
本文为 AI 研习社编译的技术博客,原标题 :
How a team of deep learning newbies came 3rd place in a kaggle contest
作者 | Mercy Markus
翻译 | linlh、Jenny_0420
校对 | 酱番梨 审核 | 约翰逊·李加薪 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/how-a-team-of-deep-learning-newbies-came-3rd-place-in-a-kaggle-contest-644adcc143c8
注:本文的相关链接请访问文末【阅读原文】
坚持住,还有一天就放假啦!

照片由Alexander Naglestad拍摄于Unsplash
The Women in Data Science组织与她们的合作伙伴共同发起了 WiDS Datathon 的活动。这个活动的挑战在于,你需要建立一个预测卫星图像中油棕种植园存在的模型。Planet and Figure Eight慷慨地提供了地球卫星最近拍摄的卫星图像的注释数据集。数据集图像具有3米的空间分辨率,每个图像都基于图像中存在的油棕种植园进行标记(0表示无种植园,1表示有种植园)。任务是训练一个模型,该模型将卫星图像作为输入,并输出包含油棕种植园的图像可能性预测。标号训练和测试数据集由竞赛创建者提供用于模型开发。点此了解更多。
我和我的队友(Abdishakur、Halimah和Ifeoma Okoh)在这个挑战中使用了Fast.AI框架。多亏了Thomas Capelle在Kaggle上的入门内核,它为如何解决这个问题提供了很多洞见,同时也为Fast.ai团队创建了一个令人惊叹的深度学习课程,简化了许多困难的深度学习概念。现在,初学者深入学习,就可以赢得 kaggle 比赛。
让我们开始:一个简单易学的深度学习教程
现在不要担心什么都懂,这需要大量的练习。本教程旨在向您展示,对于初学者来说,fast.ai 到底有多厉害。我假设你懂一点点Python,而且你也接触过一些机器学习。如果你满足了上述那些条件,万事俱备,咱们开始吧!
这里显示的所有代码都可以在谷歌协作实验室上使用;这是一个免费的Jupyter笔记本环境,不需要设置,完全在云中运行。通过协作,您可以编写和执行代码,保存和共享您的分析,以及访问强大的计算资源,所有这些都是免费的。单击此处访问我们将使用的代码。
导入 fast.ai 和其他需要用到的库:
导入库
获取比赛的数据
为了让获取数据更加简单直接,Abdishakur 把比赛的数据文件上传到了dropbox.com。你可以在比赛的页面中找到。你需要同意比赛的规则才能够获取这些数据。
查看数据
当我们面临一个问题第一件需要做的事情就是看下手上的数据。在找到解决的方法之前,我们需要理解这个问题并且看下数据长什么样。看数据意味着理解数据是如何构成的,数据的标记(label)是怎样的,以及示例图片张是怎样的。

使用pandas库来读取数据:
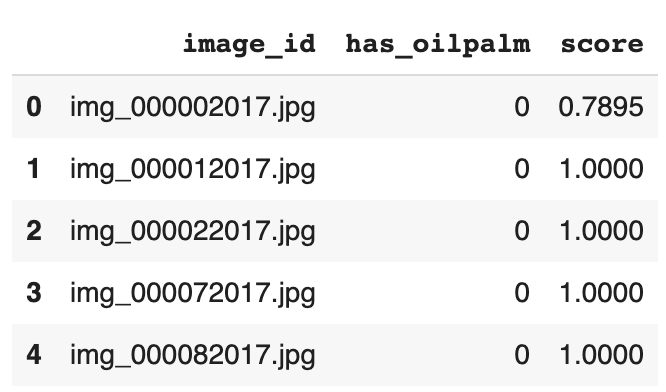
用于训练模型的数据标记
在处理图像分类数据集和表格式数据集最大的差别在于标签的存储方式。标签在这里指的就是图像中的内容。在这个比赛的数据集中,标签是存储在CSV文件中的。
要了解表格中score这一列是如何计算得到的,请查看原文。
使用seaborn库的countplot函数来绘制训练数据的分布。从图形中,我们可以看到14,300张图片中没有包含油棕人工林(oil palm plantations),而942张图片中是有的。这个就是称之为不平衡的数据,这属于深度学习的问题,在这里不展开。

