(给Python开发者加星标,提升Python技能)
作者:苏克 (本文来自作者投稿)
摘要:学 Excel 还是 R、Python?机器学习怎么入门?数据工程师和数据科学家有什么区别?听听美国 IT 大牛的建议。
去年我决定从传统水利行业跨行到 Python 领域的时候,满脑子都是困惑与担心,犹豫放弃所学多年的专业知识值不值得,担心万一转行失败怎么办,纠结实际工作比想象中的难怎么办。
没遇到指点迷津的大佬,只好网上各种搜,众说纷纭,最后在「要不要转行」这个问题上浪费了很长时间。在跨过这个坎之后,回头来看以前那些问题,思路清晰很多。
其实,在开始阶段,相比具体的专业知识,更重要的是大方向把握。好比,你告诉我旅途上的风景有多么多么美,但我想先知道是哪条路,好判断能不能去到。
最近看到一篇叫「2019 年学习数据科学是什么感受」的文章,深有感触。作者是 Thomas Nield,美国西南航空公司的商务顾问,著有《Getting Started with SQL (O'Reilly) 》等书,经验丰富的 IT 大牛。
文章中他 以一问一答的形式,给那些想要踏上数据科学之路的人,提了一些中肯的建议。里面有些观点很有价值,特节选翻译成文,这里分享给你。
背景:假设你是一名「表哥」,平常工作主要使用 Excel,数据透视表、制图表这些。最近了解到未来很多工作岗位会被人工智能会取代,甚至包括你现在的工作。你决定开始学习数据科学、人工智能和机器学习,Google 搜索「如何成为数据科学家」找到了下面这样一份学习路线图,然后你就开始向作者大牛请教。
Q:我是否真的必须掌握这个图表中的所有内容,才能成为数据科学家?
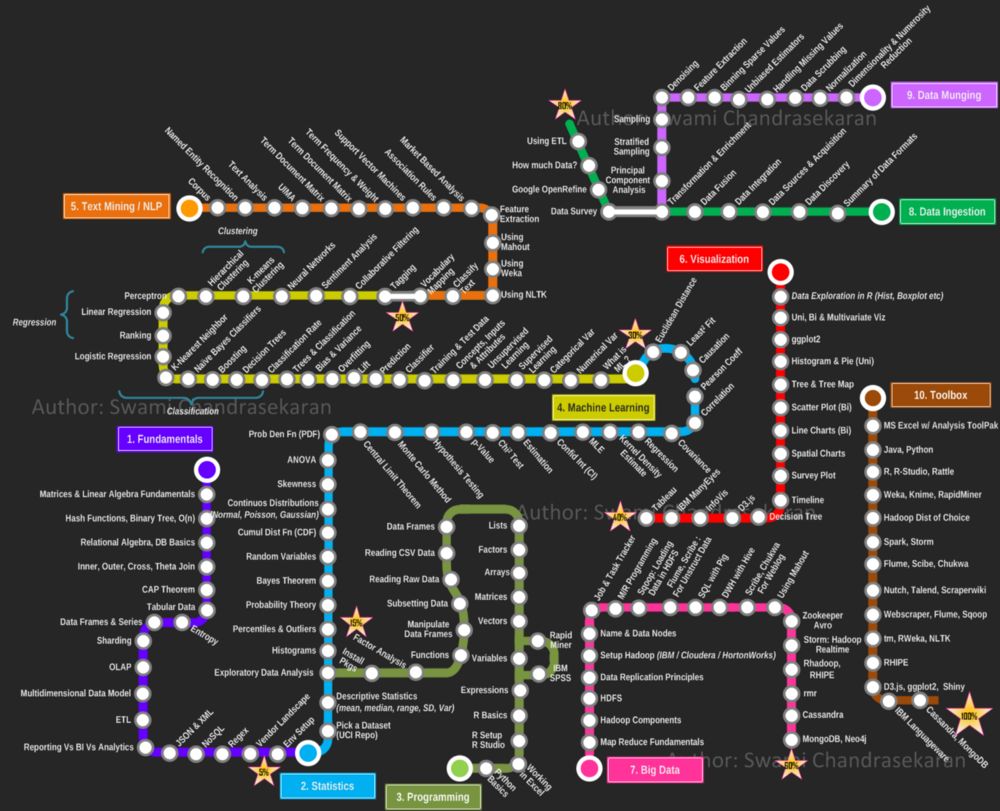 成为一名数据科学家的必须技能(截至2013年)
成为一名数据科学家的必须技能(截至2013年)A:简单说,不需要全部。这是 2013 年的路线图,有点过时了,里面连 TensorFlow 都没有,基本没有人再参考。完全可以划掉这个图中的一些路径,前几年「数据科学」划分地过于分散,采用其他方法会更好。
Q:听你这样说就不那么紧张了,那么我应该回到学校继续深造,然后获得一个数据科学硕士学位吗? 我看很多数据科学家至少都是硕士。
A:天哪,你为什么这样做?不要被「数据科学」这些高大上的术语给唬住了,这些术语主要是用来重新定义一些业务分类。事实上,学校教授的东西基本都是过时的技术,不如选择 Coursera 或 Khan Academy 这些在线自学网站。
Q:那么我该如何开始自学呢?LinkedIn上的人说应该先学习 Linux ,Twitter 的人建议先学习 Scala,而不是 Python 或 R
A:不要信那些人的话。
Q:好的,R怎么样?不少人喜欢它。
A:R 擅长数学建模,但 Python 能做的更多,比如数据处理和搭建 Web 服务,总之 Python 比 R 的学习投资回报率高。
Q:R 在 Tiobe上的排名仍然很高,而且拥有大量的社区和资源,学它有什么不好?
