
01 生活中,我们经常遇到以下问题
如何预测一个用户是否购买某件商品?
如何预测用户流失概率?
如何判断用户的性别?
如何预测用户是否点击某商品?
如何判断一天评论是正面还是负面?
预测用户是否点击某个广告
如何预测肿瘤是否是恶性的等等
02 如何选择算法模型解决问题?
现实中的这些问题可以归类为分类问题 或者是二分类问题。逻辑回归是为了就是解决这类问题。根据一些已知的训练集训练好模型,再对新的数据进行预测属于哪个类,并且概率是多少。比如用户是否点击某个广告、肿瘤是否是恶性的、用户的性别,等等。
逻辑回归(Logistic regression 或logit regression),即逻辑模型(英语:Logit model,也译作“评定模型”、“分类评定模型”)是离散选择法模型之一,主要是针对因变量为分类变量而进行回归分析的一种统计方法,属于概率型非线性回归。它的有点是算法简单高效,在实际生活中应用广泛;缺点是离散型的数据需要通过生成虚拟变量进行使用。
02 什么是逻辑回归?
逻辑回归是一种广义的线性回归,通过构造回归函数,利用sklearn库实现分类或预测。它使用的函数是Sigmoid函数,也称为s函数,双弯曲线。它把数据集分为0-1区间,然后根据0.5把数据分两类。一类是(0.5 –1);另外一个类是(0——0.5)。当x>0是, 我们把数据归为一类,x<0时,我们把数据归为另一类。
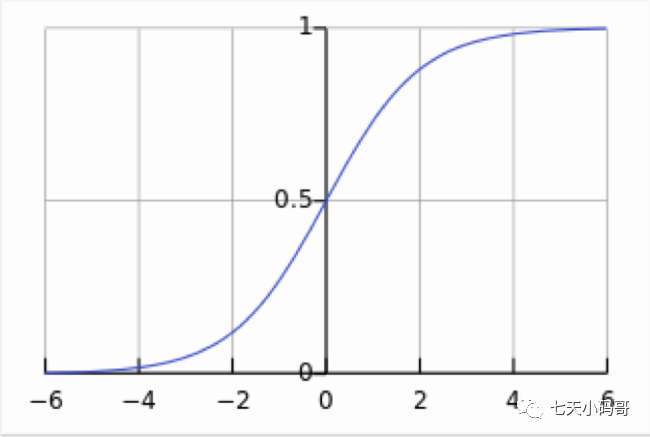
在逻辑回归中,x使用一个y表示,也就是y=f(x1,x2,x3)= a1x1+a2x2+….+anxn。逻辑回归的关键是找到a1,a2,,,an的参数,然后就得到y,进而得到x。最后就可以根据x预测属于哪一类。
03 案例:运用逻辑回归预测用户是否购房
已知某公司的地产中介数据库,包括年龄、教育水平、房屋所有等信息。请根据已知用户信息预测是否购买房产。
是否购买房产是二分问题。用户要么购买,要么租房。这些信息可以使用0 1 表示。我们使用逻辑回归实现该问题。
04 解析流程
因为预测的结果是一个是否题目,要么购买、要么租房。它符合逻辑回归特征。但是数据集中包含很多离散类型变量,需要进行虚拟化处理。首先,我们可以确定逻辑回归流程
第一步:数据处理
第二步:虚拟化处理:分无大小与有大小处理
第三步:建立回归模型
第四步:预测
代码如下:
import pandas
from sklearn.linear_mode import LogisticRegression
def main():
"""
主函数流程
:return:
"""
file_name = 'data.csv'
# 预测数据 自变量
predict_aim = 40
# 第一步 数据处理
processed_data = process_data(file_name)
# 第二步 转换数据类型
input_data, output_data = data_2_category(processed_data)
# 第三步 建立逻辑回归模型
logistic_model = model_data(input_data, output_data)
# 第四步 根据模型预测结果
predict_data(logistic_model)
if __name__ == '__main__':
# 主函数
main()
05 第一步:数据处理
数据处理主要是导入数据集,然后对其进行处理。首先,我们使用pandas.read_csv读取数据文件,然后通过data.shape查看数据集中包括3187行,21列。最后,我们使用dropna()去除数据集中的缺失值,去除后还剩下3085行。如果不去除这些值,它们会影响模型的训练。因此,数据挖掘的第一步就是清理数据,使得它整洁干净,符合数据挖掘算法的要求。(文末扫码 获得源代码和数据集)
06 第二步:虚拟化处理
由于数据集中包括离线类型数据,比如性别等列,我们需要对其进行虚拟化处理。这些变量分有大小意义与无大小的变量。(文末扫码 获得源代码和数据集)
虚拟化处理
def data_2_category(processed_data):
'''
第二步:转换数据集
把离散型数据转化为连续型数据分两部分:
第一部分:无大小意义的数据 使用get_dummies()处理
第二部分:有大小意义的数据 使用map()处理
:param processed_data:
:return:
'''
# 处理无大小意义的数据
print('*' * 20)
print('开始处理无大小意义的列')
dummies_data = data_2_category_get_dummies(processed_data)
# print(dummies_data.columns)
# 处理有大小意义的数据,返回处理后的数据集
print('*' * 20)
print('开始处理有大小意义的列')
dummies_data_final = data_2_category_map(dummies_data)
07 第三步:建立回归模型
我们使用sklearn中的逻辑回归模型对数据建模。首先,创建模型logistic_model,然后使用fit()训练输入与输出数据,进而得到模型的评分是0.8424635332252837。符合预期,我们可以使用该模型进行预测
建立模型
def model_data(input_data, output_data):
'''
第三步:建立回归模型
:param input_data:
:param output_data:
:return:
'''
logistic_model = LogisticRegression()
