随着深度学习的成熟,在18年的《Nature》子刊中,一共出现了三篇综述,分别从基因组学(genetic),健康守护(health care)与生物医学(biomidicine)这三个角度,介绍了深度学习的引入带来的研究机会及挑战。本文将首先简述深度学习的背景知识,之后依次概述上述三篇文章的主要内容,带你一文鸟渺深度学习与生物碰撞出的火花。
深度学习需要大量的数据,而近些年来测序技术的进步,带来了数据总量与样本量的增加,下图是不同类型的数据随年份总数据量的变化趋势,以及不同类型的数据的样本量与单个样本数据的大小,从数据量的增长趋势,既可以解释为何在过去某些领域深度学习的应用取得了成功,也可以预测未来那些领域有可能取得突破。该图中缺少蛋白质相关的数据,例如蛋白质之间的相互作用,蛋白质的三维结构,蛋白质与小分子的互作等,但蛋白质相关的数据,通量相比测序数据明显偏低,还没有达到深度学习的“引爆点”。
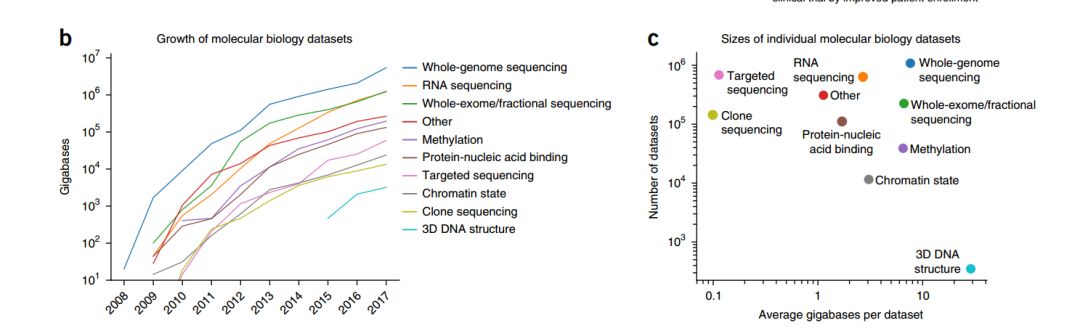
不同类型数据的数据量变化 来自Deep learning in biomedicine
相比传统的机器学习方法,深度学习的方法训练出的模型可以适用于多种不同类型的数据,还可以结合多种来源的数据,共同完成一个任务。例如预测DNA突变是否有害,可以分别训练基于Chip-seq和表观阻蛋白的模型,之后再将这俩个模型结合基于基因序列的模型,来综合预测突变是否有害的可能性。如何提高及利用深度学习带来的数据整合能力与泛化能力,是未来模型结构创新及模型再新场景下预测需要注意的点。
除了常见的有监督学习与无监督学习,半监督学习与强化学习也是值得生物界关注的两种学习模式。该模式下部分数据有标签,部分数据没有标签。这在基因数据中很常见,通常只有少量数据有高质量的标签。通过深度生成模型,可以使用到那些没有标注的数据,从而提升训练可用的数据量。强化学习的训练过程中涉及到了与环境的互动,使得模型能够持续的提升性能。
深度学习,追根究底,是统计学习的一种,是基于对大批量已有数据汇总的结果进行处理,通过优化算法,使得模型能够在未知的新数据上做出最优的预测或聚类。这导致了模型缺少解释性,也就是说从概率上来讲,模型表现的不差,但对于每一个新的预测数据来说,却无法给出为何给出这个预测结果的原因。目前提升深度学习的解释性的工作,有俩个方向,一是从众多特征中找到一个对预测贡献度最大的特征子集,另一个是在卷积神经网络的框架下,通过将整张图的权重矩阵以热图的方式,呈现出来,从而展示出高层的网络预测是如何决定于低层的网络结构的。
