 标星★公众号,第一时间获取最新研究
标星★公众号,第一时间获取最新研究
本期作者:Yibin Ng
本期编译:1+1=6
近期原创文章:
机器学习有很多应用,其中之一就是预测时间序列。一个最有趣(或者可能是最赚钱)的时间序列是股票价格。
今天,我们用更严谨的学术态度来解决这个问题。例如:移动平均、线性回归、KNN、Auto ARIMA和Prophet的预测范围为1年,而LSTM的预测范围为1天。在一些文章有人说LSTM比我们目前看到的任何算法都要出色。但很明显,我们并不是comparing apples to apples here。
代码+数据如下(文末下载):
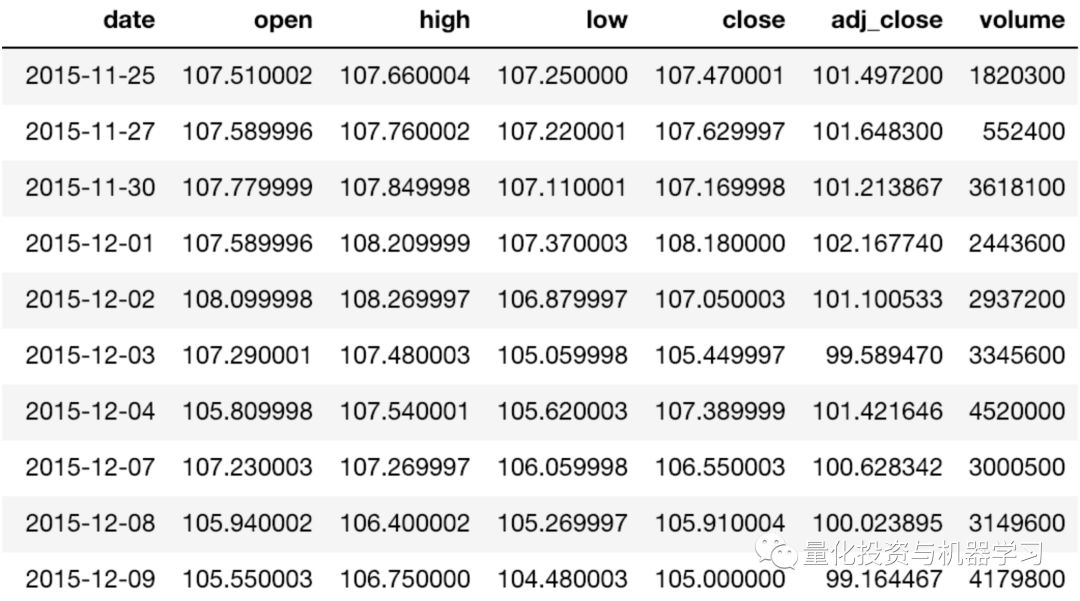
我们的目标是使用前N天的数据(即预测范围= 1)预测Vanguard Total Stock Market ETF(VTI)的每日调整收盘价 。我们将使用VTI从2015年11月25日至2018年11月23日三年的历史价格。可以从雅虎财经下载(https://finance.yahoo.com/quote/VTI/),数据集如下:
import math
import matplotlib
import numpy as np
import pandas as pd
import seaborn as sns
import time
from datetime import date, datetime, time, timedelta
from matplotlib import pyplot as plt
from pylab import rcParams
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from tqdm import tqdm_notebook
stk_path = "./data/VTI.csv"
test_size = 0.2
cv_size = 0.2
Nmax = 2
fontsize = 14
ticklabelsize = 14
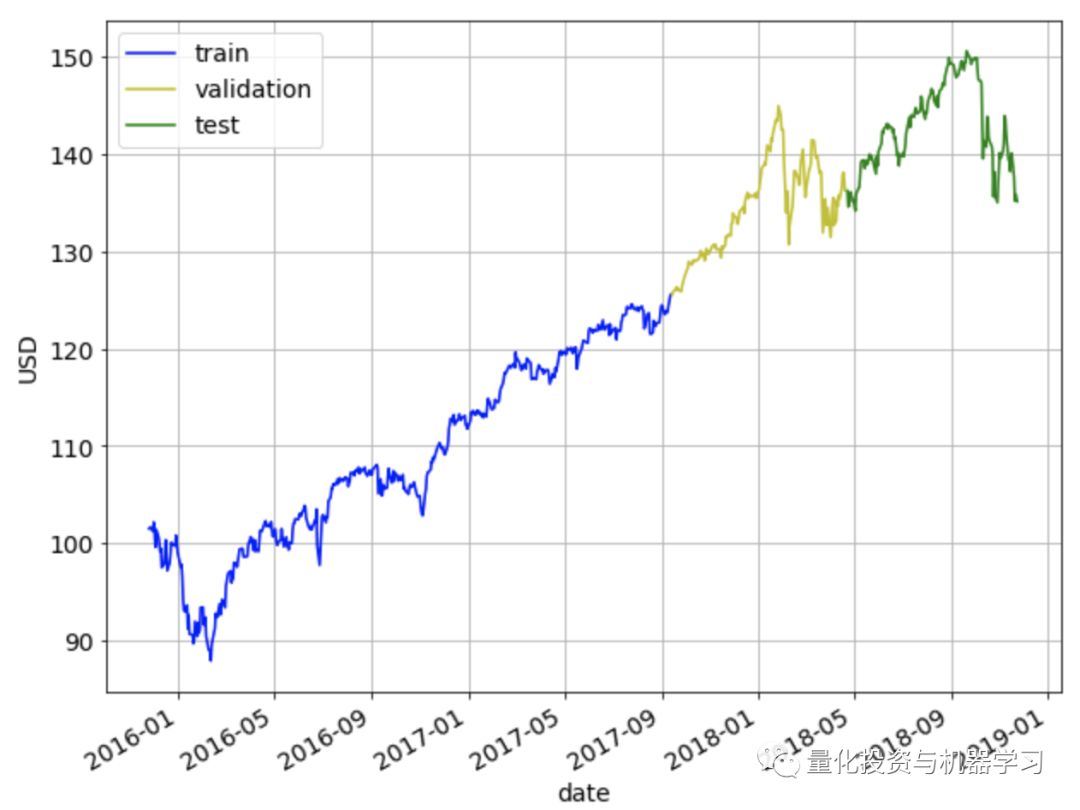
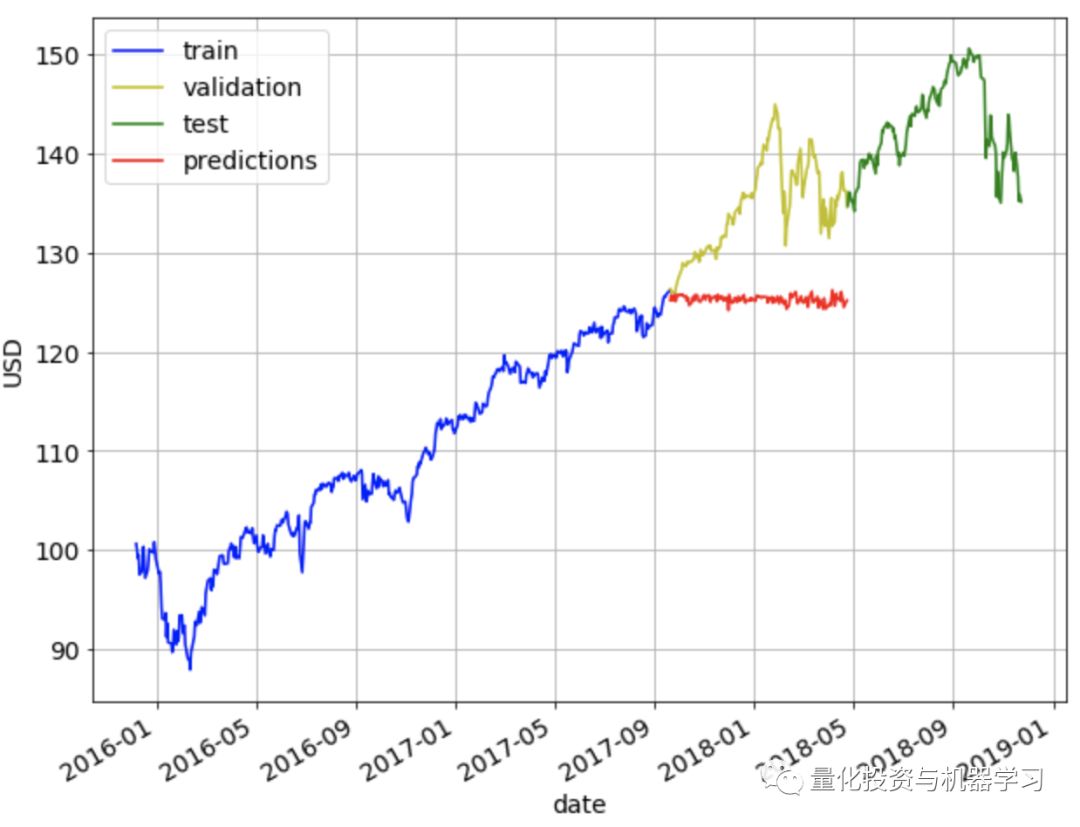
将数据集分为60%训练集、20%验证集和20%测试集。使用训练集对模型进行训练,使用验证集对模型超参数进行调整,最后使用测试集对模型的性能进行测试。
rcParams['figure.figsize'] = 10, 8
ax = train.plot(x='date', y='adj_close', style='b-', grid=True)
ax = cv.plot(x='date', y='adj_close', style='y-', grid=True, ax=ax)
ax = test.plot(x='date', y='adj_close', style='g-', grid=True, ax=ax)
ax.legend(['train', 'validation', 'test'])
ax.set_xlabel("date")
ax.set_ylabel("USD")
为了评估我们的方法的有效性,我们将使用均方根误差(RMSE)和平均绝对百分比误差(MAPE)进行度量。对于这两个指标,值越低,预测效果越好。
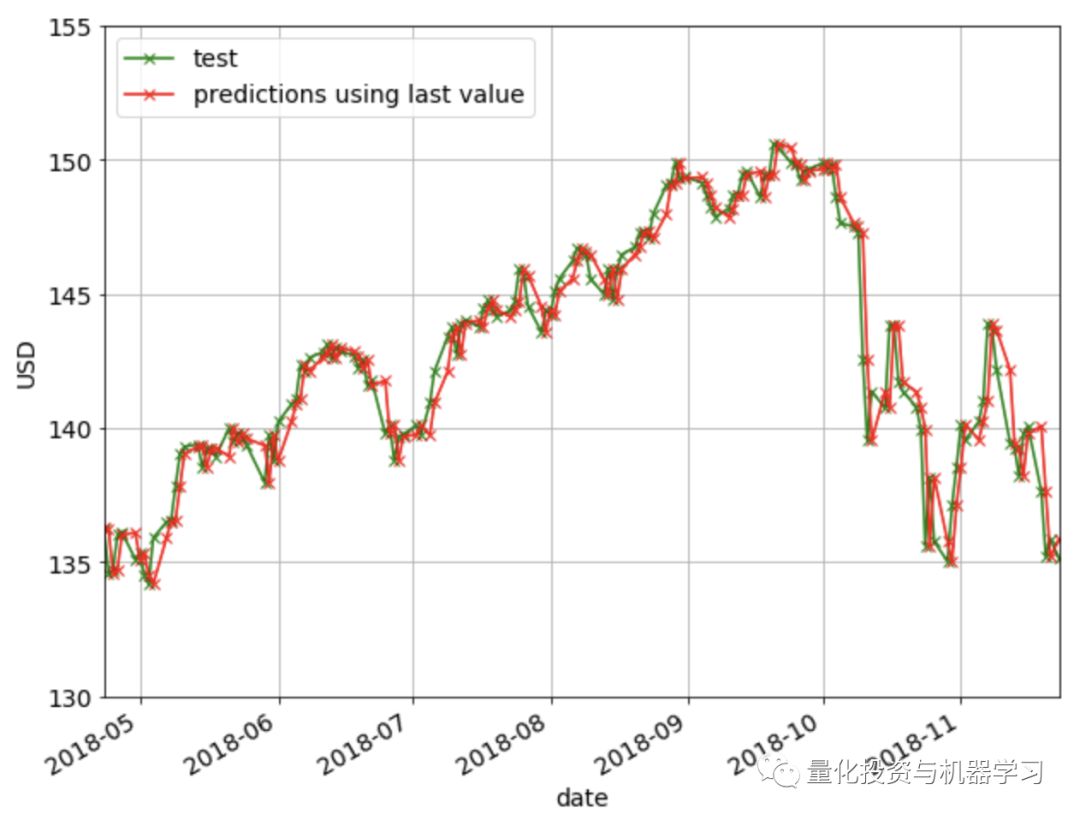
在Last Value方法中,我们将简单地将预测设置为最后一个观测值。这意味着我们将当前的复权收盘价设置为前一天的复权收盘价。这是最具成本效益的预测模型,通常用作比较更复杂模型的基准。这里不需要调优超参数。
