 标星★公众号 ♥你们
标星★公众号 ♥你们
▎编译:shan | 公众号翻译部
▎作者:Druce Vertes
近期原创文章:
什么是分类算法?
回归预测了连续的值,比如一个资产的收益,而分类算法预测了一个离散的值,比如,这个股票下一段时间的表现是否比现在要好?这就是个二分问题,需要一个是或者否的答案,另一个例子:如果将一只股票的业绩区间分成四份,那么这支股票的下个月业绩会落在那块,这就是个多项分类问题,会得到4个可能的结果。在这篇文章中,我们将给分类问题进行高屋建瓴的解析,并在组合上应用分类算法预测收益。分类算法本身是深度学习的一种,最开始是用于手写识别或者图像识别,分类算法是机器学习中的基础算法,在它的基础上可以做出很多有意思的东西。
代码链接:
https://github.com/druce/Machine-learning-for-financial-market-prediction/blob/master/Classification%20Mad%20Science.ipynb
分类算法要素
首先,我们在二维坐标上生成一些红色和蓝色的点,整个坐标系在0-100中间。
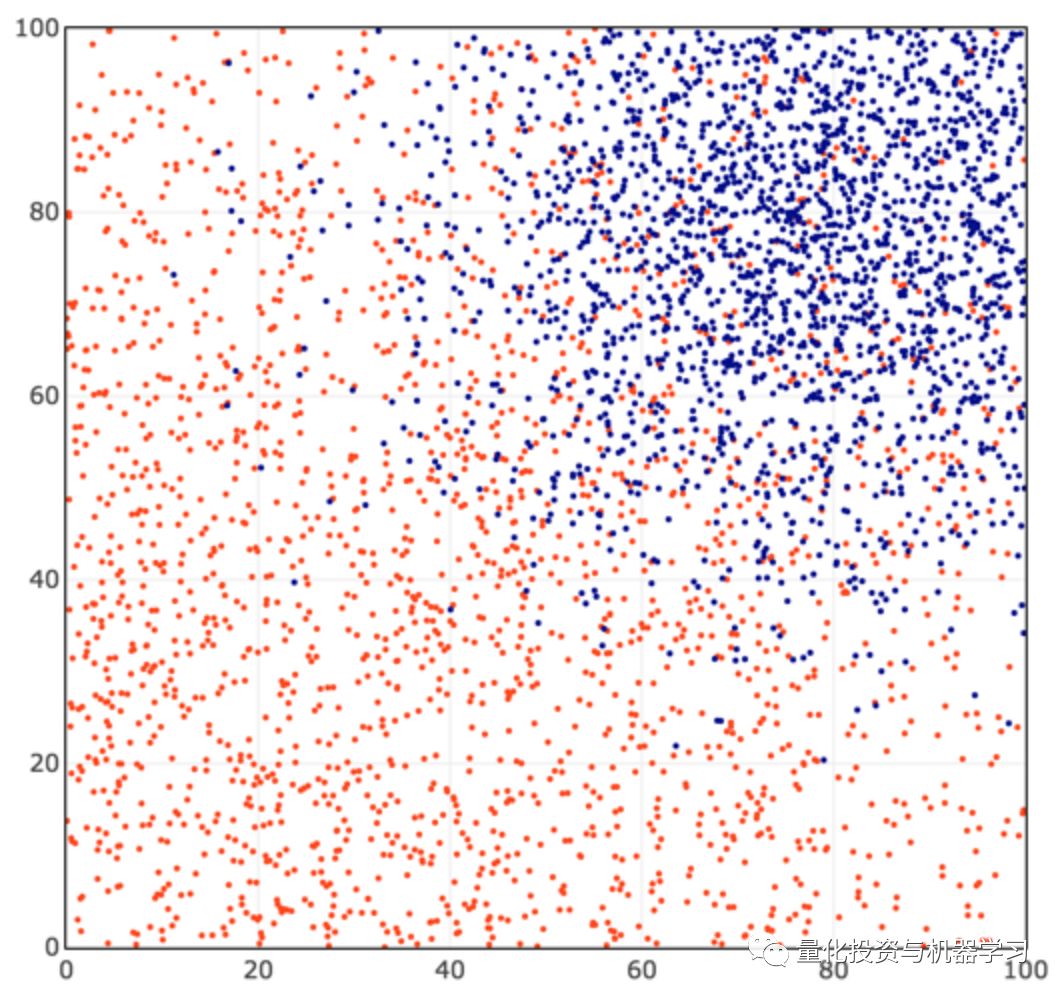
测试数据中:
2000个红色点以坐标(25,25)为中心,标准差为50,设置label=0;
2000个蓝色点以坐标(80,80)为中心,标准差为20,设置label=1。
我们希望寻找的一个函数,输入x和y就能得出是在红色区还是蓝色区,逻辑回归是一个简单且流行的分类算法。
我们展示一下如何应用逻辑回归。
1、首先我们设定z(x,y)=ax+by+c
2、然后我们用squashing激活函数把正数映射到1,负数映射到0
