作者:Oluwole Alowolodu
翻译:李润嘉
校对:吴金笛
转自:数据派ID:datapi
本文约3400字,建议阅读10分钟。
本文使用监督式机器学习技术来预测美国爱荷华州艾姆斯市(Ames, Iowa)的房价。
介绍
该项目旨在使用监督式机器学习技术来预测美国爱荷华州艾姆斯市(Ames, Iowa)的房价。Ames的房屋数据集来自Kaggle,这是谷歌旗下的一个在线平台,它为数据科学家和机器学习科学家提供合作和竞争的机会。Kaggle以提供不同的数据和竞赛为特色,其中便包括由Dean De Cock编辑的Ames房屋数据集。
该数据集包含具有81个特征的测试集和训练集。其中,训练文件包括1460条观测值,测试文件包含1459个观测值。
数据清洗
建模的第一步便是数据探索和数据清洗,旨在理解数据集中的每个特征和模式。将训练集和测试集合并到一起进行统一的数据工程,并对缺失值进行探索。以下是一张热力图,可从中看出数据中的缺失值所处的位置。
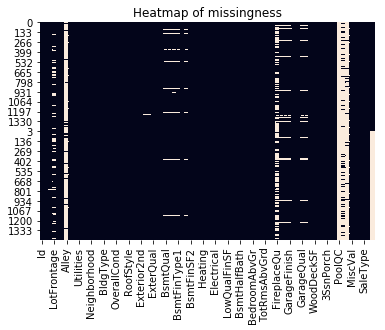
热图为特征缺失,尤其是包含大量缺失值的列提供了线索。通过对组合数据集的进一步分析,提取出每个特征所含缺失值的具体数量。可知共有34列含有缺失值,其中PoolQC,LotFrontage,FireplaceQual,Fence,Alley和MiscFeatures列的缺失值最多。以下是一个条形图,显示了缺失值的分布情况。
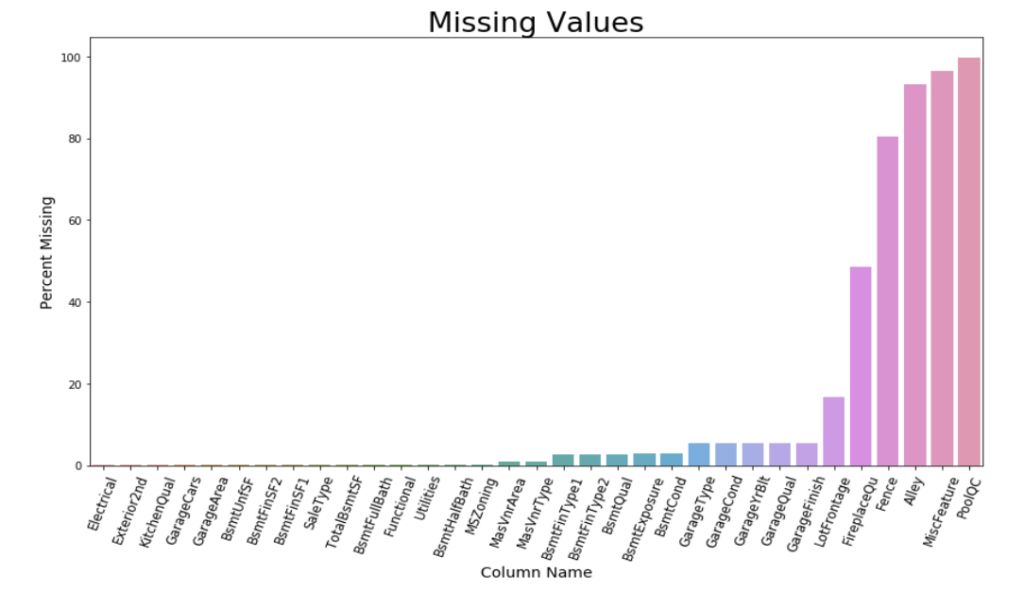