下图显示了使用Last Value方法的预测。如果你仔细观察,你会发现每一天的预测(红叉)仅仅是前一天的值(绿叉)。
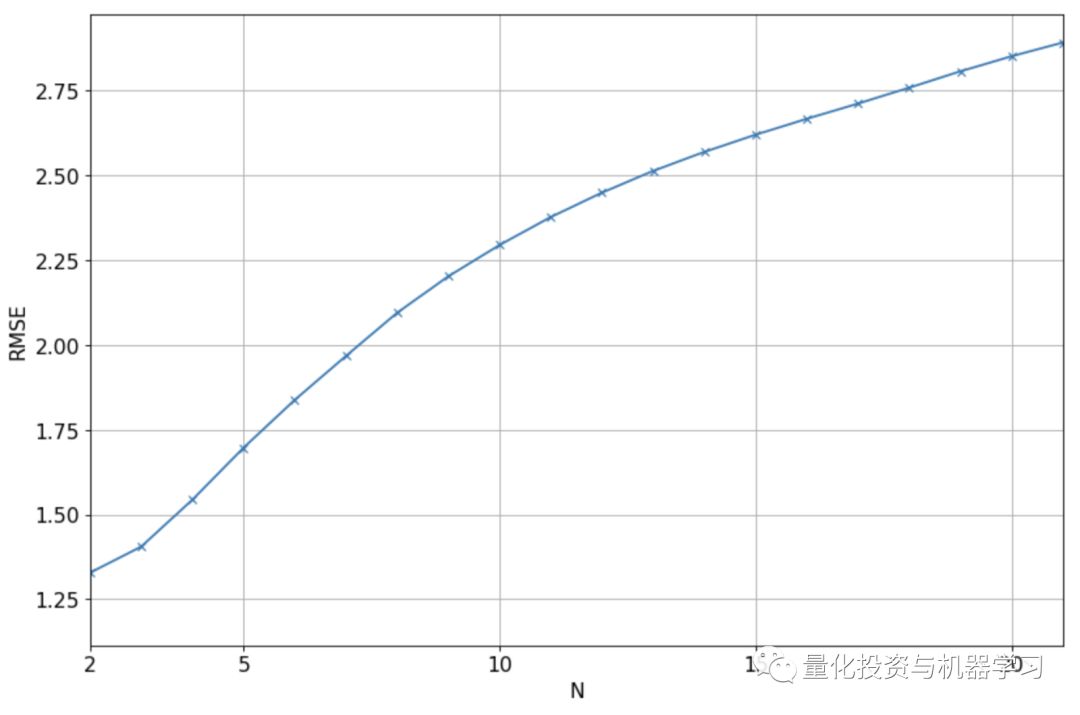
在移动平均法中,预测值将是前N个值的平均值。这意味着我们将当前复权收盘价设置为前N天复权收盘价的平均值。需要调整超参数N。
下图展示了验证集上实际值和预测值之间的RMSE,对于不同的N值,我们将使用N=2,因为它给出了最低的RMSE。
est_list = get_preds_mov_avg(df, 'adj_close', N_opt, 0, num_train+num_cv)
test['est' + '_N' + str(N_opt)] = est_list
print("RMSE = %0.3f" % math.sqrt(mean_squared_error(est_list, test['adj_close'])))
print("MAPE = %0.3f%%" % get_mape(test['adj_close'], est_list))
test.head()
RMSE = 1.270
MAPE = 0.640%
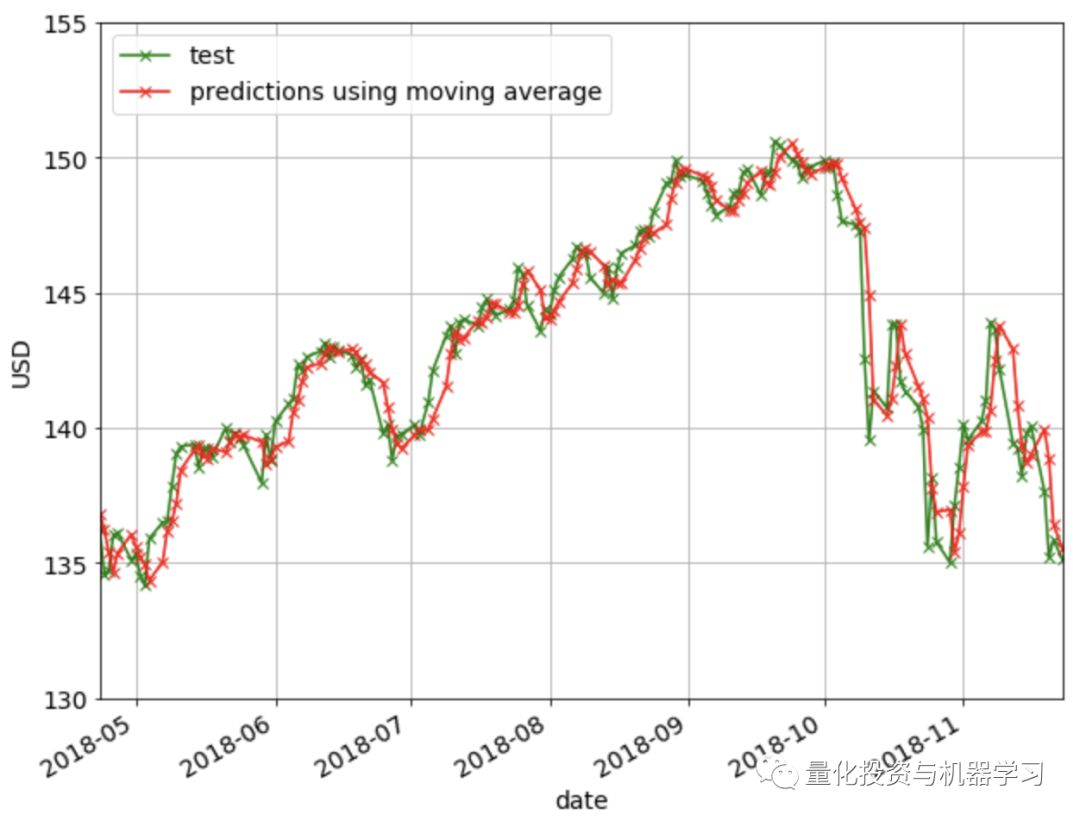
下图显示了移动平均法的预测结果:
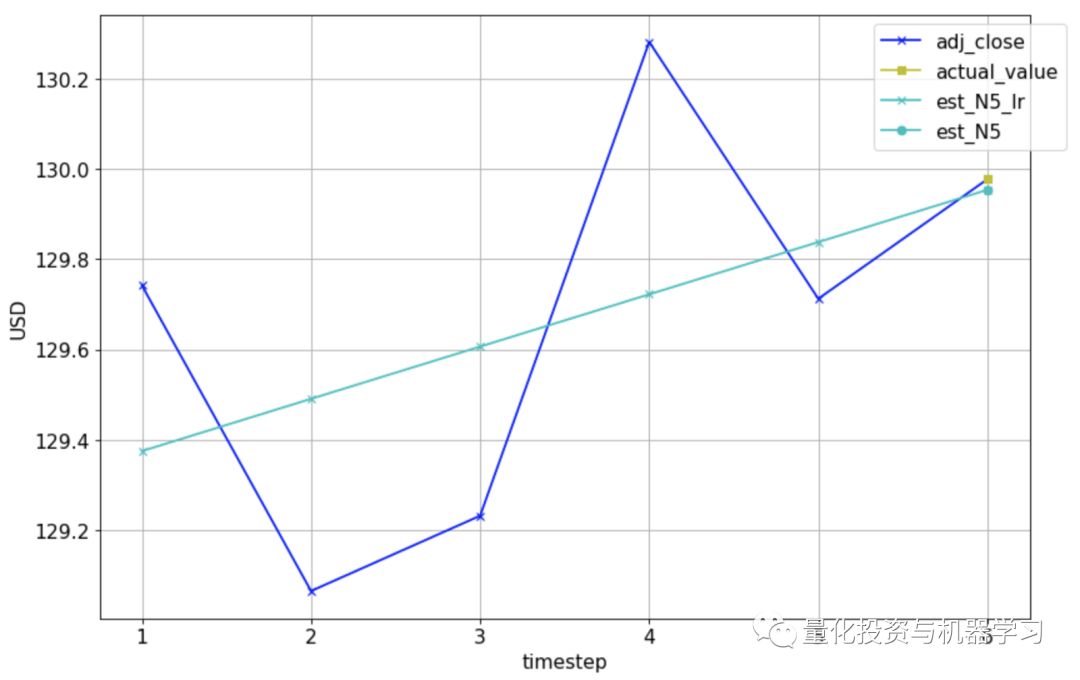
线性回归是对一个因变量和一个或多个自变量之间的关系进行建模的一种线性方法。我们在这里使用线性回归的方法是将线性回归模型与之前的N个值进行拟合,并用这个模型预测当前的值。下图是N=5的一个例子。实际复权收盘价显示为深蓝色的十字,我们想要预测第6天的值(黄色方块)。我们将通过前5个实际值拟合一条线性回归线(浅蓝色线),并用它来做第6天的预测(浅蓝色圆)。
day = pd.Timestamp(date(2017, 10, 31))
Nmax2 = 5
df_temp = cv[cv['date'] <= day]
plt.figure(figsize=(12, 8), dpi=80)
plt.plot(range(1,Nmax2+2), df_temp[-Nmax2-1:]['adj_close'], 'bx-')
plt.plot(Nmax2+1, df_temp[-1:]['adj_close'], 'ys-')
legend_list = ['adj_close', 'actual_value']
color_list = ['r', 'g', 'k', 'y', 'm', 'c', '0.75']
marker_list = ['x'
, 'x', 'x', 'x', 'x', 'x', 'x']
regr = LinearRegression(fit_intercept=True)
for N in range(5, Nmax2+1):
X_train = np.array(range(len(df_temp['adj_close'][-N-1:-1])))
y_train = np.array(df_temp['adj_close'][-N-1:-1])
X_train = X_train.reshape(-1, 1)
y_train = y_train.reshape(-1, 1)
regr.fit(X_train, y_train)
y_est = regr.predict(X_train)
plt.plot(range(Nmax2+1-N,Nmax2+2),