3、然后我们使用损失函数去度量预测误差,这个误差项应该在预测正确的时候趋近为0
4、最后我们算出参数a,b,c来最小化这个损失函数
如果我们能训练这个分类器,使其的误差趋近于0,那么我们就能得到一个函数能够尽量的匹配预测值和观察值。
我们通过使用梯度下降方法来降低误差,先随机选择参数值a,b和c,确定这些值的移动方向以使整个函数的误差缩小,然后更新a,b和c的值使最终的误差最小。
我们得到一个红点和蓝点的分类如下:
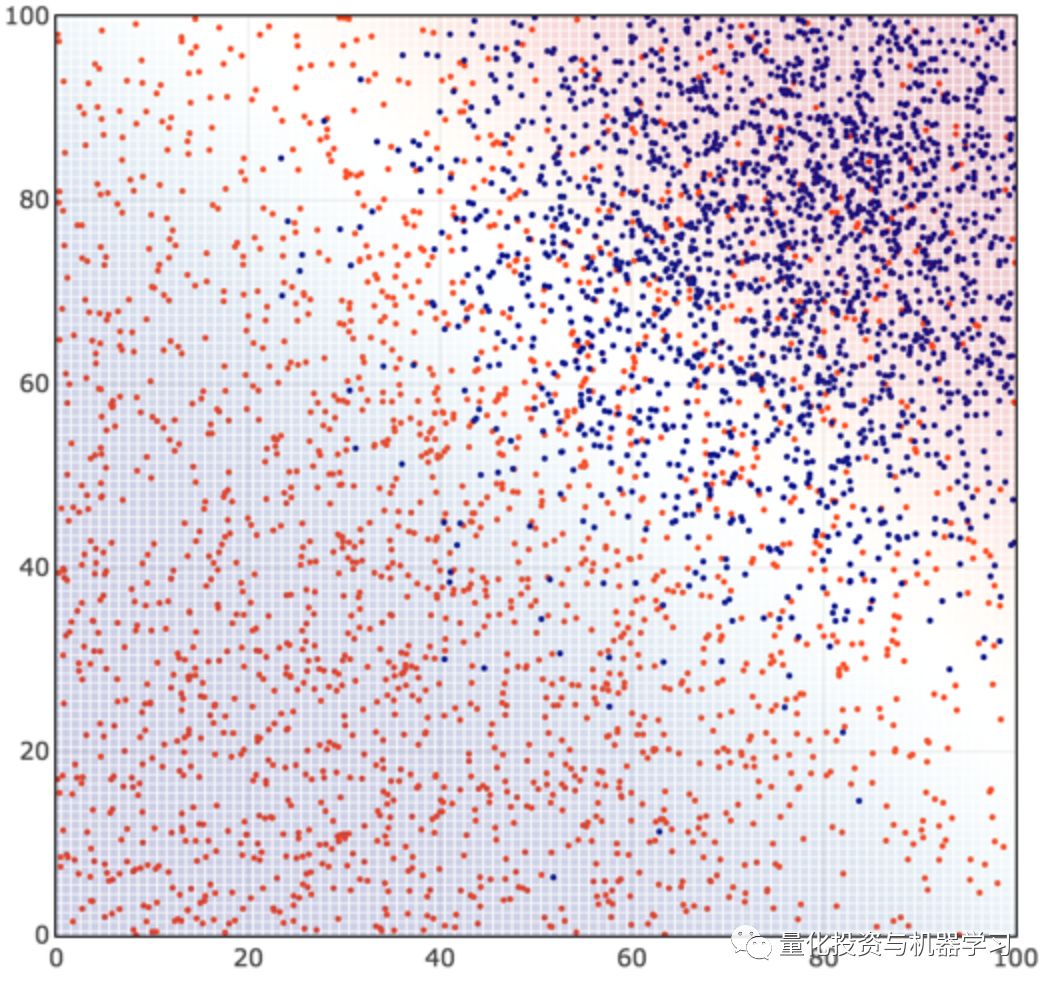
让我们仔细看看隐藏在背后的这四个步骤。
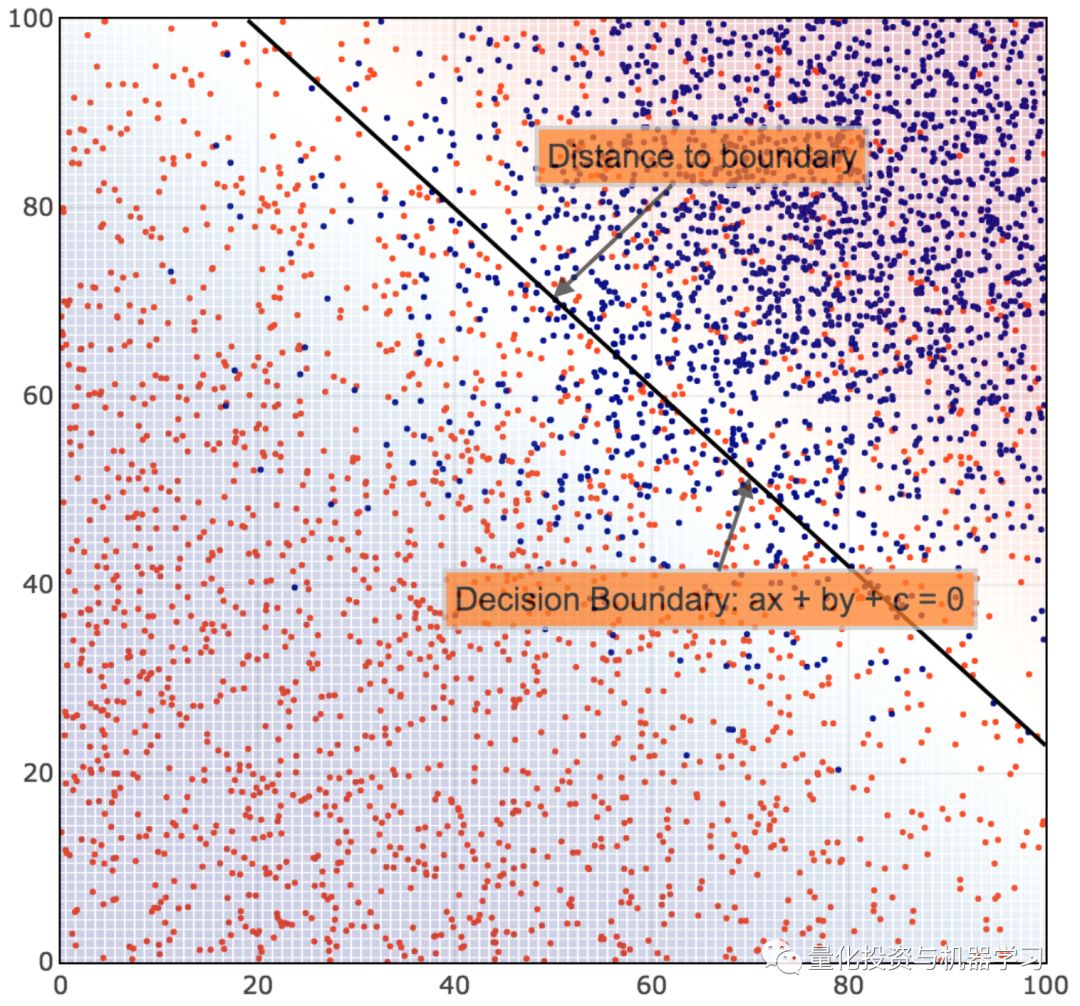
决策函数Z(x,y): = ax + by + c与ax + by + c = 0的欧式距离成正比,它代表了到分类边界的距离。
Squashing函数:在逻辑回归里,squashing函数式逻辑回归函数为 这种类型的函数称作激活函数,函数形状很像’S’,因此用S(X)来表示,可以将负无穷到正无穷的数据映射到[0,1]区间之内,直观的解释是它将对数几率映射到了0-1之间。

损失函数:假设我们预测是蓝色点的概率为0.8,那么如何判断预测的准确性,对于二分分类问题来说,我们想要尽量缩小误差。V = - log(p)y - log(1-p)(1-y) 在这个式子中,y是我们的预测结果,p是我们预测为篮点区域的概率。
一个好的方法来可视化log loss是用-log(correctness),如果我们确定预测是100%准确的,则log(loss)=0,如果我们的预测是100%错误的,则log(loss)将得到正无穷。