两个类别的统计
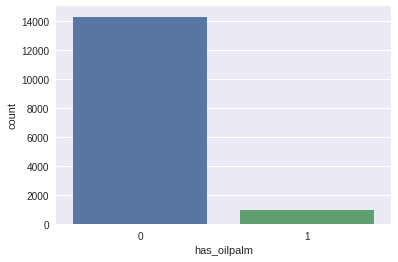
训练数据集的分布
测试数据提供在两个分开的目录中,the leaderboard holdout data 和 leaderboard test data。我们要将这两个结合起来,因为这是比赛的要求,提交对两个数据集的预测结果。总的共有6534张图像。
 整合 leaderboard holdout data 数据 leaderboard test data
整合 leaderboard holdout data 数据 leaderboard test data
在这里我们使用 fast.ai 的DataBlock API来结构化数据,这是一个非常方便的方式来将数据喂给我们的模型。
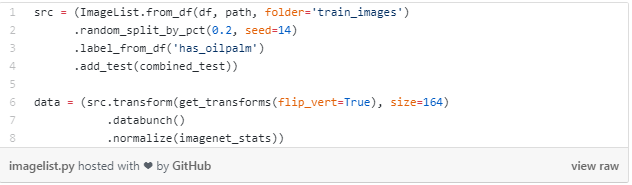
创建一个ImageList来存放数据
使用ImageList来保存训练数据,和使用from_df方式。这样做的原因是因为存储测试集信息的数据格式叫做df。告诉程序该去哪里找到训练图片:path,和保存图片的文件夹:train_images。
接下来,随机分配训练集。保留20%的数据在训练过程中衡量模型的性能。选定一个种子保证当我们重来的时候结果相同。我们需要确保知道哪些有效而哪些没有。
告诉ImageList哪里找到数据的标签,以及我们刚刚整合的测试数据。
最后,在数据上执行变换。设置 flip_vert = True 来翻转图片,这样可以使得不管图片旋转了某个方向模型都可以识别。使用 imagenet_stats来标准化图片。(注:这个是迁移学习的技巧)
下面是带有和不带有油棕人工林的卫星图片:

展示两批图片

有油棕人工林的标签为1,没有的为0
现在开始训练模型。使用卷积神经网络作为主干和resnet模型中预训练好的权重,resnet模型是被训练好用于大量图片分类的模型。不用担心这具体的意思是什么。现在,我们构建一个模型能够输入卫星图像,并且能输出属于两个类别的概率。

卷积神经网络

找到最优模型学习率
接下来,使用 lr_find() 来找到最理想的学习率,使用recorder.plot()可视化这个过程。
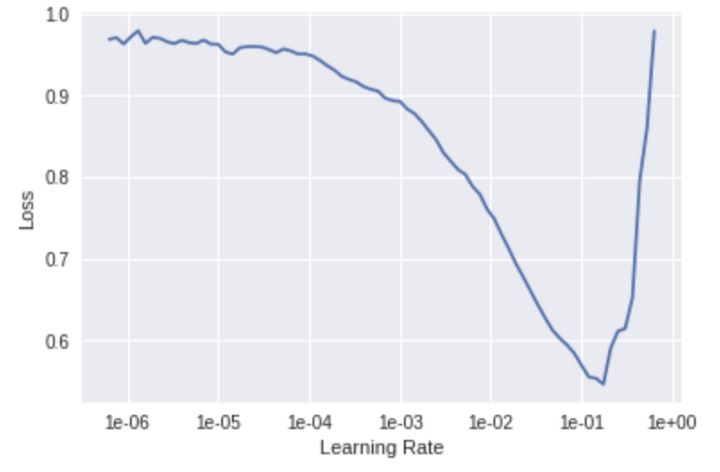
找到最优的模型学习率
在这个图像中选择最接近曲线斜率最陡峭的地方:1e-2,作为我们的学习率。