np.concatenate((y_est, np.array(df_temp['est_N'+str(N)][-1:]).reshape(-1,1))),
color=color_list[N%len(color_list)],
marker=marker_list[N%len(marker_list)])
legend_list.append('est_N'+str(N)+'_lr')
plt.plot(Nmax2+1,
df_temp['est_N'+str(N)][-1:],
color=color_list[N%len(color_list)],
marker='o')
legend_list.append('est_N'+str(N))
plt.grid()
plt.xlabel('timestep')
plt.ylabel('USD')
plt.legend(legend_list, bbox_to_anchor=(1.05, 1))
matplotlib.rcParams.update({'font.size': fontsize})
下面是我们用训练模型和做预测的代码:
import numpy as np
from sklearn.linear_model import LinearRegression
def get_preds_lin_reg(df, target_col, N, pred_min, offset):
"""
Given a dataframe, get prediction at each timestep
Inputs
df : dataframe with the values you want to predict
target_col : name of the column you want to predict
N : use previous N values to do prediction
pred_min : all predictions should be >= pred_min
offset : for df we only do predictions for df[offset:]
Outputs
pred_list : the predictions for target_col
"""
regr = LinearRegression(fit_intercept=True)
pred_list = []
for i in range(offset, len(df['adj_close'])):
X_train = np.array(range(len(df['adj_close'][i-N:i])))
y_train = np.array(df['adj_close'][i-N:i])
X_train = X_train.reshape(-1, 1)
y_train = y_train.reshape(-1, 1)
regr.fit(X_train, y_train)
pred = regr.predict(N)
pred_list.append(pred[0][0])
pred_list = np.array(pred_list)
pred_list[pred_list < pred_min] = pred_min
return pred_list
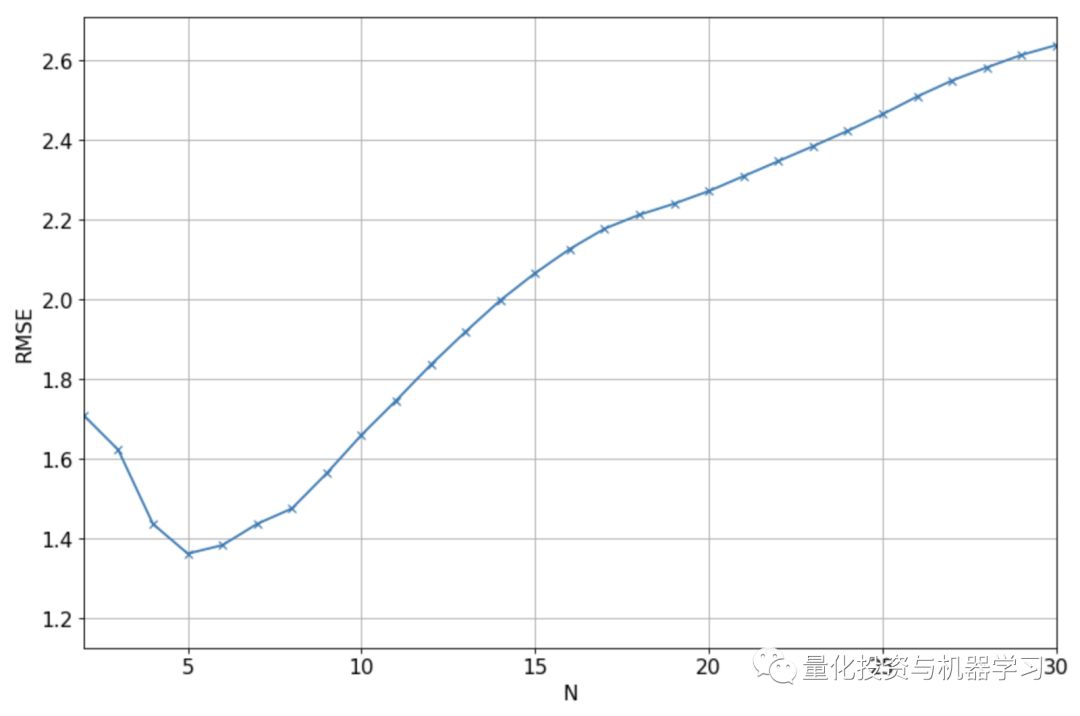
下图显示了验证集的实际值和预测值之间的RMSE,对于N的不同值,我们将使用N=5,因为它给出了最低的RMSE。
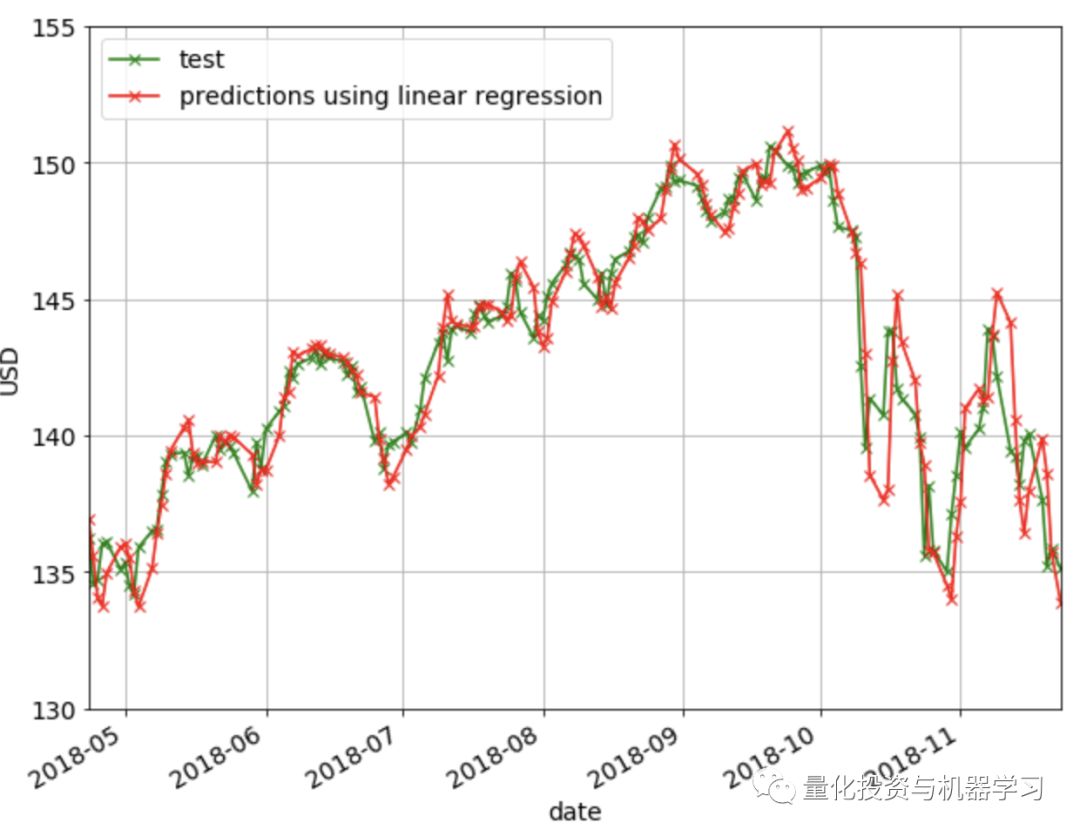