不同的含有缺失变量的特征有不同的估算方式。在估算之前需要考虑以下因素:该特征是分类型特征还是数值型特征,缺失值是随机完全缺失、随机缺失还是非随机缺失。
对于含有随机缺失值的数值型特征,比如 'LotFrontage' ,将使用位于同一区域的房屋的中位数来进行估算。其他含有缺失值的数值型特征大多根据一定的规则进行填充,大部分情况下使用0来填充。对于分类型特征,其中一些似乎含有缺失值,但是空值(NA)实际上意味着这个变量或房子显然缺少这样的特征,例如,'PoolQC' 中的空值意味着该变量没有 'Pool' 这个属性,它应当归为 'No_pool' 。类似的方法可适用于大多数特征。
删除异常值——缺失值估算的下一步是对数据集进行探索,找出可能的异常值。可通过在散点图上可视化每列来完成。
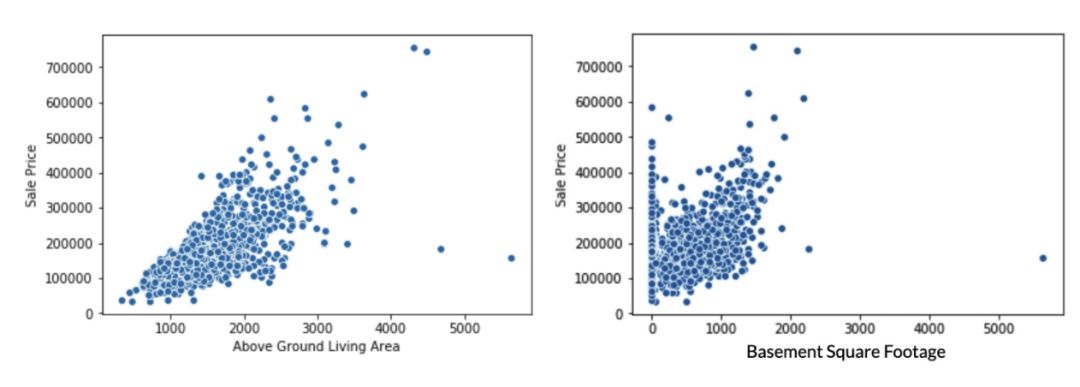
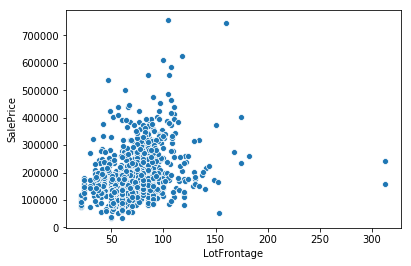
'AboveGroundLivingArea',BasementSquareFootage'
和 'LotFrontage' 特征具有明显的异常值,这些变量应当从数据集中删除
特征工程
在进行特征工程之前,需要对特征进行相关性分析,以便更深入地了解它们的方差、自变量特征之间的相关关系和自变量特征与因变量特征—— SalePrice之间的相关关系。
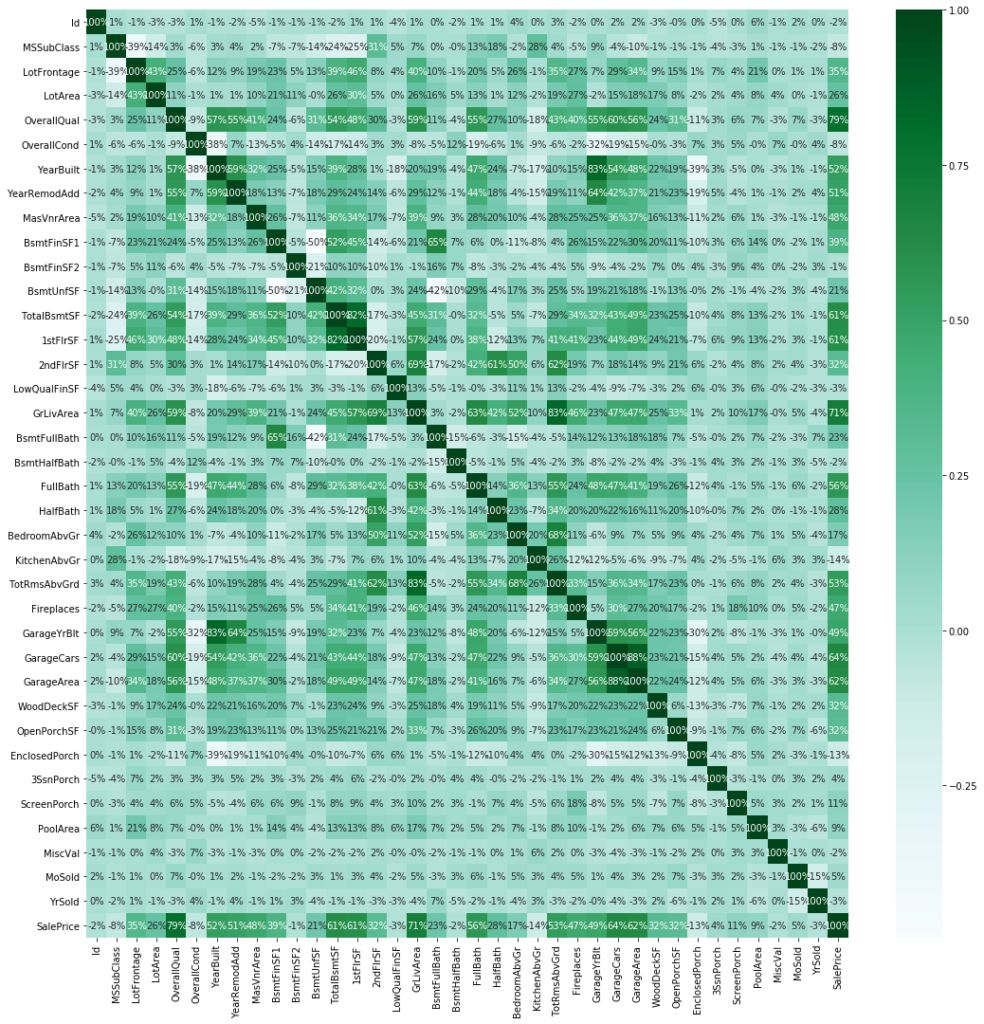
从热力图中可观察到 'GarageCars' 与 'GarageArea'高度相关,'GarageYearBuilt'与 'YearBuilt' 高度相关,'TotalRoomsAboveGround' 与 'GroundLivingArea' 高度相关。它们的相关性均在80%以上。从该矩阵还可以深入了解最适于特征工程的特征。
