 标星★公众号 爱你们♥
标星★公众号 爱你们♥
作者:Ali Alavi、Yumi、Sara Robinson
编译:公众号进行了全面整理
近期原创文章:

刚刚巴菲特开完股东大会,特朗普又在Twitter来了一出。让股票市场跌宕起伏。

这也诞生了一个新词:
一推就倒
▍形容一条Twitter就吓得屁滚尿流,崩溃倒下的东西,多用于股市。
接下来我们就应用技术手段,基于Python,建立一个工具,可以阅读和分析川普的Twitter。然后判断每条特定的Twitter是否具有川普本人的性格。
同时我们还结合了其他的方法,包括Deep Learning、Machine Learning、NLP、LSTM等基于Python、Keras等。
万字干货
对川普的Twitter做个全面分析!
让大家以后面对川普冷不丁的Twitter有所准备!
为了简单起见,我们将每条Twitter分解成单词。
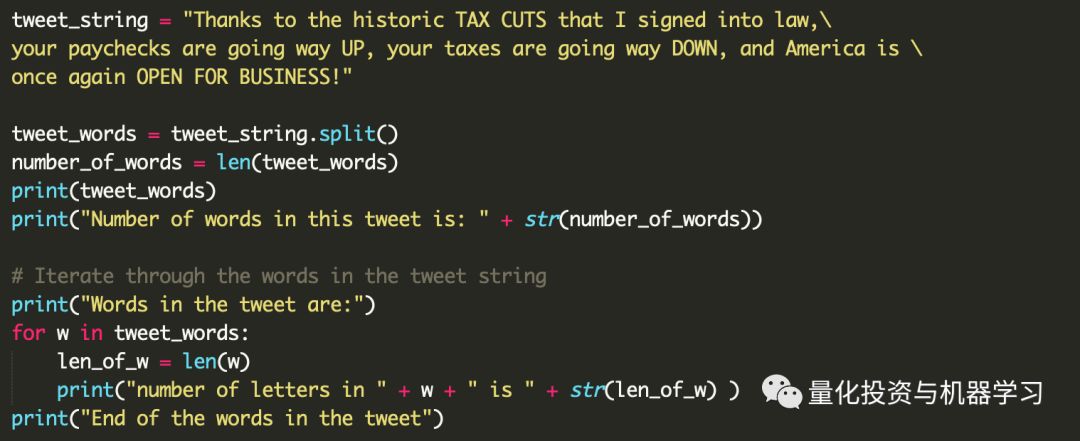
如你所见,我们手动复制了Trump的一条Twitter,将其分配给一个变量,并使用split()方法将其分解为单词。split()返回一个列表,我们称之为tweet_words。我们可以使用len函数计算列表中的项数。在第4行和第5行中,我们打印前面步骤的结果。注意第5行中的str函数。为什么在那里?
最后,在第9行中,我们循环遍历tweet_words:也就是说,我们逐个遍历tweet_words项,将其存储在w中,然后在第10行和第11行处理w。所以,第10行和第11行被执行了很多次,每一次都有不同的w值。你应该能够说出第10行和第11行是做什么的。
将此代码保存为first.py。如果你使用Mac或Linux,请转到终端,在保存文件的文件夹中,输入python3.6 first.py,然后按Enter键。在Windows上,您需要在命令提示符下键入py first.py。
在这里,我们尝试改进我们的代码,这样我们就可以知道一条Twitter是“坏”还是“好”。
这里的想法是创建两个由好词和坏词组成的列表,并根据它们从这些列表中包含的词数增加或减少推文的值。

因此,在第16行和第17行中,我们初始化了两个值,每个值表示一条Twitter中好词和坏词的数量。在第19行和第20行中,我们创建了好单词和坏单词的列表。当然,这些都是非常主观的列表,所以请根据你自己的个人意见随意更改这些列表。
在第21行,我们逐个检查了Twitter中的每个单词。在第22行打印之后,我们检查这个单词是否存在于good_words或bad_words中,并分别增加number_of_good_words或number_of_bad_words。如你所见,要检查列表中是否存在项,可以使用in关键字。
另外,请注意if的语法:你需要在条件后面输入colon (:) 。而且,在if中应该执行的所有代码都应该缩进。
到目前为止,我们的假设是,词语不是好就是坏。但在现实世界中,词语的权重各不相同:awesome比alright好,bad比terrible好。到目前为止,我们的代码还没有考虑到这一点。
为了解决这个问题,我们使用名为字典的Python数据结构。字典是一个条目列表,每个条目都有一个键和一个值。我们将这些项称为键值对。因此,字典是键值对的列表(有时称为键值存储)。
我们可以通过在花括号中放入key:values列表来定义字典。请看下面的代码:

正如你所看到的,我们只使用了一个字典。给不好的词一个负的权重,好的词一个正的权重。确保值在-1.0和+1.0之间。稍后,我们使用word_weights字典检查其中是否存在单词,并计算分配给单词的值。这与我们在前面的代码中所做的非常相似。
这段代码的另一个改进是它的结构更好:我们尝试将代码的不同逻辑部分分离到不同的函数中。函数是用def关键字定义的,后跟着一个函数名,后面跟着圆括号中的零个或多个参数。
我们的代码中仍然存在一些明显的缺陷。例如,我们可以假设一个名词,无论是单数还是复数,都具有相同的值。例如,单词 tax 和 taxes 被解释为两个不同的单词,这意味着我们的字典中需要有两个不同的条目,每个条目对应一个。为了避免这种冗余,我们可以尝试对Twitter中的单词进行词干处理,这意味着尝试将每个单词转换为其词根。例如,tax 和 taxes 都将被纳入tax。
这是一个非常复杂的任务:自然语言非常复杂,构建一个stemmer需要花费大量的时间和精力。此外,这些任务以前也做过。那么,为什么要重新发明轮子,尤其是如此复杂的一个?相反,我们将使用其他程序员编写的代码,并将其打包到名为NLTK的Python模块中。
我们可以在命令行中运行pip install nltk来安装NLTK。但是,这将尝试在我们的系统上全局安装模块。这并不好:我们的系统上可能有使用相同模块的程序,安装相同模块的新版本可能会带来问题。此外,如果我们可以将所有模块安装在代码所在的同一目录中,则只需复制该目录并在不同的机器上运行。
因此,我们从创建一个虚拟环境开始。
首先,确保与代码所在的文件夹相同。然后在终端中输入以下内容:

如果你在Windows上,在命令提示符中输入以下内容:

这将在当前文件夹中创建Python的本地副本及其所需的所有工具。
现在,需要告诉你的系统使用Python的这个本地副本。在Mac或Linux上,使用以下命令:

Windows:

如果所有操作都正确,应该会看到命令提示符发生了更改。最有可能的是,您应该在命令行的开头看到(env)。
我们使用pip命令安装Python包。但是首先,让我们运行以下命令来确保我们使用的是最新版本的pip:

当你使用Mac时,要确保运行以下命令:

现在,你可以使用pip命令安全地安装NLTK:

最后,运行Python解释器,运行Python(如果是在Windows上,则运行py),并在解释器中输入以下命令:

