

来源:Medium
本文转自公众号 新智元
【导读】统计学和机器学习的真正差别。统计学和机器学习在很多情况下是被混淆的,大部分人其实并不能很好的区分二者。介于此,本文详解的讲解了二者实际的差异,非常有指导意义。
很多人并不能很好的区分统计学和机器学习,因为之间确实有太多的相同之处。目前流行的一种说法是,机器学习和统计学之间的主要区别在于它们的目的:机器学习模型旨在使最准确的预测成为可能;统计模型被设计用于推断变量之间的关系。
这种说法在技术上来说没有问题,但它没有给出特别明确或令人满意的答案。说机器学习是关于准确的预测,而统计模型设计用于推理几乎是无意义的陈述,除非你精通这些概念。
因为统计数据和统计模型是不一样的。统计学是数据的数学研究,没有数据就无法进行统计;统计模型是数据的模型,用于推断数据中的关系或创建能够预测未来值的模型。通常,这两者是相辅相成的。
实际上,我们需要讨论两件事:首先,统计数据与机器学习有何不同?其次,统计模型与机器学习有何不同。所以今天,我们就来详细解读一下二者的区别。
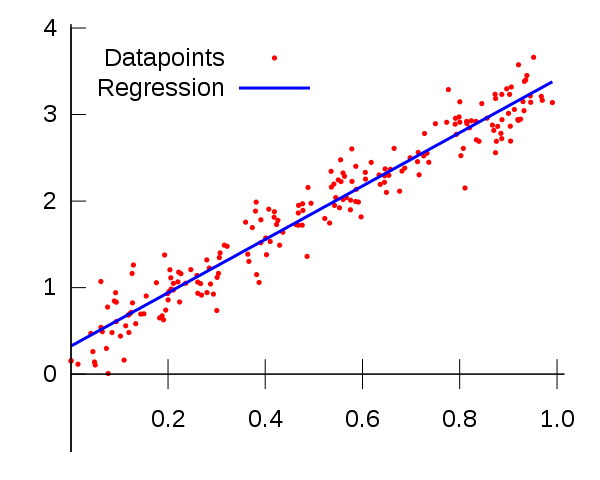
可能因为统计建模和机器学习中使用的方法的相似性,使人们认为它们是同一个东西。可以理解,但根本不是这样。
最明显的例子是线性回归,这可能是造成这种误解的主要原因。线性回归是一种统计方法,我们训练线性回归量并获得与统计回归模型相同的结果,旨在最小化数据点之间的平方误差。
在一个案例中,我们做了“训练”模型的事情,其中涉及使用数据的一个子集。我们不知道模型将如何执行,直到在训练期间能够“测试”出此数据不存在的、被称为测试集的其他数据。在这种情况下,机器学习的目的是在测试集上获得最佳性能。
对于统计模型,我们只要找出可以最小化所有数据的均方误差(假设数据是一个线性回归量,加上一些随机噪声,本质上通常是高斯噪声),无需训练,也无需测试。
一般来说,特别是在研究中(例如下面的传感器示例),模型的要点是表征数据与结果变量之间的关系,而不是对未来数据进行预测。我们将此过程称为统计推断,而不是预测。但我们仍然可以使用此模型进行预测,但评估模型的方式不涉及测试集,而是涉及评估模型参数的重要性和稳健性。
(受监督的)机器学习的目的是获得可以进行可重复预测的模型。我们通常不关心模型是否可解释,机器学习只看重结果。而统计建模更多的是发现变量之间的关系和这些关系的重要性,同时也适合预测。
举例说明这两个程序之间差异。一名环境科学家主要研究传感器数据。如果试图证明传感器能够响应某种刺激(例如气体浓度),就会使用统计模型来确定信号响应是否具有统计显着性。
他会尝试理解这种关系并测试其可重复性,以便能够准确地表征传感器响应并根据这些数据做出推断。可能测试的一些事情包括实际上,响应是否是线性的?响应是否可以归因于气体浓度而不是传感器中的随机噪声?等等。
而同时,我们还可以获得20个不同传感器的阵列,可以用来尝试预测新近表征的传感器的响应。我们不认为一个预测传感器结果的20个不同变量的模型具备多少可解释性。由于化学动力学和物理变量与气体浓度之间的关系引起的非线性,这个模型可能会比神经网络更深奥。我希望这个模型有意义,但只要我能做出准确的预测就已经很不错了。
如果试图证明数据变量之间的关系达到一定程度的统计显著性,那么发论文的时候应该会使用统计模型而不是机器学习。这是因为我们更关心变量之间的关系,而不是做出预测。做出预测仍然很重要,但是大多数机器学习算法缺乏可解释性使得难以证明数据内的关系(这实际上是学术研究中的一个大问题,研究人员使用他们不理解和获得的算法似是而非的推论)。

这两种方法的目标不同,尽管使用的方法类似。机器学习算法的评估使用测试集来验证其准确性。统计模型可以使用置信区间,显着性检验和其他检验对回归参数进行分析,以评估模型的合法性。由于这些方法产生相同的结果,因此很容易理解为什么人们可能认为它们是相同的。
有一个误解存在了10年:仅基于它们都利用相同的基本概率概念这一事实,来混淆这两个术语是不合理的。