深度学习在医疗相关的应用,除了模型解释性的缺失,还要面对俩个问题,第一是机器可能会在少数情况下犯愚蠢的错误,即使机器在大部分时候都表现的和人类专家水平相当,但偶然会犯低级错误,二是如果训练数据中包含了偏见,模型会放大偏见。例如黑人由于超重比例增多而导致二型糖尿病风险增加,人类能够看出种族和疾病风险之间并无因果关系,但基于相关性的深度学习却会引入偏见,从而在医疗诊断中歧视黑人。
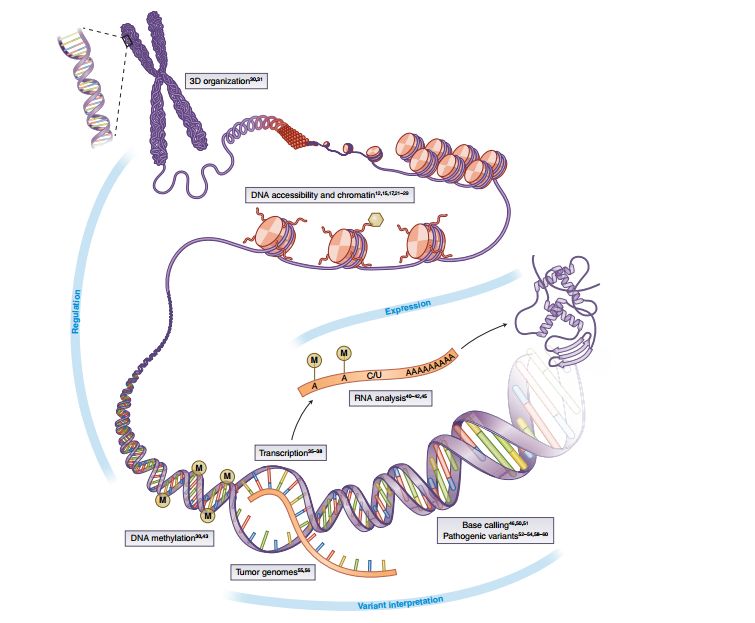
深度学习在基因组领域具体应用场景 来自A primer on deep learning in genomics
先说基因组方面的应用,上图展示了不同尺度下的具体场景,从基于HighC的数据推测DNA3维结构,到使用TATC及chip-seq的数据来预测染色质的结合,再到甲基化与转录数据,最后到变异检测和变异有害性的预测,都有相关的应用。其中较为成熟是变异检测,谷歌16年底发布的Deep variant之外宣布其表现水平已超越了目前的通用流程GATK,而在最新版的GATK 4.0 中,也已引入了基于深度学习的模块。
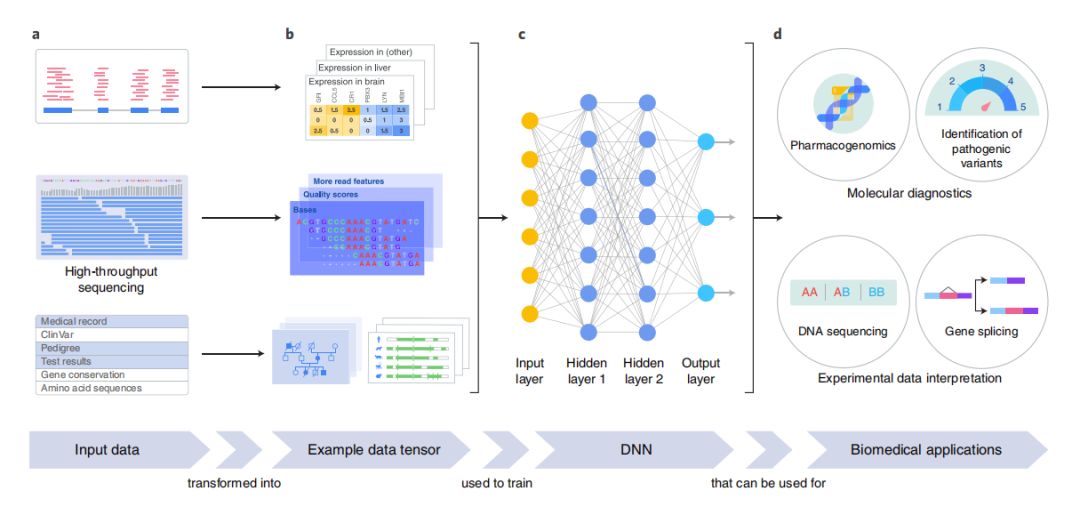
深度学习在基因组方面的应用流程及场景,包括变异有害性评估,药物毒副反应预测,剪切位点预测,来自A guide to deep learning in healthcare
传统的基因组关联分析(GWAS)大多只能检测一个点突变(SNP)与所研究疾病的关系,而DeepWAS,这一新提出的框架则能够根据功能单元,选择出一组SNP 的集合,来更加综合的研究治病的基因突变,并能直接的寻找调控区域的基因突变。在一项针对抑郁症的研究中,使用DeepWAS 框架的新研究发现了一个新的控制抑郁症的主要基因MEF2C。
在健康守护方面,可穿戴设备的数据,将为慢性病患者提供持续的健康监控,例如通过手环或心贴收集心跳及心电数据,并据此预测心脏病患者的发病概率,而植入式的持久血糖监控,也可用来预测那些糖尿病患者更容易出现并发症。可穿戴设备给出的时间序列数据,使用深度学习中的RNN及LSTM,能够更好的提取特征,同时整合多来源数据的能力,使得该领域的应用能够在模型中引入基因数据,从而提升模型的精度。在最新的Nature子刊Machine Intelligence上,则报道了基于心跳数据通过自编码器模型预测病人死亡率的案例。

健康守护的另一个数据来源是社交媒体,例如通过自然语言处理技术,分析聊天记录与展示的状态,可以预测出个人的是否有自杀倾向,或者是否已陷入抑郁状态。通过社交网络,还可以利用位置信息,提前预测传染病的爆发。基于社交网络,体检数据(电子病历)以及基因数据,给出个性化的健康咨询推荐,也是深度学习可以应用的场景。例如Deep Patient使用三层堆叠的降噪自动解码器从电子健康病历数据中获取一个通用的病人特征,在对严重糖尿病、精神分裂症以及各种癌症的预测表现上,“Deep Patient”遥遥领先。
