 标星★公众号 ♥你们
标星★公众号 ♥你们
▎作者:Alexandr Honchar
▎编译:yana | 公众号翻译部
近期原创文章:
优化是机器学习研究人员最有趣的领域之一。本文将告诉大家一些关于如何解决机器学习优化问题的方法,以及其他。
我们从简单的函数优化开始,然后转移到更复杂的函数,它们有多个局部最小值或者很难在约束优化和几何优化问题中找到最小值。使用完全不同的优化方法:从基于渐变的方法开始,并使用进化算法和前沿深度学习的最新思想。当然,也会出现机器学习应用程序,但真正的目标是在数值优化中展示大范围的问题和算法,并了解最受欢迎的AdamOptimizer() 真正发生的事情。
在本文中会有很多图片——对于零阶方法,Scipy的一阶,Tensorflow与一阶,二阶方法等。查看源代码在文末。
首先,定义一组函数。从最简单的那些开始,这应该非常容易优化,并展示使用不同工具的一般套路。可以在这里找到完整的函数和公式列表:

https://www.sfu.ca/~ssurjano/optimization.html
我们只选择了其中的一些。
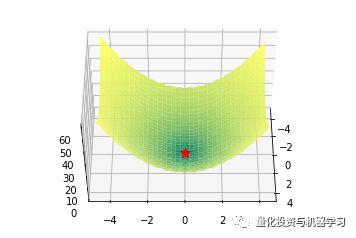
Bowl函数
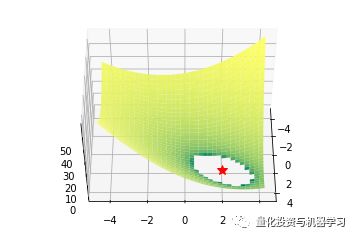
Bohachevsky函数和Trid函数
def bohachevsky(x, y):
return x**2 + 2*y**2 - 0.3*np.cos(3*3.14*x) - 0.4*np.cos(4*3.14*y) + 0.7
def trid(x, y):
return
(x-1)**2 + (y-1)**2 - x*y
Plate函数
Booth,Matyas 和 Zakharov 函数
def booth(x, y):
return (x + 2*y - 7)**2 + (2*x + y - 5)**2
def matyas(x, y):
return 0.26*(x**2 + y**2) - 0.48*x*y
def zakharov(x, y):
return (x**2 + y**2) + (0.5*x + y)**2 + (0.5*x + y)**4
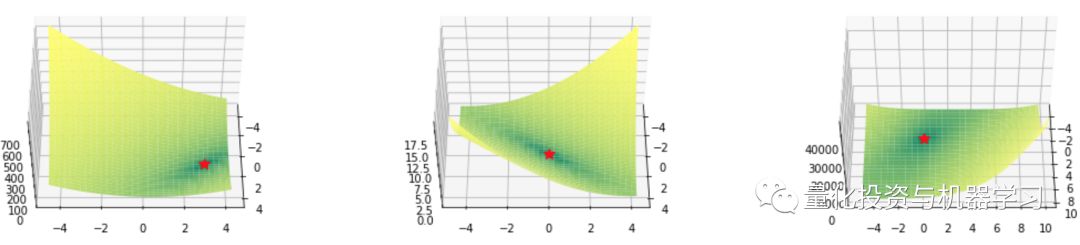
Booth (左),Matyas (中) 和 Zakharov (右) 函数
Valley函数
Rozenbrock, Beale 和 Six Hump Camel 函数
def rozenbrock(x, y):
return (1-x)**2 + 100*(y - x**2)**2
def beale(x, y):
return (1.5 - x + x*y)**2 + (2.25 - x + x*y**2)**2 + (2.65 - x + x*y**3)**2
def six_hump(x, y):
return (4 - 2.1*x**2 + x**4/3)*x**2 + x*y + (-4 + 4*y**2)*y**2
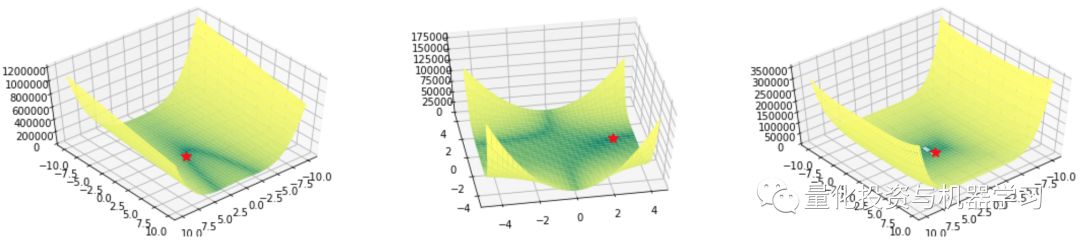
在本章节,我们将简要介绍SciPy和Tensorcow的基本优化算法。
没有梯度的优化
通常我们的成本函数是有噪音的,或者是不可微的,所以在这种情况下,我们不能应用使用梯度方法。在本教程中,我们将比较不计算梯度的Nelder-Mead和Powell算法。第一种方法构建(n + 1)维单形并在其上找到最小值,并按序更新单形。Powell方法对空间的每个基矢量进行一维搜索。使用SciPy实现它们:
minimize(fun, x0, method='Nelder-Mead', tol=None,callback=make_minimize_cb)
部分代码展示,原文获取全部代码
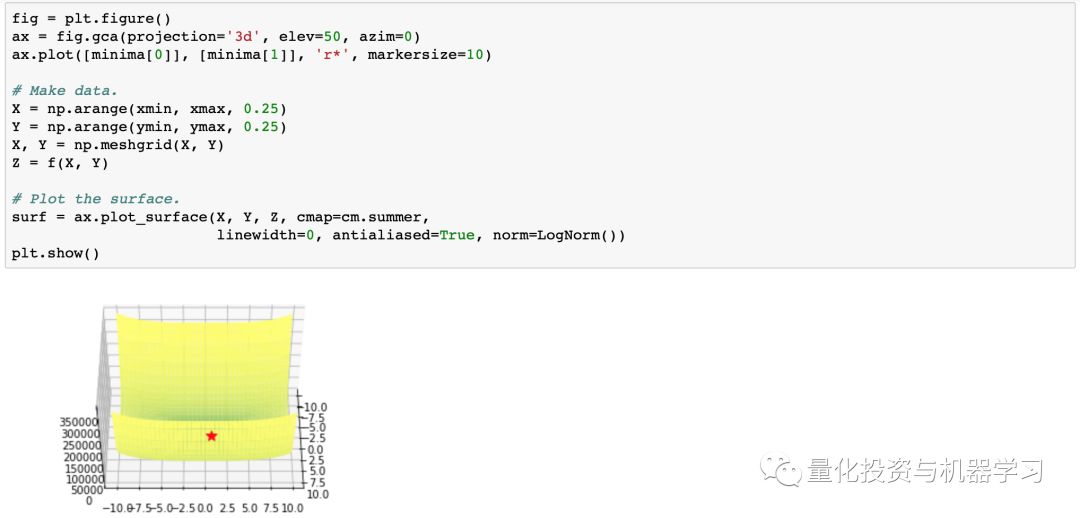
一阶算法
可能从Tensorflow等机器学习框架中了解到这一系列算法。所有这些背后的想法是朝着反梯度的方向发展,这导致函数的最小化。但转向这个极小的细节差异很大。我们将从Tensorflow回顾以下内容:有动量(和没有动量)的梯度下降,Adam和RMSProp。我们将定义这样的TF函数:
x = tf.Variable(8., trainable=True)
y = tf.Variable(8., trainable=True)
f = tf.add_n([
tf.add(tf.square(x), tf.square(y)),
tf.square(tf.add(tf.multiply(0.5, x), y)),
tf.pow(tf.multiply(0.5, x), 4.)