如果你只是对数学感兴趣,使用 R 完全没问题,配合 Tidyverse 包更是如虎添翼。但数据科学的应用范围远超数学和统计学。所以相信我,Python 在 2019 年更值得学,学它不会让你后悔。
Q:Python 难学么?
A:Python 是一种简单的语言,可以帮你可以自动完成许多任务,做一些很酷的事情。不过数据科学不仅仅是脚本和机器学习,甚至不需要依赖 Python 。
Q:什么意思?
A:Python 这些只是工具,使用这些工具可以从数据中获取洞察力,这个过程有时会涉及到机器学习,但大部分时间没有。简单地来说,创建图表也可以算是数据科学,所以你甚至不必学习 Python,使用 Tableau 都行,他们宣称使用他们的产品就可以「成为数据科学家」。
Q:好吧,但数据科学应该不仅仅是制作出漂亮的可视化图表,Excel 中都可以做到,另外学习编程应该很有用,告诉我一些 Python 方面的知识吧
A:学习 Python,你需要学习一些库,比如用于操作 DataFrame 的 Pandas 、制作图表的 Matplotlib,实际上更好的选择是 Plotly,它用了 d3.js。
Q:我能懂一些,但什么是 DataFrame?
A:它是一种有行和列的数据结构,类似 Excel 表,使用它可以实现很酷的转换、透视和聚合等功能。
Q:那 Python 与 Excel 有什么不同?
A:大不相同,你可以在 Jupyter Notebook 中完成所有操作,逐步完成每个数据分析阶段并可视化,就像你正在创建一个可以与他人分享的故事。毕竟,沟通和讲故事是数据科学的重要组成部分。
Q:这听起来和 PowerPoint 没什么区别啊?
A:当然有区别,Jupyter Notebook 更自动简洁,可以轻松追溯每个分析步骤。有些人不太喜欢它,因为代码不是很实用。如果你想做一款软件产品,更好的方法是使用其他工具模块化封装代码。
Q:那么数据科学跟软件工程也有关系么?
A:也可以这么说,但不要走偏,学习数据科学最需要的是数据。初学的最佳方式是网络爬虫,抓取一些网页,使用 Beautiful Soup 解析它生成大量非结构化文本数据下载到电脑上。
Q:我以为学习数据科学是做表格查询而不是网页抓取的工作,所以我刚学完一本 SQL 的书,SQL 不是访问数据的典型方式吗?
A:好吧,我们可以使用非结构化文本数据做很多很酷的事情。比如对社交媒体帖子上的情绪进行分类或进行自然语言处理。NoSQL 非常擅长存储这种类型的数据。
Q:我听说过 NoSQL 这个词,跟 SQL 、大数据有什么关系?
A:大数据是 2016 年的概念,已经有点过时了,现在大多数人不再使用这个术语。NoSQL 是大数据的产物,今天发展成为了像 MongoDB 一样的平台。
Q:好的,但为什么称它为 NoSQL?
A:NoSQL 代表不仅是 SQL,它支持关系表之外的数据结构,不过 NoSQL 数据库通常不使用 SQL,有专门的查询语言,简单对比一下 MongoDB 和 SQL 查询语言:

Q:这太可怕了,你意思是每个 NoSQL 平台都有自己的查询语言?SQL 有什么问题?
A:SQL 没有任何问题,它很有价值。不过这几年非结构化数据是热潮,用它来做分析更容易。需强调的是,尽管 SQL 难学,但它是一种非常通用的语言。
Q:好的,我可以这样理解么: NoSQL 对数据科学家来说不像 SQL 那么重要,除非工作中需要它?
A:差不多,除非你想成为一名数据工程师。
Q:数据工程师?