应该会弹出一个窗口。 选择包含popular标识符的项目,然后单击download。这将下载popularNLTK模块使用的所有必要数据。
现在我们已经安装了NLTK,让我们在代码中使用它。
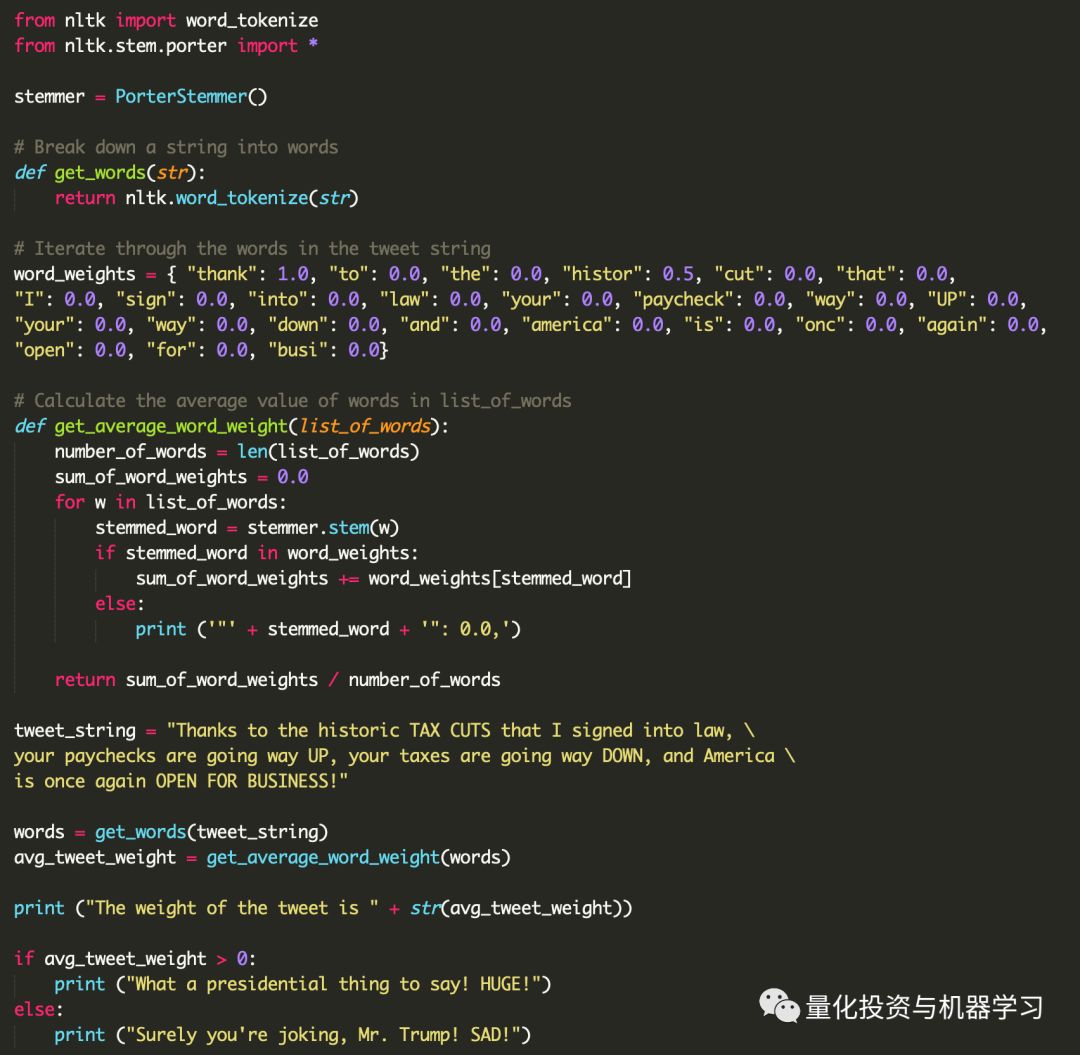
为了使用Python中的模块,我们需要首先导入它。在第11行,我们告诉Python要使用函数word_tokenize,在第12行中,我们说要使用nltk.stem.porter模块中的所有内容。
在第14行中,我们使用PorterStemmer创建了一个stemmer对象,在第18行中,我们使用word_tokenize而不是split来以更智能的方式将Twitter分解为单词。
最后,在第31行,我们使用了stemmer.stem查找单词的词干,并将其存储在stemmed_word 中。其余的代码与前面的代码非常相似。
你应该记得,我们在第20到24行中使用了一个词对词的字典。在我们的程序中有这么长的单词列表是一种不好的做法。想想看,当我们决定更改单词到值的字典时(比如添加一个单词或更改一个单词的权重),我们需要打开并编辑代码。这是有问题的,因为:
1、我们可能会错误地更改代码的其他部分。
2、添加的单词越多,代码的可读性就越差。
3、不同的人使用相同的代码可能想要定义不同的字典(例如,不同的语言、不同的权重……),如果不更改代码,他们就无法做到这一点。
由于这些(以及更多)原因,我们需要将数据从代码中分离出来。换句话说,我们需要将字典保存在单独的文件中,然后将其加载到程序中。
文件有不同的格式,这说明数据是如何存储在文件中的。例如,JPEG、GIF、PNG和BMP都是不同的图像格式,用于说明如何在文件中存储图像。XLS和CSV也是在文件中存储表格数据的两种格式。
在本例中,我们希望存储键值数据结构。JSON数据格式是存储这类数据最常用的数据格式。下面是一个JSON文件的例子:

正如你所看到的,它看起来就像一个Python字典。因此,继续创建一个新文件,并将其命名为“word_weight .json”。

现在,我们需要做的就是告诉Python将这个文件加载到word_weights中。
为了打开文件,我们使用open函数。它打开一个文件并返回一个file对象,该对象允许我们对文件执行操作。每当我们打开一个文件,我们需要关闭它。这确保文件对象上的所有操作都被刷新到文件。
在这里,我们希望加载文件内容并将其分配给一个变量。我们知道文件的内容是JSON格式。所以我们需要做的就是导入Python的json模块,并将它的load函数应用到我们的file对象上:

但明确使用close可能会有问题:在大型程序中,很容易忘记关闭文件,而并且可能会发生关闭在一个块内部,而这个块一直没有执行(例如if)。
为了避免这些问题,我们可以使用with关键字。负责关闭文件。