下图显示了线性回归方法的预测结果。可以观察到,该方法不能很好地捕获方向的变化(即下降到上升趋势,反之亦然)。
XGBoost是以迭代的方式将弱学习者转化为强学习者的过程。自2014年推出以来,XGBoost已被证明是一种非常强大的机器学习算法,通常是许多机器学习竞赛中的首选算法。
我们将在训练集中训练XGBoost模型,使用验证集优化其超参数,最后在测试集中应用XGBoost模型并报告结果。使用的显著特征是过去N天的复权收盘价,以及过去N天的成交量。除了这些特征,我们还可以做一些特征工程。我们将构建的其他功能包括:
过去N天,最高价和最低价每天的差值
过去N天,开盘价和收盘价每天的差值
在构建这个模型的过程中,学到了一个有趣的事情,那就是特征缩放对于模型的正常工作是非常重要的。我们的第一个模型根本没有实现任何伸缩,下面的图显示了对验证集的预测。模型训练的是89到125之间的复权收盘价,因此模型只能输出这个范围内的预测。当模型试图预测验证集并且它看到超出了这个范围时,它不能很好地拓展使用。
如果没有正确地进行特征缩放,预测是非常不准的
接下来尝试将训练集规模缩放为均值0和方差1,并且在验证集上应用了相同的变换。但显然这不会起作用,因为在这里我们使用从训练集计算的均值和方差来转换验证集。由于来自验证集的值远大于来自列车集的值,因此在缩放后,值仍将更大。结果是预测仍然如上所述,只是缩放了y轴上的值。
最后,将序列集合的均值缩放为0,方差为1,然后用这个来训练模型。随后,当对验证集进行预测时,对每个样本的每个特征组进行缩放,使其均值为0,方差为1。例如,如果我们对第T天进行预测,我将取最近N天(T-N到T-1)的复权收盘价,并将其缩放为均值为0,方差为1。成交量特征也是一样的,我取前N天的成交量,将其缩放为均值为0,方差为1。使用与其他特征相同的操作。然后我们使用这些缩放的特征来做预测。预测值也会被缩放,我们用它们对应的均值和方差进行逆变换。发现这种扩展方式提供了最好的性能,如下所示。
下面是我们用来训练模型和做预测的代码:
import math
import numpy as np
from sklearn.metrics import mean_squared_error
from xgboost import XGBRegressor
def get_mape(y_true, y_pred):
"""
Compute mean absolute percentage error (MAPE)
"""
y_true, y_pred = np.array(y_true), np.array(y_pred)
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
def train_pred_eval_model(X_train_scaled, \
y_train_scaled, \
X_test_scaled, \
y_test, \
col_mean, \
col_std, \
seed=100, \
n_estimators=100, \
max_depth=3, \
learning_rate=0.1, \
min_child_weight=1, \
subsample=1, \
colsample_bytree=1, \
colsample_bylevel=1, \
gamma=0):
'''
Train model, do prediction, scale back to original range and do
evaluation
Use XGBoost here.