A:数据科学家分为两个职业。数据工程师为模型提供可用的数据,机器学习和数学建模涉及比较少,这些工作主要由数据科学家来做。如果你想成为一名数据工程师,建议优先考虑学习 Apache Kafka 而不是 NoSQL,Apache Kafka 现在非常热门。
如果想成为「数据科学家」,可以看看这张数据科学维恩图。简单来说,数据工程师是一个多领域交叉的岗位,你需要懂数学/统计学、编程以及你专业方面的知识。
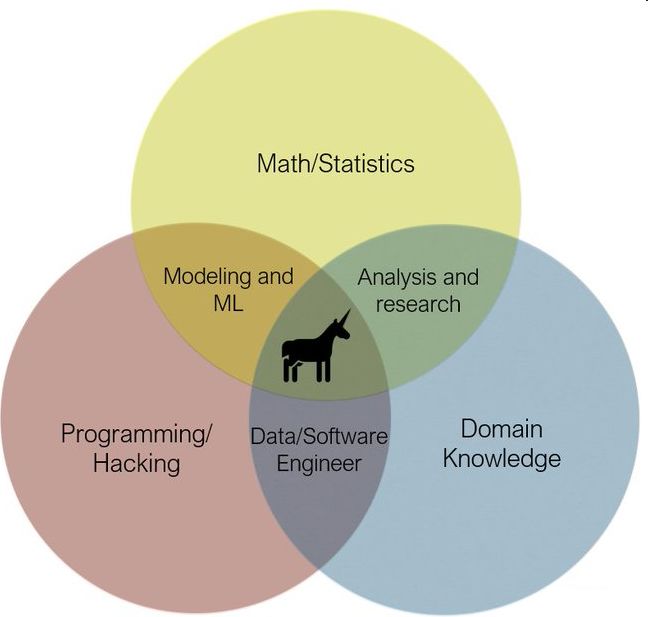
Q:好吧,我不知道我现在是想成为数据科学家还是数据工程师。回过头来,为什么要抓维基百科页面呢?
A:抓取下来的页面数据,可以作为自然语言处理的输入数据,之后就可以做一些事情,如创建聊天机器人。
Q:我暂时应该不用接触自然语言处理、聊天机器人、非结构化文本数据这些吧?
A:不用但值得关注,像 Google 和 Facebook 这些大公司,目前在处理大量非结构化数据(如社交媒体帖子和新闻文章)。除了这些科技巨头,大部分人仍然在使用关系数据库形式的业务运营数据,使用着不是那么前沿的技术,比如 SQL。
Q:是的,我猜他们还在做挖掘用户帖子、电子邮件以及广告之类的事情。
A:是的,你会发现 Naive Bayes 有趣也很有用。获取文本正文并预测它所属的类别。先跳过这块,你目前的工作是处理大量表格数据,是想做一些预测或统计分析么?
Q:对的,我们终于回到正题上了,就是解决实际问题,这是神经网络和深度学习的用武之地吗?
A:不要着急,如果想学这些,建议从基础开始,比如正态分布、线性回归等。
Q:明白,但这些我仍然可以在 Excel 中完成,有什么区别?
A:你可以在 Excel中 做很多事情,但编程可以获得更大的灵活性。
Q:你说的编程是像 VBA 这样的么?
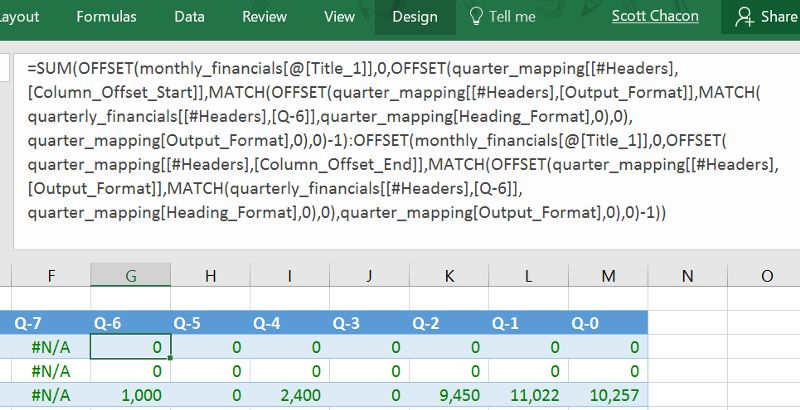
A:看来我需要从头说了。Excel 确实有很好的统计运算符和不错的线性回归模型。但如果你需要对每个类别的项目进行单独的正态分布或回归,那么使用 Python 要容易得多,而不是创建一长串的公式,比如下面这样,这会让看公式的人无比痛苦。除此之外,Python 还有功能强大的 scikit-learn 库,可以处理更多的回归和机器学习模型。
Q:这需要涉及到数学建模领域是吧,我需要学习哪些数学知识?
