
实现流程
从摄像头获取视频流,并转换为一帧一帧的图像,然后将图像信息传递给opencv这个工具库处理,返回灰度图像(就像你使用本地静态图片一样)
程序启动后,根据监听器信息,使用一个while循环,不断的加载视频图像,然后返回给opencv工具呈现图像信息。
创建一个键盘事件监听,按下"d"键,则开始执行面部匹配,并进行面具加载(这个过程是动态的,你可以随时移动)。
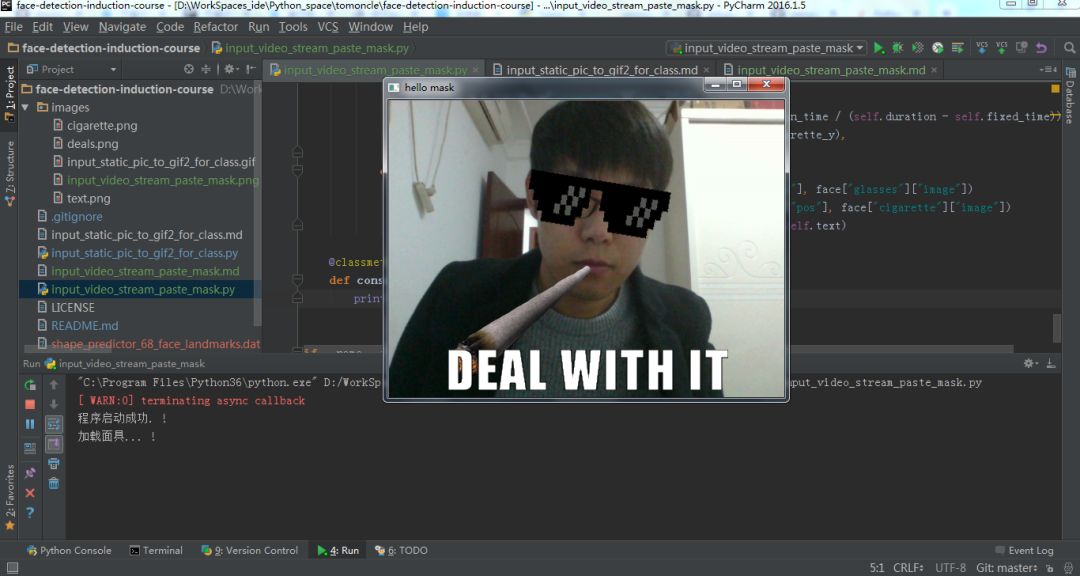
面部匹配使用Dlib中的人脸检测算法来查看是否有人脸存在。如果有,它将为每个人脸创建一个结束位置,眼镜和烟卷会移动到那里结束。
然后我们需要缩放和旋转我们的眼镜以适合每个人的脸。我们将使用从Dlib的68点模型返回的点集来找到眼睛和嘴巴的中心,并为它们之间的空间旋转。
在我们实时获取眼镜和烟卷的最终位置后,眼镜和烟卷从屏幕顶部进入,开始匹配你的眼镜和嘴巴。
假如没有人脸,程序会直接返回你的视频信息,不会有面具移动的效果。
默认一个周期是4秒钟。然后你可以通过"d"键再次检测。
程序退出使用"q"键。
这里我将这个功能抽象成一个面具加载服务,请跟随我的代码一窥究竟吧。
from time import sleep
import cv2
import numpy as np
from PIL import Image
from imutils import face_utils, resize
try:
from dlib import get_frontal_face_detector, shape_predictor
except ImportError:
raise
class DynamicStreamMaskService(object):
"""
动态黏贴面具服务
"""
def __init__(self, saved=False):
self.saved = saved
self.listener = True
self.video_capture = cv2.VideoCapture(0)
self.doing = False
self.speed = 0.1
self.detector = get_frontal_face_detector()
self.predictor = shape_predictor("shape_predictor_68_face_landmarks.dat")
self.fps = 4
self.animation_time = 0
self.duration = self.fps * 4
self.fixed_time = 4
self.max_width = 500
self.deal, self.text, self.cigarette = None, None, None
def read_data(self):
"""
从摄像头获取视频流,并转换为一帧一帧的图像
:return: 返回一帧一帧的图像信息
"""
_, data = self.video_capture.read()
return data
def get_glasses_info(self, face_shape, face_width):
"""
获取当前面部的眼镜信息
:param face_shape:
:param face_width:
:return:
"""
left_eye = face_shape[36:42]
right_eye = face_shape[42:48
]
left_eye_center = left_eye.mean(axis=0).astype("int")
right_eye_center = right_eye.mean(axis=0).astype("int")
y = left_eye_center[1] - right_eye_center[1]
x = left_eye_center[0] - right_eye_center[0]
eye_angle = np.rad2deg(np.arctan2(y, x))
deal = self.deal.resize(
(face_width, int(face_width * self.deal.size[1] / self.deal.size[0])),
resample=Image.LANCZOS)
deal = deal.rotate(eye_angle, expand=True)
deal = deal.transpose(Image.FLIP_TOP_BOTTOM)
left_eye_x = left_eye[0, 0] - face_width // 4
left_eye_y = left_eye[0, 1] - face_width // 6
return {"image": deal, "pos": (left_eye_x, left_eye_y)}
def get_cigarette_info(self, face_shape, face_width):
"""
获取当前面部的烟卷信息
:param face_shape:
:param face_width:
:return:
"""
mouth = face_shape[49
:68]
mouth_center = mouth.mean(axis=0).astype("int")
cigarette = self.cigarette.resize(
(face_width, int(face_width * self.cigarette.size[1] / self.cigarette.size[0])),
resample=Image.LANCZOS)
x = mouth[0, 0] - face_width + int(16 * face_width / self.cigarette.size[0])
y = mouth_center[1]
return {"image": cigarette, "pos": (x, y)}
def orientation(self, rects, img_gray):
"""
人脸定位
:return:
"""
faces = []
for rect in rects:
face = {}