我们继续分解这个问题,我们的预测结果是0或者1,那么我们的预测的概率就在0和1 之间。如果我们的预测值是1(蓝色点),并且我们的预测准确率为p(假设为0.8),那么V=-log(0.8). V = - log(p)y - log(1-p)(1-y) 等式的第二项为0因为1-y=0。当一个预测接近1时,log loss趋近于0,如果一个预测趋近于0时,log loss则非常大。相反,如果预测值为0(红色点区域),那么损失函数V = -log(1-p),第一项为0因为y=0,如果我们的预测接近于0,那么log loss为0,如果预测趋近于1,那么log loss则非常大。

在以上四步中,我们用以下方法来分解二分分类问题:
1、寻找到合适的参数a,b,c
2、最小化损失函数V(S(ax + by + c)) = J(a,b,c)…
3、训练所有的训练集
这些就是二分分类方法的要素:寻找一个函数和满足函数的参数(a,b和c),使其预测概率为1,并且最小化损失函数,我们可以借助计算机来实现它。
最后一点
当预测概率超过一个概率阈值时,我们预测蓝色类。一般来说,我们不应该假设我们的决策边界必须在50%概率线上。在实际问题中,我们应该考虑假阳性与假阴性的成本。当我们提高概率阈值时,我们减少了误报的数量,增加了误报的数量。ROC曲线可以帮助我们可视化。我们想要选择一个决策边界阈值来最大化真实世界的性能,如果我们增加一个正预测的阈值,那么更少的假阳性的边际收益等于额外的假阴性的成本。
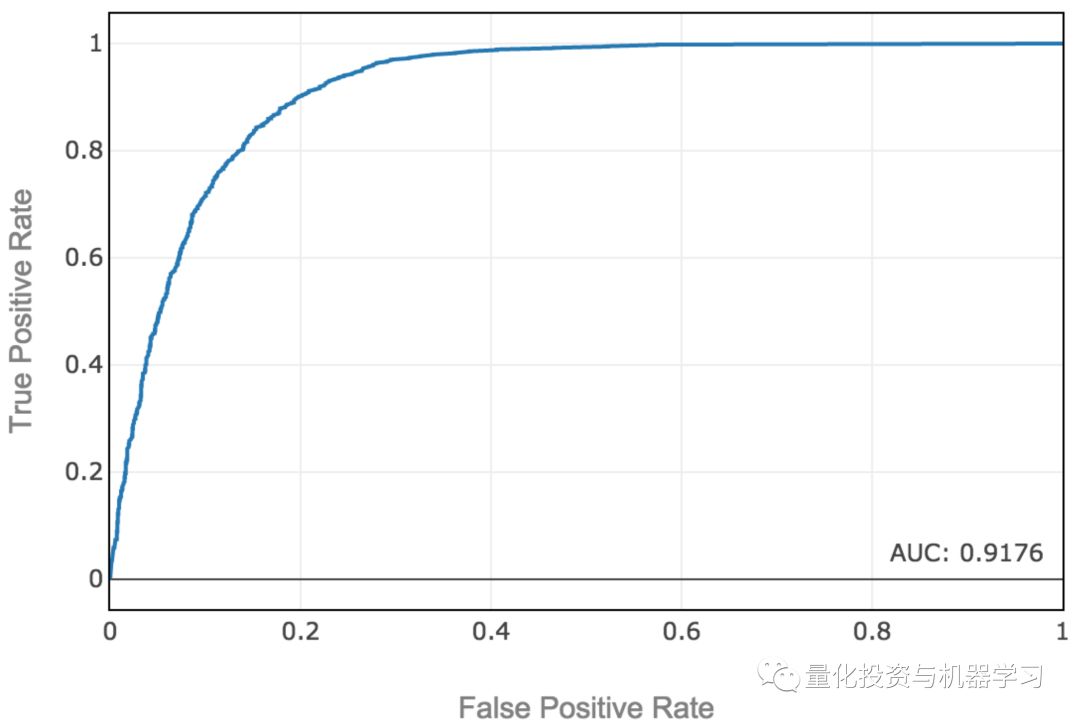
那么在如此多的分类算法中,我们如何找到试用的分类算法呢?
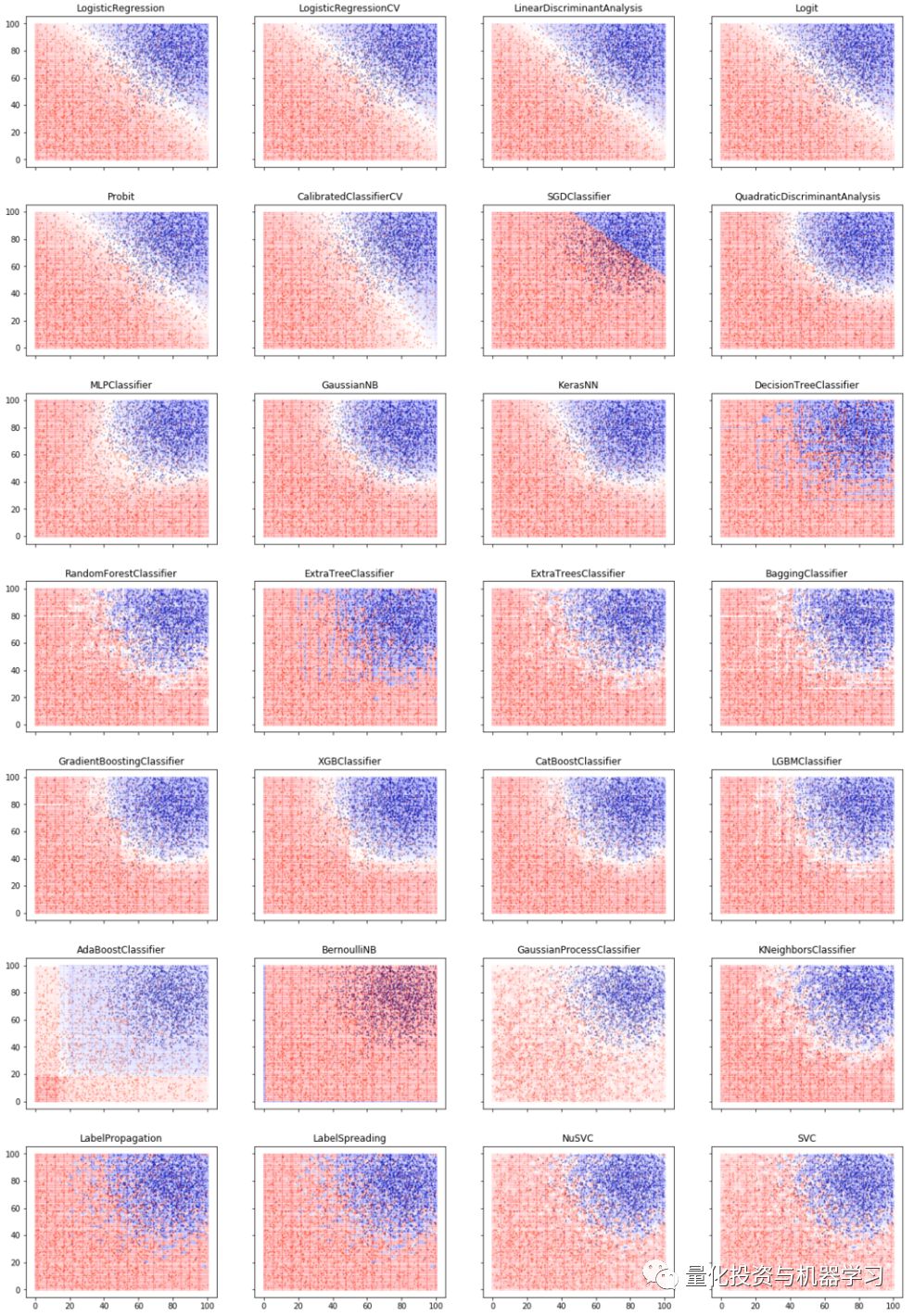
那么应该明确的问题:
1、x和y符合什么分布。
2、决策边界的图形是什么样子的?是线性还是非线性。