])
部分代码展示,原文获取全部代码

并按照以下方式优化:
opt = tf.train.GradientDescentOptimizer(0.01)
grads_and_vars = opt.compute_gradients(f, [x, y])
clipped_grads_and_vars = [(tf.clip_by_value(g, xmin, xmax), v) for g, v in grads_and_vars]
train = opt.apply_gradients(clipped_grads_and_vars)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
points_tf = []
for i in range(100):
points_tf.append(sess.run([x, y]))
sess.run(train)
我们将使用SciPy的共轭梯度,牛顿共轭梯度,截断式牛顿,有序最小二乘编程方法。可以在Stephen Boyd和Lieven Vandenberghe的免费在线书籍中阅读有关此类算法的更多信息。在下文中,有机器学习优化的另一个很酷的比较方式
二阶算法
我们还将触及几种使用二阶导数的算法,以实现更快的收敛:dog-leg置信区域,十分精确的置信区间。这些算法依次解决子优化任务,其中找到了搜索区域(通常是球体)。我们知道,这些算法需要Hessian(或其近似值),因此我们将使用numdifftools库来计算它们并传递给SciPy优化器。
from numdifftools import Jacobian, Hessian
def fun(x):
return (x[0]**2 + x[1]**2) + (0.5*x[0] + x[1])**2 + (0.5*x[0] + x[1])**4
def fun_der(x):
return Jacobian(lambda x: fun(x))(x).ravel()
def fun_hess(x):
return Hessian(lambda x: fun(x))(x)
minimize(fun, x0, method='dogleg', jac=fun_der, hess=fun_hess)
灵感来自此处:
https://stackoverflow.com/questions/41137092/jacobian-and-hessian-inputs-in-scipy-optimize-minimize
部分代码展示,原文获取全部代码

在这本章节,我们想先从视觉角度评估结果,先用肉眼看轨迹是非常重要的,毕竟公式会更清晰。
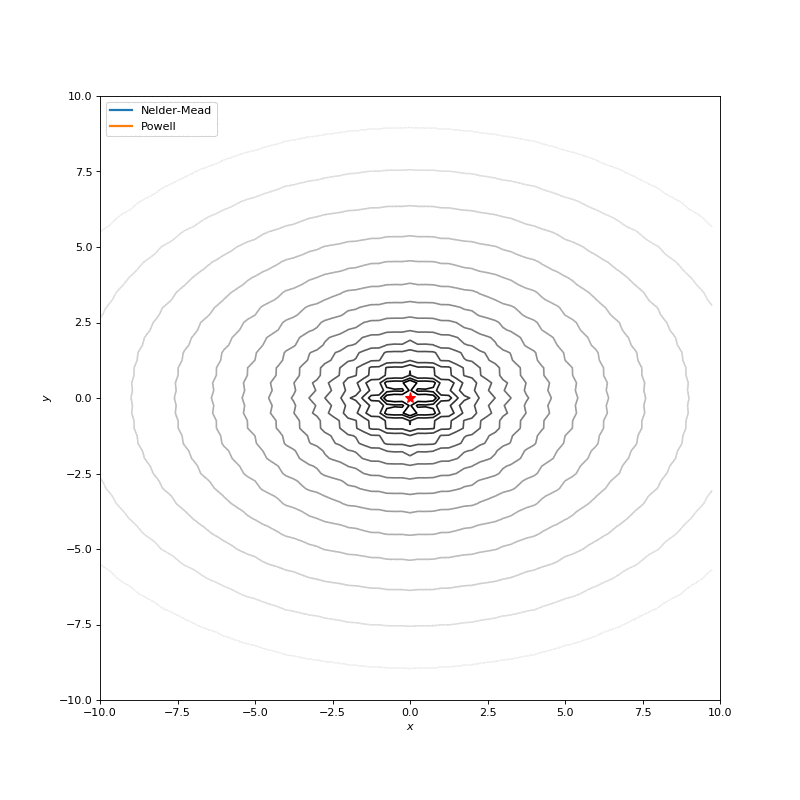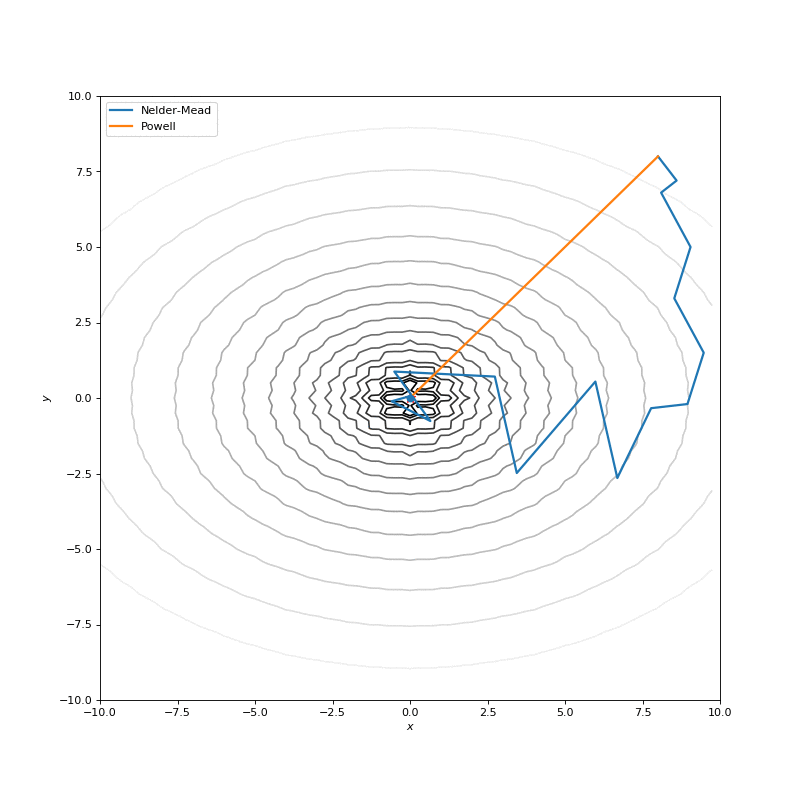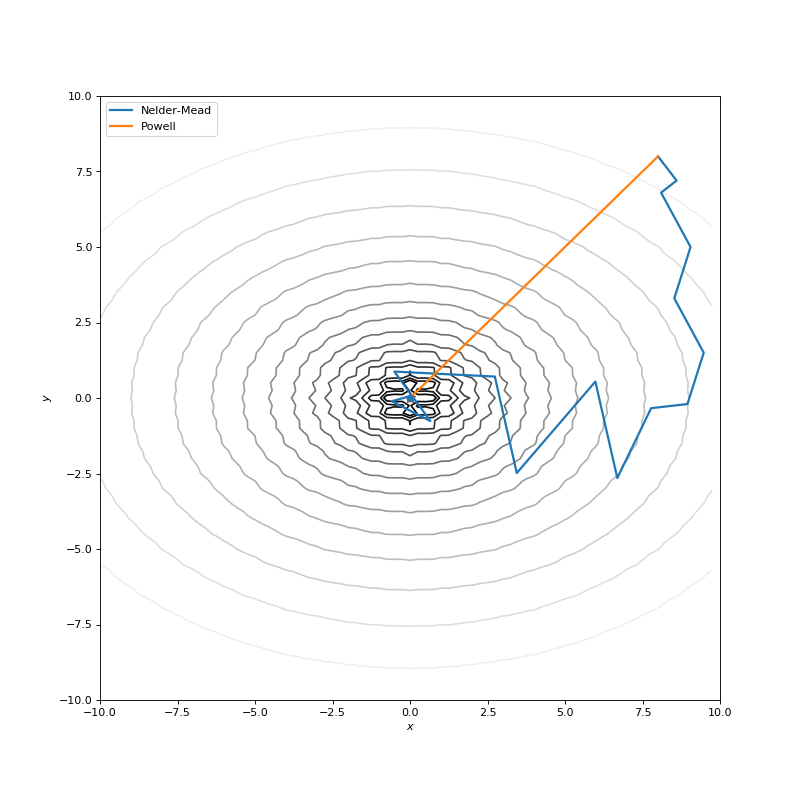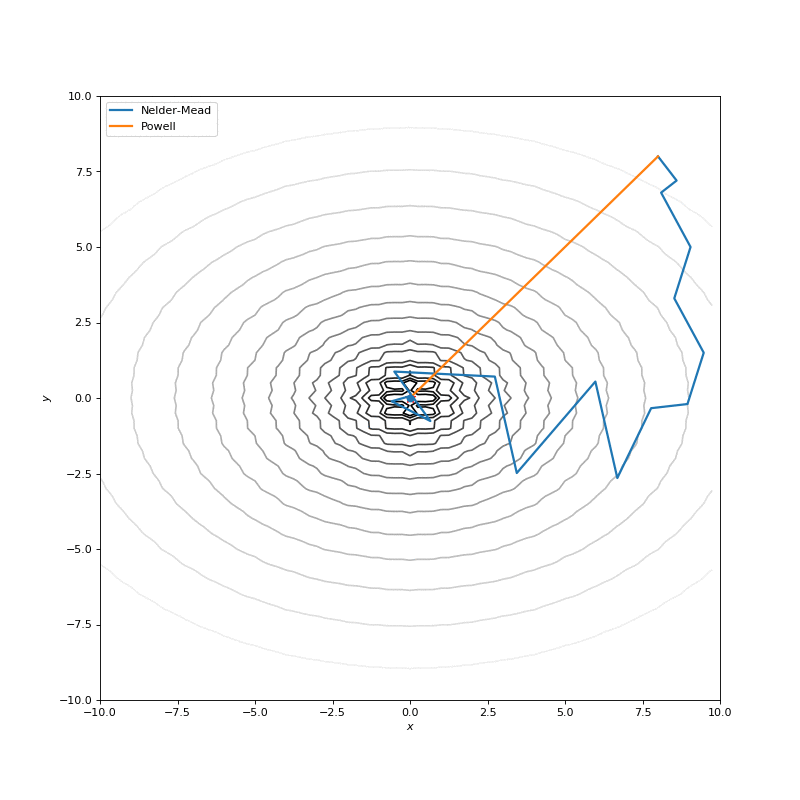