用学习率 = 1e-2训练模型循环5次
这里我们会使用 fit_one_cycle 函数训练模型5轮( 在所有的data上循环5次)
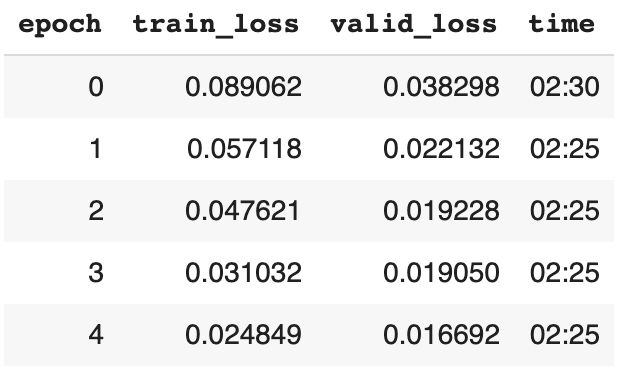
训练和验证的损失
有注意到上图矩阵表格中training_loss和valid_loss在逐渐消失吗?使用这些来监测模型性能的改善随着时间的变化。
最好的模型在第4轮训练完得到。
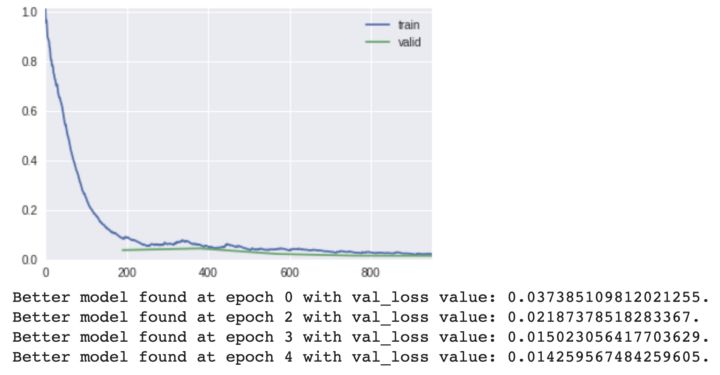
训练模型的输出; 训练和验证损失的变化
当运行训练和验证数据集时,fast.ai 内部会选择和保存最优的模型。
比赛提交是基于在预测可能性和观察到目标, has_oilpalm之间的接收器工作特性曲线下的面积( the Area under the Receiver Operating Characteristic curve )。想要学习更多关于AUC曲线的知识可以看这个开发者速成课程,这个视频,或者是Kaggle学习论坛的帖子。Fast.ai默认没有提供这个方法,这里我们使用 scikit-learn 库。
打印出验证矩阵
使用预训练的模型和fast.ai的美在于你可以获得一个非常好的预测准确率,在这个例子中没有花费太多力气就达到了99.4%。

第一阶段训练的矩阵信息
保存模型并绘制关于预测的混淆矩阵
learn.save('resnet50-stg1')

绘制混淆矩阵
混淆矩阵是以图形化的方式来查看模型对于图片确和不正确的预测结果。
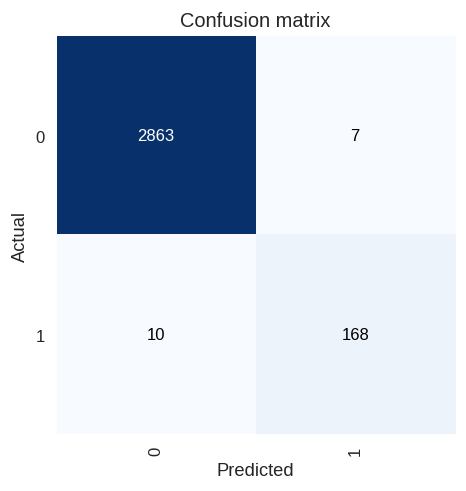
第一阶段训练的混淆矩阵
对于这个图形,我们看到模型正确预测了2,863张没有油棕人工林的图像,168张图像有油棕人工林是正确分类的。10张图片含有油棕人工林但是被分为没有油棕人工林,7张图片是没有包含油棕人工林但是被分类为有油棕人工林。
对于一个简单的模型这个效果还不错。
接下来,我们为训练迭代找一个理想的学习率。

找一个理想的学习率
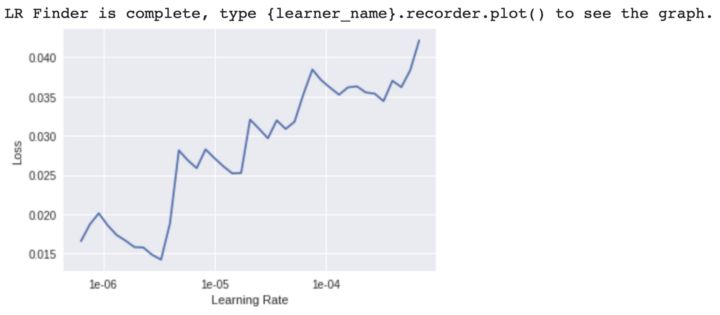
选择介于1e-6到1e-4之间的学习率
使用最大化的介于1e-6到1e-4之间的学习率喂给模型,并训练7轮。