3、确定损失函数,并且如何最小化损失函数,常用的损失函数有 均方根误差(mean-squared-error),交叉熵损失(cross-entropy loss),折页损失(hinge loss)等。
4、如何在过拟合和提升预测效果之间权衡。
5、最后,看下这个算法如何训练数据,如何根据x找到确定的y,这个算法的复杂度是多少,比如逻辑回归比较简单效率较高,而神经网络则需要较长的时间去训练数据,这个分类器是离散的还是连续的,连续的分类器试用任意的x和y。而离散的分类器是一个略完备的模型。逻辑回归用于离散变量的分类,即它的输出y的取值范围是一个离散的集合,因此是离散型分类器。
上图中的前五个分类器都是线性的,这些分类器预测的结果相近,只在前提条件,适用的分布,损失函数和如何缩小过拟合有些许不同。
其他分类器有的有非线性的决策边界:如Quadratic Discriminant Analysis, Multi-Layer Perceptron, Gaussian Naive Bayes, 和 Keras NN。剩下的分类器可能是分段线性的,如KNN, Trees, Bagging, Boosting,比如K近邻(KNN)算法是找到最近的k个邻居来进行分类的,而K是在交叉验证中得到的。应用Boosting模型最近在Kaggle机器学习大赛中获得了很多奖,它主要用的是集成学习的思路,即对新的实例进行分类的时候,把多个单分类器的结果进行某种组合,来对最终的结果进行分类。
下面简单介绍下其他的分类算法:
决策树算法:决策树是一种简单但广泛使用的分类器,它通过训练数据构建决策树,对未知的数据进行分类。决策树的每个内部节点表示在一个属性上的测试,每个分枝代表该测试的一个输出,而每个树叶结点存放着一个类标号。
