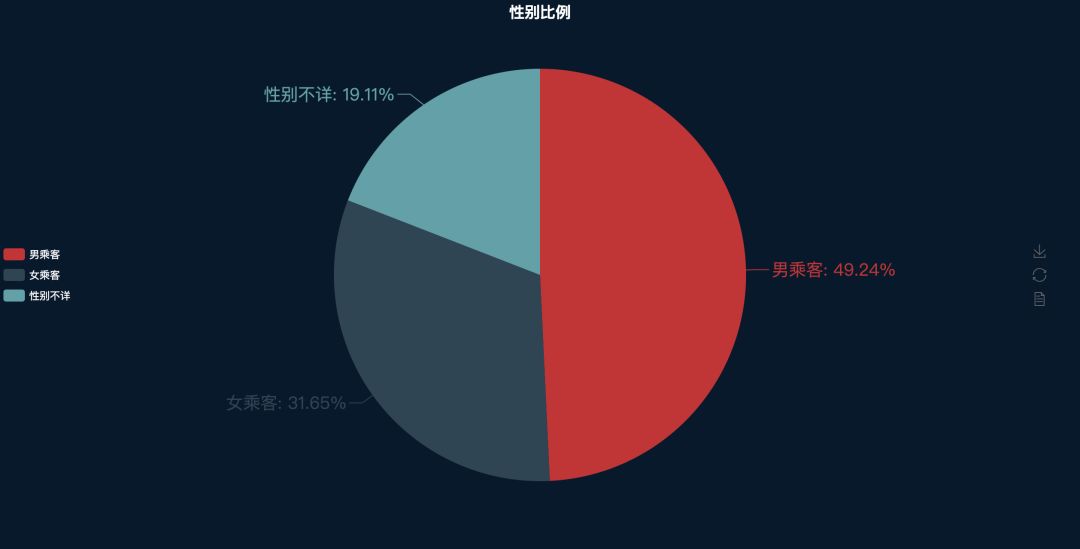
乘客性别
先单独把性别拎出来看一下,后面再根据城市进行分析,结果显示,抛开未设置性别的乘客不论,总体来看顺风车的用户群中,男性(占比49.39%)还是多于女性(占比31.55%)的。毕竟跨城顺风车,大过年的,女性乘客对于安全性的忧虑还有要有的。
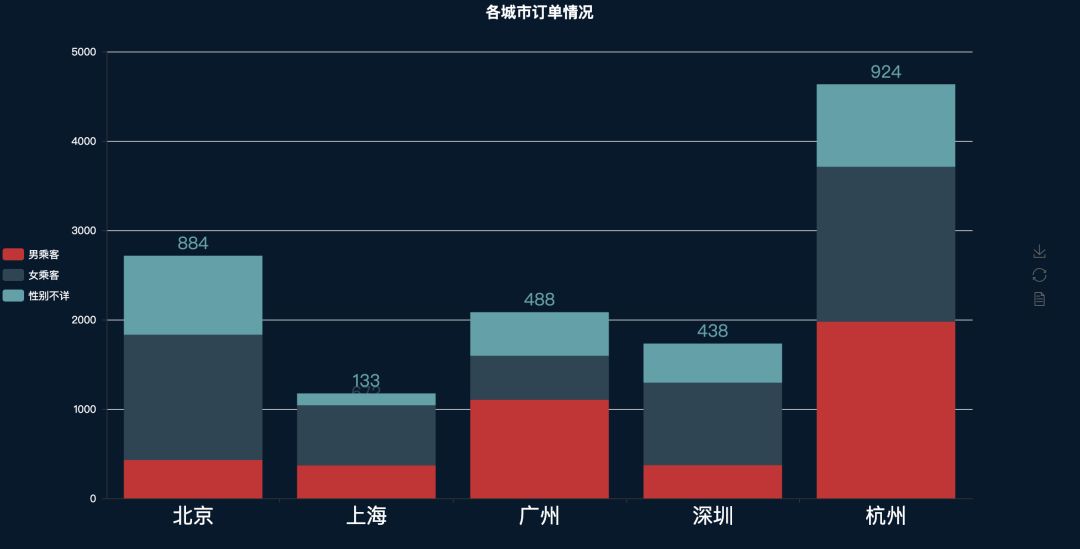
城市订单
真实数据的话订单数量应该是深圳 > 北京 > 广州 > 上海 > 杭州,但是同一个城市内的乘客性别比例应该还是具有一定的参考价值的,可以看到北京、上海、深圳的女性乘客数量占比都是高于男性的。
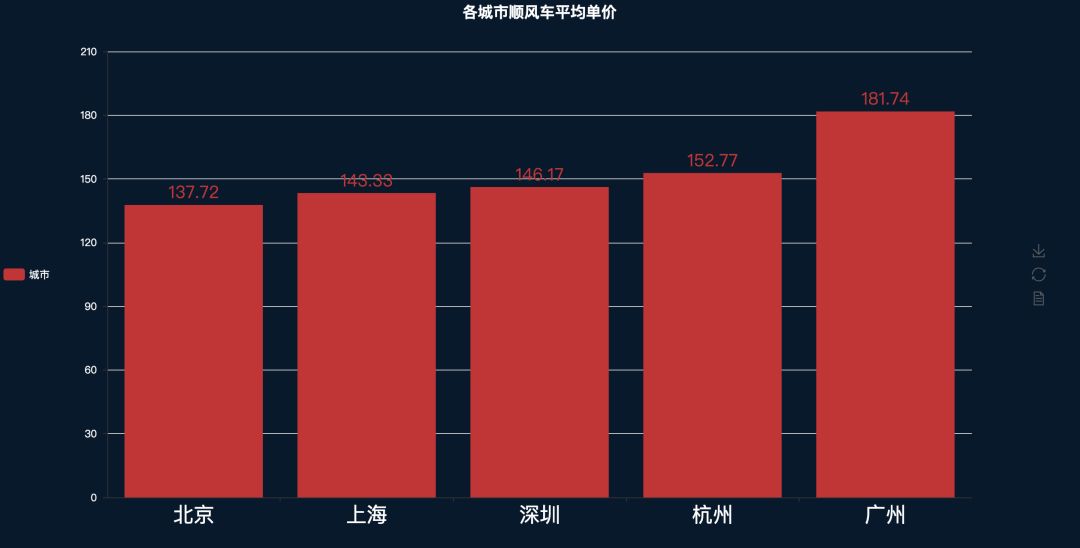
客单价
原本是想比较一下平均路程长度,但是想想这个事情太折腾了,由于平台主要还是依靠路程来计算拼车费用的,所以通过计算客单价的话大概也能反映一下平均形成长度(我猜的,然后结果是这样的,没想到广州是最高的,也可能是我统计错误