训练7轮模型,学习率不超出1e-6到1e-4的范围。
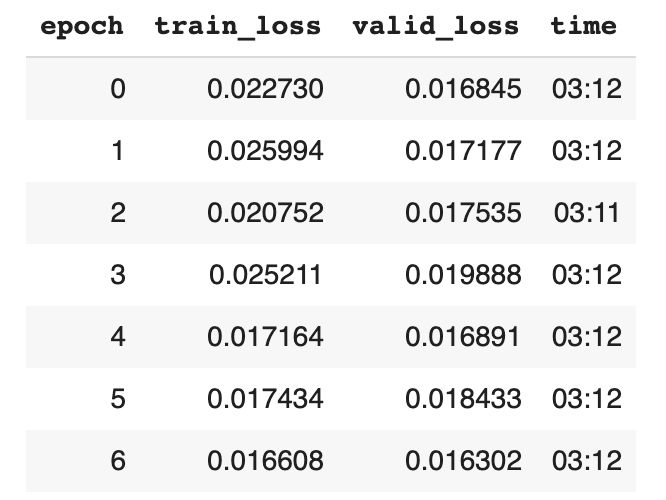
训练和验证的损失
图形化的方式观察矩阵参数来监视模型在每轮训练后的性能。
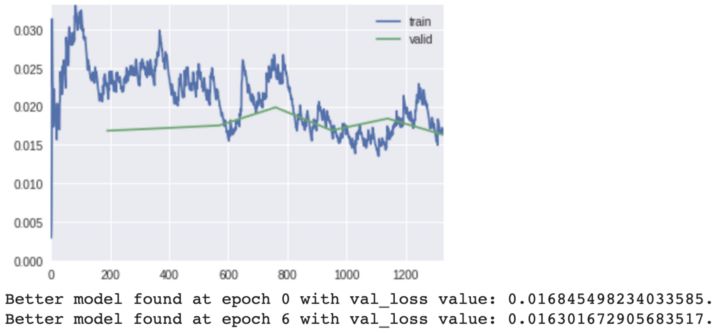
训练模型的输出;训练和验证损失的变化
保存第二阶段训练的模型。
learn.save('resnet50-stg2')

准确率, 错误率和AUC分数
打印出模型的准确率,错误率,曲线下面积的度量。

第二阶段训练的指标信息
正如你所看到的准确率从99.44%提升到了99.48%。错误率从0.0056降低到了0.0052。AUC也同样有进步,从99.82%变到了99.87%。

绘制混淆矩阵
经过和上次绘制的混淆矩阵的对比,你会发现这个模型能够得到更好的预测结果。
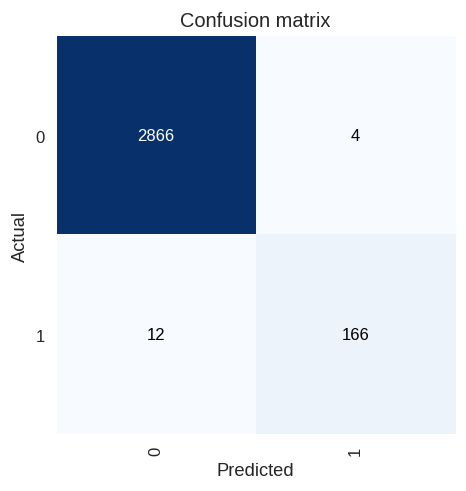
第二阶段训练的混淆矩阵
相比前面来说,错误分类了7张没有包含油棕人工林的图片,现在降到了3张,这是一种进步了。
你会发现,在训练的过程中,我们遵循着一个模式:训练过程中调整少量的参数。这个过程就称之为微调。大部分的深度学习实验都遵循一个相似的迭代模式。
图像变换
在数据上做更多的图像变换,这样能够帮助改善我们的模型。关于每一种转换可以在fast.ai的文档中找到描述。
在图像上应用不同的转换来改善模型
max_lighting: 如果设置为None,由max_lighting控制的随机亮度和对比度,按照p_lighting的概率应用
max_zoom : 如果不是1或者比1小的值,随机选择1到max_zoom的值按照概率p_affine的值应用
max_warp : 如果设置为None,在-max_warp到max_warp之间随机确定对称扭曲的程度,按照概率p_affine应用
重新找到一个最优的学习率。