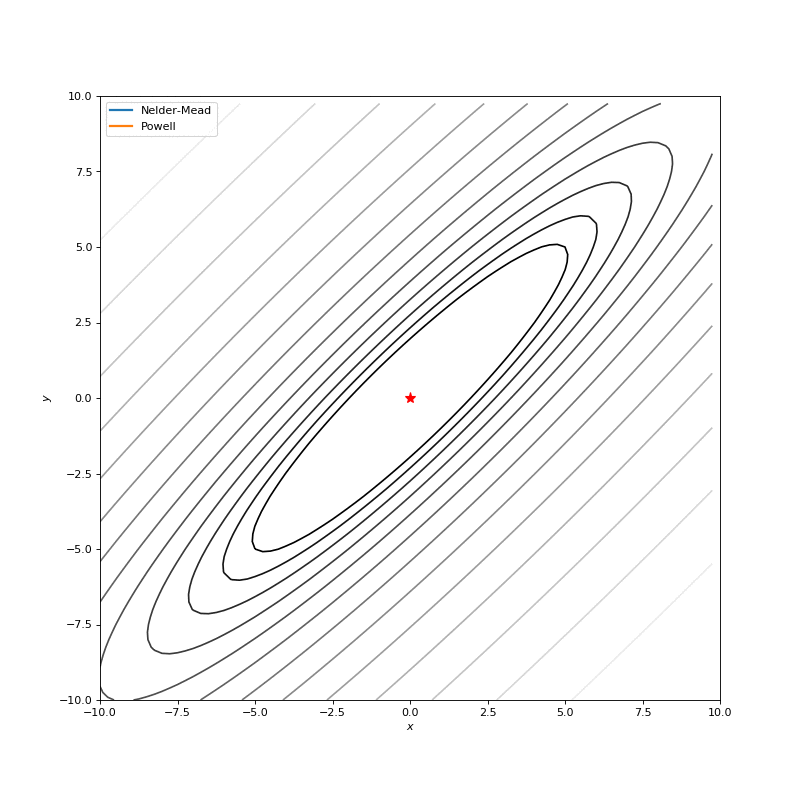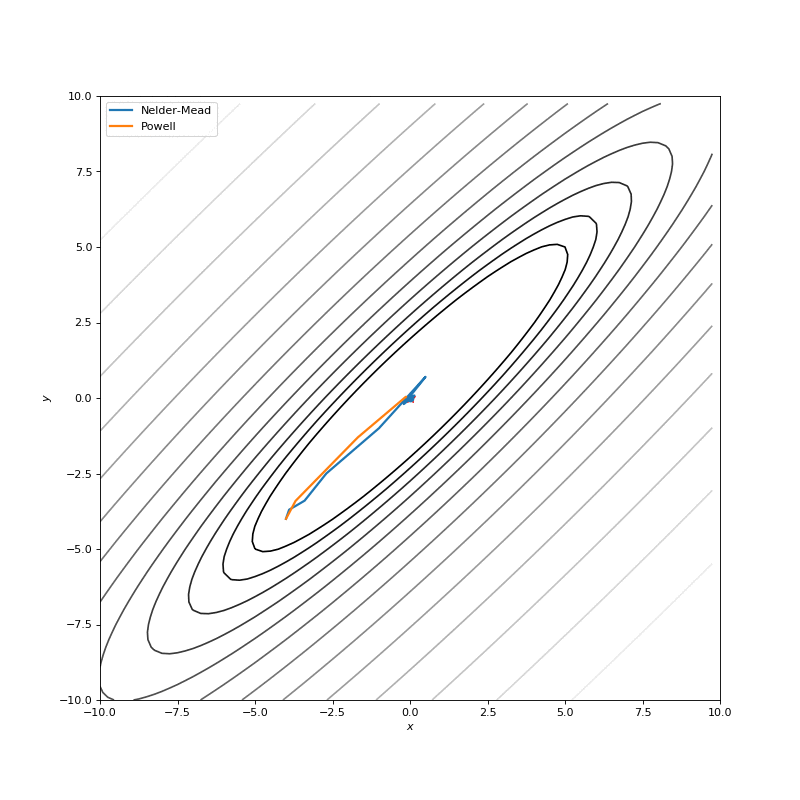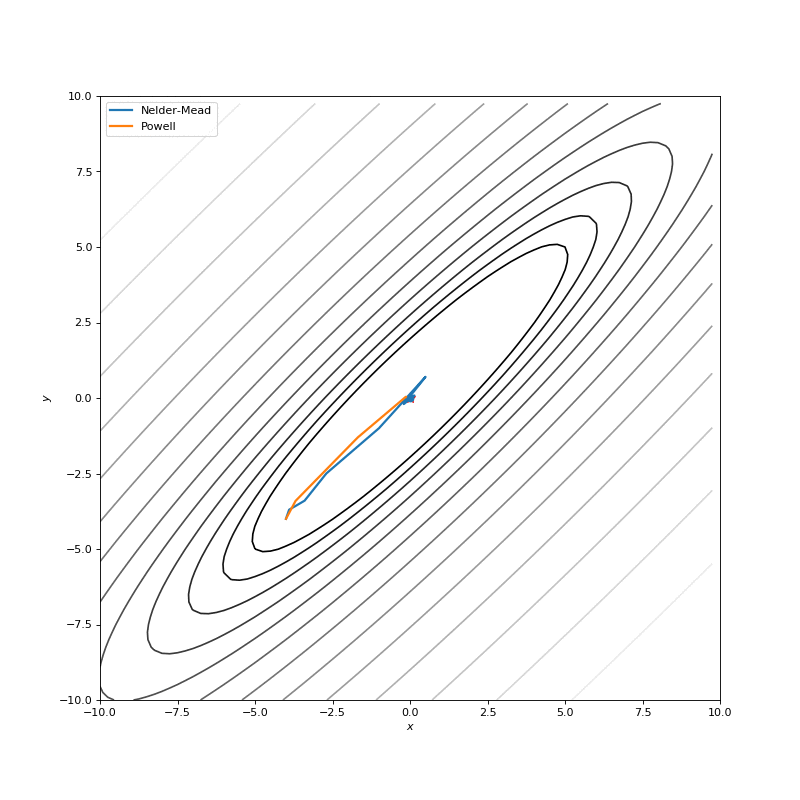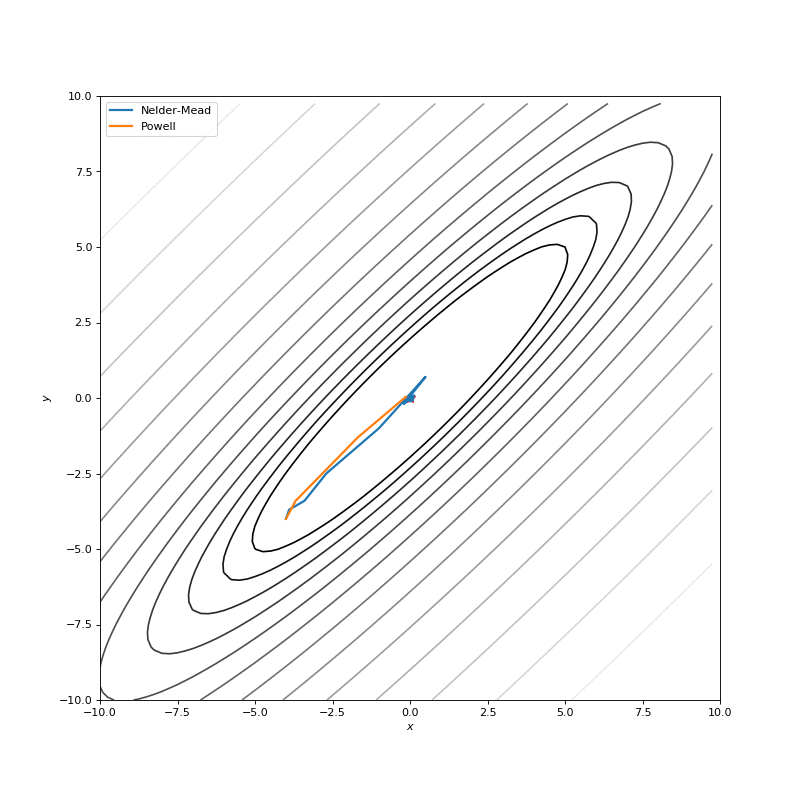
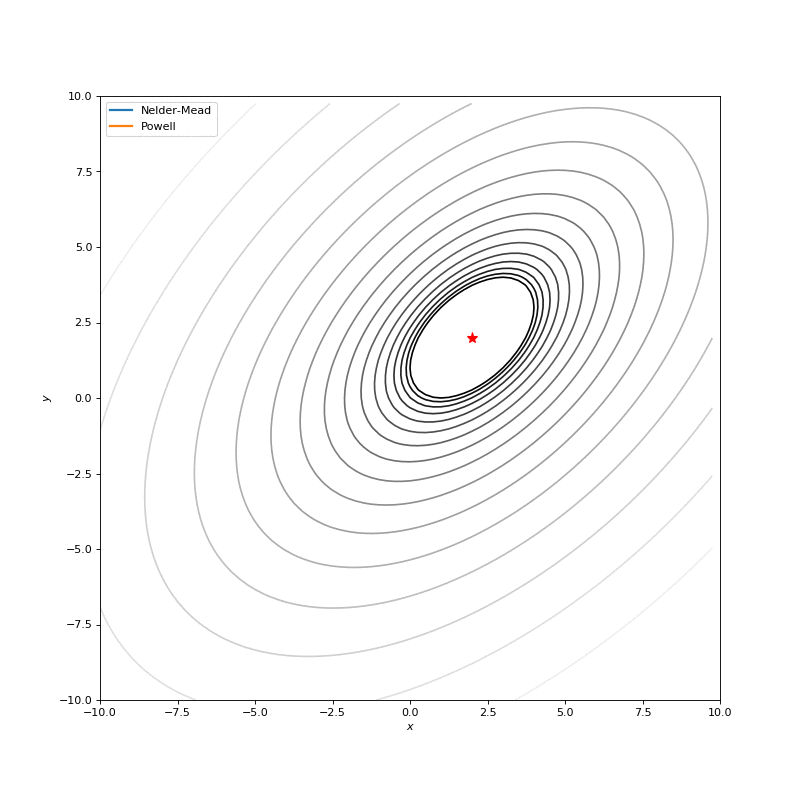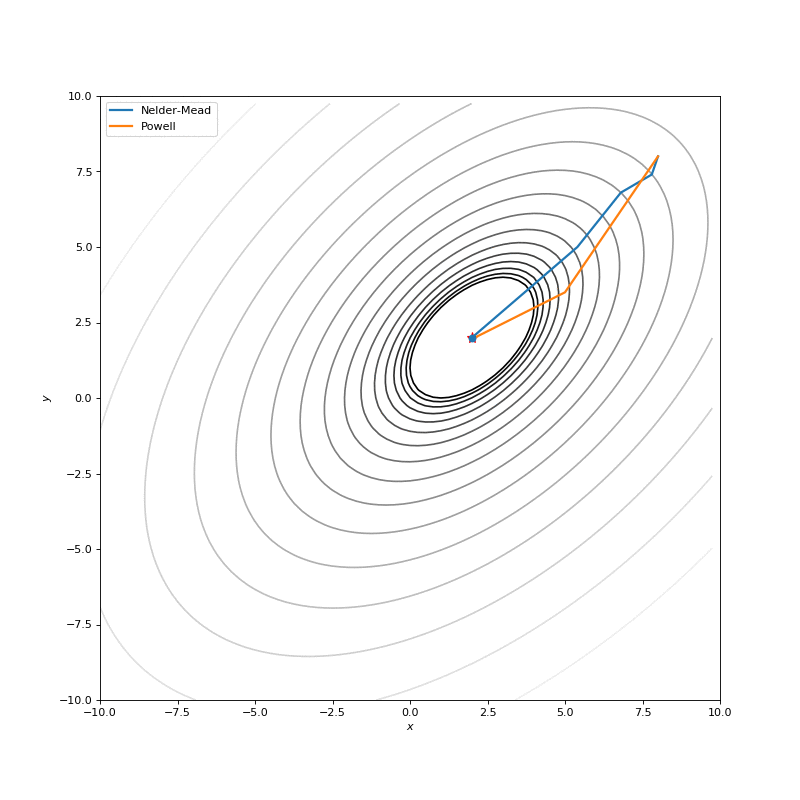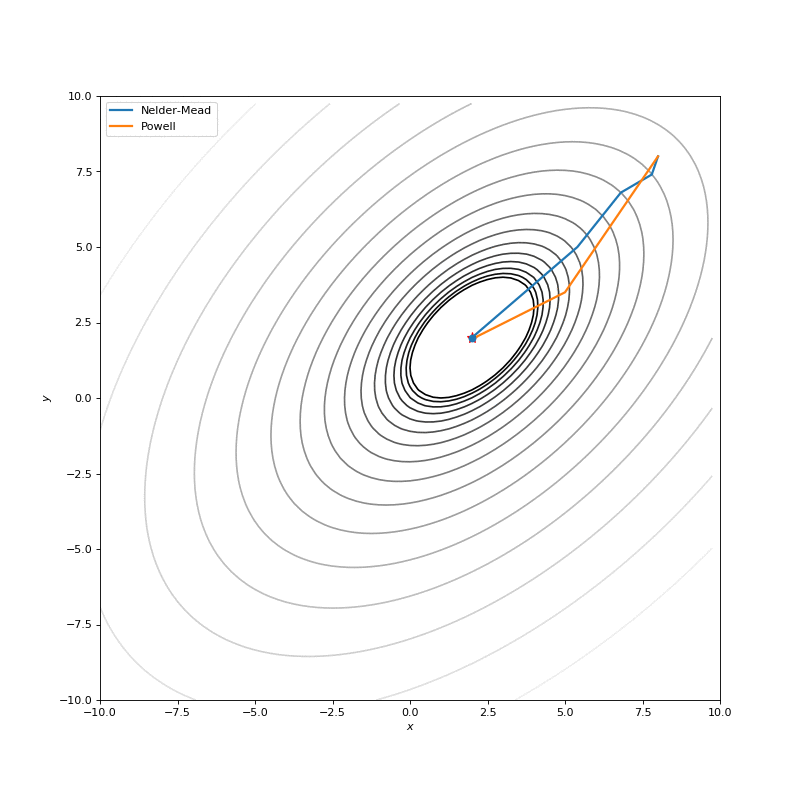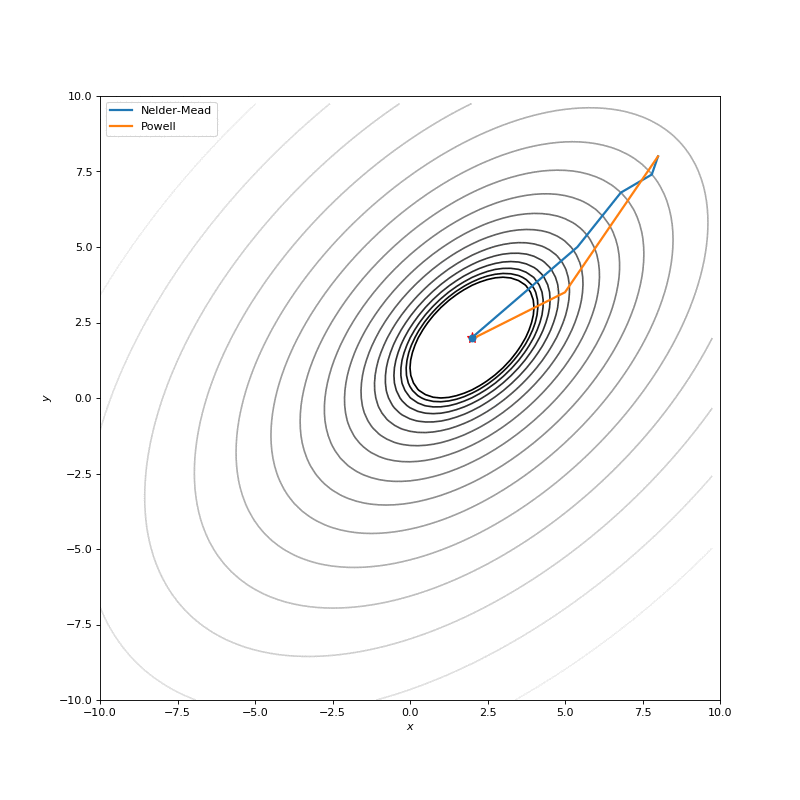 用Nelder-Mead和Powell优化Bohachevsky,Matyas和Trid函数
用Nelder-Mead和Powell优化Bohachevsky,Matyas和Trid函数
可以看到SciPy和Tensorflow基于渐变的方法的比较。其中一些算法可能看起来太“慢”,但速度在很大程度上取决于超参数的选择,我们稍后会看一下它们。
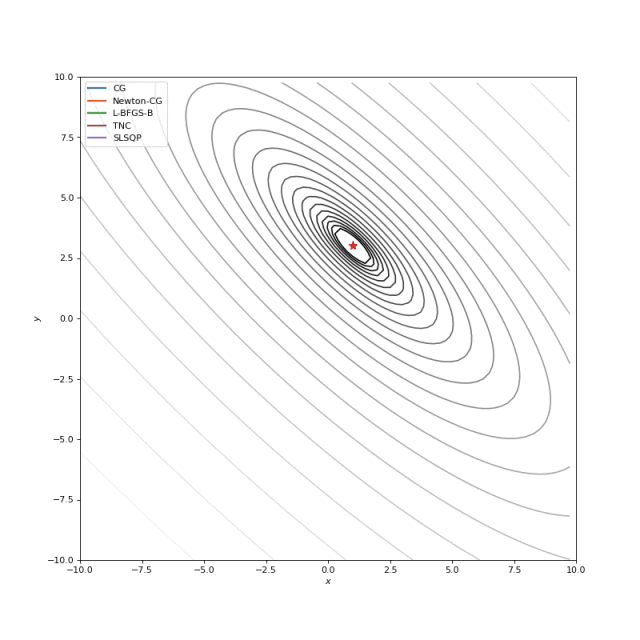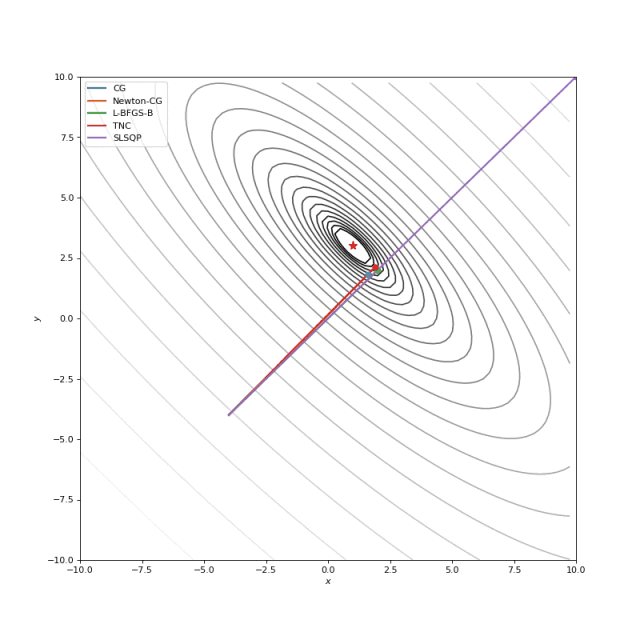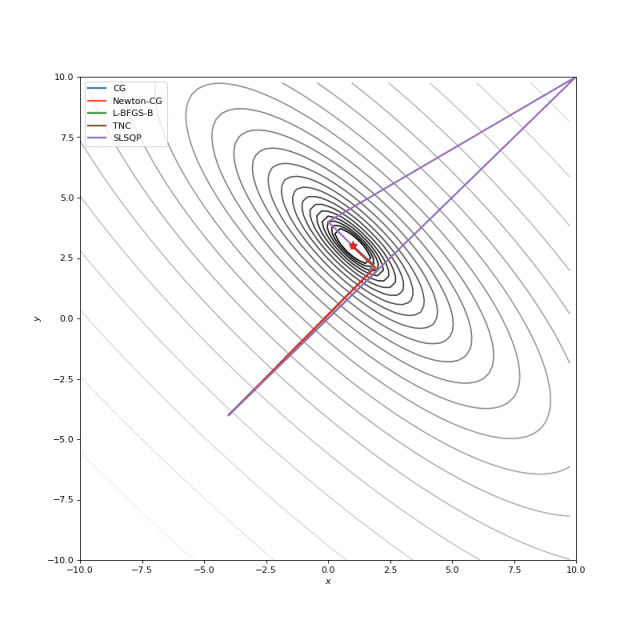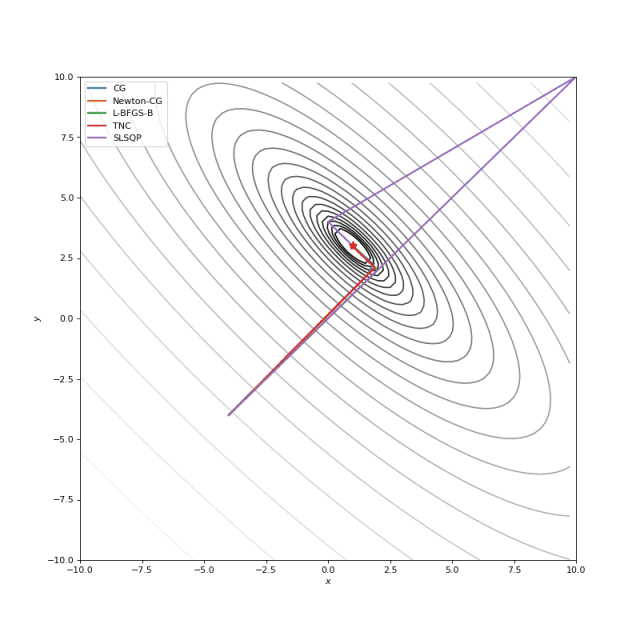