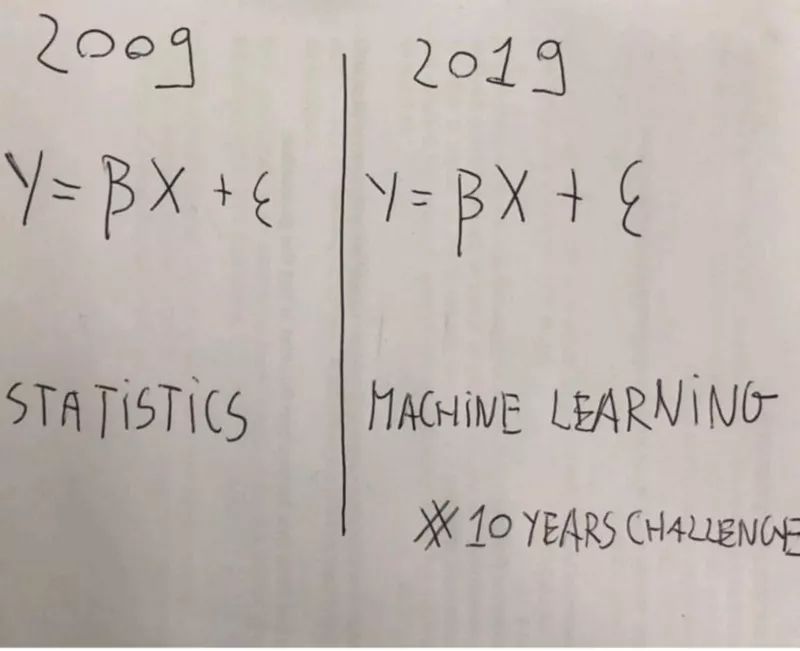
有人一种说法是,根据这个事实做出机器学习只是美化统计的陈述,我们也可以做出以下陈述:
物理学只是美化数学
动物学只是美化邮票收藏
建筑只是美化沙子城堡建筑
这些陈述(尤其是第三个)非常荒谬,所有这些陈述都基于这种混淆基于类似想法的术语的想法(用于架构示例的双关语)。
实际上,物理学是建立在数学基础之上的,它是数学应用于理解现实中存在的物理现象。物理学还包括统计学的各个方面,现代统计学的形式通常是由一个由Zermelo-Frankel集理论与测量理论相结合的框架构建,以产生概率空间。它们之间都有很多共同之处,因为都来自相似的起源,并应用类似的想法,来达成合乎逻辑的结论。同样,建筑和沙堡建筑也有很多共同点啊,但这两个显然不是一个概念。
还有两个与机器学习和统计相关的常见误解我们需要纠正一下,一个是混淆了数据科学和统计学;另一个是混淆了机器学习和人工智能。这些是AI与机器学习不同,数据科学与统计学不同。这些是相当无争议的问题所以它会很快。
数据科学 vs 统计学
数据科学本质上是应用于数据的计算和统计方法,这些方法可以是小型或大型数据集,也可以是探索性数据分析。数据被检查和可视化,以帮助科学家更好地理解数据,并从中做出推论。数据科学还包括数据争用和预处理等内容,因此还在某种程度上涉及到计算机科学,例如编码,在数据库,Web服务器等之间建立连接和pipe等。不一定非得使用计算机来进行统计,但如果没有计算机,就没法真正进行数据科学。所以,数据科学使用统计数据,但二者也显然不一样。
机器学习 vs 人工智能
机器学习跟人工智能不同。事实上,机器学习是人工智能的一个子集,这是非常明显的,因为我们正在“训练”一台机器,根据以前的数据对某些类型的数据做出可推广的推断。
在我们讨论统计和机器学习的不同之前,让我们首先讨论相似之处。我们已经在前几节中对此进行了一些讨论。
机器学习建立在统计框架之上。这应该是显而易见的,因为机器学习涉及数据,并且必须使用统计框架来描述数据。然而,统计力学也扩展到大量粒子的热力学,也建立在统计框架之上。压力的概念实际上是一个统计量,温度也是一个统计量。如果你觉得这听起来很荒谬可笑,但事实上确实如此。这就是为什么你无法描述分子的温度或压力,这是荒谬的。温度是分子碰撞产生的平均能量的表现。对于足够大量的分子,我们可以描述像房子或户外的温度。
你会承认热力学和统计学是一样的吗?不,热力学使用统计数据来帮助我们以运输现象的形式理解工作和热量的相互作用。
实际上,热力学是建立在除了统计之外的更多项目之上的。同样,机器学习也利用了大量其他数学和计算机科学领域,例如:
当你开始使用Python进行编码,剔除sklearn库并开始使用这些算法时,很多这些概念都被抽象出来,因此很难看出这些差异。
统计学与机器学习之间的主要区别在于统计学仅基于概率空间。从集合论中推导出整个统计数据,它讨论了我们如何将数字组合成类别,称为集合,然后对此集合强加一个度量,以确保所有这些的总和值为1,我们称之为概率空间。
除了这些集合和度量的概念之外,统计数据不对宇宙做任何其他假设。这就是为什么当我们用非常严格的数学术语指定概率空间时,我们指定了3个东西。
概率空间,我们这样表示,(Ω,F,P)由三部分组成:
机器学习基于统计学习理论。它仍然基于概率空间的这种公理概念。该理论是在20世纪60年代发展起来的,并扩展到传统统计学。
机器学习有几种类型,这里我们主要讲监督学习,因为它是最容易解释的。
根据监督学习的统计学习理论,一组数据,我们将其表示为S={(xᵢ,yᵢ)}。这是一个有n个数据点的数据集,每个数据点由我们称之为功能的其他一些值描述,这些值由x提供,并且这些特征由某个函数映射以给出值y。
假如说我们已经有了这些数据,我们的目标是找到将x值映射到y值的函数。可以描述此映射的所有可能函数的集合,称为假设空间。
