如今的AI已经能够在Dota2这样的对战游戏中战胜人类了,但游戏主播和解说却不需要担心自己失业,因为当前的神经网络还无法解释自己为何做出决定。我们可以训练另一个神经网络,对前一个神经网络做出的每一个决定,来预测人类会给予其什么样的解释。还拿Dota2举例子,可以训练一个神经网络,对操作游戏的AI点的每一个技能,买的每一个装备,去猜测人类会给予怎么解释。但当AI进化出人类想不到的策略时,就像围棋中Alpha Go已经能够走出人类棋手想不出的套路,上述策略就不行了。

本文是《Possible Mind》(点击查看相关的读书笔记)系列读书笔记的第三篇,围绕因果推理的创始人,《The book of why》的作者Judea Pearl的题为“The limitation of opaque machine learning”,延伸而写成。当前神经网络缺少解释性,其成功的原理是如魔法一般的黑盒子。当前提升模型解释性的方法,无论是注意力机制,对模型进行压缩,用线性的浅层的模型来模拟深层的模型,还是对隐藏层的权重可视化展示,都只是隔靴搔痒,无法带来质变。本文基于Judea Pearl的随笔以及他去年12月的一篇论文整合而成,先说明可解释的重要性,再讨论因果推理带来的本质改变,再详述因果推理对深度学习带来的八大助力。

当扫地机器人遇到上图的情况,卡住了,如果其内部的AI能够正确的给出为何会卡住的解释,那下次机器人就会避免不平的环境,不管造成不平的是地毯还是掉在地上的衣物,这就提高了模型的可扩展性。能够给出解释,还可以帮助人更好与AI协作,假设每次扫地机器人能够告诉人自己今天因为那种原因卡住了,从而多花了多少分钟才扫完屋子,那这家的主人就可以下一次避免让家里出现地面不平的情况,从而让机器人能够更高效的工作,节约能源。而机器具有因果推理后,还会学到是自己清扫地毯的角度,使得地毯打折从而使得地面不平的,从而下次用其他的角度去清扫地毯覆盖的地方。
这些都是实际的好处,而在《Possible mind》这本书中,借用哲学家Stephen Toulmin在1961年的书《Foresight and Understanding》中的对比,引入了巴比伦和雅典科学的区别,同样是预测天体的运行,四季的节律,巴比伦的预测在精确程度和一致性上都好过同时代的雅典人,但雅典的预测背后有神话去提供解释,并且当一种解释比另一种解释更符合时,前者会战胜后者,巴比伦式的精准预测,没有带给这个文明天文学,而古希腊则孕育了现代科学。
类似的还有李约瑟之问,为何古代中国没有发展出科学,尽管其很长的一段时间中技术是领先全球的。比如勾股定理,明明中国人早在《周髀算经》中就有所记录,但西方人却称之为毕达哥拉斯定理。这里的区别在于前者只是从经验的层面记录了这个现象,而后者是对此给予了普遍化的证明。用机器学习的视角来看,前者无法确定这个规律的可扩展性如何,而后者保证了在所有的宇宙中,该规律都是适用的。
借用这个对比,当前的深度学习,尽管取得了突飞猛进的进展,但由于其缺少可解释性,不透明,还是属于巴比伦式的。即使其在所有的游戏上,都战胜了人类,都需要花更少的能源即时间去训练,也不能算是能匹敌人脑的强人工智能。雅典的天文学者,可以根据自己的理论,去设计一个实验,来估算地球的半径,还和真实的结果相差不多,而巴比伦式的不透明的“天文知识”,则根本不会问出这样的问题。当今的大数据,不会用虚假的概念来讲故事,而根据《人类简史》中的论述,正是想象出的共同体,使得人类走进了文明时代。
按照Judea Peral的分类,认识世界分三个层次,最低的是关联,只需要观察就好,例如那些症状告诉医生这个人患病了,那些行为告诉我这个人容易被促销打动;再上一层是干预,也就是去通过行为去改变世界之后,看会发生什么,这个层次要回答的问题是吃药能不能治病,而最高的层次是反事实的推理,要达到这一层,需要想象力,需要反思,要回答的问题是如果我之前多一些锻炼,现在是不是就不会生病。