找到一个理想的学习率
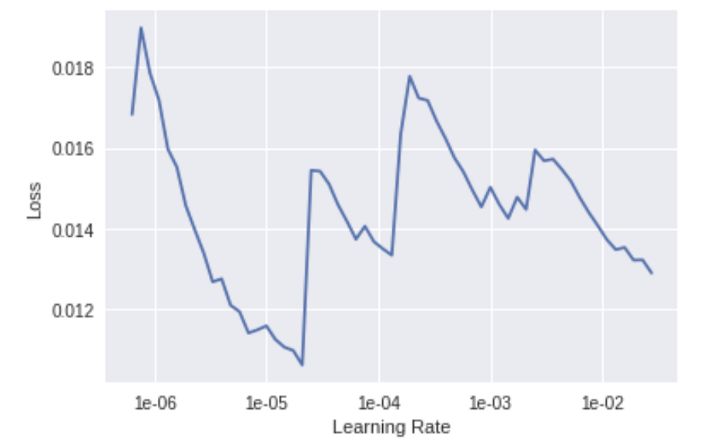
选择1e-6的学习率
训练模型5轮

训练5轮
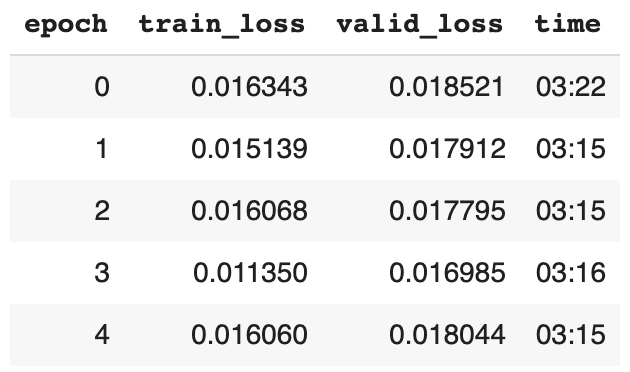
训练和验证的损失
对于训练的参数和之前的参数,我们的模型稍微在迭代0.0169对比0.0163更差了。不要感到失望。
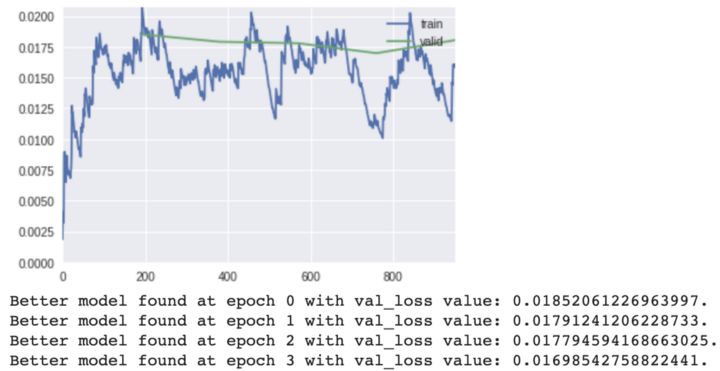
模型训练的输出,最好的模型是在第3轮训练
保存第三阶段的训练模型,并打印出指标信息。可以看到现在模型的准确率是99.38%,上个阶段是99.48%。AUC分数从99.87%提升到88.91%,这个是比赛进行评判的指标。
learn.save('resnet50-stg3')

准确率,错误率和AUC分数

第三阶段训练的指标
不知道你有没有注意到我们一开始的图像设置size=164,然后我们慢慢的增加到了size=256,就像下面这样的做法。这样做是为了运用fast.ai在分类中逐步改变图片的大小。比如说训练开始的时候使用比较小的图片,然后随着训练的进行慢慢提升图片的大小。这种方式在开始时模型会非常不准确,但是在看了大量图片之后会突然变化,并取得巨大的进步,在后面的训练中,模型能够识别更大的图片来学习图片中细微粒的差别。想要了解更多,点击这里。
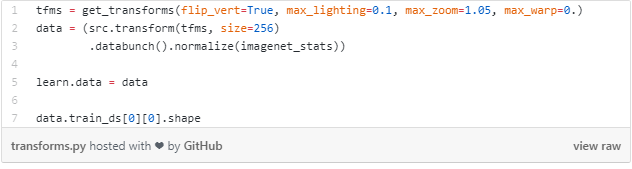
应用不同的变换来提升模型,图片大小增加到256
再次寻找最优的学习率。