因此,当代码退出with块时,使用with打开的文件将自动关闭。确保在处理文件时始终使用with编码模式。很容易忘记关闭文件,这可能会带来许多问题。
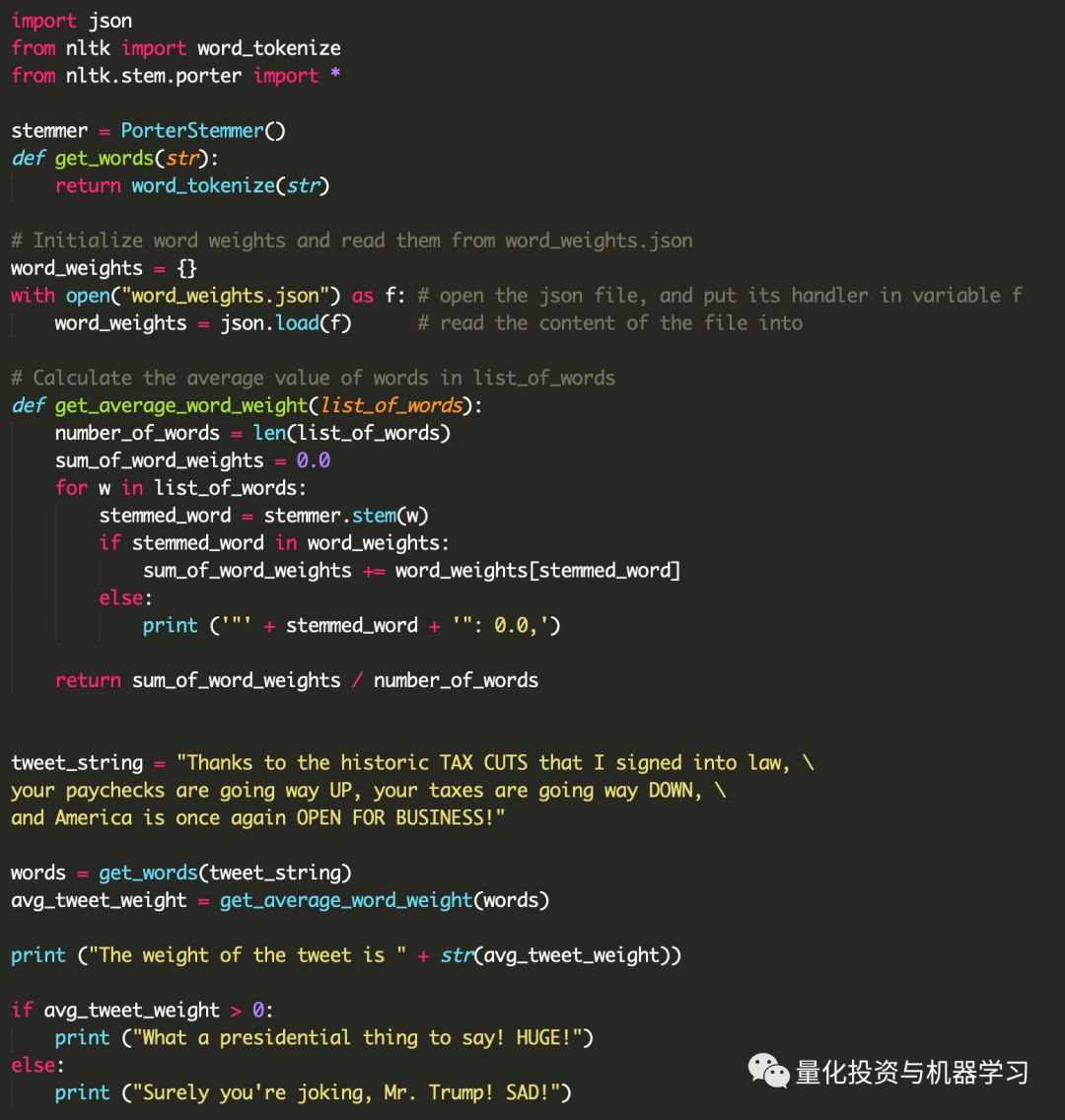
我们可以进一步改进这段代码,将加载JSON文件和分析Twitter转换为两个函数。
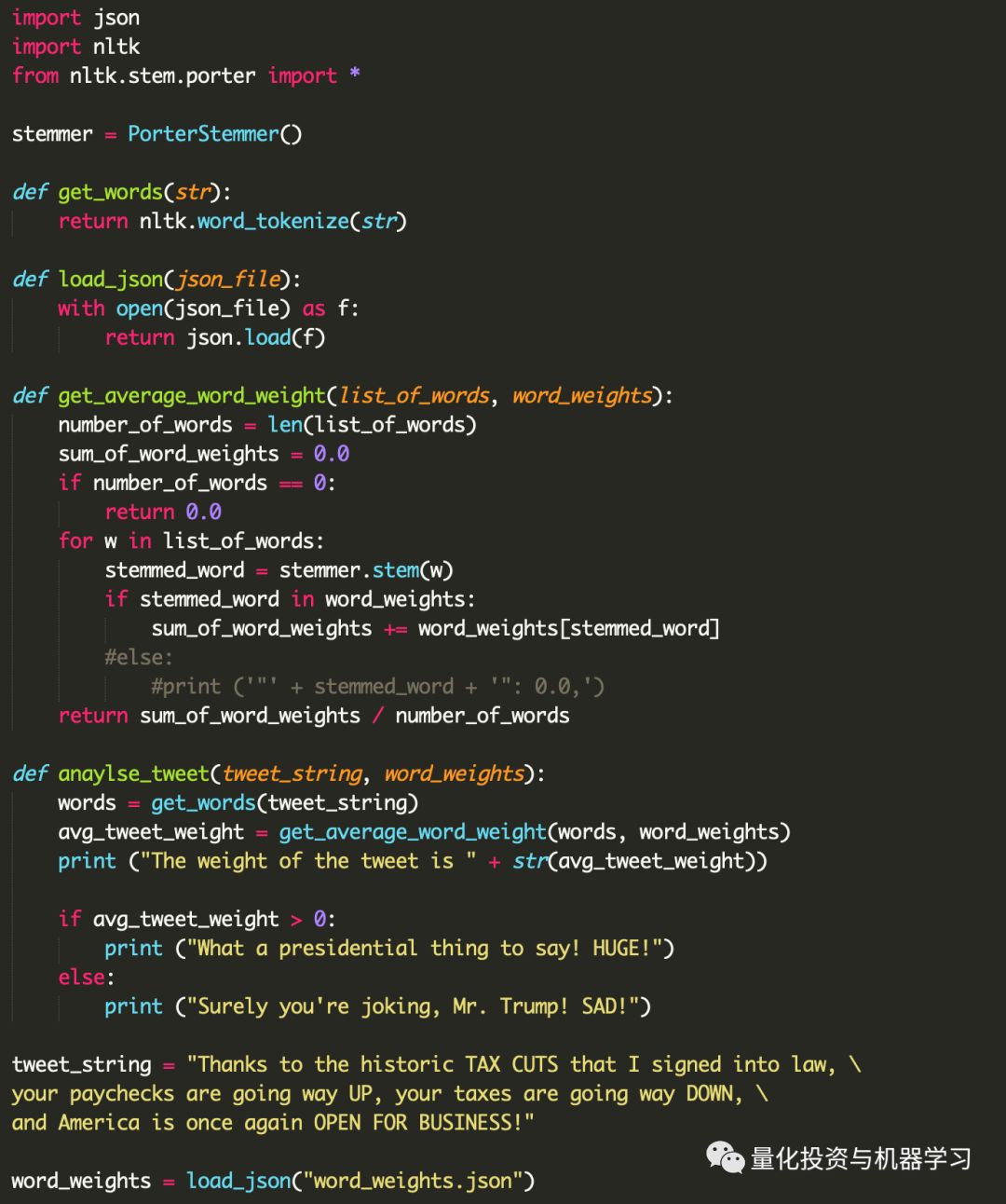
现在,我们的程序所做的就是分配一个Twitter字符串,加载一个单词权重字典,并使用加载的字典分析该Twitter字符串。
为了从Twitter读取数据,我们需要访问它的API(应用程序编程接口)。API是应用程序的接口,开发人员可以使用它访问应用程序的功能和数据。
通常,Twitter、Facebook等公司允许开发人员通过API访问用户数据。但是, 你可能知道,用户数据对这些公司非常有价值。此外,当涉及到用户数据时,许多安全和隐私问题就会出现。因此,这些公司希望跟踪、验证和限制开发人员及其应用程序对其API的访问。
因此,如果您想访问Twitter数据,首先需要登录Twitter(如果您没有Twitter帐户,则需要登录),然后访问https://apps.twitter.com/。单击Create New App按钮,填写表单,然后单击Create your Twitter Application按钮。
在新页面中,选择API Keys选项卡,并单击Create my access token按钮。将生成一对新的访问令牌,即Access令牌密钥。。将这些值与API密钥和API密钥一起复制。
现在,启动终端或命令提示符,转到工作目录,然后激活虚拟环境(提醒:如果你在Mac / Linux上运行.env / bin / activate,如果你在Windows上运行env / Scripts / activate )。现在,使用pip安装python-twitter包:

这将安装一个popular包,用于在Python中使用Twitter API。
https://github.com/bear/python-twitter

现在,让我们快速测试一下我们的设置。
通过输入Python来运行python解释器(如果在Windows上,则输入py)。输入以下内容,并使用上一步复制的值替换你的:
_consumer_key、YOUR_CONSUMER_SECRET、YOUR_ACCESS_TOKEN和YOUR_ACCESS_TOKEN_SECRET:

我们还可以使用GetUserTimeline方法Twitter API获取用户的tweet。例如,要想获取川普的最后一条推文,只需使用以下内容:

这将为我们提供一个包含一个项目的列表,其中包含关于川普最后一条推文的信息。我们可以得到关于Twitter的不同信息。例如:
last_tweet.full_text将提供他最后一条推文的全文。
利用我们获得的关于Twitter API的知识,我们现在可以更改代码来从Twitter加载推文字符串。
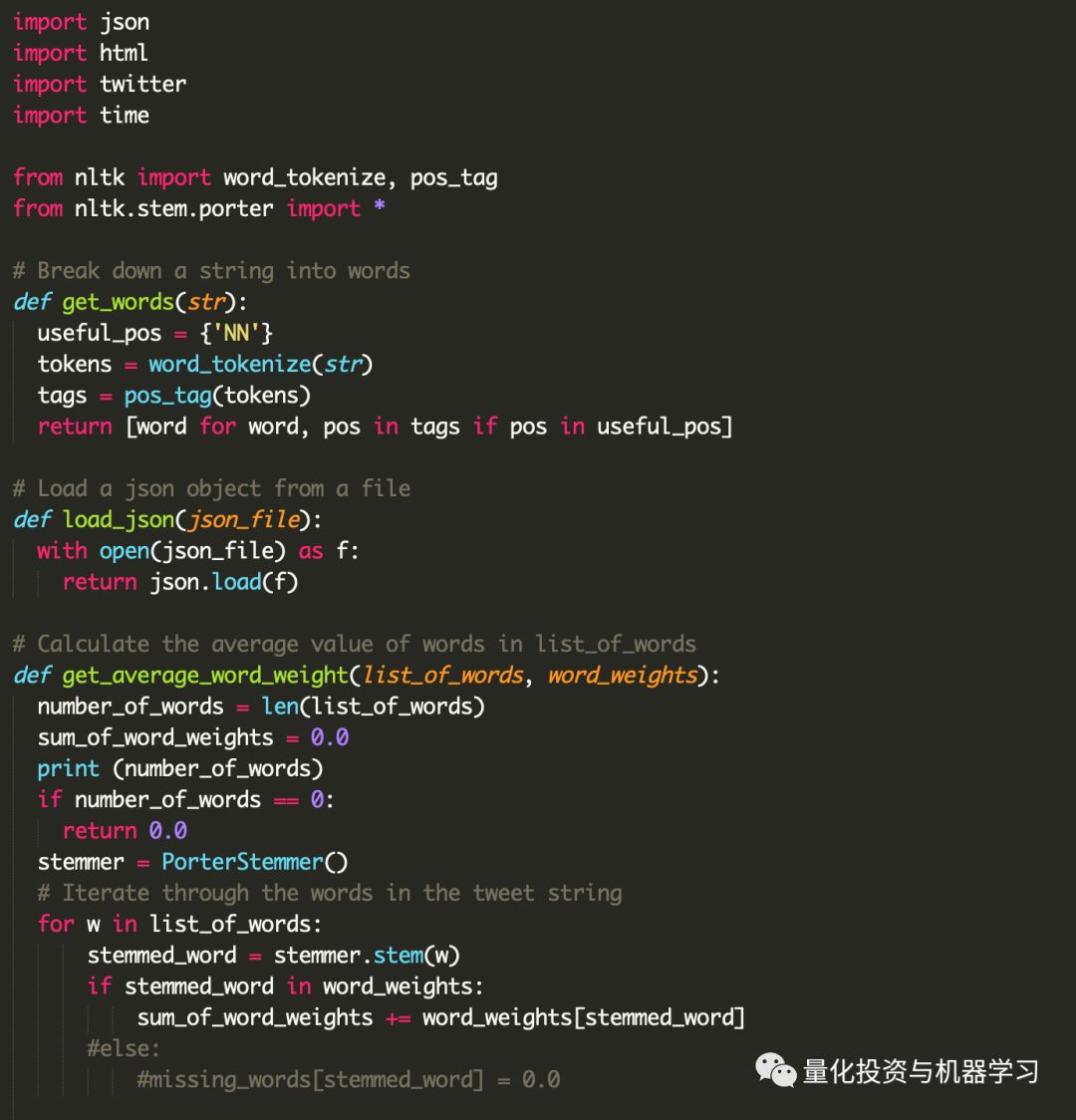