face_shades_width = rect.right() - rect.left()
predictor_shape = self.predictor(img_gray, rect)
face_shape = face_utils.shape_to_np(predictor_shape)
face['cigarette'] = self.get_cigarette_info(face_shape, face_shades_width)
face['glasses'] = self.get_glasses_info(face_shape, face_shades_width)
faces.append(face)
return faces
def listener_keys(self):
"""
设置键盘监听事件
:return:
"""
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
self.listener = False
self.console("程序退出")
sleep(1)
self.exit()
if key == ord("d"):
self.doing = not self.doing
def init_mask(self):
"""
加载面具
:return:
"""
self.console("加载面具...")
self.deal, self.text, self.cigarette = (
Image.open(x) for x in ["images/deals.png", "images/text.png", "images/cigarette.png"]
)
def drawing(self, draw_img, faces):
"""
画图
:param draw_img:
:param faces:
:return:
"""
for face in faces:
if self.animation_time current_x = int(face["glasses"]["pos"][0])
current_y = int(face["glasses"]["pos"][1] * self.animation_time / (self.duration - self.fixed_time))
draw_img.paste(face["glasses"]["image"], (current_x, current_y), face["glasses"]["image"])
cigarette_x = int(face["cigarette"]["pos"][0])
cigarette_y = int(face["cigarette"]["pos"][1] * self.animation_time / (self.duration - self.fixed_time))
draw_img.paste(face["cigarette"]["image"], (cigarette_x, cigarette_y),
face["cigarette"]["image"])
else:
draw_img.paste(face["glasses"]["image"], face["glasses"]["pos"
], face["glasses"]["image"])
draw_img.paste(face["cigarette"]["image"], face["cigarette"]["pos"], face["cigarette"]["image"])
draw_img.paste(self.text, (75, draw_img.height // 2 + 128), self.text)
简单介绍一下这个start()函数, 启动后根据初始化监听信息,不断监听视频流,并将流信息通过opencv转换成图像展示出来。
并且调用按键监听函数,不断的监听你是否按下"d"键进行面具加载,如果监听成功,则进行图像人脸检测,并移动面具,
并持续一个周期的时间结束,面具此时会根据你的面部移动而移动。最终呈现文章顶部图片的效果.
def start(self):
"""
启动程序
:return:
"""
self.console("程序启动成功.")
self.init_mask()
while self.listener:
frame = self.read_data()
frame = resize(frame, width=self.max_width)
img_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
rects = self.detector(img_gray, 0)
faces = self.orientation(rects, img_gray)
draw_img = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
if self.doing:
self.drawing(draw_img, faces)
self.animation_time += self.speed
self.save_data(draw_img)
if self.animation_time > self.duration:
self.doing = False
self.animation_time = 0
else:
frame = cv2.cvtColor(np.asarray(draw_img), cv2.COLOR_RGB2BGR)
cv2.imshow("hello mask", frame)
self.listener_keys()
def exit(self):
"""
程序退出
:return:
"""
self.video_capture.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
ms = DynamicStreamMaskService()
ms.start()
写在最后
长按扫描下方二维码关注后回复“面具”
获取本文完整源代码和模型下载地址

▼ 点击成为社区注册会员 「在看」一下,一起PY!