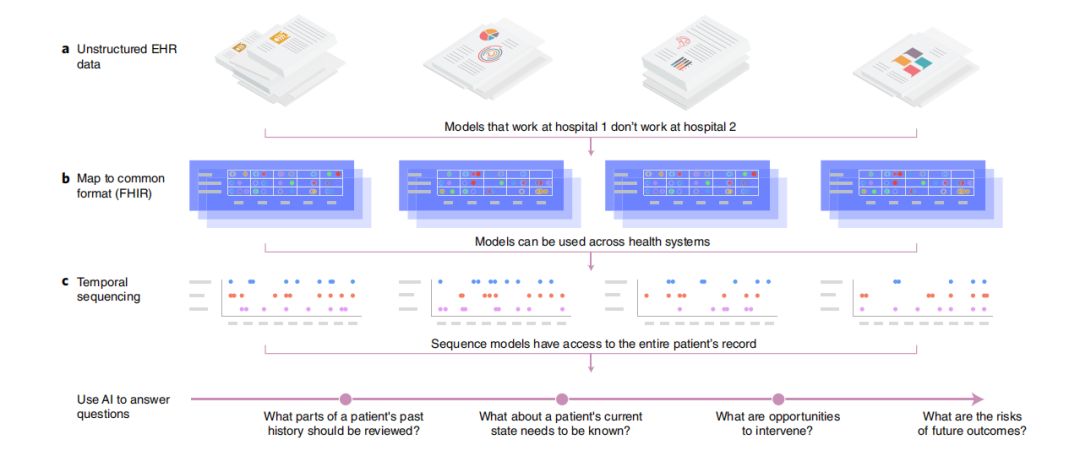
对电子病历进行处理的流程,先进行数据的结构化,再按时间先后对数据整理,之后用提取出的特征回答范例问题,来源A guide to deep learning in healthcare
聊天机器人也可以应用于健康守护领域,通过提取医师与病人的问答记录中的模式,再结合知识图谱技术,可以免费的为更多的人提供健康咨询以及初步的问诊。随着面向消费者的基因检测的普及,如能通过自然语言处理,将遗传咨询的服务自动化,将能够让更多人更好的应用基因检测带来的信息。
而我设想的深度学习在健康守护方面的应用,还包括基于虚拟现实及增强现实技术,通过游戏化的场景,来及时检测退行性病。例如对于帕金森,如果能将体检转换为一个VR游戏,例如射击,赛车,那就可以持续的进行监控,从而做到早发现。或者对于阿兹海默,也可以对于基因型风险较高的,通过益智游戏,来延缓发病的年龄。
而当前最火的应用,莫过于医学影像。这方面从眼部的老年黄斑病变,到肿瘤阴影区的识别。美国FDA以及批准深度学习在心脏标注, 肿瘤识别,以及视网膜病变检测上的应用,深度学习给出的概率性预测,可以用来帮助医师进行判断。在基础科学研究上,有对细胞切片影像的分割和统计,例如cellProfiler,可以从图片中提取出细胞数目,细胞大小及细胞荧光变化等基础特征,但对于更高层解释,则无法自动化给出。
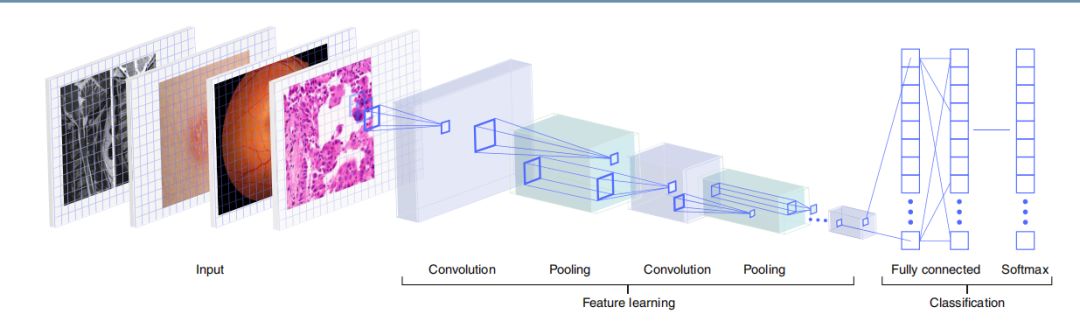
医学影像处理流程示例 来源:A guide to deep learning in healthcare
使用强化学习,可以使用机械手臂来自动化常见的微创的手术,减少人为的医疗错误。还可以对手术中的异常进行监控。但是对于全新的手术流程,深度学习无法实现自动化的处理。在药物研发领域,深度学习可以用来筛选出合适的小分子,减少研发成本。
参考文献
[1] A guide to deep learning in healthcare
[2] Deep learning in biomedicine
[3] A primer on deep learning in genomics
[4] Deep-learning cardiac motion analysis for human survival prediction
[5] DeepWAS: Directly integrating regulatory information into GWAS using deep learning supports master regulator MEF2C as risk factor for major depressive disorder