当然,如前所述,在代码中存储数据是一种不好的做法。当这些数据涉及某种秘密时,情况就更糟了。但是我们知道怎么正确地做。我们从.cred.json加载Twitter凭据。只需创建一个新的JSON文件,将密钥和秘密存储在字典中,并将其保存为.cred.json:

许多推文包含非字母字符。例如,一条推文可能包含&、>或<。这样的字符被Twitter转义。这意味着Twitter将这些字符转换为html安全字符。
例如,像 Me & my best friend <3 这样的推文被转换为Me & my best friend <3。为了将其转换回原来的表示形式,我们需要使用html模块中的unescape函数取消对推文的转义。
试着运行这段代码。你应该能够判断特朗普最新的推文是否是他的风格。
先听首歌,让我们开始下面另一个分析。
先看看下面三篇文章:
1、https://machinelearningmastery.com/develop-word-based-neural-language-models-python-keras/
2、https://blog.keras.io/using-pre-trained-word-embeddings-in-a-keras-model.html
3、https://machinelearningmastery.com/text-generation-lstm-recurrent-neural-networks-python-keras/
我们使用川普的最新约3000条推文来训练模型。
2.7.13 |Anaconda 4.3.1 (64-bit)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-1)]
Using TensorFlow backend.
keras 2.0.6
tensorflow 1.2.1
numpy 1.11.3

1.2.1
单字输入单字输出模型
第一个训练数据是一个由11个单词和三个感叹号组成的句子。我们将使用这句话创建一个简单的LSTM模型。模型应该能够过度拟合并复制这个句子!

首先创建Tokenizer对象。Tokenizer在word和idnex之间创建映射。映射记录在字典中:key = words, value = index。字典可以通过“tokenizer.word_index”访问字典。
word_index删除特殊字符,例如…或!
所有的单词都转换成小写字母。
索引从'1'而不是0开始!

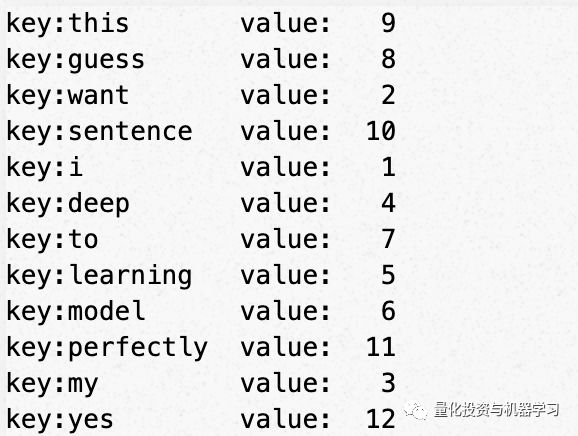
分词器。texts_to_sequences将字符串转换为索引列表。索引来自tokenizer.word_index。你可以看到索引是按照句子中出现的单词的顺序排列的。

将词汇表大小定义为唯一单词的数量+ 1。这个vocab_size用于定义要预测的类的数量。加1必须包含“0”类。word_index.values()没有使用0定义单词。因此,因此我们可以将此类0用于占位符类(即填充类)。

准备好训练数据X, y,当我们创建一个单词输入一个单词输出模型时:
X.shape =(句子中的N个单词 - 1,1)
y.shape =(句子中的N个单词 - 1,1)

((11,), (11,))
注意,num_class被设置为vocab_size,即N个唯一单词+ 1。y的打印表明,在第0列和第1列中没有包含索引的行。 这是因为:


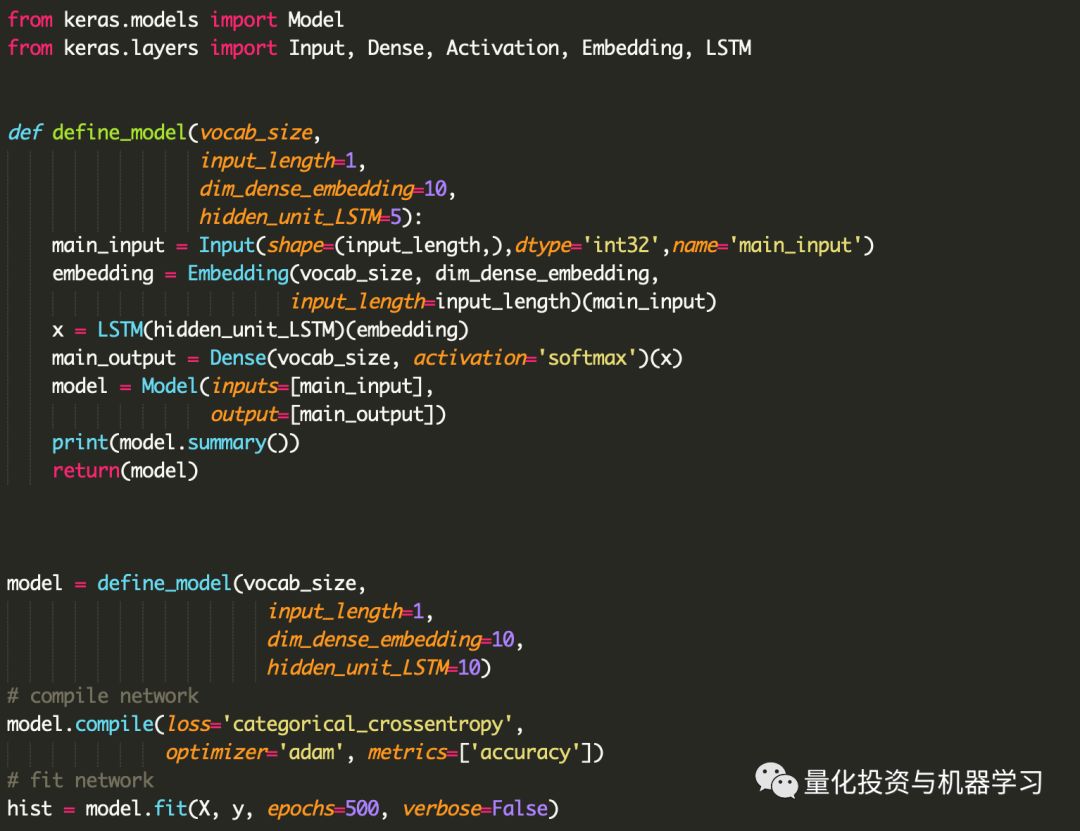
模型很简单;一个嵌入层,接着是一个LSTM层,然后是前馈神经网络层。
Word embeddings是一种自然语言处理技术,旨在将每个词的语义映射到一个几何空间。
参数