Inputs
X_train_scaled : features for training. Scaled to have
mean 0 and variance 1
y_train_scaled : target for training. Scaled to have
mean 0 and variance 1
X_test_scaled : features for test. Each sample is
scaled to mean 0 and variance 1
y_test : target for test. Actual values, not
scaled
col_mean : means used to scale each sample of
X_test_scaled. Same length as
X_test_scaled and y_test
col_std : standard deviations used to scale each
sample of X_test_scaled. Same length as
X_test_scaled and y_test
seed : model seed
n_estimators : number of boosted trees to fit
max_depth : maximum tree depth for base learners
learning_rate : boosting learning rate (xgb’s “eta”)
min_child_weight : minimum sum of instance weight(hessian)
needed in a child
subsample : subsample ratio of the training
instance
colsample_bytree : subsample ratio of columns when
constructing each tree
colsample_bylevel : subsample ratio of columns for each
split, in each level
gamma : minimum loss reduction required to make
a further partition on a leaf node of
the tree
Outputs
rmse : root mean square error of y_test and
est
mape : mean absolute percentage error of
y_test and est
est : predicted values. Same length as y_test
'''
model = XGBRegressor(seed=model_seed,
n_estimators=n_estimators,
max_depth=max_depth,
learning_rate=learning_rate,
min_child_weight=min_child_weight,
subsample=subsample,
colsample_bytree=colsample_bytree,
colsample_bylevel=colsample_bylevel,
gamma=gamma)
model.fit(X_train_scaled, y_train_scaled)