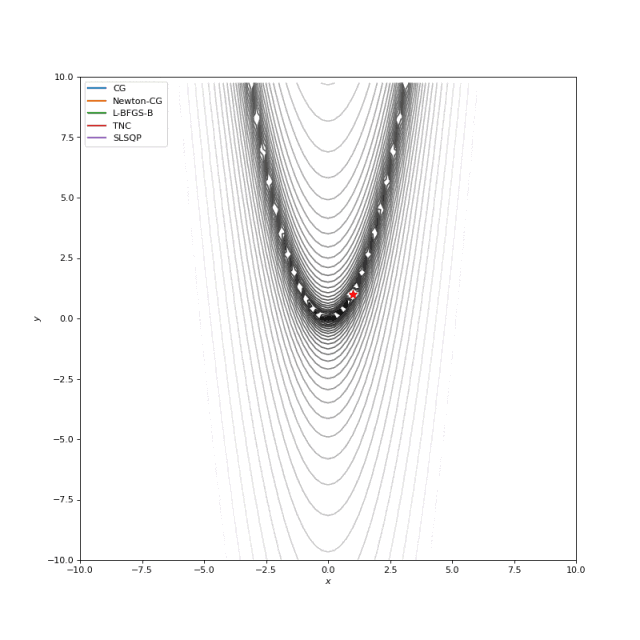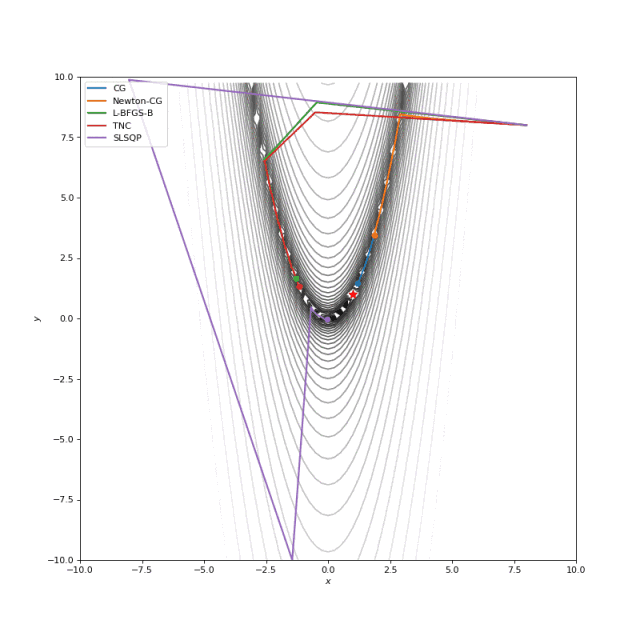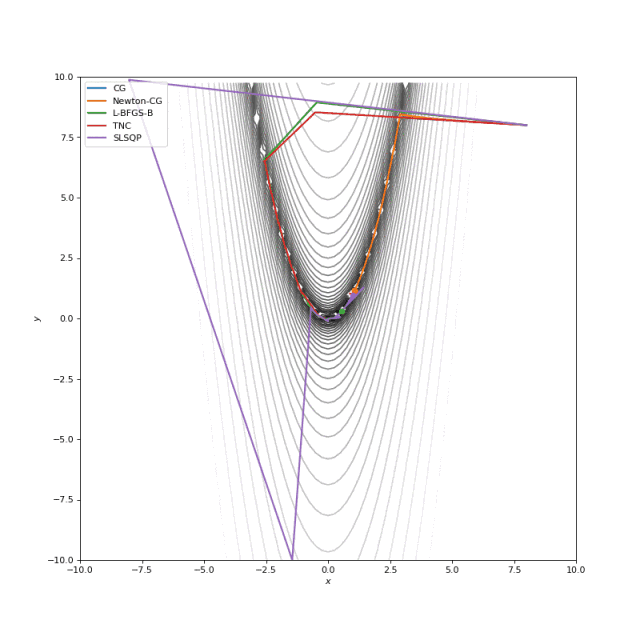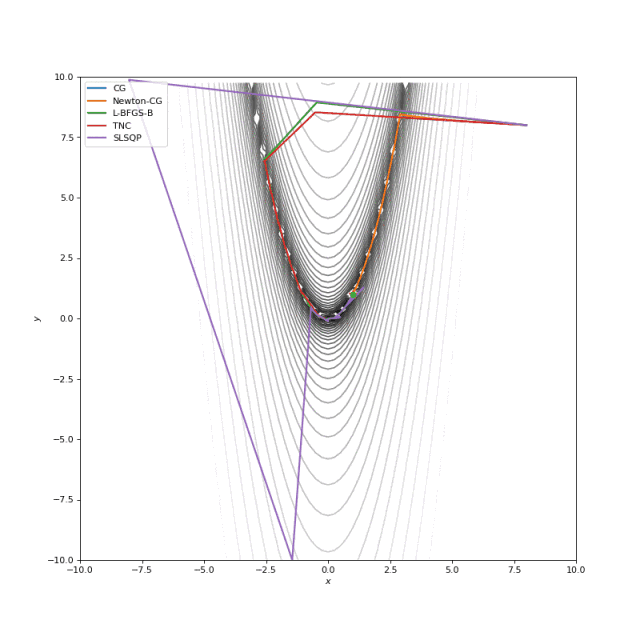
Booth, Rosenbrok 和 Six Hump 函数在SciPy
使用二阶导数几乎立即导致我们看到“好”的二次函数的最小值,但对其他函数并没那么简单。例如:对于Bohachevsky函数,它趋近最小值,但最小值没有真实存在。
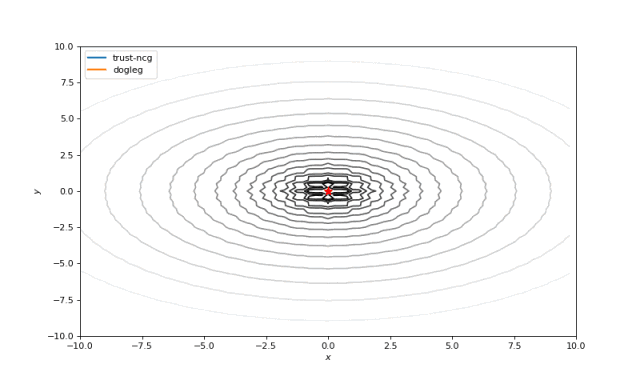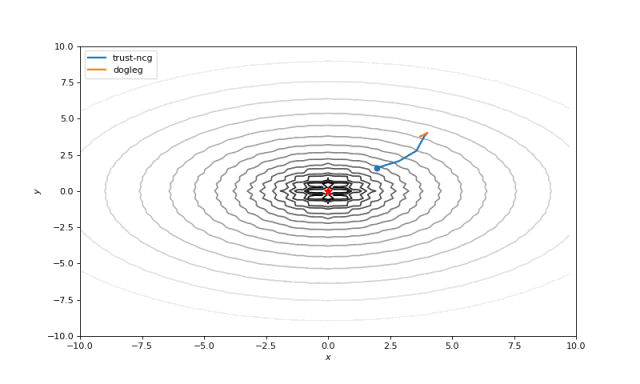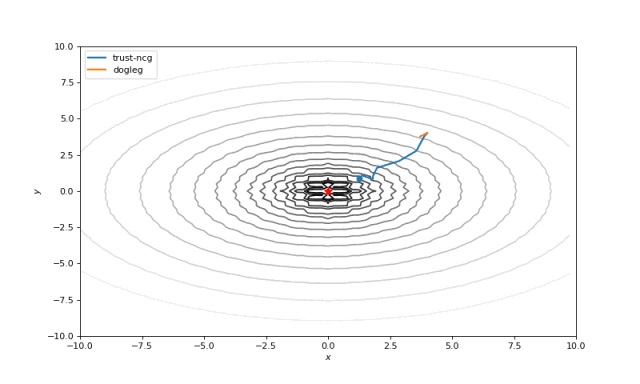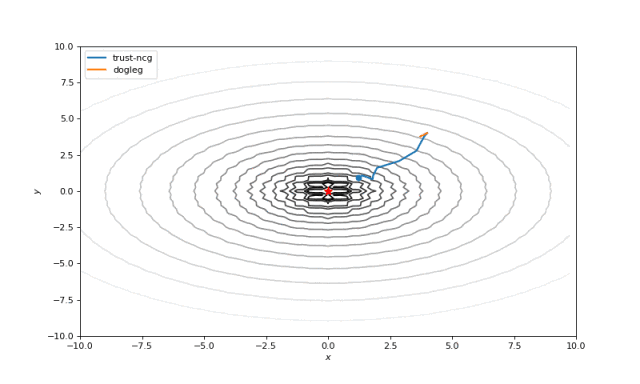
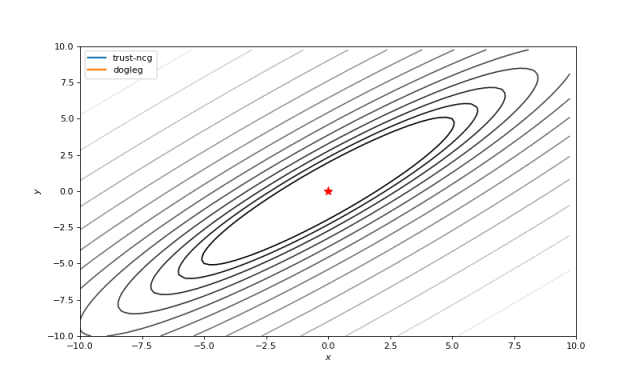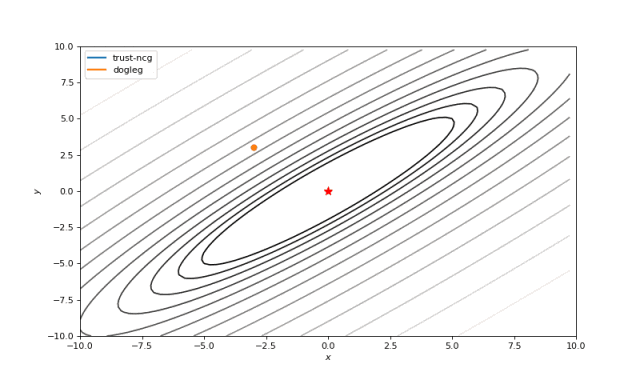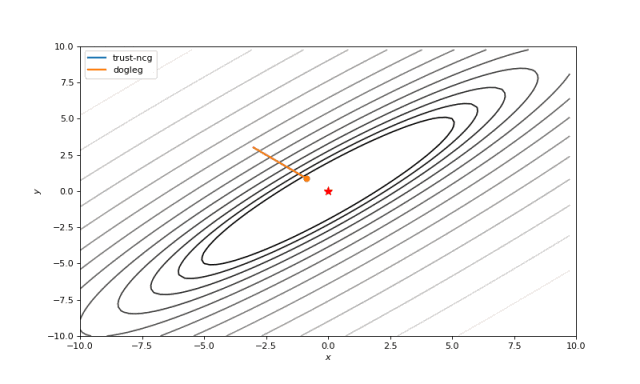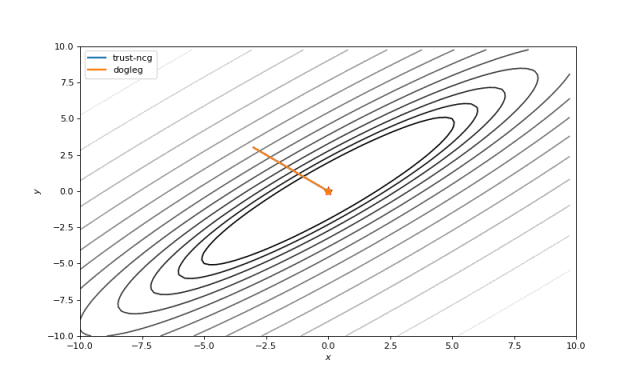