训练结果表明,该模型能较好地预测训练语句的准确性。
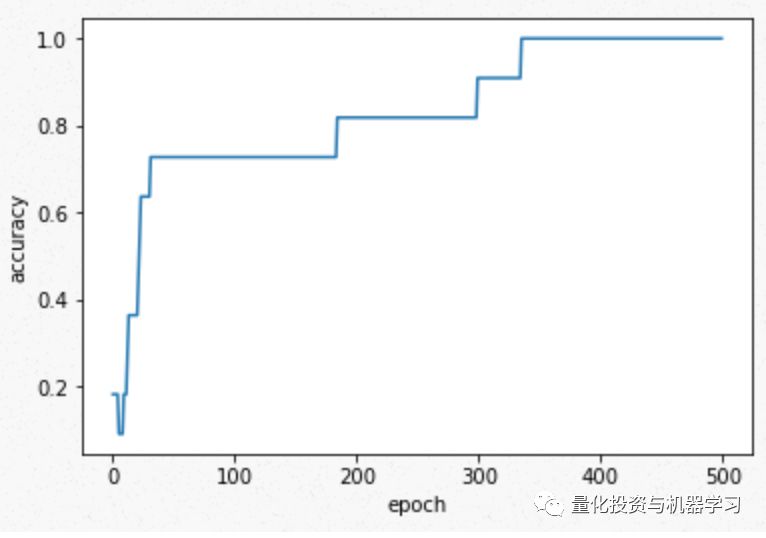
现在检查一下我们的模型能否正确生成训练过的句子。生成一个以“I”开头的13个单词的句子。它成功地生成了原句。原来的句子有12个单词,所以在“yes”之后预测的第13个单词可以是任何单词。在这种情况下,yes之后的单词被预测为to。但是如果你用不同的初始值训练,这个值就会改变。


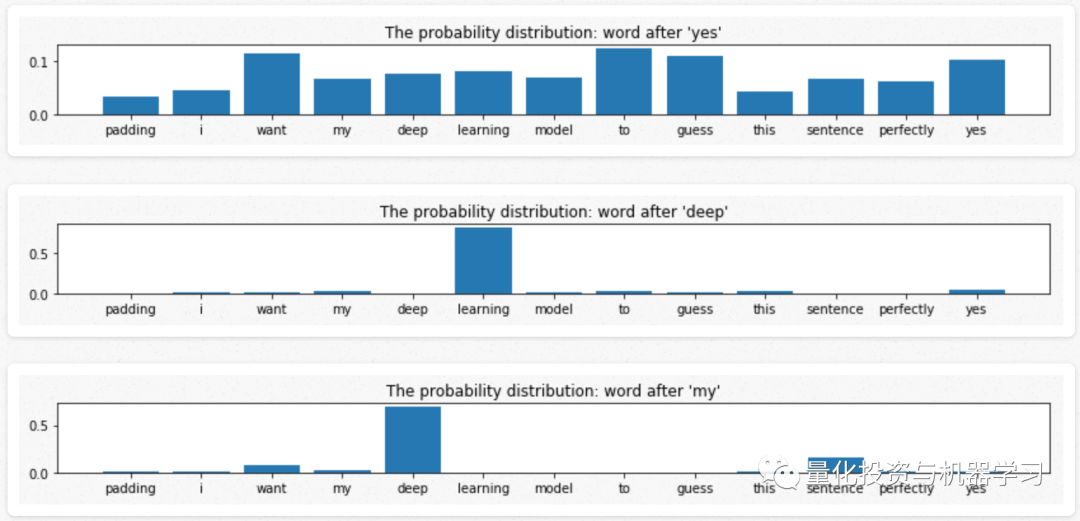
看一下前面那个单词的概率分布。


除“yes”外,所有单词的附加概率分布都有较大的峰值,其他地方的概率分布比较平缓。峰位于下一个单词。例如,单词“deep”之后的概率分布峰值出现在“learning”。然而,“yes”之后单词的概率分布是相当平坦的。

在前面的例子中,我们只有一个句子来训练模型。我现在将使用大约3000条来自川普的推文来训练一个深度学习模型。
数据

让我们从dataframe中随机选择的10条推文。它显示推文包含许多仅出现一次的术语或对预测不感兴趣的术语。 所以我们先清理文本。


推文清洁技巧:

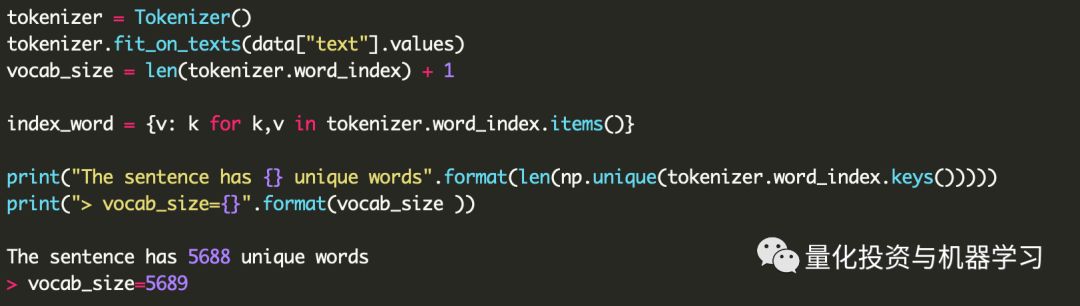
我们发现这些清理对于创建有意义的模型非常重要。不进行清洗,模型的训练精度提高不超过0.05。我们试图通过大幅增加模型的复杂性来解决这个问题,但是并不是很成功。似乎删除不经常出现的单词是非常有用的方法。
这是有道理的,因为删除这些不常出现的单词会使Tokenizer.word_index的大小减少20%以上(1 - 5689/7300)。
现在,我们创建一个单词和索引之间的映射。Tokenizer很好地过滤特殊字符。
使用Tokenizer的单词索引字典,只用单词indecies表示每个句子。 让我们看看句子是如何用单词indecies表示的。


重构句子数据
目前每一行都是一个句子
我们将改变它,以便每行对应一个单词进行预测,如果有两个句子““Make America Great Again”和“Thanks United States”,这将创建5行:"- - Make America", "- Make America Great", "Make America Great Again", "- - Thanks United", "- Thanks United States"。

Total Sequences: 50854
序列长度因数据而异。我们加“0”使每个句子相同。
将目标变量转换为一个独热编码向量。

通过增加密集嵌入向量的维数,增加LSTM中隐藏单元的数量,使模型比之前的例子更加复杂。
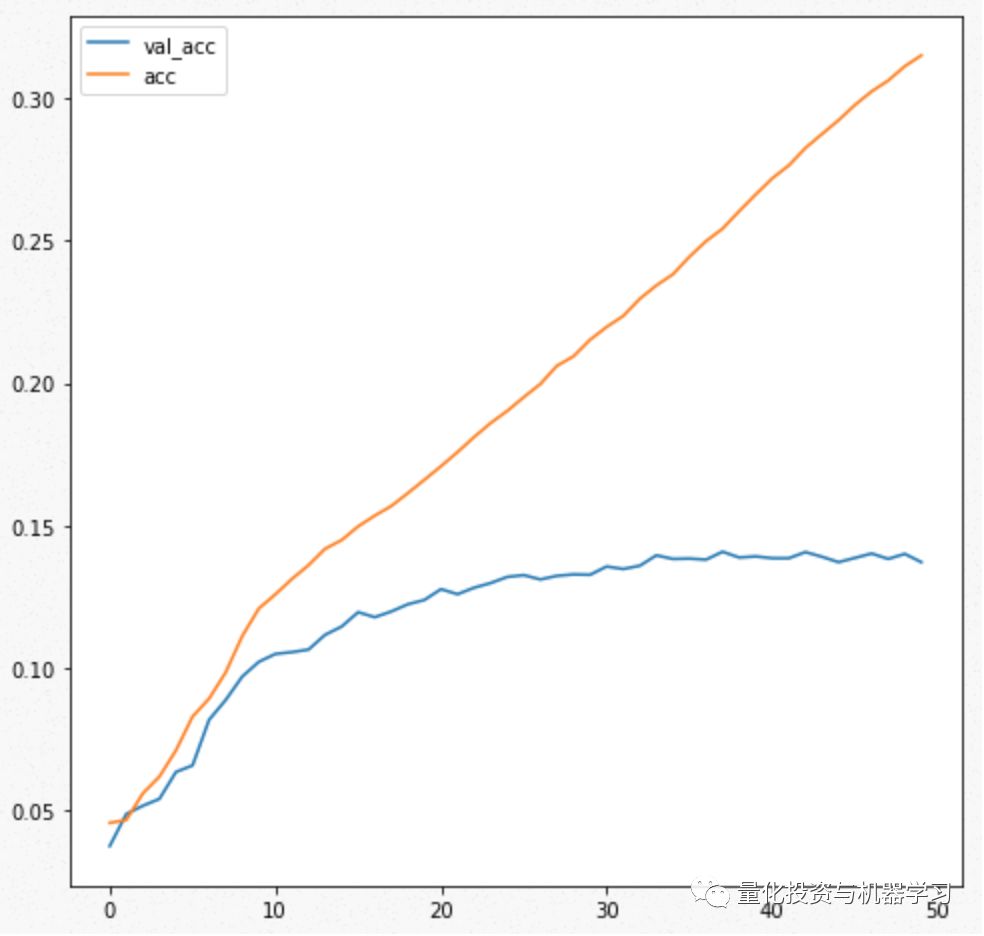
训练精度不断提高,但验证精度没有明显提高。考虑到训练数据量小,这是合理的;模型过度拟合。