特征添加——在现有特征基础上构造了9个新特征,主要是二分类特征。新添的第一个特征是 "GrYrAfter" ,它代表了 'Garage year difference' ,记录了建筑物建造年份 ' YearBuilt ' 和车库建造年份 'GarageYrBuilt ' 之间是否存在时间差。这个潜在的差值值得洞悉,因为这可能意味着建筑物的施工时间非常漫长或者期间进行了一些重大改造,这些信息都需要了解。新添的第二个特征是 "Remodelling",生成两个模型来刻画房屋改建的时间差,第一个是二分类特征,它记录了房屋的建造年份 ' YearBuilt ' 与改建年份 ' YearRemodAdd ' 是否相同。第二个是数值特征,它在第一个特征为“是”的情况下,记录了二者的时间差(YearRemodAdd - YearBuilt)。房屋建造时间是否晚于1980年和是否早于1960年也是新添的两个二分类特征,其余所有特征如下表所示。

基于对 'Garage Year Built' 中的缺失情况的仔细分析、它的高相关性以及由它构造出的新特征,对其采取了删除措施。因为它对自变量的影响已被更简单的特征所代替。
特征变换
——对4个特征进行了变换以校正其分布图中所观察到的偏斜情况。
观察到 'LotAre' 的分布异常,需要对其进行变换。对数变换之后得到了更好的分布,如下图所示:
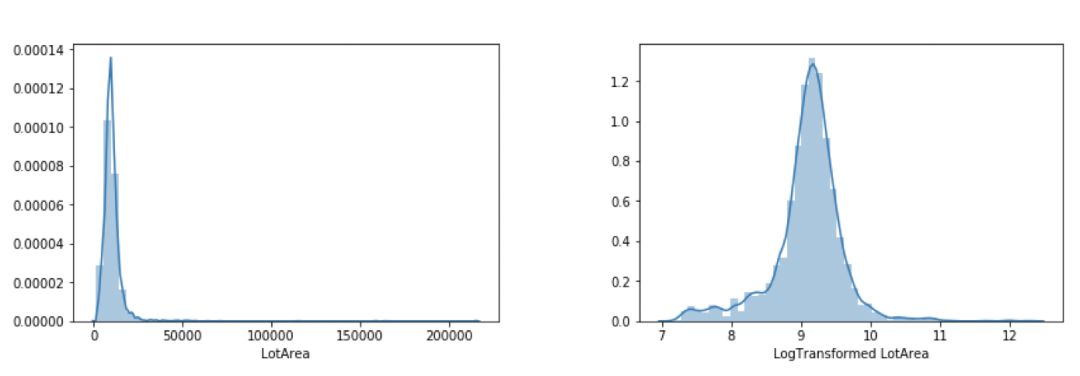