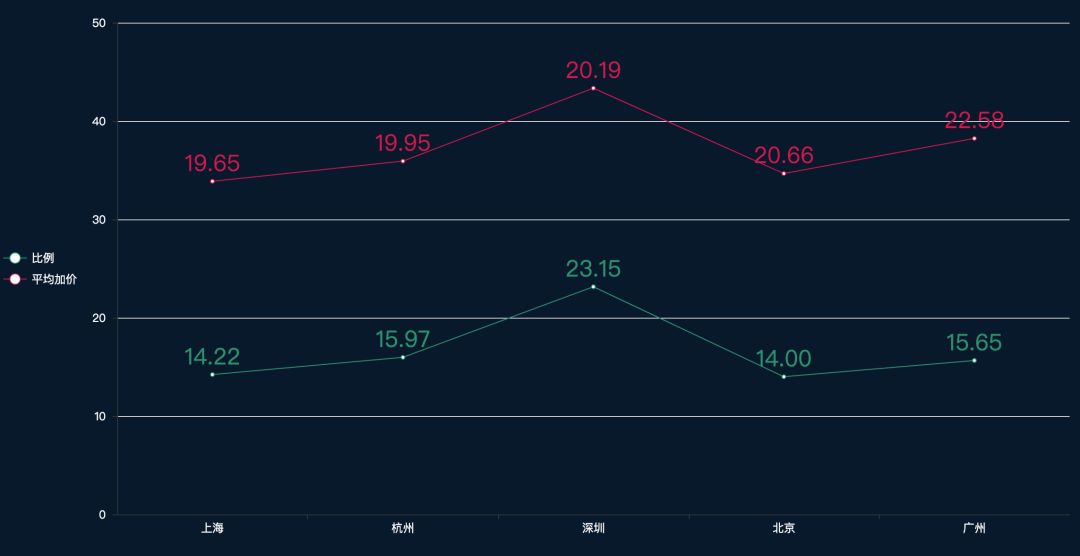
哪里乘客最壕
有时候有些偏远地区订单或者顺路司机少,乘客会加价希望司机接单,于是统计了一下各城市加价订单的占比和平均的加价额度,得出如下结果:
占比最高的城市是深圳,平均加价额度最高的城市也是深圳,看来深圳的小哥哥小姐姐们的确出手阔错,然而加价比例最低的是北京,不过这也不能说明帝都人民不壕气,可能就是人家繁华,司机多。
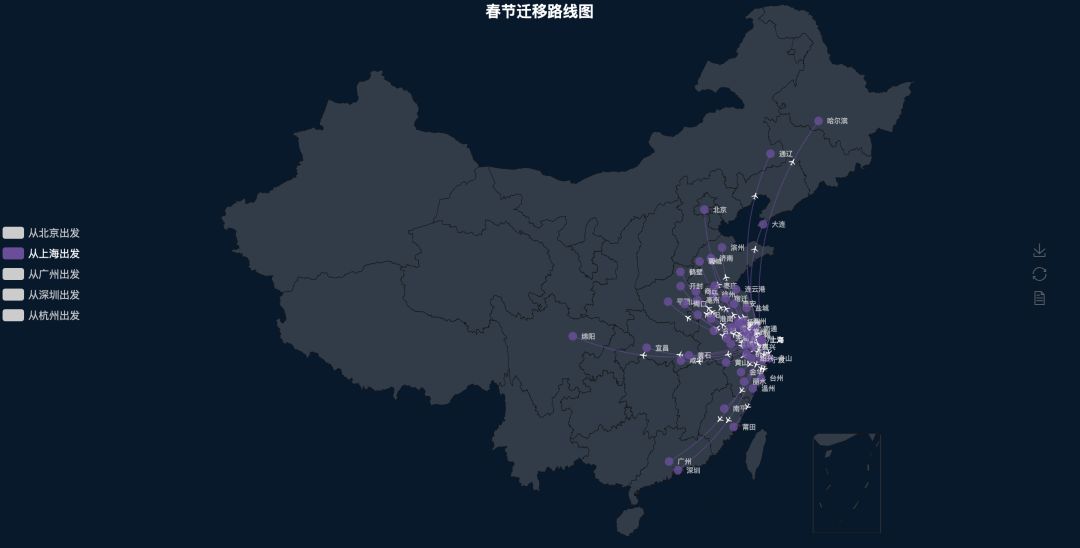
返乡路线图
最后放几张返乡的路线图
北京
上海
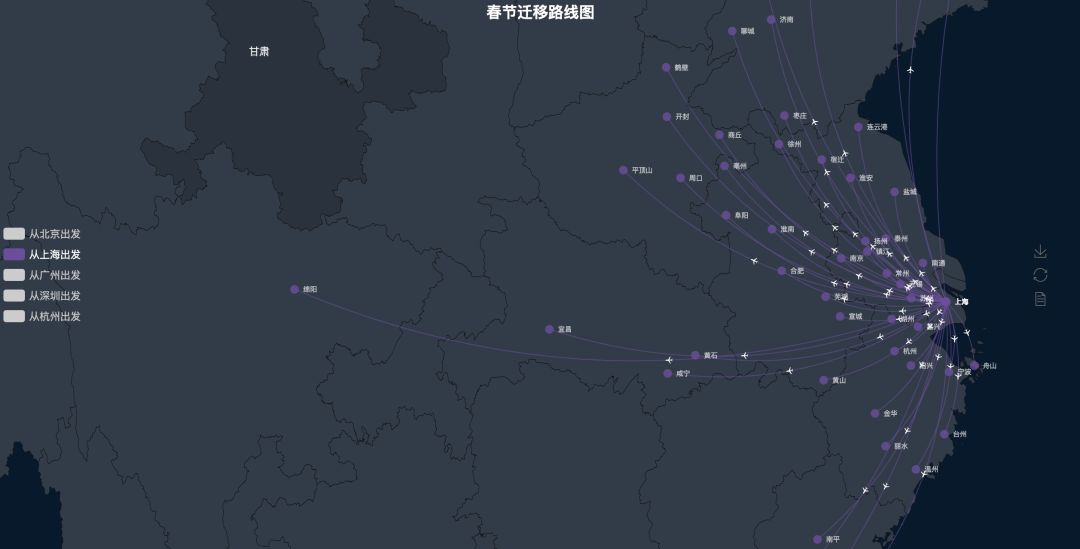
广州
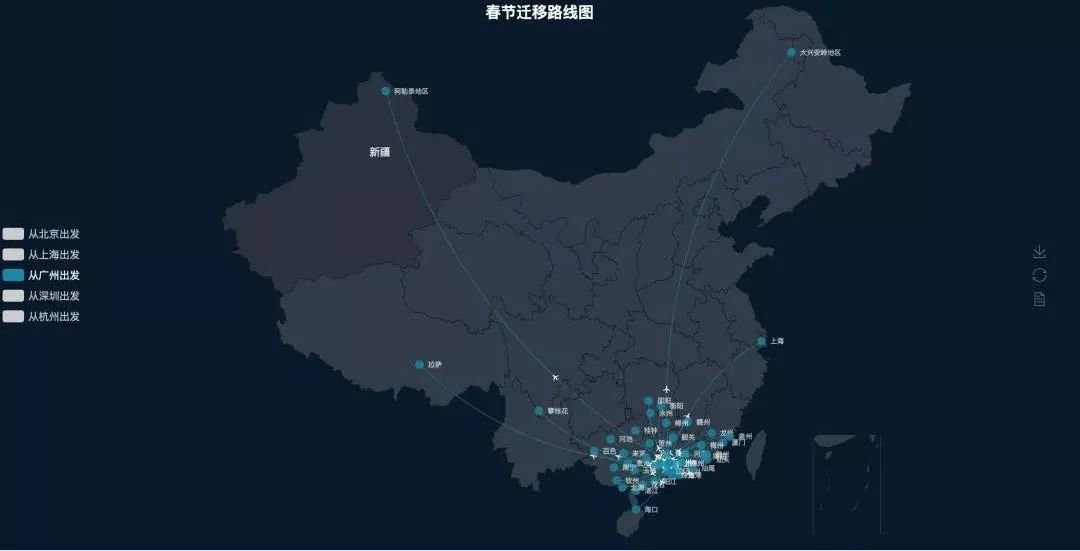
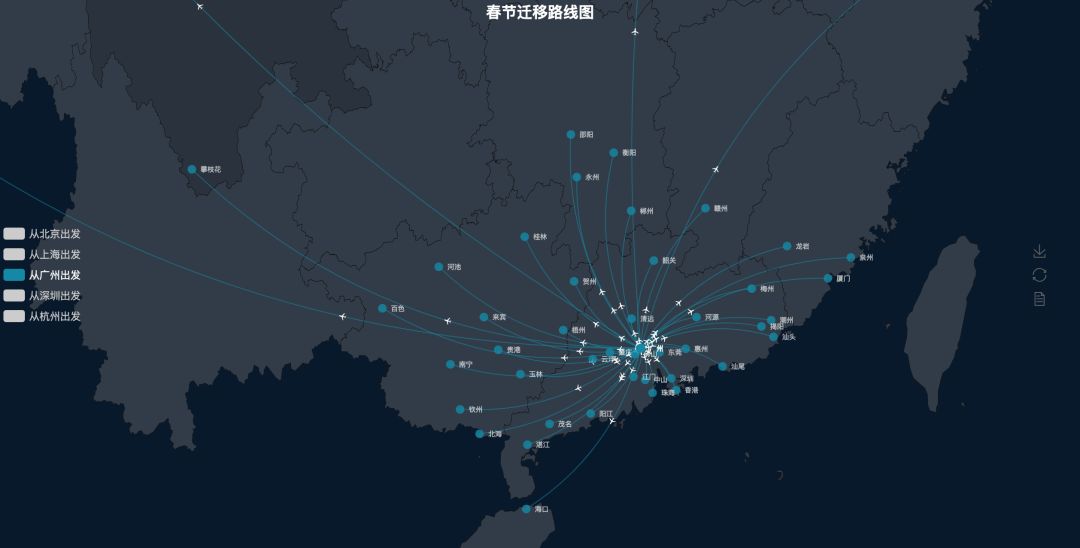
深圳