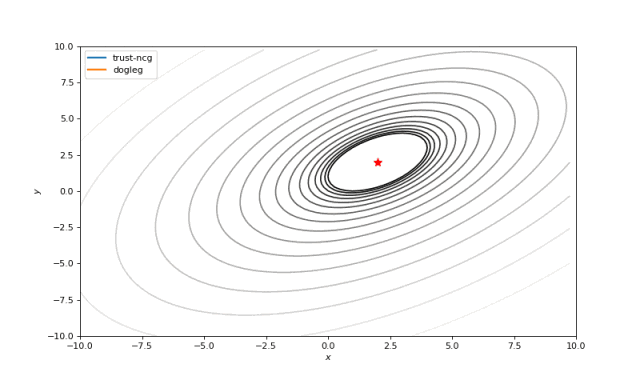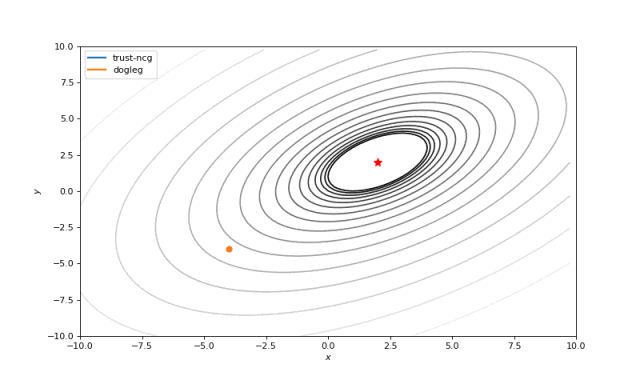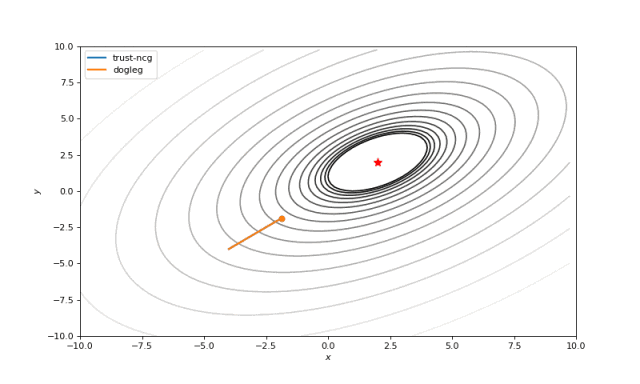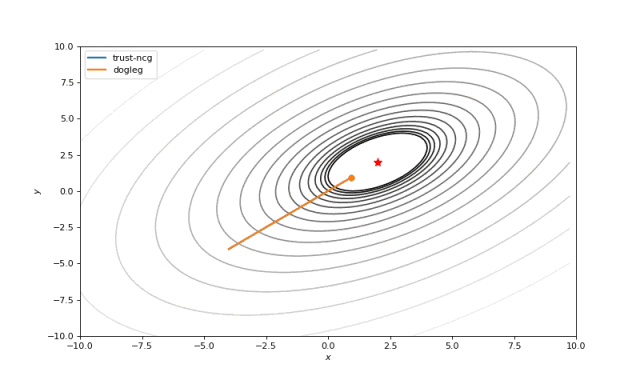
Bohachevsky, Matyas 和 Trid 函数
学习率
首先,你可能已经注意到,像Adam和RMSprop这样流行的自适应算法甚至与SGD相比也很慢,但把它们设计成速度更快了吗?这是因为这些损失表面的学习率太小。必须分别针对每个问题调整此参数。在下面的图像中,可以看到如果将其增加到值1会发生什么。
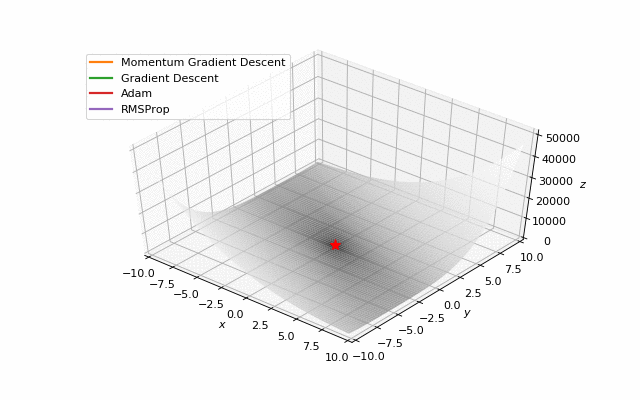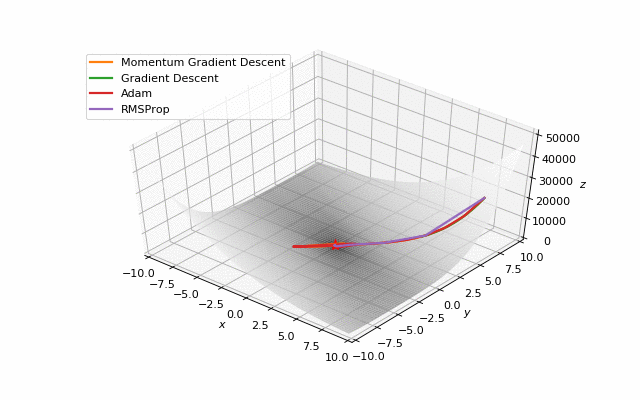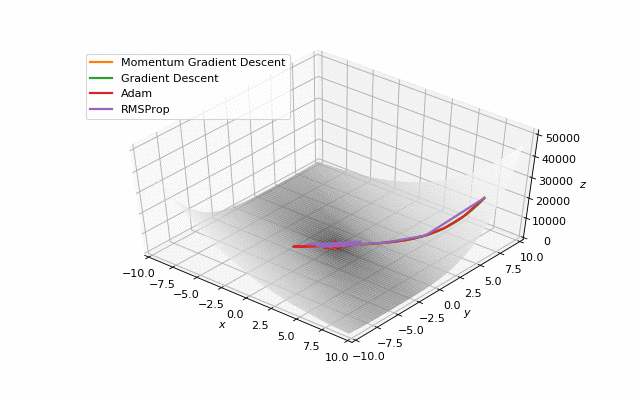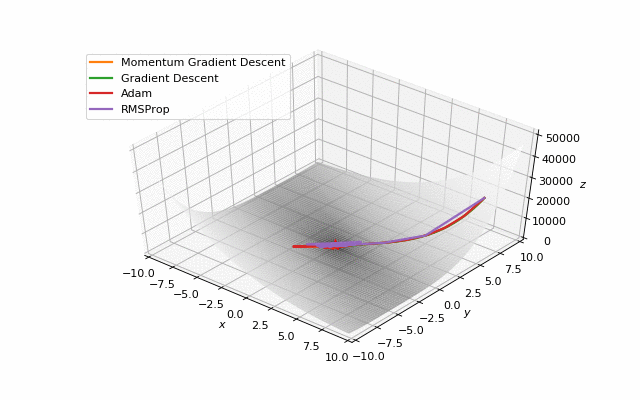
提高Adam和RMSProp的学习率
初始点