LotArea特征的变换
另一个需要进行变换的特征是 'GroundLivingArea' ,它的分布向右倾斜,进行对数变换之后也得到了更好的分布,如下图所示:
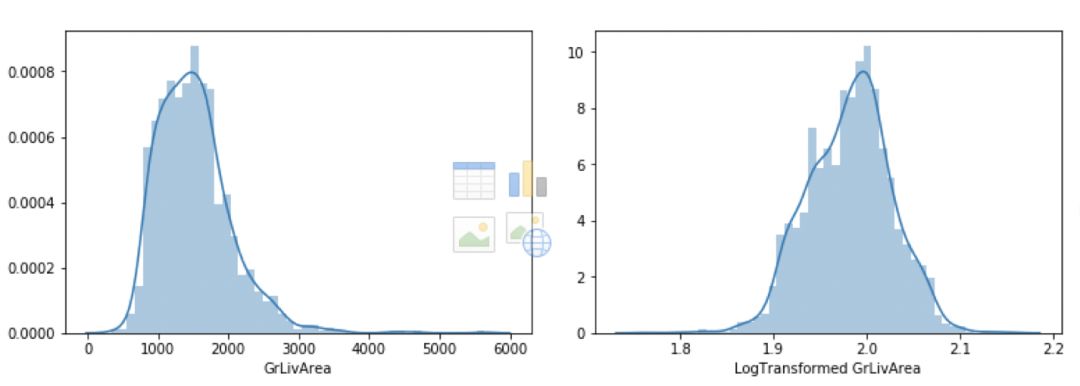
GroundLivingArea特征的变换
其他两个特征中,'First Floor Square Footage' 特征也进行了对数变换,'Lot Frontage' 则进行了box-cox变换。
最后一个进行特征变换的是因变量 'SalePrice '。在目标变量中观察到的向右倾斜经过对数变换,修正为正态分布。
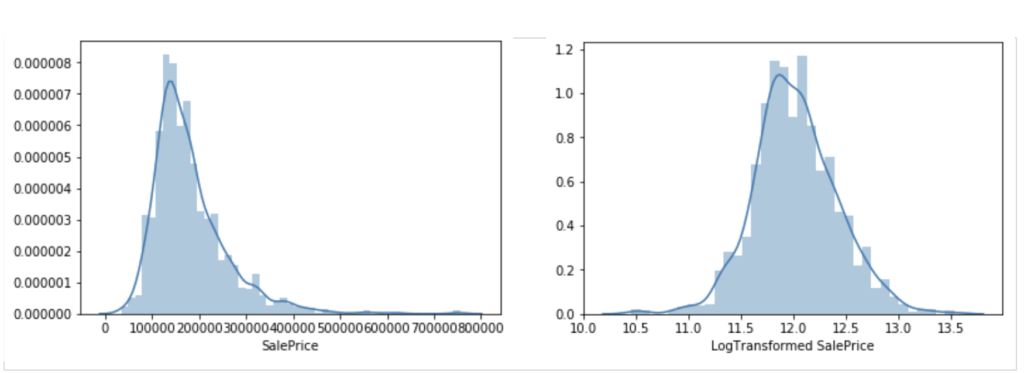
目标变量 —— SalePrice的变换
特征虚拟化——在建模之前对分类型特征进行哑编码。经过特征添加、删除和变换后,数据框中包含87个特征和2919条观测值:

在哑编码和从每个哑编码后的特征中删除一个哑变量之后,有201个列添加到数据框中,总共有288个特征。

建模
将合并后的数据框重新拆分为训练数据框和测试数据框,其中训练集包括1460条观测值,测试集包括1459条观测值。总共有5个模型在训练集上进行了训练。
基于线性的回归——即Ridge,Lasso和ElasticNet是为预测而构建的第一批模型。之所以使用这些惩罚多元线性回归技术,是因为它们可在最小化预测误差时调节特征之间的多重共线性。
岭回归——对于该模型,完成了交叉验证所需折叠次数的试验,如下图所示:
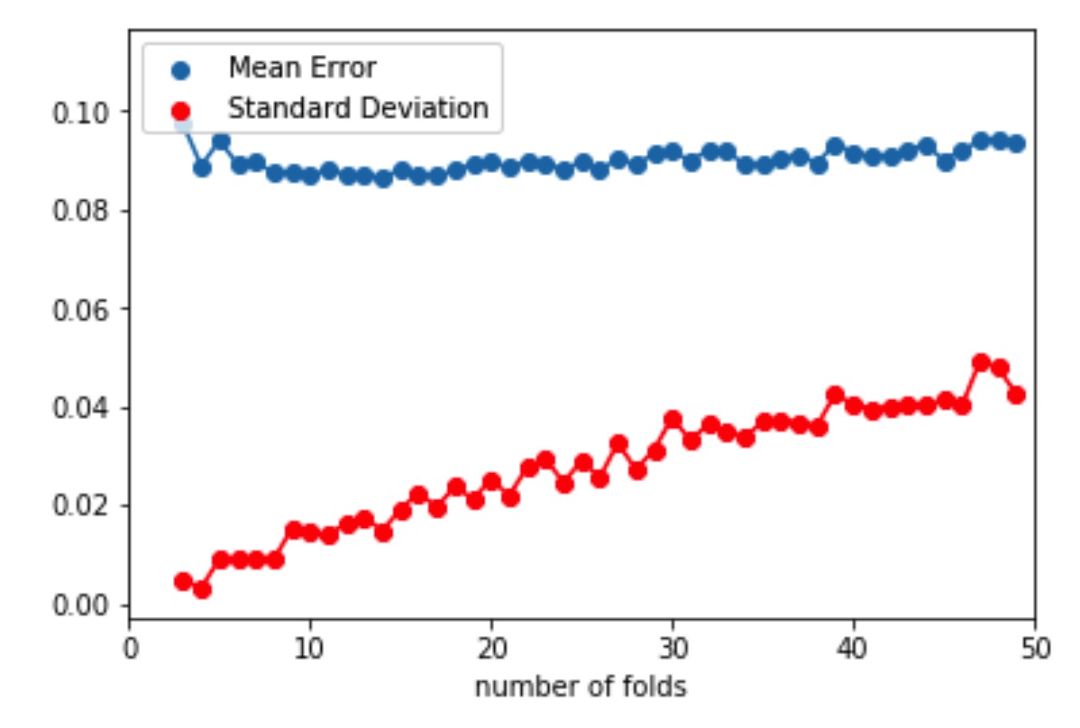