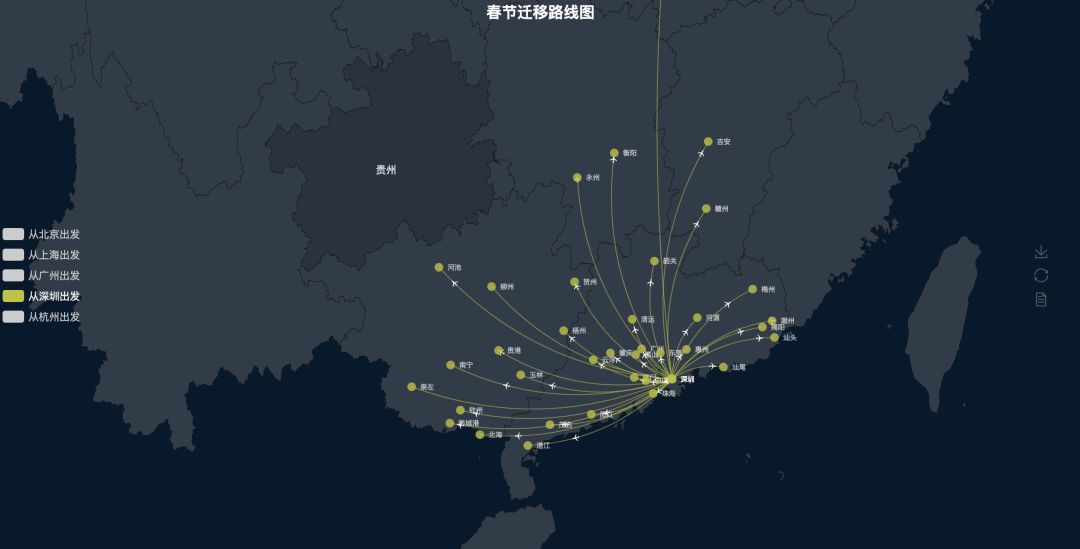
杭州
杭州明显有别与其它几个城市,一个是杭州的数据样本多,另外一个平台上杭州黄牛多,那些最远的单子就是黄牛广告单
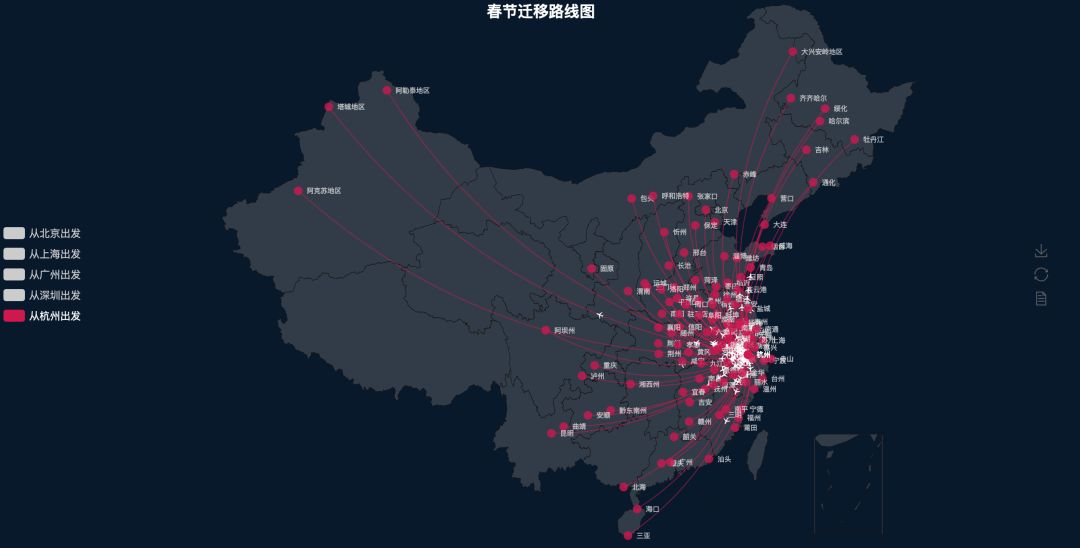
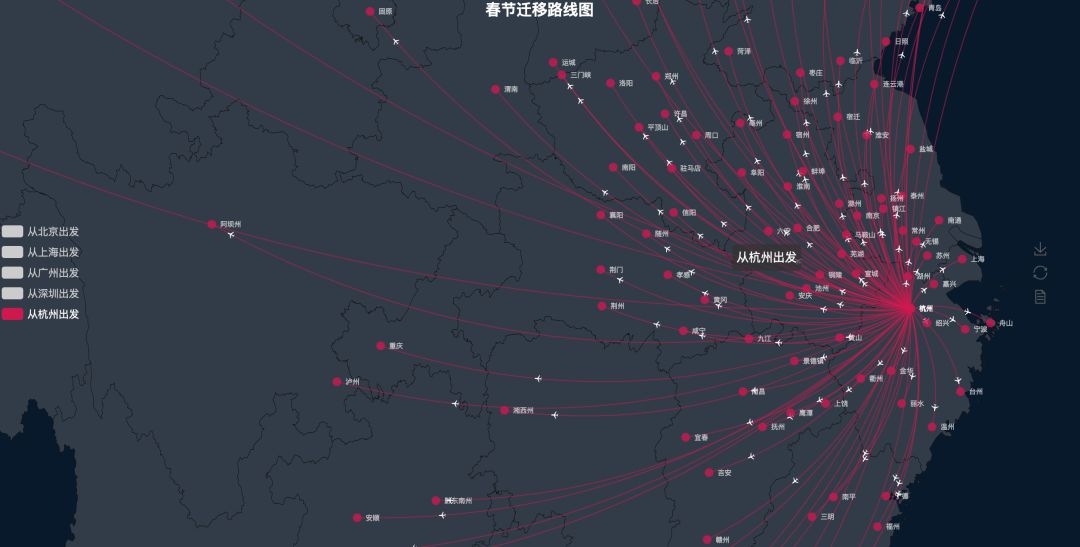
爬虫思路
注册成为司机,利用mitm抓包存储拼车单
统计思路
数据的话我是通过本地Mongodb存储,所以直接用python操作Mongodb数据
Pymongo
关于Mongodb数据库的连接,直接上代码:
client = MongoClient('mongodb://localhost:27017')
spring = client.spring
collection = spring['orders']
以上代码的意思就是连接本地Mongodb-spring数据库-orders文档集合