Bagging算法:
bootstrap aggregating的缩写。让该学习算法训练多轮,每轮的训练集由从初始的训练集中随机取出的n个训练倒组成,初始训练例在某轮训练集中可以出现多次或根本不出现训练之后可得到一个预测函数序列h.,… …h 最终的预测函数H对分类问题采用投票方式,对回归问题采用简单平均方法对新示例进行判别。
决策森林:随机森林指通过多颗决策树联合组成的预测模型,可以对样本或者特征取bagging。
Boosting算法:其中主要的是AdaBoost(Adaptive Boosting)。初始化时对每一个训练例赋相等的权重1/n,然后用该学算法对训练集训练t轮,每次训练后,对训练失败的训练例赋以较大的权重,也就是让学习算法在后续的学习中集中对比较难的训练铡进行学习,从而得到一个预测函数序列h 一…h其中h有一定的权重,预测效果好的预测函数权重较大,反之较小。最终的预测函数H对分类问题采用有权重的投票方式,对回归问题采用加权平均的方法对新示例进行判别。( 类似Bagging方法,但是训练是串行进行的,第k个分类器训练时关注对前k-1分类器中错分的文档,即不是随机取,而是加大取这些文档的概率)。
集成算法:在运行了很多分类算法之后,我们可以选择最终的分类器模型。在上面的例子中,我们使用Voting Classifier模型,相比逻辑回归来说获得了85.9%的准确率和更好的AUC。
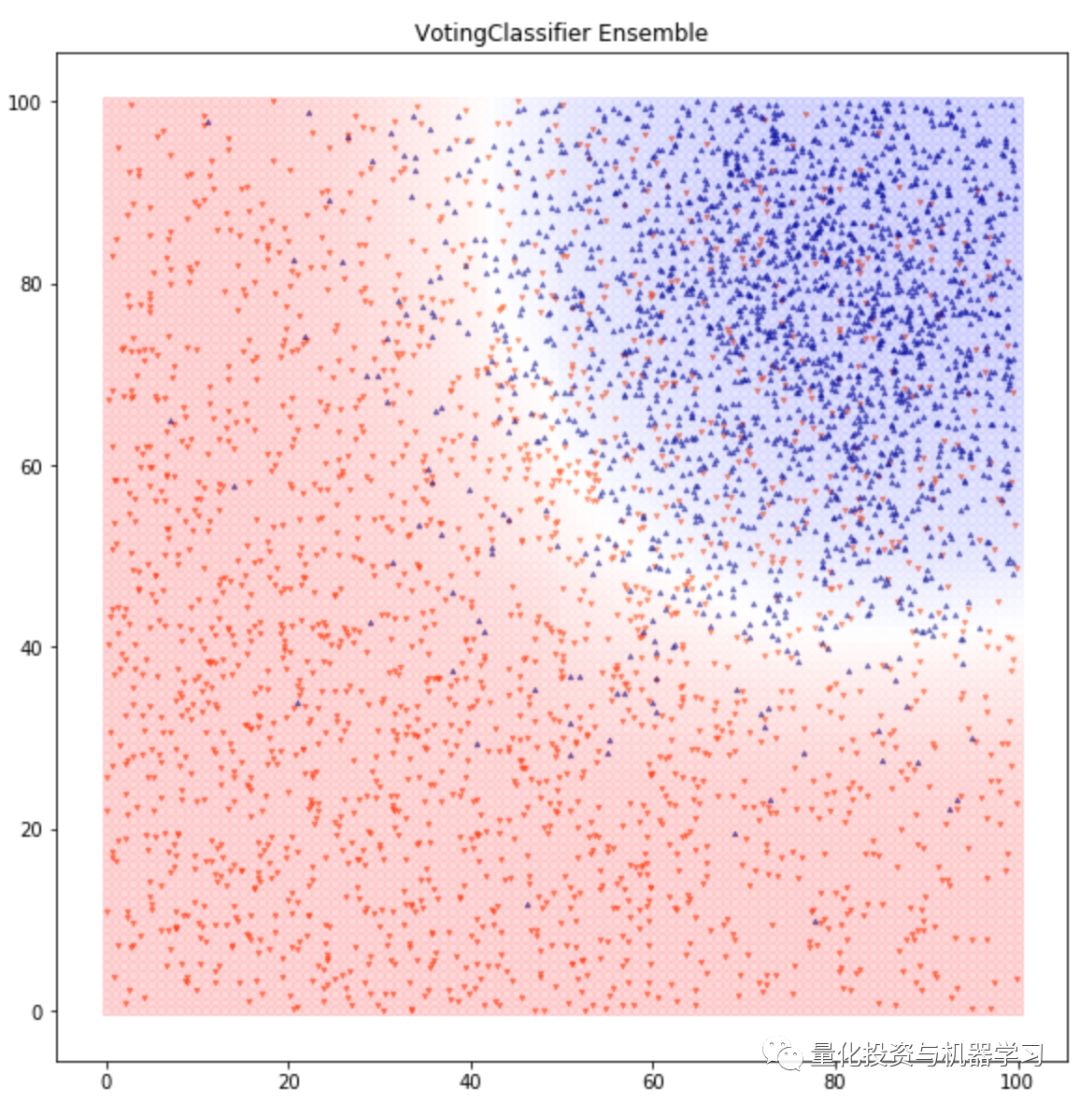
我们现在有了足够多的工具来对数据进行分类,收集和清洗以得到一个好的数据集,找到一个合适的模型就能解决80%的问题。
总结一下,在分类算法中,我们学到了
1、分类算法的基础
2、如何应用逻辑回归
3、不同分类算法的区别