从图中可以看出,随着折叠次数的增加,标准偏差也随之增加,而平均误差保持不变,使用的折叠次数为10。
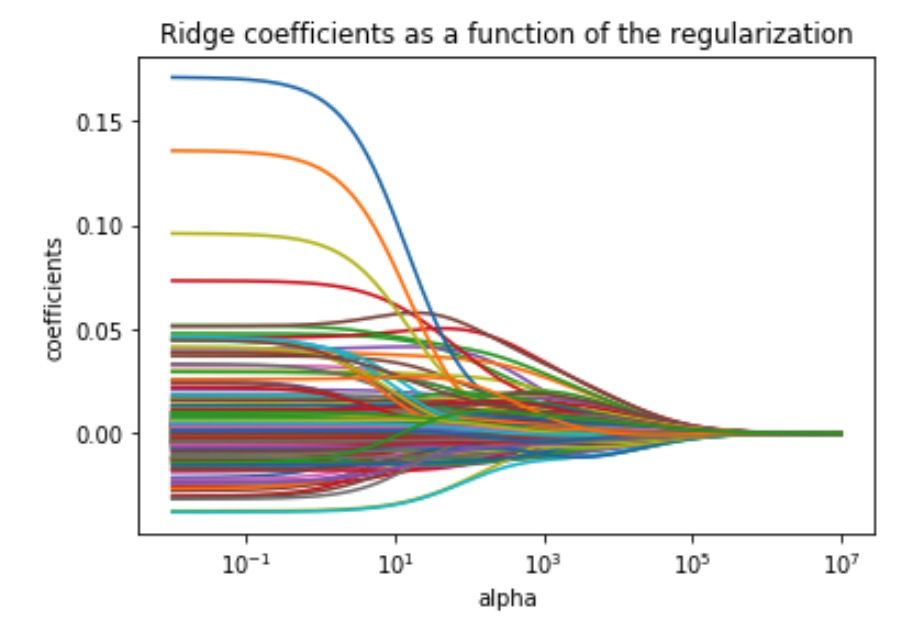
岭回归系数与正则化/惩罚强度折线图
上图为岭回归系数与正则化/惩罚强α折线图。随α的增加,系数也随着减小收缩到0。不仅系数减小,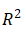 (量度变量与回归直线接近程度的统计量)也随之下降。这意味着该模型减少了方差,也因此引入了偏差但产生了减少的预测误差 ——“偏差-方差权衡”。令alpha = 10,tol = 1e-05,solver ='svd',得到最佳交叉验证得分0.1132。
(量度变量与回归直线接近程度的统计量)也随之下降。这意味着该模型减少了方差,也因此引入了偏差但产生了减少的预测误差 ——“偏差-方差权衡”。令alpha = 10,tol = 1e-05,solver ='svd',得到最佳交叉验证得分0.1132。
Lasso回归——Lasso回归同岭回归一样,也是正则化模型,用来减轻多重共线性的影响。在超参的优化基础上,令alpha = 10,max_iter = 25,得到最佳交叉验证得分0.1147。
Elatic-Net模型——这是一个将岭回归和Lasso惩罚强度结合起来的正则化模型。
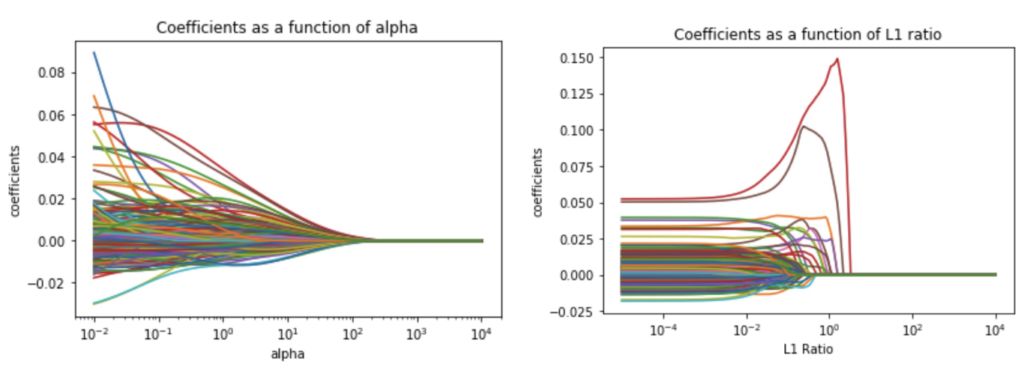
同样,与其他惩罚模型一样,随着α的增加,系数缩小为0,如同从特征的图形表示中观察到的那样,它们完全从lasso下降到零。经过调参得到最佳参数是l1_ratio = 0.001和α=0.1,得到交叉验证得分0.11204。