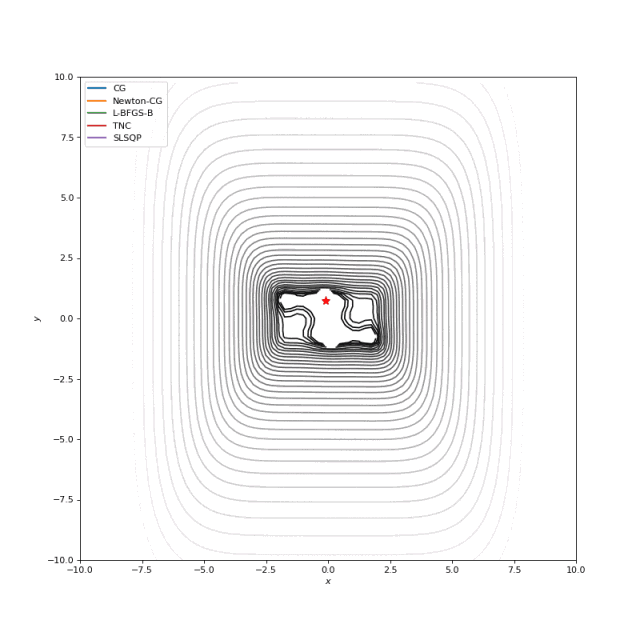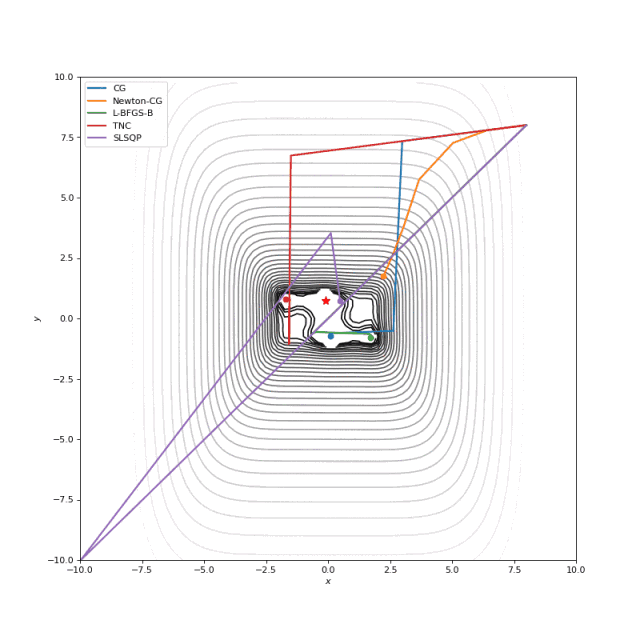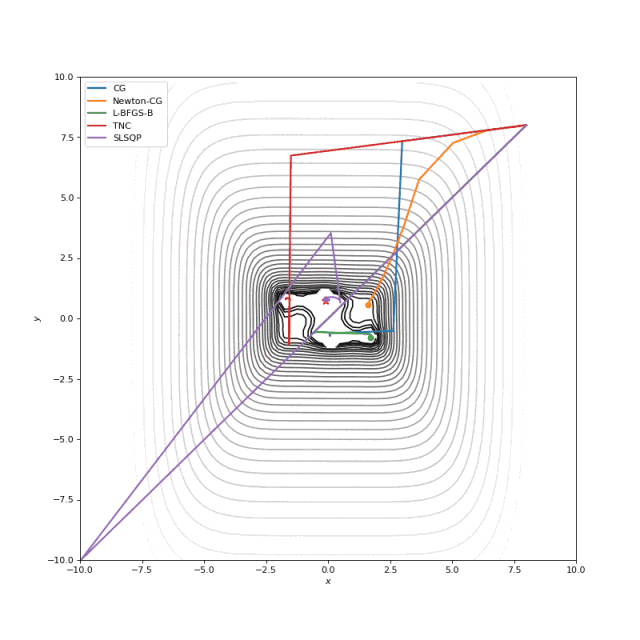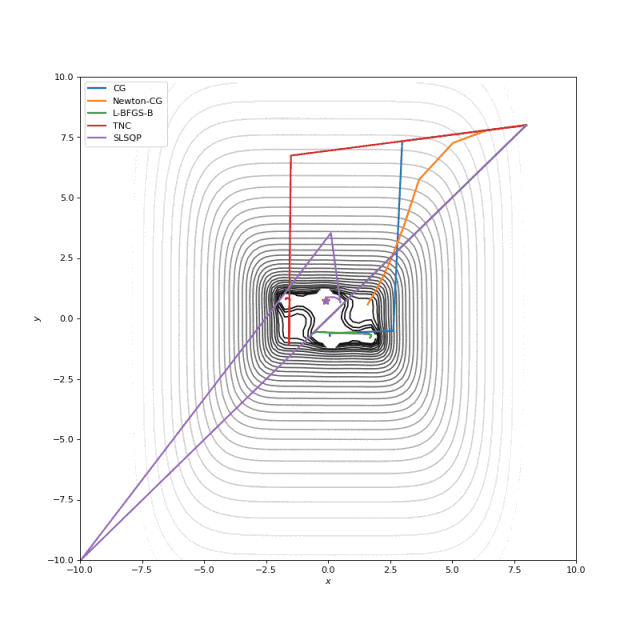
通常我们只是从随机点(或者像神经网络中的一些智能初始化器)开始搜索最小值,但一般来说它不是好的策略。在下面的示例中,可以看到,如果从错误的点开始,即使是二阶方法也可以发散。在纯优化问题中克服这个问题的一种方法是使用全局搜索算法来估计全局最小值的区域。
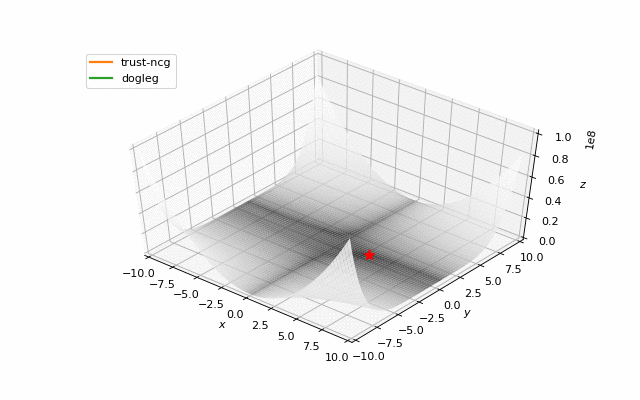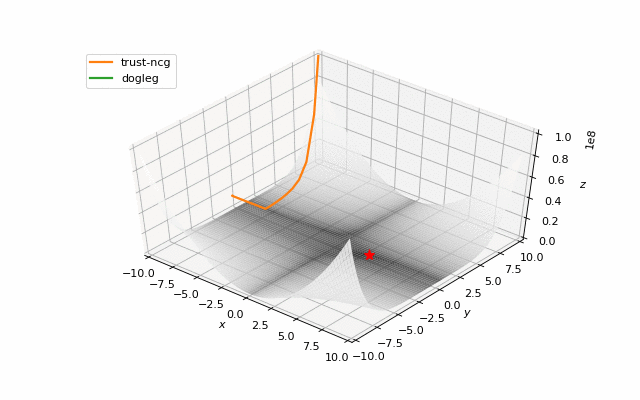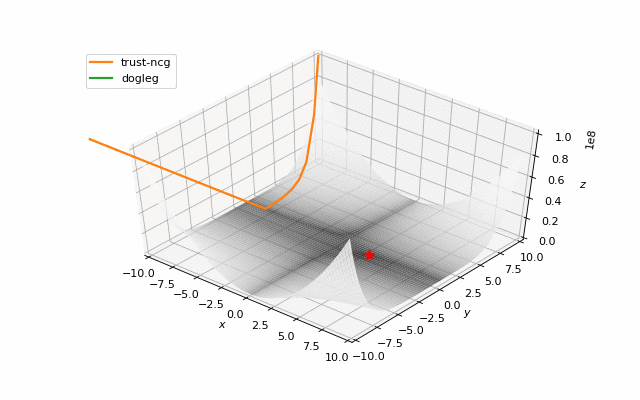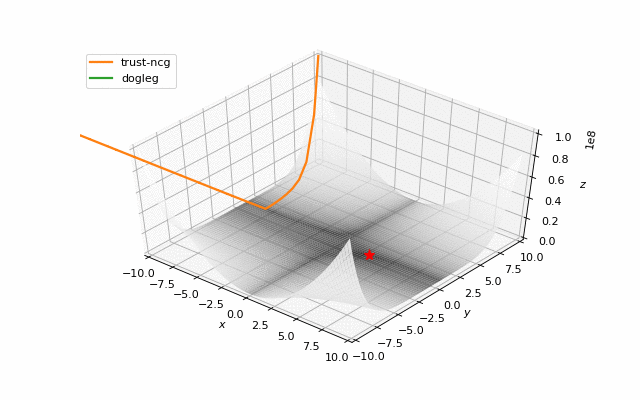
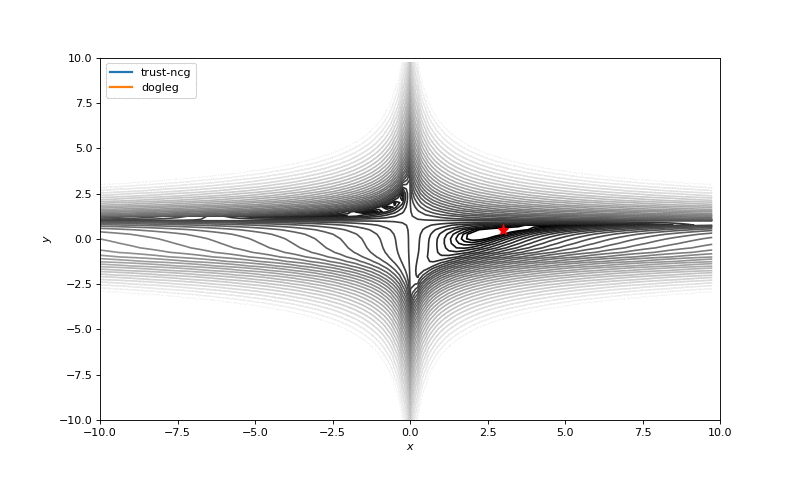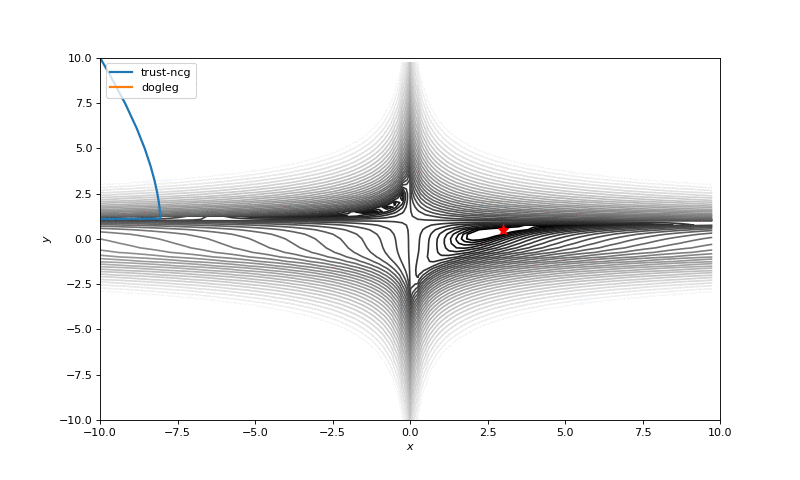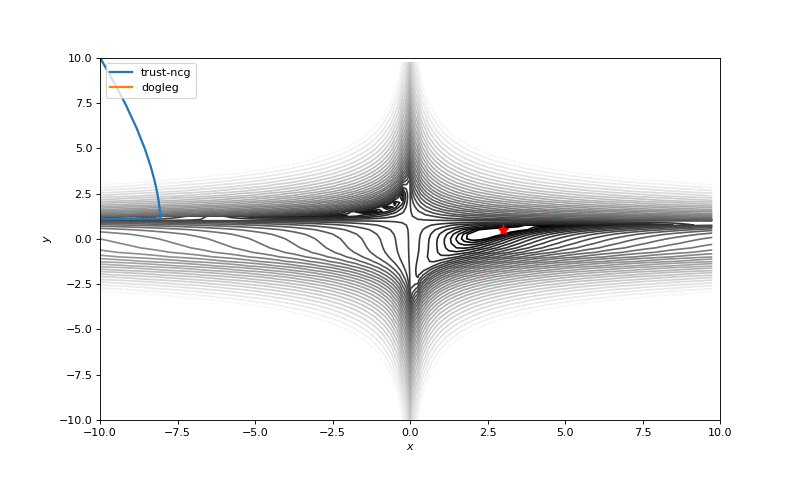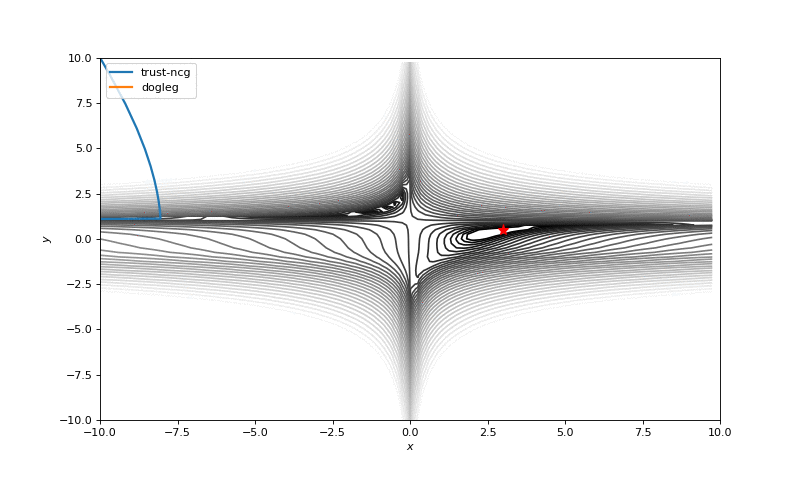
从错误的起点发散二阶方法
你想马上在Tensorcow中尝试一些SciPy算法来训练机器学习模型。因为tf.contrib.opt已经提供了这些服务,你甚至不需要构建自定义优化器。它允许使用相同的算法及其参数:
vector = tf.Variable([7., 7.], 'vector')
loss = tf.reduce_sum(tf.square(vector))
optimizer = ScipyOptimizerInterface(loss, options={'maxiter': 100}, method='SLSQP')
with tf.Session() as session:
optimizer.minimize(session)
本文只是对优化领域的介绍,但只从这些结果我们就可以看出,它根本不容易。使用“酷酷的”二阶或自适应速率算法并不能保证收敛到最小值,而且,还要一些学习速率超参数和查找起始点。无论如何,关于所有这些算法是如何工作的,现在你有一些直觉。例如,可以确信使用二阶方法来实现二次类函数是不错的考虑,不会生涩地使用算法,算法不需要衍生工具也能很好地运行,并且必须成为优化库的一部分。
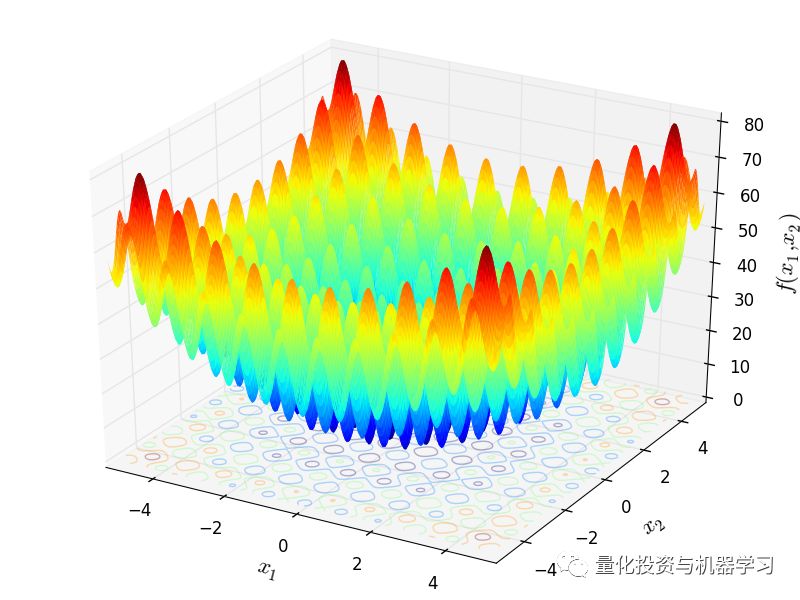
我们还需要记住,这些功能不是真的很难!当我们遇到......有约束......和随机性的事情时,会发生什么?
Optimization
量化投资与机器学习微信公众号,是业内垂直于Quant、MFE、CST等专业的主流自媒体。公众号拥有来自
公募、私募、券商、银行、海外等众多圈内10W+关注者。每日发布行业前沿研究成果和最新资讯。