找一个理想的学习率
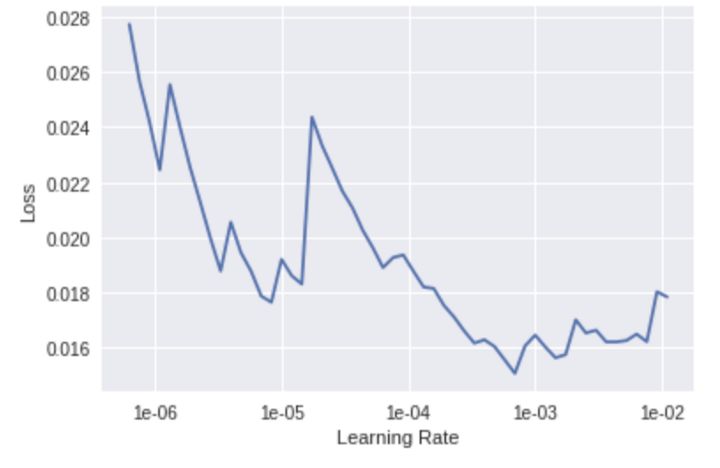
找一个理想的学习率
用学习率为1e-4训练5轮模型

训练5轮模型,学习率设置为1e-4
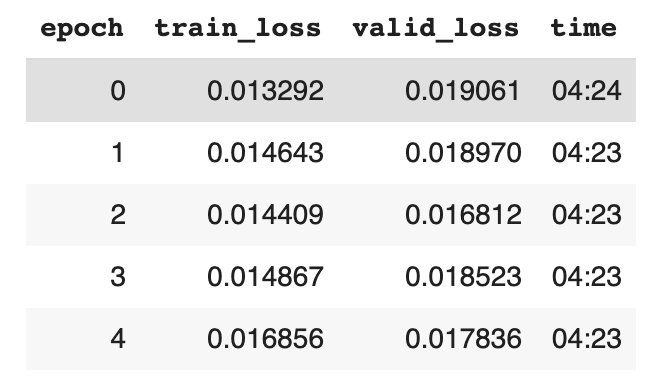
训练和验证损失
可以看到训练指标和之前的对比,我们的模型有了小小的提升,从0.0169变成0.0168。
模型训练的输出; 最好的模型在第2轮训练
保存最后阶段的模型,并打印出指标信息。
learn.save('resnet50-stg4')

准确率,错误率和AUC分数
你会注意到模型的准确度现在是99.44%,上一次训练阶段的改进率为99.38%。

第四阶段训练的指标
现在可以看到我们的模型能够对数据做出多好的预测了。
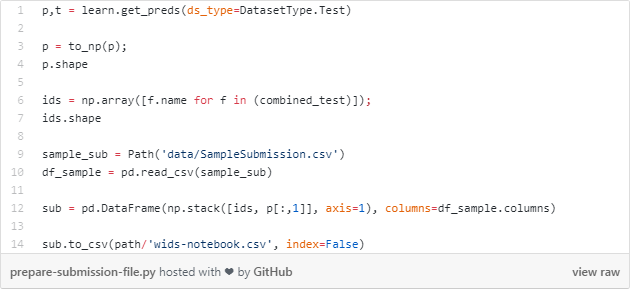
准备一个CSV提交文件
现在还可以进入WiDS比赛中,并提交你的结果。直接去到比赛的页面中,点击加入比赛,然后接受比赛的规则。之后就可以提交的预测结果了,看看你参加了这个比赛的成绩排在怎样的位置吧。

模型预测的结果得到私有测试集和公开测试集的分数
免责声明:这个教程不会使得你和我们一样排在第三名,我想把这些按照最简单的语言表达出来。如果想要知道更详细的,查看 Abdishakur的帖子。
想要学习更多的内容吗?了解下Jeremy Howard和fast.ai团队制作的非常棒的课程当中的第七部分吧。
AI研习社友情提示:学习道路千万条,不看原文就一条。
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1660