基于树的模型——训练了三种基于树的模型,即支持向量机(SVM),梯度增强回归(Gradient Boosting Regressor)和XGBoost。
支持向量回归——对于这个基于树的模型,需要3个主要参数来指示模型的最优调参,它们是gamma,epsilon和C。其中C的影响最大,它是一个调整参数,如同epsilon一样,有助于确定可容忍的违规边界和超平面的阈值。
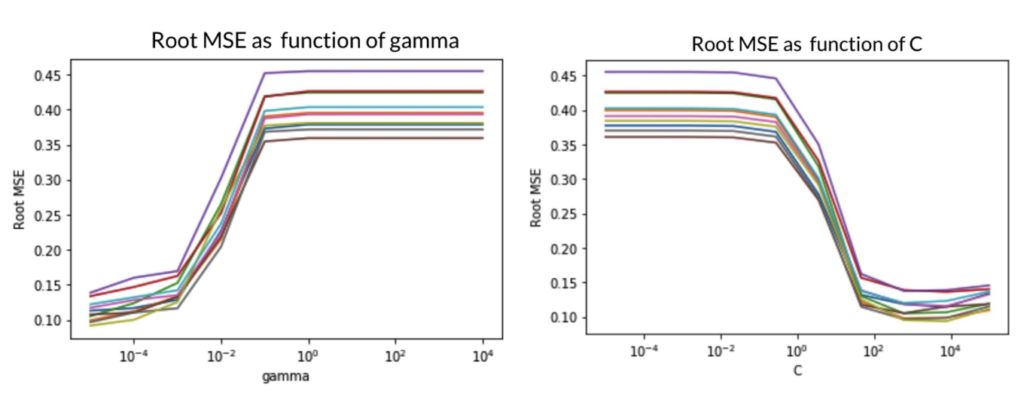
由网格搜索法得到回归的最佳参数是gamma = .000001,C = 100,epsilon = 0,它们也可从图像中观察得到。对于低均方根误差,需要低gamma值和高C值。
其他模型有:
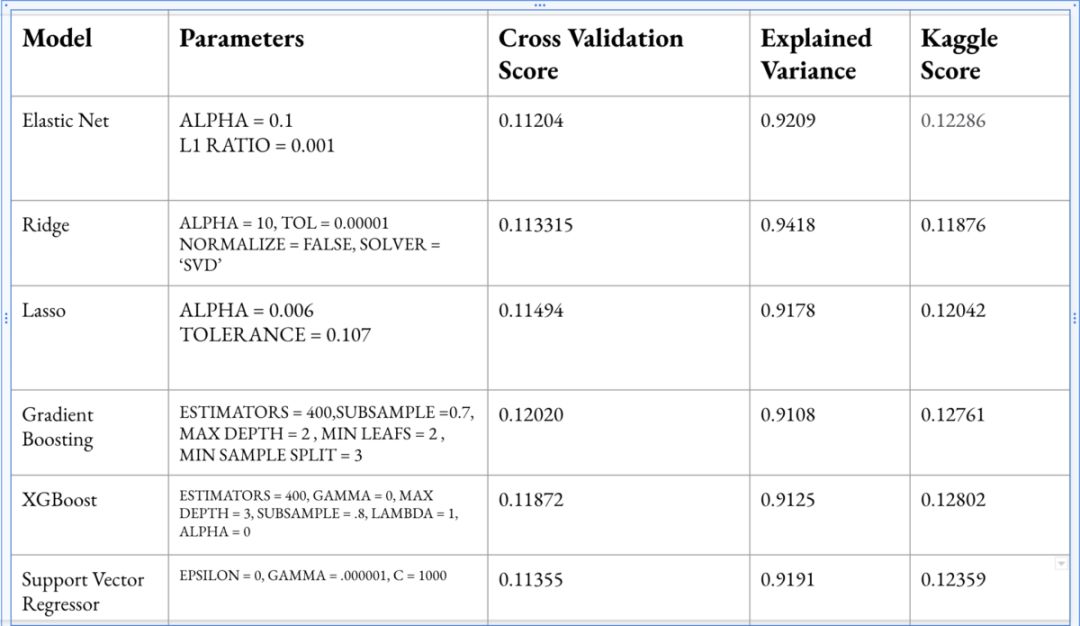
Gradient Boosting Regressor——此模型的交叉验证得分为0.12020; 和XGBoost ——最后训练的模型得出了0.11872的交叉验证分数。
下面的表格显示了所有使用的模型以及它们的运行情况,而不局限于本地模型,还包括kaggle。岭回归的kaggle得分为0.12286,位居kaggle整体排名的前20%。
特征重要性
使用基于树的模型,绘制了特征重要性图,首先来自梯度增强回归模型:
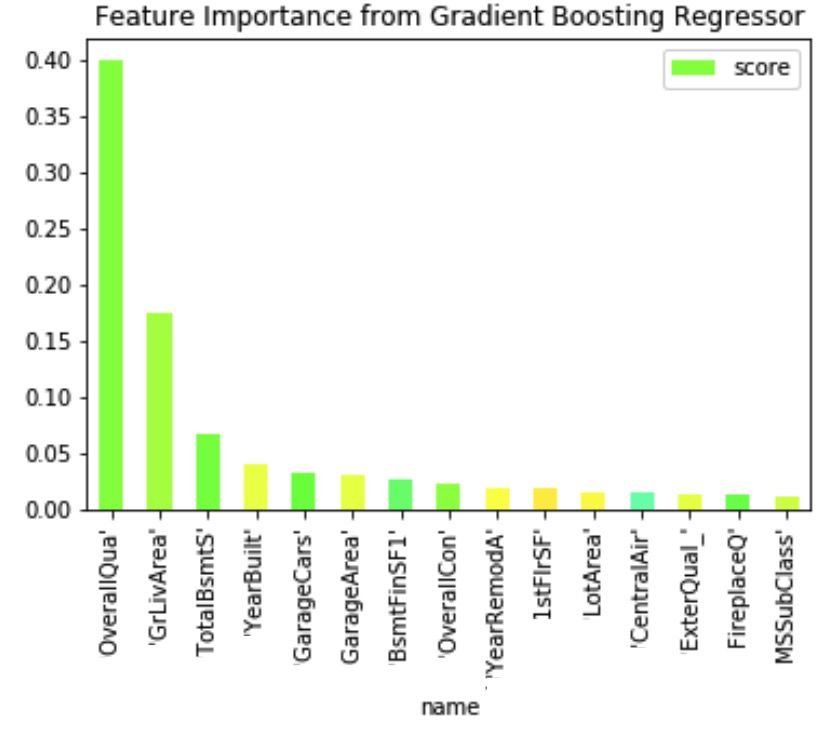
