
如果你听过很多关于将asyncio添加到Python中的讨论,并对它与其它并发方法的比较结果很好奇,或者想知道并发是什么,以及它如何加速程序,那么你就来对了地方。
在本文中,你将学习以下内容:
本文假设你对Python有基本的了解,并且使用至少3.6版来运行示例。你可以从Real Python GitHub 源下载示例。(https://github.com/realpython/materials/tree/master/concurrency-overview )
什么是并发?
并发的字典定义是同时发生。在Python中,同时发生的事情用不同的名称(线程、任务、进程)来调用,但是在更高的级别上,它们都指向一个按顺序运行的指令序列。
我喜欢把它们看作是不同的思路。每一个都可以在某一点停止,处理它们的CPU或大脑可以切换到另一个。每一个的状态都会被保存,这样就可以在它们被中断的地方重新启动。
你可能想知道为什么Python对同一个概念使用不同的单词。事实证明,线程、任务和进程只有在从高级层面查看时才相同。一旦你开始挖掘细节,你就会发现它们都代表了稍微不同的东西。随着示例的深入,你将看到更多它们的不同之处。
现在我们来讨论一下这个定义中有关“同时运行”的部分。你必须小心一点,因为当你深入到细节时,只有multiprocessing才是真正意义上的同时运行。 Threading 和 asyncio 都运行在一个处理器上,因此它们两个一次只能运行一个。它们只是非常聪明地找到轮流加速整个过程的方法。尽管它们没有真正地同时运行,我们仍然将其称为并发。
线程或任务轮流执行的方式是 threading 和 asyncio之间的主要区别。在threading中,操作系统实际上知道每个线程,并可以在任何时候中断它,以开始运行不同的线程。这称为抢占式多任务处理(https://en.wikipedia.org/wiki/Preemption_%28computing%29#Preemptive_multitasking ),因为操作系统可以抢占线程来进行切换。
抢占式多任务处理非常方便,因为线程中的代码不需要做任何事情来进行切换。它也可能是困难的,因为“在任何时候”这句话。这种切换可以发生在单个Python语句的中间,甚至是像x = x + 1这样的简单语句。
另一方面,asyncio使用协作多任务处理(https://en.wikipedia.org/wiki/Cooperative_multitasking )。这些任务必须通过宣布它们何时可以被切换出来相互配合。这意味着任务中的代码必须稍做修改才能实现这一点。
提前做这些额外工作的好处是,你总是知道你的任务将被交换到哪里。除非在Python语句的中间做了标记,否则它不会被交换出去。稍后你会看到这将如何简化你的设计。什么是并行?
到目前为止,你已经了解了发生在单个处理器上的并发。你那酷毙了的新笔记本电脑具有的CPU内核呢?你如何利用它们? multiprocessing就是答案。
使用 multiprocessing,Python可以创建新的进程。这里的进程几乎可以看作是一个完全不同的程序,尽管从技术上讲,它们通常被定义为一组资源集合,其中的资源包括内存、文件句柄等。一种考虑方式是,每个进程都运行在自己的Python解释器中。
因为它们是不同的过程,所以多进程程序中的每个任务都可以运行在不同的核心上。在不同的核心上运行意味着它们实际上可以同时运行,这非常棒。这样做会产生一些复杂的问题,但是Python在大多数情况下都能很好地处理这些问题。
既然你已经了解了什么是并发和并行,那么让我们来回顾一下它们之间的差异,然后我们来看看它们为什么很有用:
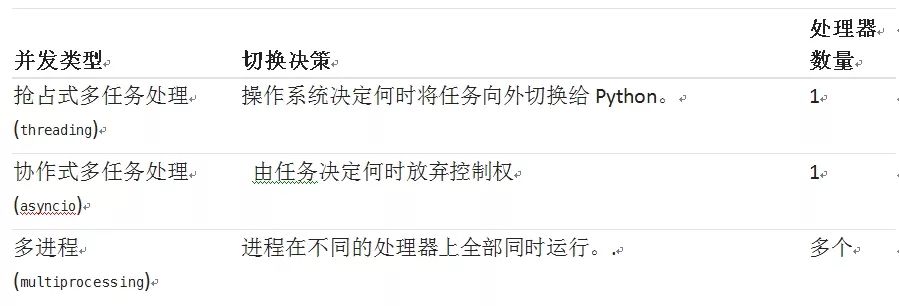
并发类型中的每一个都很有用。我们来看看它们可以帮助你加速哪种类型的程序。
并发在什么时候有用?