···
验证准确性和训练准确性


利用主成分分析法对词向量的维数进行降维处理,并在二维空间中对其进行可视化处理。


输入一个词,看后面AI会生成什么。
1、当“Make America”作为前两个词出现时,人工智能几乎总是预测“再次伟大”作为下一个词。
2、当提供“North”时,下一个单词几乎总是“Korea”,后面通常是一些否定句。
3、以“Omaga is”开头的句子往往具有负面含义。


在来听首歌
我们还将特朗普和希拉里的推文与自然语言处理进行比较
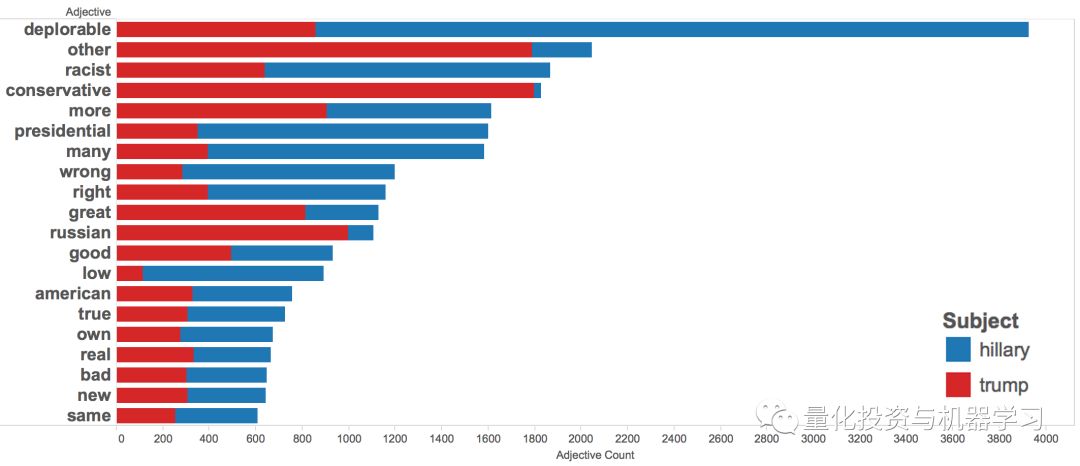
我们分析了9月9日至10日有关两位候选人的30万条推文的数据。
推文中以希拉里或特朗普为主题的最常用形容词
推文中以希拉里或特朗普为主题的热门动词

最常用的表情

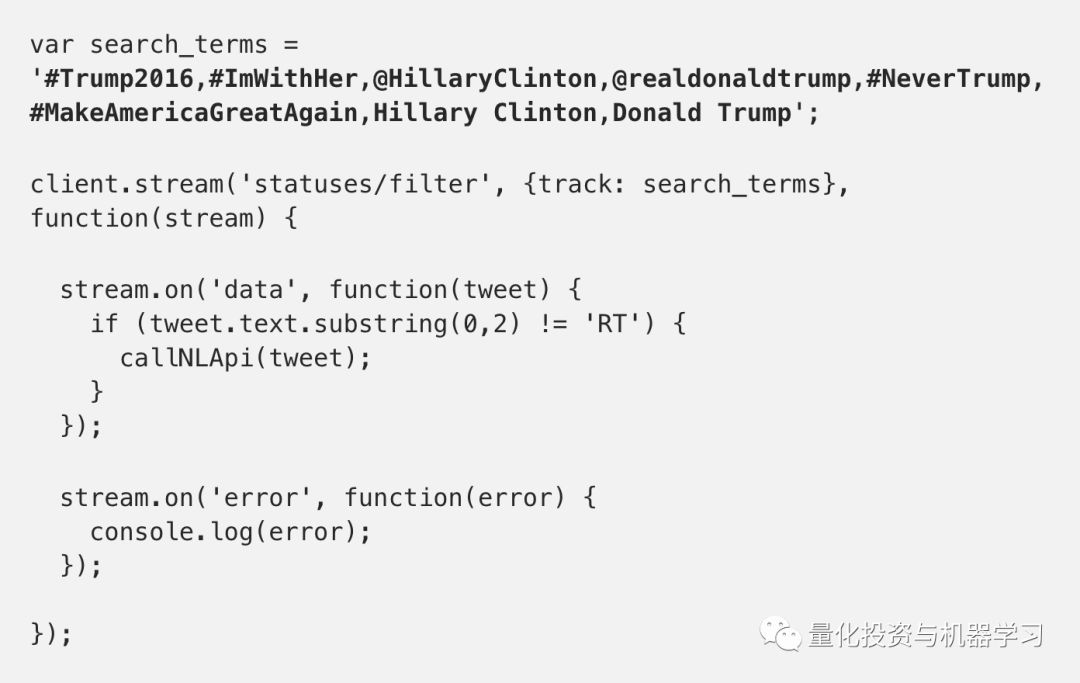
Twitter流媒体API:获取所有选举推文(https://developer.twitter.com/en/docs)

云自然语言API:解析推文并获取语法数据(https://cloud.google.com/natural-language/)

BigQuery:分析推文语法数据(https://cloud.google.com/bigquery/)
Tableau和一些JavaScript技巧:数据可视化(https://www.tableau.com/solutions/google)
使用带有Node.js的Twitter流媒体API对提到希拉里或特朗普的推文进行了流媒体处理。
一旦我们收到一条推文,我们就把它发送到自然语言API进行语法分析。
Cloud Natural Language API:解析推文
新的Cloud Natural Language API有三种方法——语法注释、实体和情感分析。这里我们将重点介绍语法注释,语法注释响应提供关于句子结构和每个单词的词性的详细信息。推文常常缺少标点符号,语法上也不总是正确的,但是NL API仍然能够解析它们并提取语法数据。举个例子,这是发布的30万条tweet中的一条
https://www.newsweek.com/trump-lone-holdout-pence-releases-tax-returns-497244)
Donald Trump is the lone holdout as VP nominee Mike Pence releases his tax returns — Newsweek
这里是从该API发回的语法数据可视化:
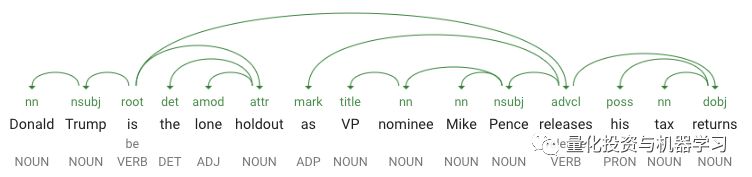
API的JSON响应提供了上面依赖关系解析树中显示的所有数据。它为句子中的每个标记返回一个对象(标记是一个单词或标点符号)。下面是上面例子中一个令牌的JSON响应示例,在本例中是单词“release”:

让我们分解一下响应:tag告诉我们“release”是一个动词。label告诉我们这个单词在上下文中所扮演的角色。这里是ADVCL,它代表状语从句修饰语。headTokenIndex指示指向此标记的弧在依赖关系解析树中的位置,每个标记作为一个索引。引理是单词的根形式,如果要计算单词出现的次数并希望合并重复的单词,这是非常有用的(请注意,“releases” is “release”)。
下面是我们对NL API的请求:

现在我们已经将所有语法数据都作为JSON,有无数种方法可以分析它。我们没有在tweet出现时进行分析,而是决定将每条tweet插入到一个BigQuery表中,然后找出如何分析它。
我们创建了一个包含所有tweet的BigQuery表,然后运行一些SQL查询来查找语言趋势。下面是BigQuery表的模式:

我们使用google-cloud npm包将每条推文插入到表格中,只需要几行JavaScript代码:
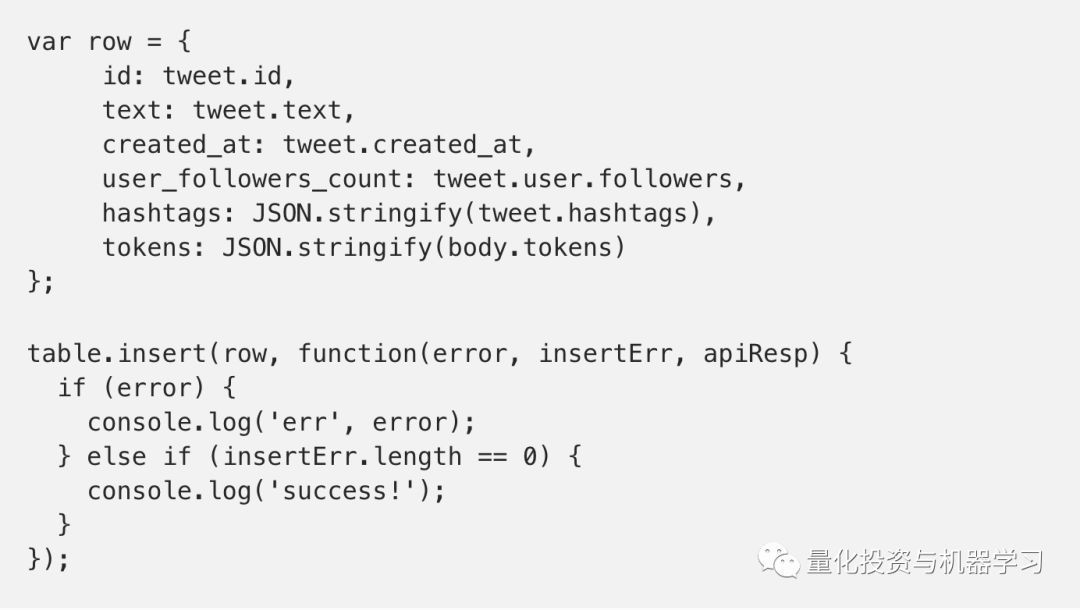
表中的token列是一个巨大的JSON字符串。幸运的是,BigQuery支持用户定义的函数(UDF),它允许你编写JavaScript函数来解析表中的数据。
https://cloud.google.com/bigquery/user-defined-functions

为了识别形容词,我们查找NL API返回的所有标记,其中ADJ作为它们的partOfSpeech标记。但我并不想要所有收集到的推文中的形容词,我们只想要希拉里或特朗普作为句子主语的推文中的形容词。NL API使使用NSUBJ((nominal subject)标签过滤符合此标准的推文变得很容易。
https://medium.com/google-cloud/comparing-tweets-about-trump-hillary-with-natural-language-processing-a0064e949666

以上是完整的查询(UDF内联)——它计算了所有以希拉里或特朗普为名义主语的推文中的形容词。
为了统计表情符号,我们修改了我的UDF,查找所有partOfSpeech标记为X(表示外文字符)的标记,并使用正则表达式提取所有表情符号字符:
https://github.com/mathiasbynens/emoji-regex
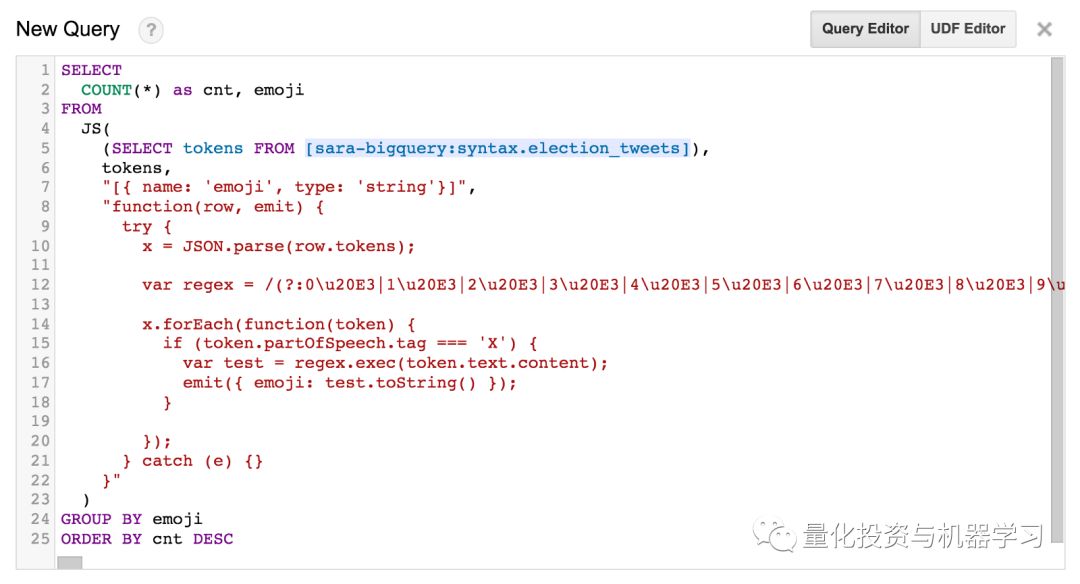
输出:

BigQuery与Tableau、data Studio和Apache Zeppelin等数据可视化工具很棒。将BigQuery表连接到Tableau来创建上面所示的条形图。Tableau允许你根据正在处理的数据类型创建各种不同的图表。下面是一个饼状图,显示了我们收集到的推文中的前10个标签(小写字母以消除重复):

为了创建表情包标签云,我们从表情包查询中下载了JSON:
使用这个方便的JavaScript库生成word云。https://github.com/lucaong/jQCloud
开始使用自然语言API:在浏览器中试用它,深入文档,或者查看这些博客文章以获取更多信息。
1、https://cloud.google.com/natural-language/#nl_demo_section
2、https://cloud.google.com/natural-language/docs/
从BigQuery开始:跟随Web UI快速入门,或者查看Felipe Hoffa的任何中等文章。
3、https://cloud.google.com/bigquery/quickstart-web-ui
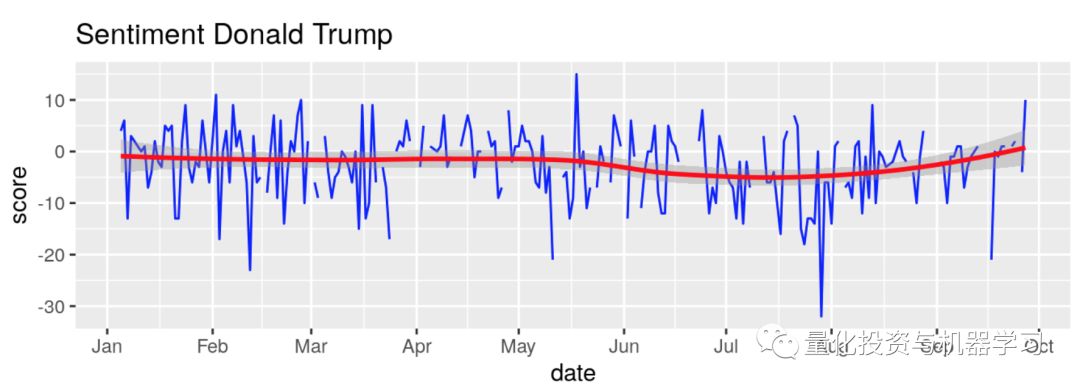
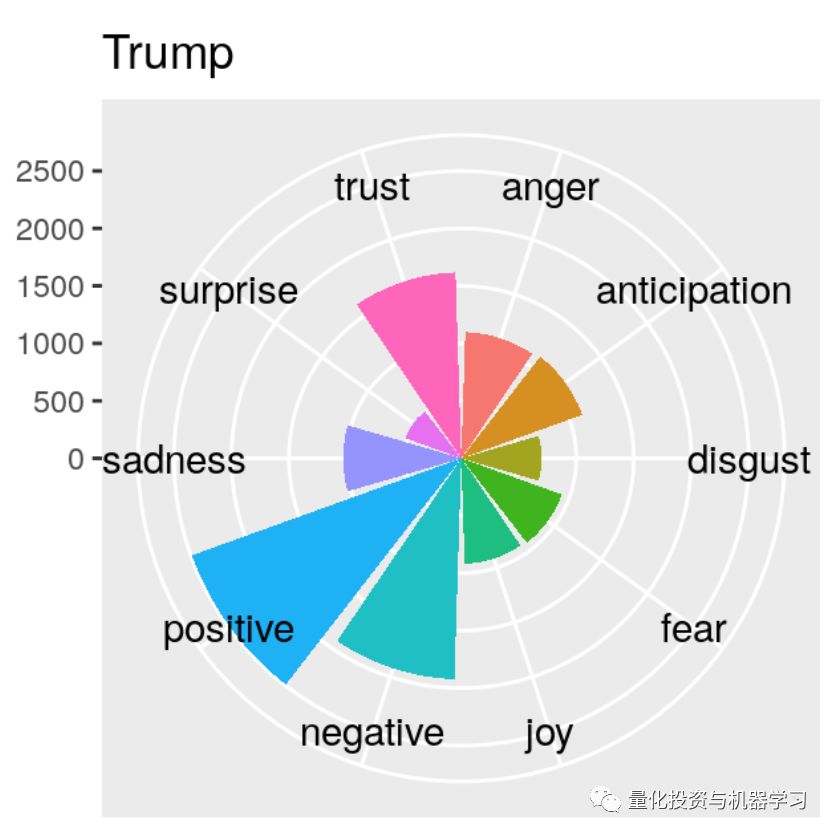
一个kaggle的例子,写的也很棒,建议大家去看原文哦!