4、如何组合分类算法以得到更好的结果
分类算法是机器学习算法的基础,很多机器学习问题的解决都始于分类算法,如语音识别、无人驾驶汽车等。在第二部分,我们将用分类算法建立一个价值投资和趋势投资的组合。
下面我们将分析下分类算法在投资中的应用,我们先简述一些基础概念:
价值与动量
价值投资策略核心是寻找高性价比的股票,通常我们使用PB(price/bookvalue)来衡量一个股票的性价比。我们将股票按照PB分成5个区间,逐月记录这五组股票的收益,这些是从1973到2017的结果。

从结果中我们可以得到,价值投资确实能赚钱。
趋势投资
我们还可以用趋势策略,即挑选最近长势喜人的股票,这只股票可能最近有利好。利好可能包括:
1、好的信息逐渐披露出来,比如公司前景喜人,开始可能只是内部人员了解,之后大众逐渐了解,利润增加,股票市场价格逐渐增长;
2、公司被低估,公司在招聘,市场,媒体上等各种表现超过大家预期,股价也会增长;
3、近期政策层利好等都会使股价近期提高;
趋势策略是市场形成的,那么如何用数据证明趋势策略有用,我们将股票按过去一年涨幅分成5个区间,走势图如下所示。

价值策略和趋势策略相结合
为了给我们之后的分类算法一个比较的标准,我们按价值策略和趋势策略中的表现分别为每一只股票打分,把股票集合按分数进行排序形成组合,表现如下图:

这样就给我们的模型一个比较的基准,这个组合的sharp ratio为0.47,让我们看看用机器学习的方式是不是能得到更好的结果。
首先,我们用个非常简单的分类方式,将股票按value/momentum的比值进行分类,对最好的那一类进行投资。对投资的组合每个月进行rebalance。