est_scaled = model.predict(X_test_scaled)
est = est_scaled * col_std + col_mean
rmse = math.sqrt(mean_squared_error(y_test, est))
mape = get_mape(y_test, est)
return rmse, mape, est
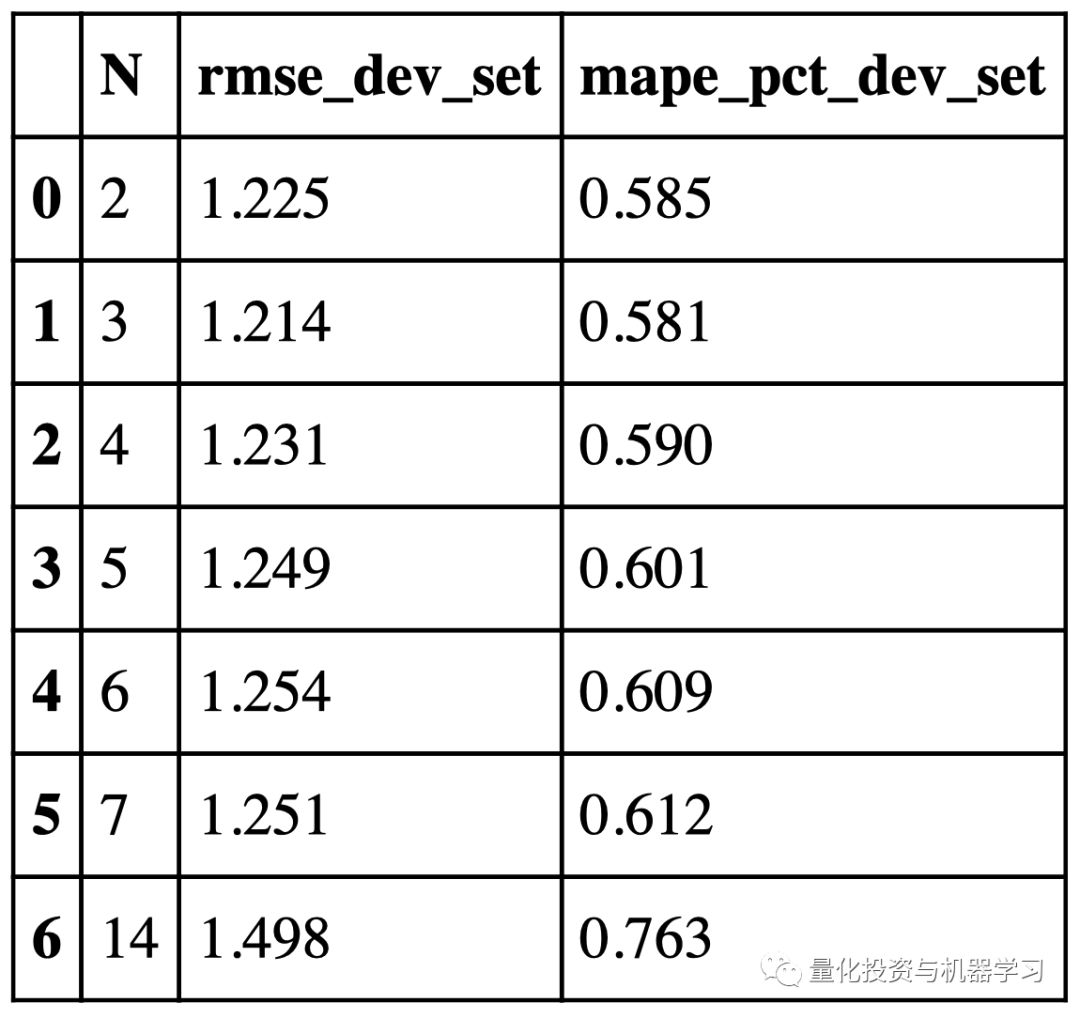
下图显示了验证集上实际值和预测值之间的RMSE,对于不同的N值,我们将使用N=3,因为它给出了最低的RMSE。
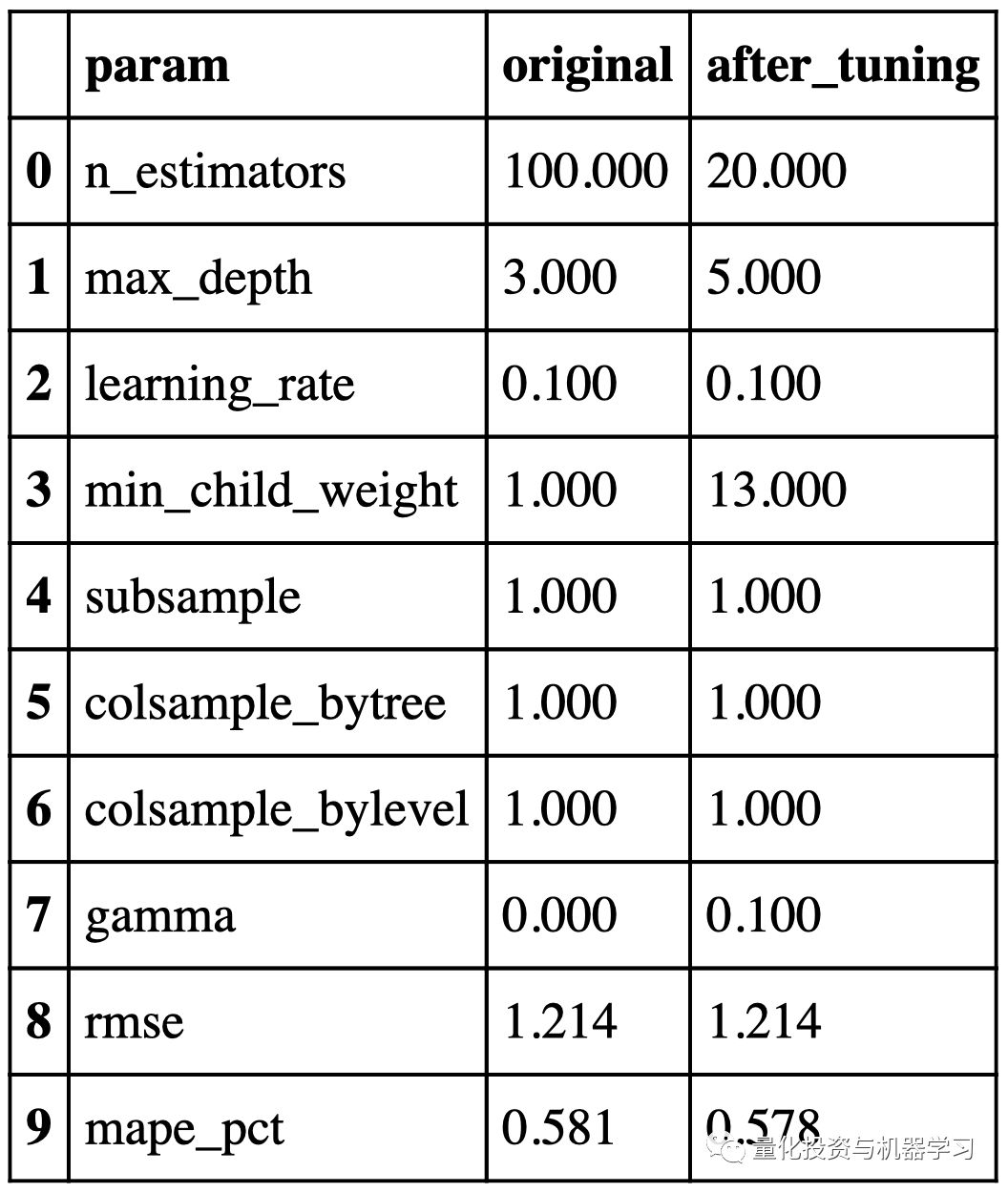
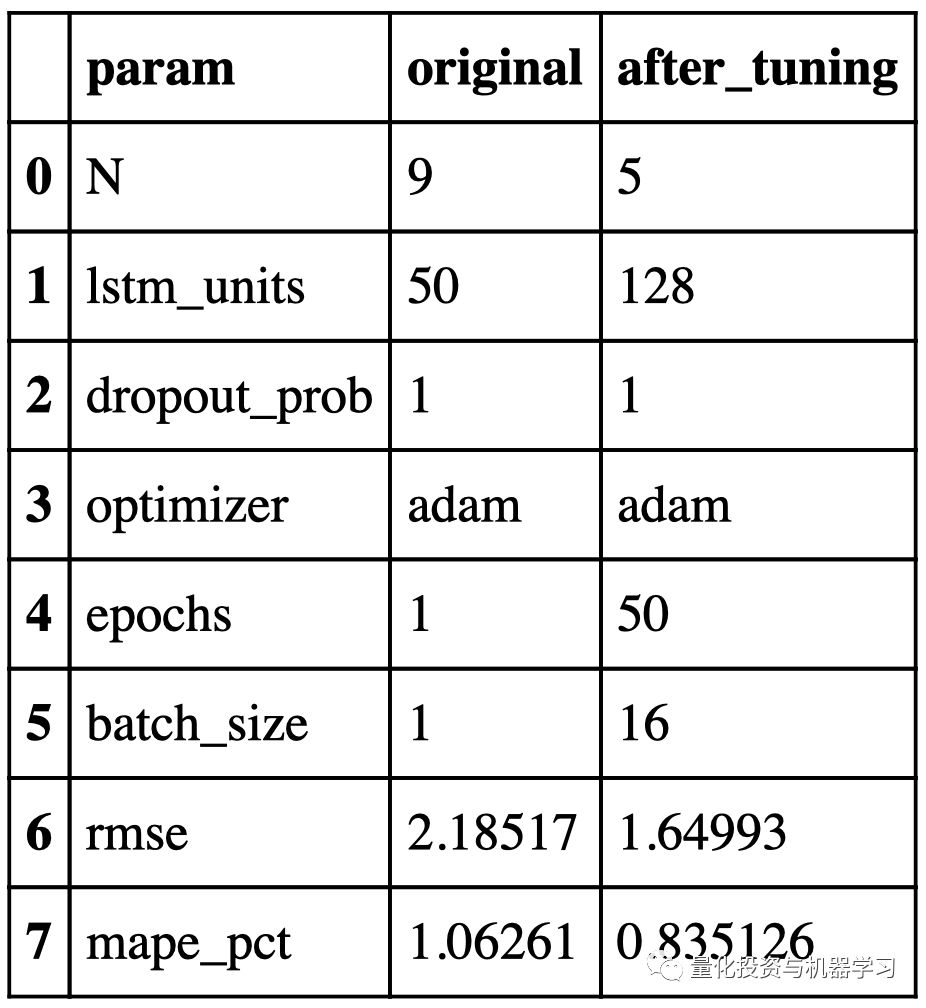
优化前后的超参数和性能如下所示:
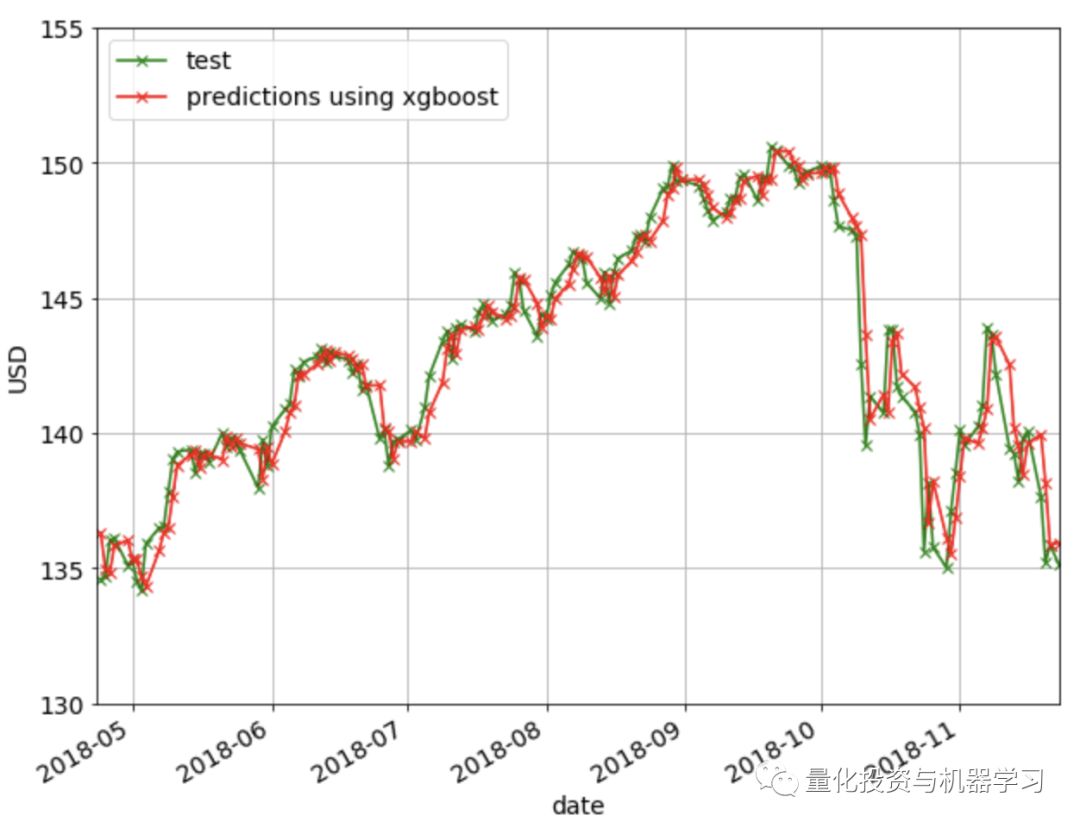
下图显示了使用XGBoost方法的预测结果:
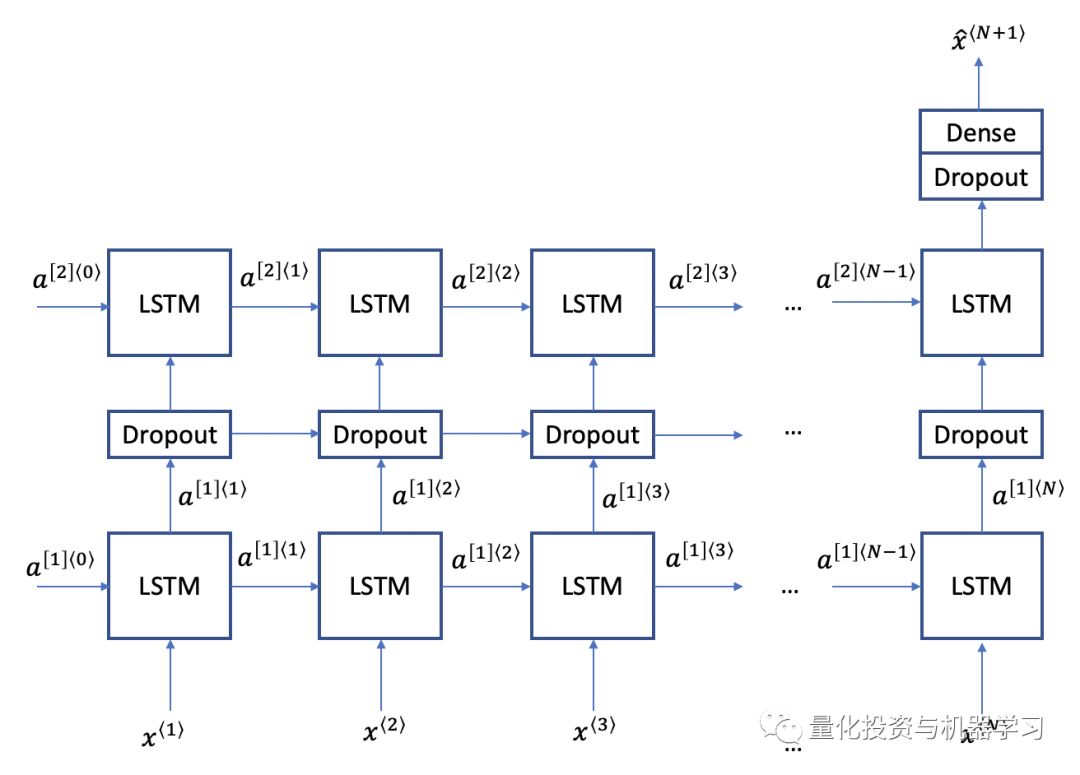
LSTM是一种深度学习模型,用于解决长序列中的梯度消失问题。LSTM有三个门:更新门、遗忘门和输出门。更新和忘记门决定是否更新单元的每个元素。输出门决定了作为下一层的激活而输出的信息量。
下面我们将使用LSTM结构。使用两层LSTM模块并在其间设置一个drop-layer以避免过度拟合。
训练N:
param_label = 'N'
param_list = range(2, 60)
error_rate = {param_label: [], 'rmse': [], 'mape_pct': []}
tic = time.time()
for param in tqdm_notebook(param_list):
x_train_scaled, y_train_scaled = get_x_y(train_scaled, param, param)
x_cv_scaled, y_cv_scaled = get_x_y(train_cv_scaled, param, num_train)
rmse, mape, _ = train_pred_eval_model(x_train_scaled, \
y_train_scaled, \
x_cv_scaled, \
y_cv_scaled, \
scaler, \
lstm_units=lstm_units, \
dropout_prob=dropout_prob, \
optimizer='adam', \
epochs=epochs, \
batch_size=batch_size)
error_rate[param_label].append(param)
error_rate['rmse'].append(rmse)
error_rate['mape_pct'].append(mape)
error_rate = pd.DataFrame(error_rate)
toc = time.time()
print("Minutes taken = " + str((toc-tic)/60.0))
error_rate
Minutes taken = 37.21444189945857
rcParams['figure.figsize'] = 10, 8
ax = error_rate.plot(x='N', y='rmse', style='bx-', grid=True)