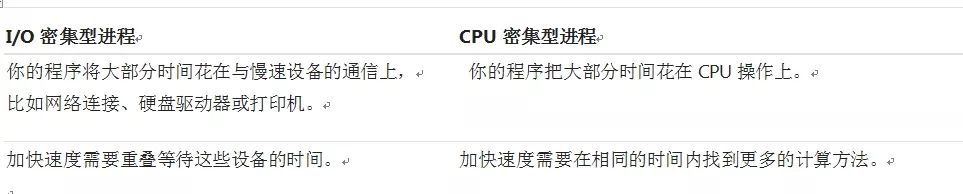
对于两种类型的问题,并发性可以产生很大的影响。这些通常称为CPU密集型和I/ O密集型。
I/O密集型问题会导致程序变慢,因为它经常必须等待来自外部资源的输入/输出(I/O)。当你的程序处理事务比CPU慢得多时,这些问题就经常出现。
比CPU慢的东西的例子有很多,但幸运的是,你的程序并没有与它们中的大多数进行交互。你的程序与之交互最多的比较慢的东西通常是文件系统和网络连接。
让我们看看它是什么样的:
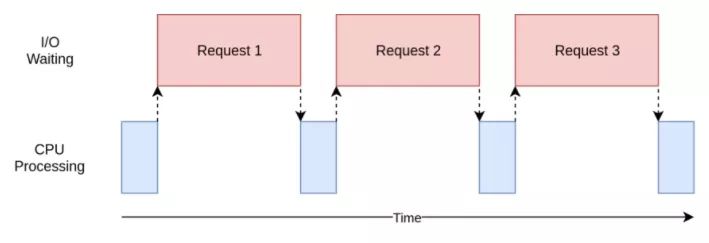
在上面的图表中,蓝色框表示程序执行工作的时间,红色框表示等待I/O操作完成的时间。此图没有按比例显示,因为internet上的请求可能比CPU指令要多花费几个数量级的时间,所以你的程序可能会花费大部分时间进行等待。这是你的浏览器大部分情况下正在做的事情。
另一方面,有一些程序在不与网络通信或访问文件的情况下执行重要计算。它们就是CPU密集型程序,因为限制程序速度的资源是CPU,而不是网络或文件系统。
下面是一个CPU密集型程序的对应图:
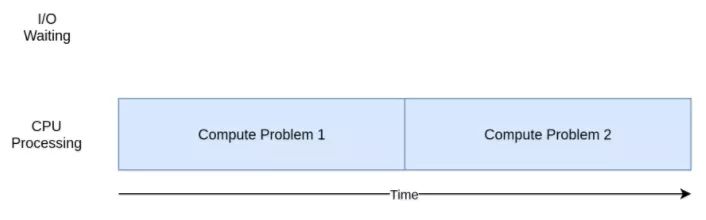
当你推敲下一节中的示例时,你将看到不同形式的并发在处理CPU密集型和I/ O密集型程序时运行良好或更差。将并发添加到你的程序中会增加额外的代码和复杂性,因此你需要决定潜在的提速是否值得付出额外的努力。在本文结束之前,你应该已经具备了足够的信息来做出这个决定。
这里有一个快速总结来阐明这个概念:
你将首先查看I/ O密集型程序。然后,你将看到一些处理CPU密集型程序的代码。
如何加速I/ O密集型程序
我们从关注I/ O密集型程序的一个常见问题开始: 通过网络下载内容。对于我们的示例,你将从几个站点下载web页面,但实际上可以是任何网络流量。只是可视化和设置网页更容易一些。
同步版本
我们将从这个任务的一个非并发版本开始。注意,这个程序需要requests模块。在运行这个程序之前,你应该先运行pip install requests命令,可能是使用virtualenv环境。这个版本一点也没有使用并发:
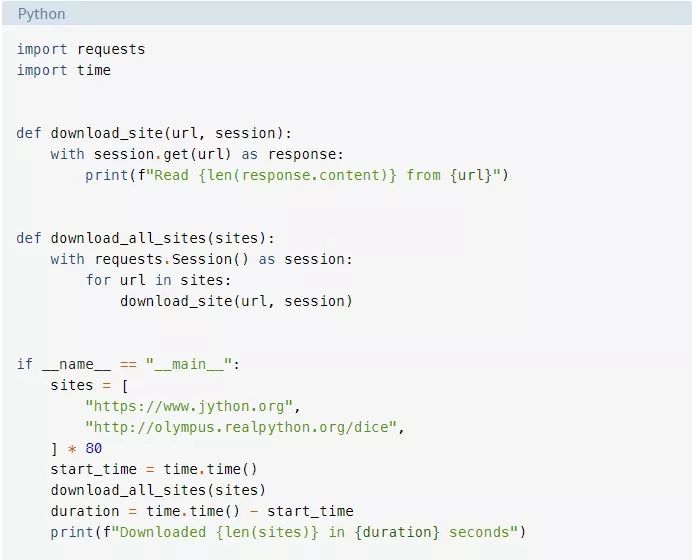
如你所见,这是一个相当短的程序。download_site()只从一个URL下载内容并打印其大小。需要指出的一件小事是,我们这里用到了一个来自requests的Session对象。
也可以直接使用来自requests的get() 函数,但是创建一个Session对象可以让requests运用一些神奇的网络小技巧,从而真正使程序加速。