'OverallQua' 特征是对房屋的整体材料和完成度进行评级,根据梯度增强回归模型,其对预测的影响最大。这并不奇怪,因为房屋的销售价格会随着其质量的提高而提高。在预测中具有高度重要性的下一个特征是 'GrLivArea',它以平方英尺为单位测量房屋的生活区域,这意味着房屋的大小会影响其价格,而模型也捕捉到了这一点。在分析特征重要性时,我首先想到的是相关矩阵。
高度相关(> 80%)的特征是否对预测产生相同的影响?在文章前部分,可看到 'GrLivArea' 与 'TotRmsAbvGrd' 有83%的相关性,这意味着以平方英尺为单位所测量的生活区域和地上的总房间数是相关的。然而,在观察到的特征重要性中,尽管 'GrLivArea' 的影响非常大,'TotRmsAbvGrd' 并不在重要特征的前15名中。这个模型的表现说明梯度增强回归在多重共线性上非常鲁棒。
用于分析特征重要性的另一个模型是随机森林:
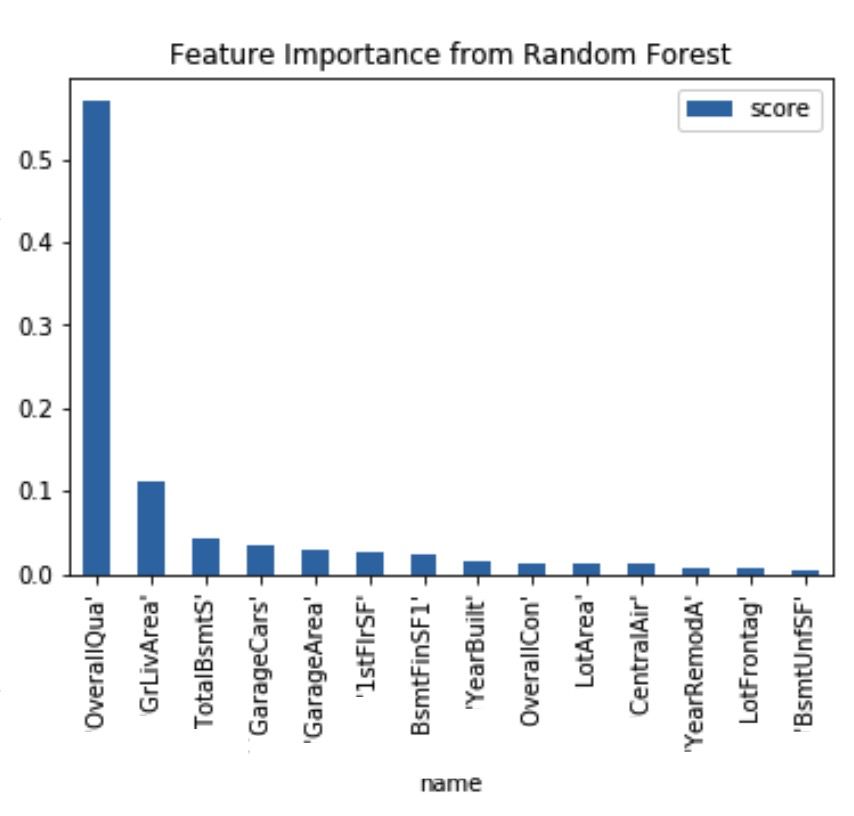
从随机森林模型获得的特征重要性与从梯度增强模型获得的特征重要性非常相似。两个模型的前3个重要的特征完全一样,虽然它们对模型的影响程度不同。同样,与梯度增强一样,随机森林对多重共线性具有鲁棒性,因为它为随机森林中的每棵树选择随机特征子集。
未来的工作
集成模型以查看是否可以改进整体预测。
这项研究由三位数据科学研究员参与:Oluwole Alowolodu,David Levy和Benjamin Rosen。
原文标题:
House price prediction using machine learning
原文链接:
https://nycdatascience.com/blog/student-works/machine-learning/house-price-prediction-using-machine-learning/
编辑:王菁
校对:洪舒越
李润嘉,首都师范大学应用统计硕士在读。对数据科学和机器学习兴趣浓厚,语言学习爱好者。立志做一个有趣的人,学想学的知识,去想去的地方,敢想敢做,不枉岁月。
18各行业,106个中国大数据应用最佳实践案例:
(1)《赢在大数据:中国大数据发展蓝皮书》;
免费试读:https://item.jd.com/12058569.html
(2)《赢在大数据:金融/电信/媒体/医疗/旅游/数据市场行业大数据应用典型案例》;
免费试读:https://item.jd.com/12160046.html
(3)《赢在大数据:营销/房地产/汽车/交通/体育/环境行业大数据应用典型案例》;
免费试读:https://item.jd.com/12160064.html
(4)《赢在大数据:政府/工业/农业/安全/教育/人才行业大数据应用典型案例》。
免费试读:https://item.jd.com/12058567.html
推荐文章
微信ID:SDx-SoftwareDefinedx
❶软件定义世界, 数据驱动未来;
❷ 大数据思想的策源地、产业变革的指南针、创业者和VC的桥梁、政府和企业家的智库、从业者的加油站;
❸个人微信号:sdxtime,
邮箱:sdxtime@126.com;
=>> 长按右侧二维码关注。

 底部新增导航菜单,下载200多个精彩PPT,持续更新中!
底部新增导航菜单,下载200多个精彩PPT,持续更新中!