A:从线性代数开始吧,它是许多数据科学的基础。你会处理各种矩阵运算、行列式、特征向量这些概念。不得不说,线性代数很抽象,如果你想要得到线性代数的直观解释,3Blue1Brown 是最棒的。
Q:就是作大量的线性代数运算?这听起来毫无意义和无聊,能举个例子么?
A:好吧,机器学习中会用到大量的线性代数知识,比如:线性回归或构建自己的神经网络时,会使用随机权重值进行大量矩阵乘法和缩放。
Q:好吧,矩阵与 DataFrame 有什么关系?感觉很相似。
A:实际上,我需要收回刚才说的话,你可以不用线性代数。
Q:真的吗?那我还要不要学习线性代数?
A:就目前而言,你可能不需要学习线性代数,直接使用机器学习库就行,比如 TensorFlow 和 scikit-learn 这些库,它们会帮助你自动完成线性代数部分的工作。不过你需要对这些库的工作原理有所了解。
Q:说到机器学习,线性回归真的算是机器学习吗?
A:是的,线性回归是机器学习的敲门砖。
Q:真棒,我一直在 Excel 中这样做,那我是不是也可以自称「机器学习从业者」?
A:技术上来说是的,不过你需要扩大知识面。机器学习通常有两个任务:回归或分类。从技术上讲,分类是回归。决策树、神经网络、支持向量机、逻辑回归以及线性回归,这些算法都在做某种形式的曲线拟合,每种算法各有优缺点。
Q:所以机器学习只是回归?它们都有效地拟合了曲线?
A:差不多,像线性回归这样的一些模型清晰可解释,而像神经网络这样更先进的模型定义是复杂的,并且难以解释。神经网络实际上只是具有一些非线性函数的多层回归。当你只有 2-3 个变量时,它可能看起来不那么令人印象深刻,但是当你有数百或数千个变量时它就开始变得有趣了。
Q:那图像识别也只是回归?
A:是的,每个图像像素基本上变成具有数值的输入变量。你必须警惕维度的诅咒,变量(维度)越多,需要的数据越多,以防变得稀疏。这是机器学习如此不可靠和混乱的众多原因之一,并且需要大量你没有的标记数据。
Q:机器学习能解决安排员工、交通工具、数独所有这些问题吗?
A:当你遇到这些类型的问题时,有些人会说这不是数据科学或机器学习而是运筹学。
Q:这对我来说似乎是实际问题。运营研究与数据科学无关?
A:实际上,存在相当多的重叠。运筹学已经提供了许多机器学习使用的优化算法。它还为常见的 AI 问题提供了许多解决方案。
Q:那么我们用什么算法来解决这些问题呢?
A:绝对不是机器学习算法,很少有人知道这一点。几十年前就有更好的算法,树搜索、元启发式、线性规划和其他运算研究方法已经使用了很长时间,并且比机器学习算法对这些类别的问题做得更好。
Q:那为什么每个人都在谈论机器学习而不是这些算法呢?
A:因为很长一段时间里,这些优化算法问题已经有了令人满意的解决方案,但自那时起就一直没有成为头条新闻。几十年前就出现了这些算法的 AI 炒作周期。如今,AI 炒作重新点燃了机器学习及其解决的问题类型:图像识别、自然语言处理、图像生成等。
Q:所以使用机器学习来解决调度问题,或者像数独一样简单的事情时,这样做是错误的吗?
A:差不多,机器学习,深度学习这些今天被炒作的任何东西通常都不能解决离散优化问题,至少不是很好,效果非常不理想。
Q:如果机器学习只是回归,为什么每个人都对机器人和人工智能,这么忧心忡忡,认为会危害我们的工作和社会?我的意思是拟合曲线真的那么危险吗?AI 在进行回归时有多少自我意识?
A:人们已经找到了一些巧妙的回归应用,例如在给定的转弯上找到最佳的国际象棋移动(离散优化也可以做)或者计算自动驾驶汽车的转向方向。但是大多都是炒作,回归只能干这些事。
Q:好吧,我要散个步慢慢消化下。我目前的 Excel 工作感觉也算「数据科学」,但数据科学家这个名头有点虚幻。
A:也许你应该关注一下 IBM。
【本文作者】
苏克,数据分析师,从事 python爬虫与数据分析。个人公众号「高级农民工」
觉得本文对你有帮助?请分享给更多人
关注「Python开发者」加星标,提升Python技能

喜欢就点一下「好看」呗~