ax = error_rate.plot(x='N', y='mape_pct', style='rx-', grid=True, ax=ax)
ax.set_xlabel("N")
ax.set_ylabel("RMSE/MAPE(%)")

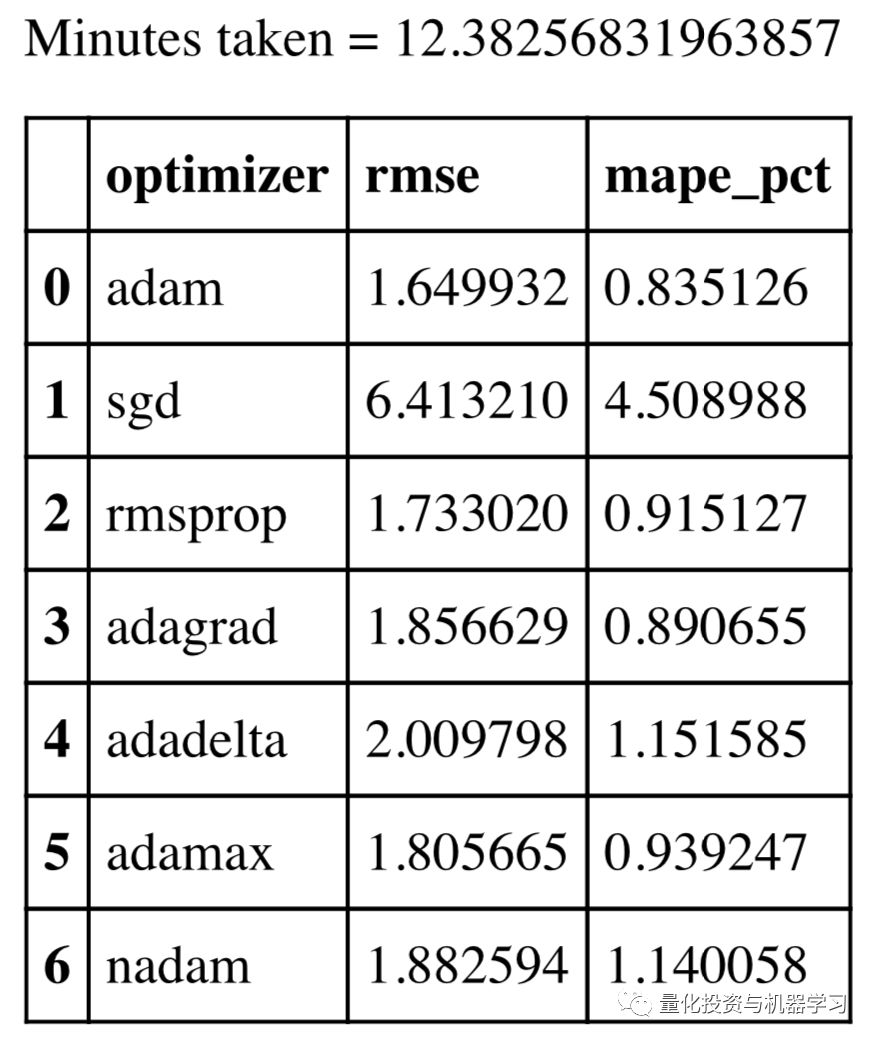
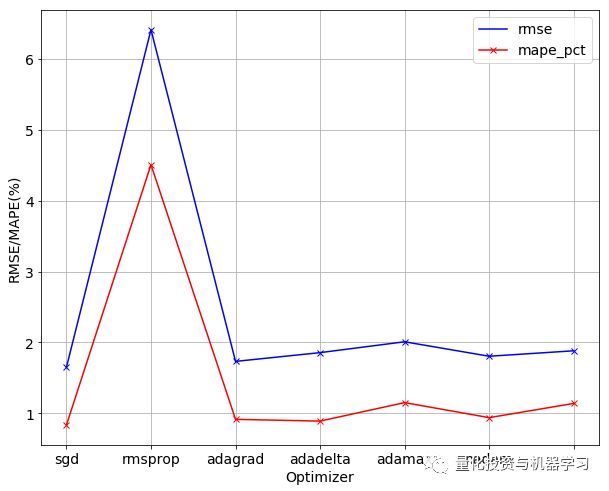
训练模型——优化器
rcParams['figure.figsize'] = 10, 8
ax = error_rate.plot(x='optimizer', y='rmse', style='bx-', grid=True)
ax = error_rate.plot(x='optimizer', y='mape_pct', style='rx-', grid=True, ax=ax)
ax.set_xticklabels(param_list)
ax.set_xlabel("Optimizer")
ax.set_ylabel("RMSE/MAPE(%)")
Text(0, 0.5, 'RMSE/MAPE(%)')
temp = error_rate[error_rate['rmse'] == error_rate['rmse'].min()]
optimizer_opt = temp[param_label].values[0]
print("min RMSE = %0.3f" % error_rate['rmse'].min())
print("min MAPE = %0.3f%%" % error_rate['mape_pct'].min())
print("optimum " + param_label + " = " + str(optimizer_opt))min RMSE = 1.650
min MAPE = 0.835%
optimum optimizer = adam
下面是我们用来训练模型和做预测的代码:
import math
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, LSTM
def train_pred_eval_model(x_train_scaled, \
y_train_scaled, \
x_test_scaled, \
y_test, \
mu_test_list, \
std_test_list, \
lstm_units=50, \
dropout_prob=0.5, \
optimizer='adam', \
epochs=1, \
batch_size=1):
'''
Train model, do prediction, scale back to original range and do
evaluation
Use LSTM here.
Returns rmse, mape and predicted values
Inputs
x_train_scaled : e.g. x_train_scaled.shape=(451, 9, 1).
Here we are using the past 9 values to
predict the next value
y_train_scaled : e.g. y_train_scaled.shape=(451, 1)
x_test_scaled : use this to do predictions