# 训练数据集
logistic_model.fit(input_data, output_data)
# 评分数据集
logistic_model_score = logistic_model.score(input_data, output_data)
print(f'数据集的逻辑回归得分是{logistic_model_score}')
return logistic_model
数据集的逻辑回归得分是0.8424635332252837
08 第四步:预测
根据模型评分,我们可以看使用它进行预测。对新的数据集预测,我们也需要三步骤。
第一步:数据处理主要是导入数据,并且删除确实。
第二步:处理离散值变量为虚拟变量
第三步:由于模型已经创建成功,我们只需要使用并且预测数据。
根据预测结果,我们得知[0 0 0 0 0 0 0 0]。这说明数据集中的每个人都购置房产。
预测数据
def predict_data(logistic_model):
"""
根据训练集的模型,我们可以进行对新的数据集进行预测
:param logistic_model:
:return:
"""
print()
print('*' * 20)
print('* 开始处理新的数据')
print('*' * 20)
file_name = 'newData.csv'
# 第一步 数据处理
new_data = process_data(file_name)
print(new_data.shape)
# 第二步:转换数据类型
input_new_data,output_new_data = data_2_category(new_data)
print('得到新的数据集的输入')
print(input_new_data.shape)
print(output_new_data.shape)
# 第三步:预测数据
result_input = logistic_model.predict(input_new_data)
print('预测后的结果是:')
print(result_input)
# 输出预测的属性
proba_input = logistic_model.predict_proba(input_new_data)
print('每一个类别的概率是:')
print(proba_input)
# 回归方程的参数是
coef_log = logistic_model.coef_
print('回归方程的参数是:')
print(coef_log)
# 截距
intercept_input = logistic_model.intercept_
print('回归方程的截距是:')
print(intercept_input)
得到新的数据集的输入
(8, 35)
(8, 1)
预测后的结果是:
[0 0 0 0 0 0 0 0]
每一个类别的概率是:
[[0.7919836 0.2080164 ]
[0.87626858 0.12373142]
[0.94658152 0.05341848]
[0.98407936 0.01592064]
[0.8974075 0.1025925 ]
[0.93894934 0.06105066]
[0.91021008 0.08978992]
[0.95289655 0.04710345]]
回归方程的参数是:
[[-9.21438094e-02 -6.24883209e-01 -9.69316011e-01 -4.47613809e-01
1.89401190e-01 1.04775826e-01 4.66224817e-04 1.92878643e-01
1.99245876e-01 4.27647983e-02 -6.95829770e-02 9.99518066e-02
1.85677580e-01 4.04643649e-01 2.77475439e-01 4.63136576e-01
1.18515339e-01 8.80706906e-01 -1.29244267e-02 -6.26125189e-01
5.52697914e-02 -3.26483869e-01 3.38429268e-01 4.69881067e-01
9.03829123e-01 3.76992082e-01 4.31214139e-01 3.25470843e-01
1.78913910e-02
5.74949532e-01 9.43142296e-01 4.56312427e-01
8.51014333e-01 2.42053025e-01 6.95736936e-01]]
回归方程的截距是:
[3.49839379]
请扫码获得完整代码,手把手指导你学Python

只需7天时间,跨进Python编程大门,已有1800+加入
【基础】0基础入门python,24小时有人快速解答问题;
【提高】40多个项目实战,老手可以从真实场景中学习python;
【直播】不定期直播项目案例讲解,手把手教你如何分析项目;
【分享】优质python学习资料分享,让你在最短时间获得有价值的学习资源;圈友优质资料或学习分享,会不时给予赞赏支持,希望每个优质圈友既能赚回加入费用,也能快速成长,并享受分享与帮助他人的乐趣。
【人脉】收获一群志同道合的朋友,并且都是python从业者
【价格】本着布道思想,只需 69元 加入一个能保证学习效果的良心圈子。
【赠予】后续圈主将开发python,0基础入门在线课程,免费送给圈友们,供巩固和系统化复习
(三重福利)最近入圈送大礼包:
1、2.7G、308份最新数据分析报告
2、40G 人工智能算法 视频课
3、Python爬虫课,共14课