当前的有监督学习,是站在了认知阶梯的第一层,强化学习由于和坏境有所互动,是站在了第二层上,通过无监督学习,去预测下一秒会发生什么,根据类比来推测位置的情况,也是介于第一层和第二层之间的。不论是那种学习范式,都是基于统计的,得出的结论是概率性的。正如同不懂得证明勾股定理,永远也无法百分之百打包票说这个规律是普世的,当前基于统计的机器学习,如同三体中被智子锁死的地球科技,看似进步神速,但总会碰到天花板。
Judea Pearl给出的解药是他发明的公理化式的因果推理图,想要详细了解的推荐下面的免费课程,edx平台上的,名为Causal Diagrams: Draw Your Assumptions Before Your Conclusions。
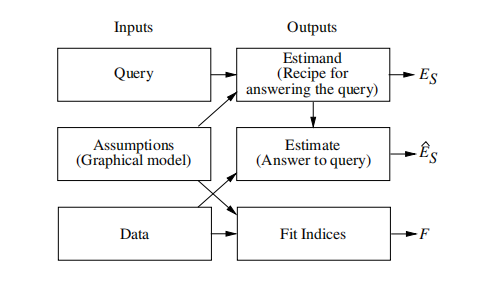
那如何机器学习在中加入因果推理了?回答是结构化因果模型(Structural Causal Models,下文简称SCM),通过有向图的形式,对常识中的因果作用方向的假设做结构化的建模,例如下图中x代表是否采取实验疗法,y代表从癌症中康复,z代表性别,那么对世界的模型就是性别可以决定一个人是否更可能会选择实验疗法,是否更容易从癌症中康复,但反方向的因果却是不现实的。

有了因果图,那SCM就可以根据提问,来计算一个和因果推理的问题,究竟有多少数据的支持,不管这个问题位于上述的认知阶梯的第几层,都能够给予回答。这里的 ,也就是考虑不同性别下是否采取实验疗法对癌症康复的概率,而根据深度学习的模型,可以估算出真实的状况下的概率,如果发现俩者的差距很大,那因果推断的模型就可以对实验疗法导致癌症康复这个因果论断给予反驳,说明这是没有事实依据的,而不是只说明实验疗法和癌症治愈缺少统计显著性。
,也就是考虑不同性别下是否采取实验疗法对癌症康复的概率,而根据深度学习的模型,可以估算出真实的状况下的概率,如果发现俩者的差距很大,那因果推断的模型就可以对实验疗法导致癌症康复这个因果论断给予反驳,说明这是没有事实依据的,而不是只说明实验疗法和癌症治愈缺少统计显著性。
那这对于解决当前机器学习缺少解释性的问题,又什么本质的改变了?这里列出Judea Pearl的八条回答:
首先是让机器做的假设以人类容易理解的方式(因果图)呈现出来,从而让模型更加透明,也让测试模型的推论的后人能够更精准的去检验模型的鲁棒性。可以说只有能够解释清楚自己每一步的推理的逻辑,模型才算具有了可证伪性,否则即使有一个不符合模型预测的事件,由于不确定其和模型的因果假设有什么关系,又该怎么区分这究竟是应该被去除的噪音还是能推翻整个认知模型的反例。
第二点是通过因果推断,去除混杂因素的影响。当前的机器学习,重要先进性数据清洗,特征提取,往往花在特征工程上的时间占到了全流程的大头。有了因果推断,就不必人,来根据常识去掉那些可能影响相关性的混杂因素,从而在更复杂的坏境下,做到端对端的学习。这使得模型能够超越建模者的认知局限,从而模拟真实坏境更复杂的相互作用。
第三点是算法化的回答反事实的问题。人类能够区分出充分条件和必要条件,能区分cause of effect与effect of cause,例如小明酒后游泳溺水而死,游戏是小明死亡的必要而不是充分条件,要回答这样的问题,就需要进行反事实的思考,去幻想如果小明没有游泳会怎样,如果游泳时小明没有喝酒会怎样。如果机器能够做这样的思考,那AI思考的模块化程度就会进一步提高,需要的训练数据也会减少,对于跨领域的迁移学习也会有所助力。
