大数据文摘出品
文章来源:medium
编译:朱帅、雪清、夏雅薇
这是一篇pandas入门指南,作者用通俗易懂的语言和简单的示例代码向我们展示了pandas的概况及一些进阶操作。“… 它是所有从事数据科学工作的人必须掌握的库”,“… pandas正是Python语言如此好用的原因之一”。pandas真有这么棒吗?一起来瞧瞧吧~
Python是一门开源编程语言,使用起来非常方便,但同时也存在一些开源语言固有的问题:实现一个功能有很多库可以用。对于刚入门的Python小白来说,很难知道为实现某个特定功能调用哪个库最好。这时候,就需要有经验的人来提点一下。本文就打算告诉你:有这样一个库,它是所有数据科学从业人员必须掌握的,这个库就叫“pandas”。

Pandas最有趣的地方就是它包含了许多其他Python库的功能,也就是说pandas是各种库的集大成者。这意味着,很多时候你只需要pandas就可以完成大部分工作。
Pandas就像是Python中的Excel:它的基本数据结构是表格(在pandas中叫“DataFrame”),可以对数据进行各种操作和变换。当然,它还能做很多其他的事。
如果你对Python已经比较熟悉了,可以直接跳到第三段。
让我们开始吧:
import pandas as pd
不要问我为什么用“pd”而不用“p”或者其他缩写形式,事实就是大家都是这么用的,你这么用就对了!:) (皮这一下很开心~)
读取数据
data=pd.read_csv('my_file.csv')
data=pd.read_csv(my_file.csv',sep=';",encoding="latin-1',nrows=1000,skiprous=[2,5])
sep参数的意思就是分隔符。如果你要处理的是法语数据,Excel中使用的csv分隔符是“;”,那么你需要通过这个参数显式地声明分隔符。encoding参数需要设置为“latin-1”以便能识别出法语的字符;n_rows=1000表示读取前1000行数据;skiprows=[2,5]的意思是在读取文件时去掉第2行和第5行的数据。
最常用的函数是:read_csv和read_excel
其他几个非常好用的函数是:read_clipboard和read_sql
写入数据
data.to_csv("my_new_file.csv",index=None)
通过设置index=None,就会原原本本地将数据写入到文件中。如果你没有指定index=None,程序就会在文件中新增一个索引列,这个列在所有列的最前面,值为0,1,2,3…直到最后一行。
我一般不用像.to_excel,.to_json,.to_pickle这些函数,因为.to_csv这个函数已经非常好用了!而且,csv也是目前最常用的存储表格数据的文件格式。
检查数据
data.shape
验证(rows, columns)信息是否与数据的行、列数相符3
data.describe()
计算一些基本的统计量,如数据计数、均值、标准差、分位数等。
查看数据
data.head(3)
打印数据的前3行。和.head()函数类似,也可以通过.tail()函数查看数据最后几行。
data.loc[8]
打印行索引为8的行。(注意下标默认从0开始)
data.loc[8,'column_1']
打印行索引为8,列名为’column_1’所指向的数据。
data.loc[range(4,6)]
输出行索引从4到6的行数据(不包括6)
逻辑操作符