部分内容展示:
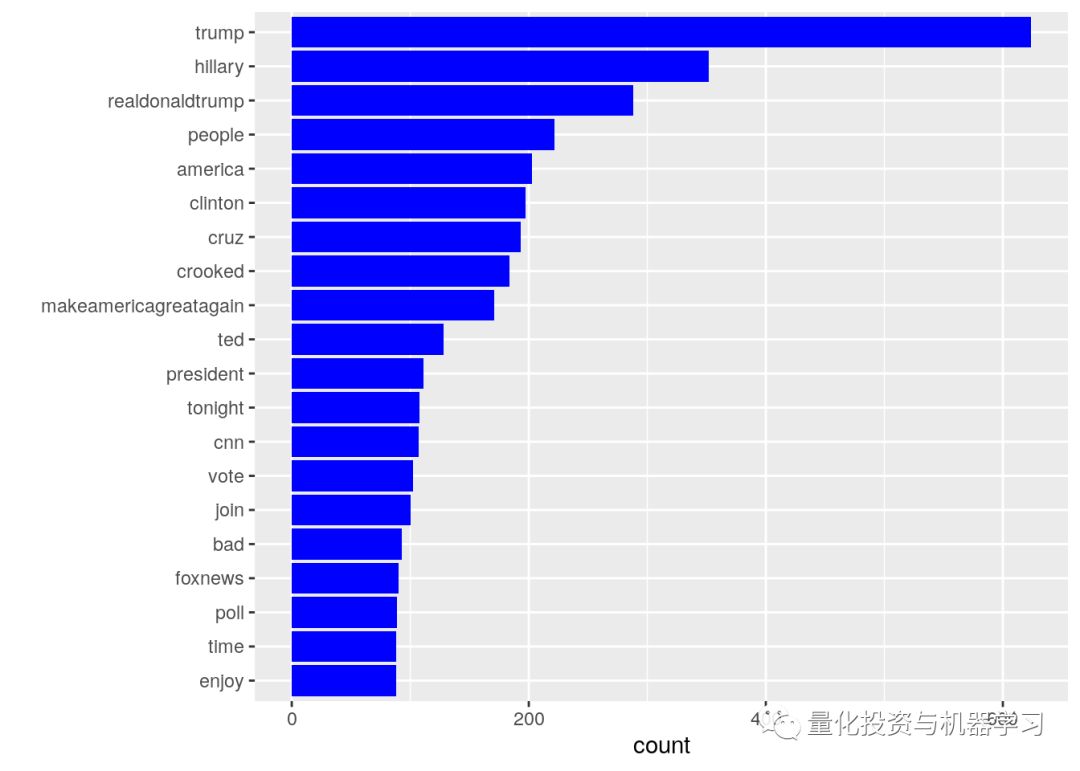


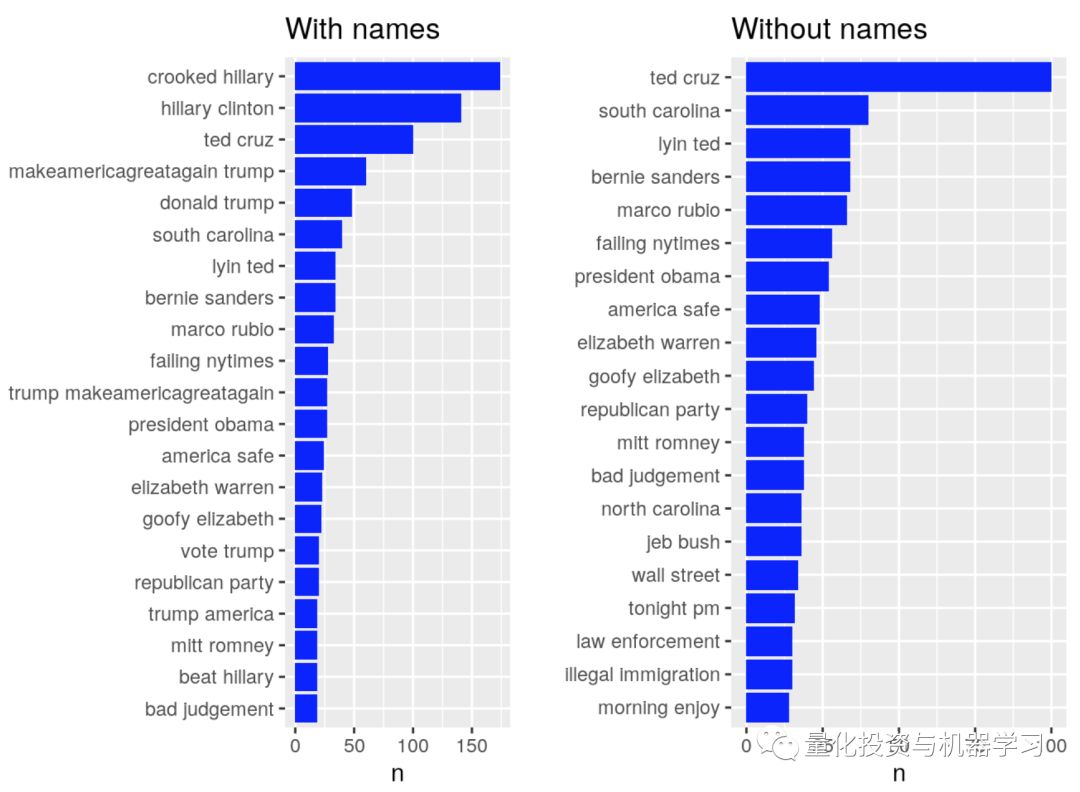
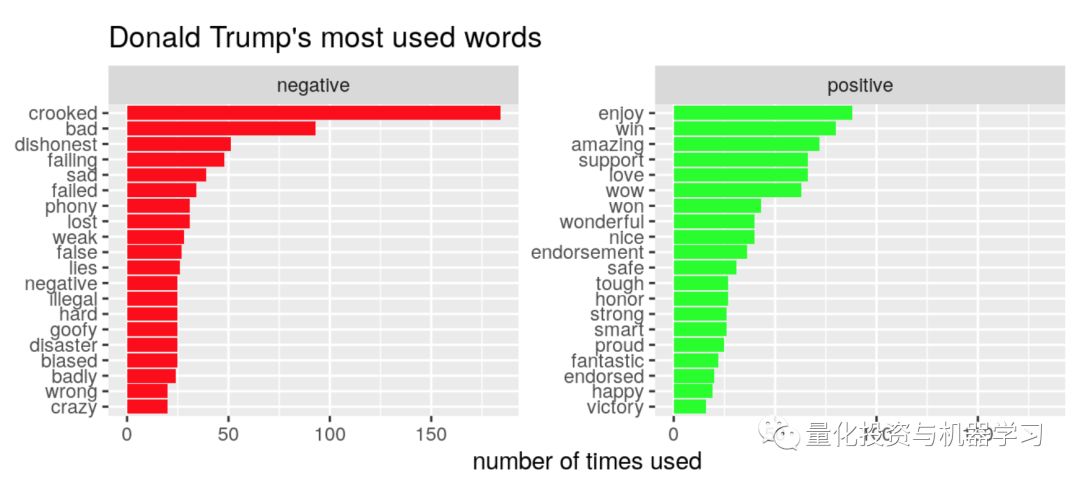
地址:
https://www.kaggle.com/erikbruin/text-mining-the-clinton-and-trump-election-tweets