y_test : actual value of the predictions
mu_test_list : list of the means. Same length as
x_test_scaled and y_test
std_test_list : list of the std devs. Same length as
x_test_scaled and y_test
lstm_units : dimensionality of the output space
dropout_prob : fraction of the units to drop for the
linear transformation of the inputs
optimizer : optimizer for model.compile()
epochs : epochs for model.fit()
batch_size : batch size for model.fit()
Outputs
rmse : root mean square error
mape : mean absolute percentage error
est : predictions
'''
model = Sequential()
model.add(LSTM(units=lstm_units,
return_sequences=True,
input_shape=(x_train_scaled.shape[1],1)))
model.add(Dropout(dropout_prob))
model.add(LSTM(units=lstm_units))
model.add(Dropout(dropout_prob))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer=optimizer)
model.fit(x_train_scaled, y_train_scaled, epochs=epochs,
batch_size=batch_size, verbose=0)
est_scaled = model.predict(x_test_scaled)
est = (est_scaled * np.array(std_test_list).reshape(-1,1)) +
np.array(mu_test_list).reshape(-1,1)
rmse = math.sqrt(mean_squared_error(y_test, est))
mape = get_mape(y_test, est)
return rmse, mape, est
我们将使用与XGBoost中相同的方法来缩放数据集。验证集调优前后LSTM网络的超参数和性能如下所示:
下图显示了使用LSTM的预测:

下面,我们在同一张图绘制上面使用的所有方法。很明显,使用线性方法的预测最差。除此之外,从视觉上很难判断哪种方法提供了最好的预测。
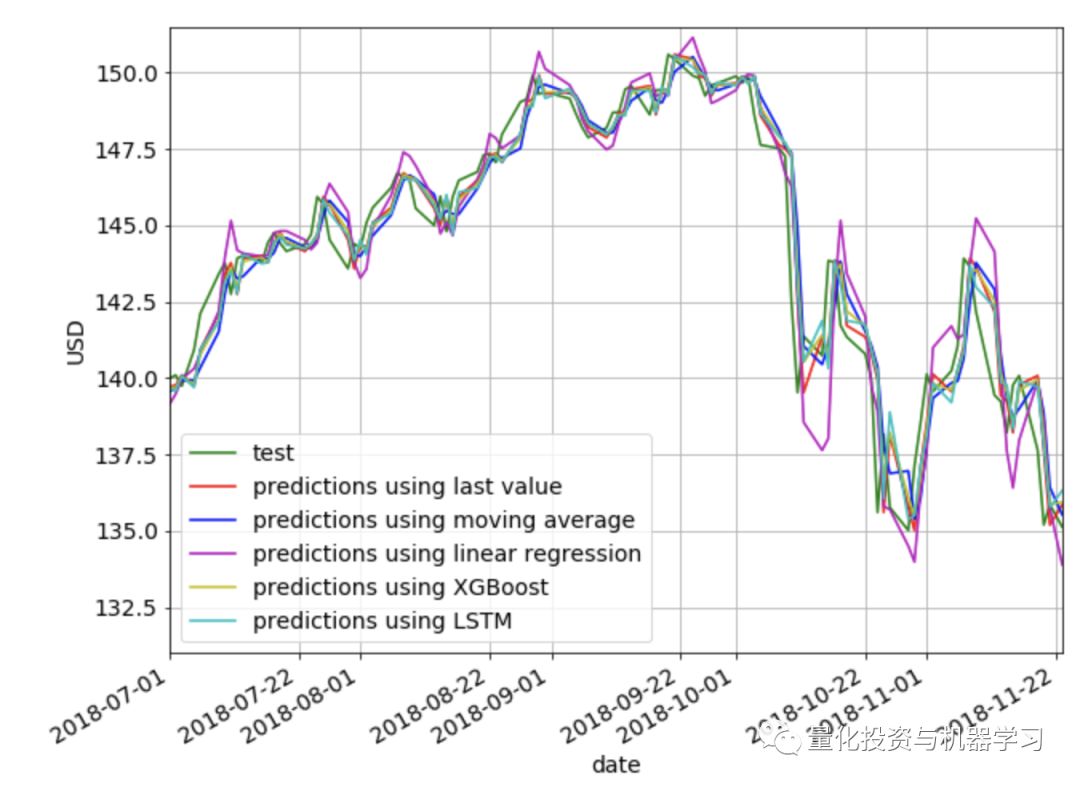
下面是我们所探讨的各种方法的RMSE和MAPE的并列比较。我们看到last value给出了最低的RMSE和MAPE,然后是XGBoost,然后是LSTM。有趣的是,简单的last value方法优于所有其他更复杂的方法,但这很可能是因为我们的预测范围只有1。对于较长的预测范围,我们认为其他方法比last value更能捕捉趋势和季节性。