另外一个稍微复杂的方法,用逻辑回归进行预测,看看那只股票会在最好的投资区间,然后对最好的那一类进行投资。预测银子选择(P/B)和趋势因子,我们选择3个月的收益来看整个结果,以防止某个月的收益有扰动。
但是我们看到结果并不好,这个结果和我们最开始的基准差不太多,那么到底是什么原因?我们怎么才能得到更好的结果。
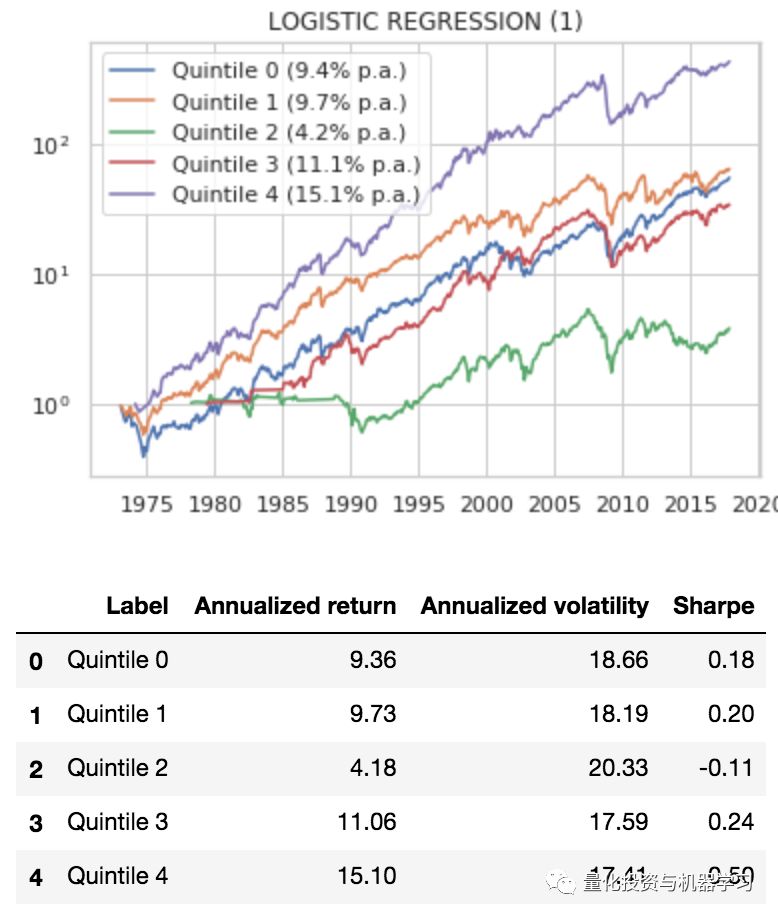
我们可以看到在这个逻辑回归中,随时函数用的是log loss损失函数,但是log loss损失函数把所有损失看成相同的。比如如果在第五区间的预测结果落到了第一区间,其实它的error是远比落在第四区间要大的多的。
另外一个问题是,如果我们得到一只股票在五个区间的概率0.30, 0.09, 0.11, 0.21, 0.29,第零区间和第四区间只有1%的差距,那么我们是否能确定落在第一区间呢?那么如果我们每次都把股票分到概率最高的区间可能会导致预测不准。我们把预测的结果画图,发现大部分都是落在表现最不好的两个区间内的。
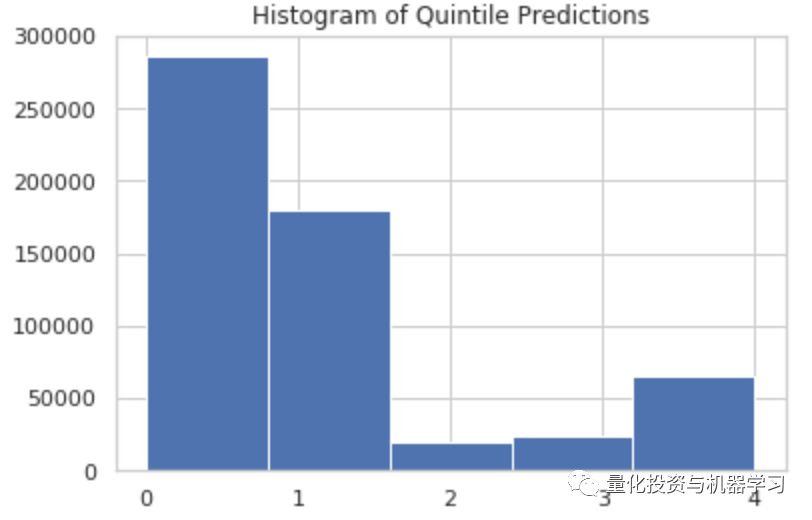
0.30 x 0 + 0.09 x 1 + 0.11 x 2 + 0.21 x 3 + 0.29 x 4 = 2.1
为了使分类更有效,我将预测结果做了个加权平均,因此本来分给第零个区间的,被分给了第二个区间,用这个方式优化后,我们的结果为:

好消息是我们的结果连续性更好了,并且收益和sharp ratio都有提高;坏消息是我们最好的区间sharp ratio为0.46,比最早做的逻辑回归还稍微差一点。
现实是残酷的,这可能是因为我们在最好的区间放了20%的股票,之前的逻辑回归,我们选了更少的股票,优中选优从而得到了更好的结果。
所以我们应该是选择对了方向,但是是否可以用更好的分类器来解决这个问题呢?