通过逻辑操作符或取数据的子集。可以使用 & (AND),~ (NOT) 以及 | (OR) 这些常用的操作符,在逻辑操作的前后记得加上括号。
data[data['coluan_1'].isin(["french','engllsh'])]
如果有时候需要对同一列使用大量的OR操作,通常使用.isin()函数代替。
基本的绘图函数
能实现这个功能主要还是得益于matplotlib库。像我们在介绍中说的,这个库的大部分功能都可以直接通过pandas使用。
data['column_numerical'].plot()
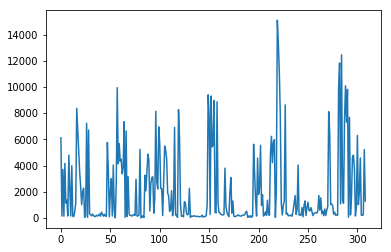
.plot()函数的输出示例
data['column_numerical'].hist()
这个函数绘制的是分布图(也称直方图)。
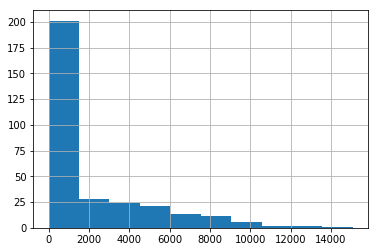
.hist()函数的输出示例
%matplotlib inline
如果你使用的是Jupyter,不要忘了在绘图前加上这一行(只需要在notebook中声明一次即可)。
更新数据
data.loc[8,'column_1']='english'
用“english”替换行索引为8列名为‘column_1’时所指向的值。
data.loc[data['column_1']=='french','column_1']='French'
用1行代码更改多行数据的值。
好了,现在你已经学会了在Excel中能完成的一些常用功能。接下来,让我们发掘一些Excel无法实现的神奇功能吧!
统计频数
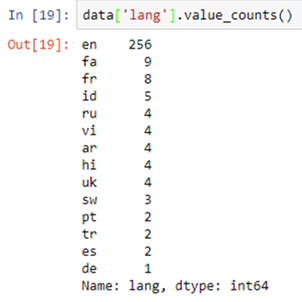
函数 .value_counts() 的输出示例。
针对行、列或者所有数据的操作
data['column_1'].map(1en)
len()函数会应用到’column_1’列下的每一个元素。
.map()操作会将一个函数应用到指定列的每一个元素。
data['column_1']. map(1en). map(1ambda x:x/100).plot()
Pandas库中一个非常好用的功能就是链式方法。它能够帮助你通过一行代码完成多个操作(比如这里的.map()函数和.plot()函数),既简单又高效。
chaining method(链式方法):
https://tomaugspurger.github.io/method-chaining
apply函数会将一个函数应用到所有列。
applymap ()函数会将一个函数应用到表格的所有单元。
tqdm — 独一无二的模块
当处理大规模数据集时,pandas需要花费一些时间来完成.map(),.apply(),.applymap()操作。tqdm是一个非常有用的库,能够预测这些操作什么时候执行结束。(好吧,我说谎了,我之前说过我们只用pandas库)。可以使用 ” pip install tqdm” 命令安装tqdm。
from tqdm import tqdm_notebook
tqdm_notebook().pandas()
使用pandas来创建tqdm进程
data['column_1'].progress_map(lambda x:x.count('e"))
用.progress_map()替换.map()函数,对.apply()函数和.applymap()函数也是一样的。

这就是在Jupyter中使用tqdm和pandas之后可以看到的进度条。
相关矩阵和散布矩阵(scatter matrices)
data.corr()
data. corr(). applymap(lambda x: int(x*100)/100)
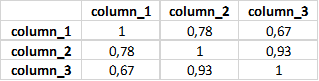
通过.corr()可以得到所有列的相关矩阵。
pd.plotting.scatter_matrix(data,figsize=(12,8))
散布矩阵(scatter matrices)的示例。它在同一个图中绘制两个列的值的所有组合。
SQL的连接功能
连接操作在Pandas中非常简单。
data.merge(other_data,on=['column_1','column_2','column_3'])
只需要一行代码就可以将3列连接到一起。
分组功能
刚开始使用这个功能的时候并不容易,你首先需要掌握一些语法知识,之后你会发现自己再也离不开这个功能了。
data.groupby('column_1)['column_2'].apply(sum).reset_index()
基于某一列对数据进行分组,再对另一列上的数据执行一些函数操作。.reset_index()函数可以将数据转变为DataFrame(表格)的形式。

正如之前提到的,用链式方法将尽可能多的函数功能通过一行代码实现,可以大大优化代码结构。(文摘菌提醒:不过也要考虑代码的可读性哦~)
遍历行
dictionary={}
for i, row in data. iterrows():
dictionary[row['column_1']]=row['column_2]
.iterrows()函数同时获取2个变量并实现循环:分别是行的索引和行的对象(也就是上面代码中的i和row)。
总而言之,pandas库正是Python语言如此好用的原因之一
仅仅通过本篇文章,很难详尽地展示Pandas库的所有功能,但是通过以上内容,你也应该明白为什么一名数据科学家离不开Pandas库了。总的来说,Pandas库有以下优点:
Pandas是一个非常重要的工具,它能够帮助数据科学家快速地阅读和理解数据,更高效地完成自己的工作。
好了,如果你觉得这篇文章对你有用的话,请记得给文摘菌点个赞,哈哈 :) 另外,文摘菌还是建议大家平时多去看看官方文档和API哦~
相关报道:
https://towardsdatascience.com/be-a-more-efficient-data-scientist-today-master-pandas-with-this-guide-ea362d27386