Pyecharts
Pyecharts(http://pyecharts.org)是大名鼎鼎的Echarts的Python可视化图表库,用起来挺顺手的,而且文档规范,基本上可以零门槛入门,具体实现请移步文档。
这里介绍一下关于Pyecharts的图表样式配置,为了保持各图表的样式统一(偷懒),Pyecharts提供了一个Style类,可用于在同一个图或者多个图内保持统一的风格
from pyecharts import Style,Geo
style = Style(
title_color="#fff",
title_pos="center",
width=1100,
height=600,
background_color='#404a59'
)
geo = Geo("全国主要城市空气质量", "data from pm2.5", **style.init_style)
这样,就创建了一个Geo地理坐标系图表
代码解读
因为全部代码有点长,所以抽了一段举个例子,主要思路就是从Mongodb取出指定数据,或者通过$group管道对数据进行处理,最后通过pyecharts生成相应的图表,呈现
from pymongo import MongoClient
from pyecharts import Style,GeoLines
def getLines(self):
client = MongoClient('mongodb://localhost:27017')
spring = self.client.spring
collection = self.spring['orders']
line_hangzhou = collection.aggregate([
{'$match': {'from_poi.city.city_name': '杭州'}},
{'$group': {'_id'
: '$to_poi.city.city_name', 'count': {'$sum': 1}}}
])
line_hangzhou_ = []
for line in line_hangzhou:
line_hangzhou_.append(["杭州", line['_id'], line['count']])
citylines = GeoLines("春节迁移路线图", **style.init_style)
citylines.add("从杭州出发",
line_hangzhou_,
**geo_style)
citylines.render("results/citylines.html")
长按关注下方公众号后,
回复返乡即可获取本文全部源码
Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以公安部、工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。

▼ 点击下方阅读原文,免费成为社区注册会员