要找到这个函数,我们必须让算法“学会”一些方法来找出解决问题的最佳方法,这个过程由损失函数实现。因此,对于我们所拥有的每个假设(建议函数),需要通过查看其对所有数据的预期风险值来评估该函数的执行情况。
预期风险基本上是损失函数乘以数据概率分布的总和。如果我们知道映射的联合概率分布,就很容易找到最佳函数。然而,这通常是未知的,因此我们最好的选择是猜测,然后凭经验确定损失函数是否更好。我们称之为经验风险。
然后,我们可以比较不同的函数,并寻找给出最小预期风险的假设,即假设给出数据上所有假设的最小值(称为下限)。
然而,该算法具有作弊的倾向,可以通过过度拟合数据来最小化其损失函数。这就是为什么在学习基于训练集数据的函数之后,该函数需要在测试数据集上进行验证,验证用的数据数据不会出现在训练集中。
显然,这不是统计学看重的点,因为统计学并不需要最小化经验风险。选择最小化经验风险的函数的学习算法称为经验风险最小化。
以线性回归的简单情况为例。在传统意义上,我们尝试将某些数据之间的错误最小化,以便找到可用于描述数据的函数。在这种情况下,常使用均方误差。我们将它调整为正负误差不会相互抵消。然后我们可以以封闭形式的方式求解回归系数。
如果将损失函数作为均方误差来执行统计学习理论所支持的经验风险最小化,最终得到的是与传统线性回归分析相同的结果。
这是因为两种情况是等价的,就像在同一数据上执行最大似然估计也会得到相同的结果一样。最大似然可以用不同的方式来实现同一目标,但没有人会说最大似然与线性回归相同,对吧。
另一个需要注意的是,在传统的统计方法中,并没有训练和测试集的概念。而是用度量来检查模型的执行方式。虽然评估程序不同,但两种方法都能够在统计上给出鲁棒的结果。
更进一步,传统的统计方法提供了最优解,因为解决方案具有封闭形式,它没有测试任何其它假设并收敛到解决方案。而机器学习方法则是尝试了一堆不同的模型,收敛到最终假设。
如果我们使用了不同的损失函数,结果就不会收敛。例如,如果我们使用铰链损耗(使用标准梯度下降不可微分,那么就需要其他技术,如近端梯度下降来解决问题),那么结果将不会相同。
当然,可以通过考虑模型的偏差来进行最终比较,比如要求机器学习算法测试线性模型,以及多项式模型,指数模型等,以查看这些假设是否更适合我们的先验损失函数。
这类似于增加相关的假设空间。在传统的统计意义上,我们选择一个模型就可以评估其准确性,但不能自动选择100个不同模型中的最佳模型。因为模型中总有一些偏差源于最初的算法选择。这是必要的,因为找到对数据集最佳的任意函数是NP难问题。
没有统计学就不会存在机器学习,但机器学习在当代非常有用,因为自信息爆炸以来人类,已经产生了大量数据。
在“到底应该选择机器学习还是统计模型”的问题上,很大程度上取决于目的是什么。如果只是想创建一种能够高精度地预测住房价格的算法,或者使用数据来确定某人是否可能感染某些类型的疾病,那么机器学习可能是更好的方法;如果试图证明变量之间的关系或从数据推断,统计模型可能是更好的方法。

还有就是,即使没有强大的统计学背景,也仍然可以掌握机器学习并应用在实际问题中。但基本的统计思想还是要有的,以防止模型过度拟合和给出似是而非的推论。
这里推荐几个不错的课程,可以让你对机器学习和统计学有更清晰的认识:
9.520/6.860: Statistical Learning Theory and Applications
http://www.mit.edu/~9.520/fall18/
该课程是以统计学家的角度来阐述机器学习
ECE 543: Statistical Learning Theory
http://maxim.ece.illinois.edu/teaching/spring18/index.html
参考链接:
https://towardsdatascience.com/the-actual-difference-between-statistics-and-machine-learning-64b49f07ea3

· 数据解读“猫奴”的人群画像 | 都是哪些人在吸猫?