第四个助力是区分直接和间接的诱因,如果只有关联分析,那在较长的时间尺度上,就会面临如何区分是否之前的决定带来了奖励的问题,但如果能够将因果关系描述出来,并且根据数据来评价每一条因果链条的坚固程度,那就能够去解决强化学习中在较长的时间尺度上,该如何分配奖励的问题。区分了直接的诱因与通过第三方作用间接的影响,就能够判定数据中那些异常点处在间接影响的链条上,受到未知因素的影响,属于噪音,而对于处于直接因果链条上的,则异常不应该被视作是噪音,而是可以证伪模型的“黑天鹅”。
第五个助力是模型具有跨领域的适用性,还能够通过其他领域来验证该模型的鲁棒性。如果一个通过强化学习的智能体在一种游戏中表现优异,那预期换一个游戏,该模型也不会表现的太差,这种能力被称为domain adaptation,人类就有这个能力,例如dota玩的好的人,玩英雄联盟也不差。如果智能体是通过因果推理,来决定下一回合的policy,那这个思考过程就更像人类做决定时的所思所想,由此类比推出,智能体也会具有更好的domain adaptation。
第六个助力避免sampling bias,正如人类的认知偏见会让人丢掉那些对支持自己结论不适合的数据,人类在对机器建模时,也会展现出类似的认知偏见。如果机器具有了公理化的因果推理,那通过反事实的问题,就可以指出人类可能受到了采样偏见的影响。这指出了人机协作的新的可能性,不是机器只懂得找出相关性,从而指数级的放大人的认知偏见,而是机器根据人对世界的建模,去帮助人做人类不擅长的用数据找出偏见,从而带来一个更公平的模型。
第七个助力是通过因果模型,来判定数据集中是否存在数据缺失的问题。例如建模者以为女性不擅长数学,那用来训练该录取那个学生的分类器时女性申请者的样本就会很少,从而使得基于统计相关的模型预测女生不应该录取到数理相关的专业。但对于基于因果判定的模型,那只要对世界的假设中包含性别会影响是否报名数理相关专业这个因果联系,那模型就能够根据数据判定出这里存在着可能的数据缺失,从而提醒建模者注意。
第八个助力是去发现因果关系,例如遗传学中的孟德尔随机,就是利用了基因在有性生殖中自然会发生重组,来区别到底基因的差距与人身体表现出来的胖瘦高矮这样的表型到底是因果性还是相关性。现实中存在着诸多类似孟德尔随机的自然形成的与随机双盲实验等价的场景,通过让模型具有因果推断能力,就能够发现未知的因果关系。
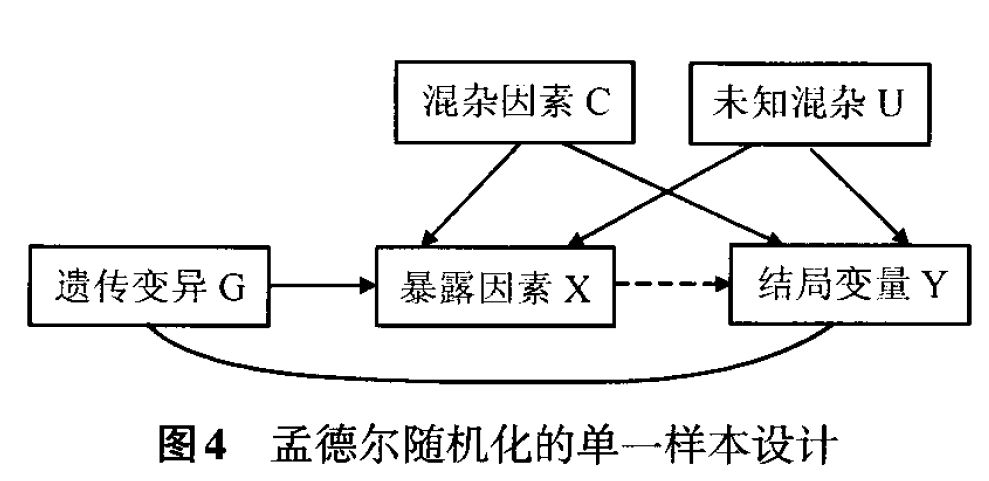
附图是孟德尔随机的示意图
总结全文,当前的深度学习,这样model free的模式,无法达到人类水平的智力,只有增加了因果推断,才能像科学的精神孕育出持续不断的发现那样,让机器学习走到之前无法企及之地,例如上文列出的八种具体任务,都需要更高层次的思考。当前的深度学习,模型缺少解释性,可迁移性,也不够鲁棒,会由于一个像素的改变而彻底改变分类的结果。所有的指数级增长都会有尽头,当前深度学习取得的成就,大多只是依赖计算资源和训练数据的指数化增加,只有不断站在更高的认知阶梯,通过自我指称获得的递归式的思考,才是无限的增长模式。因此将因果模型引入下一代人工智能中,是充分且必要的。
需要注意的是,因果推断的模型,依赖与建模者去根据常识或本领域背景,给定对因果关系运行的方向,如果这个假设有问题,那模型是无法从数据中发现人类建模者犯了因果倒置的问题的,这说明不管多么先进的模型,都需要建模者的智慧参与其中。
参考文献:The Seven Tools of Causal Inference with Reflections on Machine Learning
更多阅读
信息的俩种定义
如何让神经网络具有好奇心
读《Possible Mind》,看25位大咖谈AI