Gradient boosting models 是非常好的分类算法,我们可以尝试XGBoost分类算法来判别哪些股票会落入最好的投资区间。
结果如下:
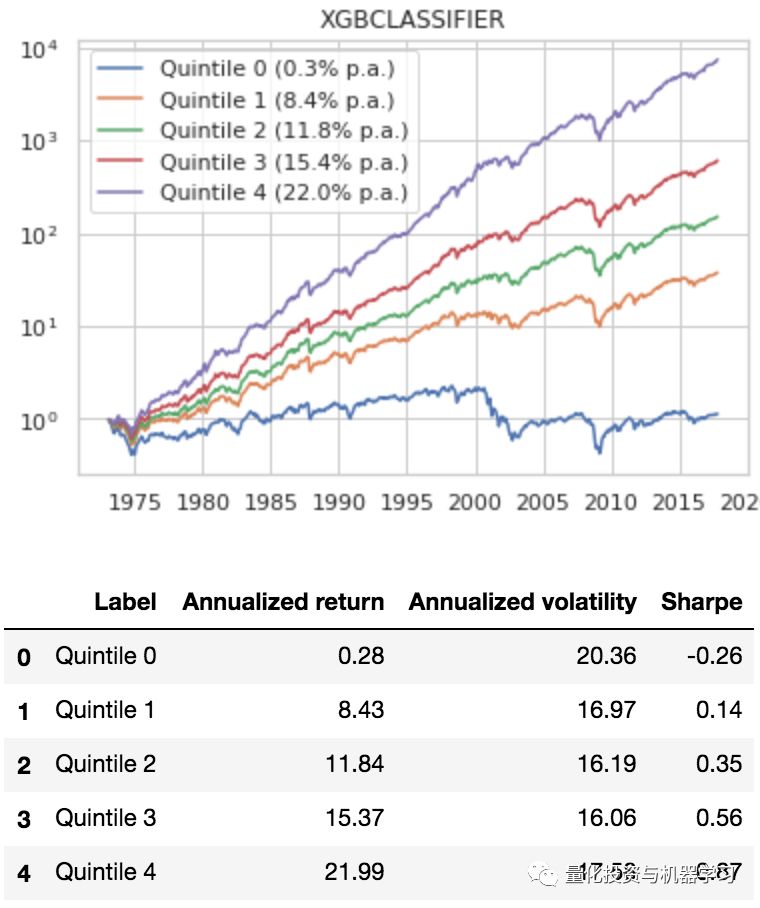
XGBoost分类算法得到的结果非常好,下面说下这个方法的缺点:
1、用三个1月的return要比一个月的return结果更平滑,降低过拟合,但是可能丢失了部分信息;
2、用log loss作为评价函数,容易使差不多概率的分类出错,如最好的区间概率0.3,最差区间概率0.29这种情况;
但是我们也有使用分类的理由:组合构建类似分类问题,选股票就是在做分类。但是我不建议直接应用分类算法,分类算法在预测收益和是否有default风险上很好用,在组合构建上也许有更好的方式。
我们学到了什么:
1、单独的价值策略或者趋势策略结果不错;
2、单纯的使用分类算法并不能得到好的收益;
3、Gradient boosting 分类算法能显著的提高结果;
4、直接进行逻辑回归也许是个更好的解决方法。
量化投资与机器学习微信公众号,是业内垂直于Quant、MFE、CST
等专业的主流自媒体。公众号拥有来自公募、私募、券商、银行、海外等众多圈内10W+关注者。每日发布行业前沿研究成果和最新资讯。