download_all_sites()会创建Session对象,然后遍历站点列表,依次下载每个站点。最后,它会打印出这个过程花费了多长时间,这样你就可以在下面的示例中满意地看到并发为我们带来了多大的帮助。
这个程序的处理关系图看起来很像上一节中的I/ O密集型关系图。
注意
: 网络流量依赖于许多因素,这些因素可能随时间而变化。由于网络问题,我看到这些测试的时间从一个运行到另一个运行时间翻了一番。
为什么同步版本很棒
这个版本代码的优点是,它很简单,并且编写和调试相对容易。这样考虑起来也更直接。只有一个思路贯穿其中,所以你可以预测下一步是什么,以及它将如何运行。
同步版本的问题
这里最大的问题是,与我们提供的其他解决方案相比,它的速度相对较慢。下面是我的机器的最终输出结果的一个例子:

注意: 你的结果可能有很大差异。运行这个脚本时,我看到时间从14.2秒到21.9秒不等。对于本文,我以三次运行中最快的一次的时间作为测试时间。两种方法之间的区别仍然很明显。
然而,速度变慢并不总是一个大问题。如果你正在运行的程序使用同步版本只需要2秒,并且很少运行,那么它可能不值得添加并发。你可以在此停止了。
如果你的程序经常运行怎么办?如果要运行好几个小时呢?让我们通过使用threading重写这个程序来继续讨论并发。
threading 版本
正如你可能猜到的,编写应用线程的程序需要更多的工作。然而,你可能会惊讶地发现,对于简单的情况,你只需要很少的额外工作。下面是使用threading的相同程序:

当你添加threading时,整个结构是相同的,你只需要做一些更改。download_all_sites()函数从每个站点调用函数一次改为更复杂的结构。
在这个版本中,你将创建一个ThreadPoolExecutor,它看起来很复杂。让我们把它分解开: ThreadPoolExecutor =Thread+Pool+ Executor。
你已经了解了Thread部分。那只是我们之前提到的一个思路。Pool部分是开始变得有趣的地方。这个对象将创建一个线程池,其中的每个线程都可以并发运行。最后,Executor是控制线程池中的每个线程如何以及何时运行的部分。它将在线程池中执行请求。
对我们很有帮助的是,标准库将ThreadPoolExecutor实现为一个上下文管理器,因此你可以使用with语法来管理Threads池的创建和释放。
一旦有了ThreadPoolExecutor,你就可以使用它方便的.map()方法。此方法在列表中的每个站点上运行传入函数。最重要的是,它使用自己管理的线程池自动并发地运行它们。
来自其他语言,甚至Python 2的人可能想知道,在处理threading时,管理你习惯的细节的常用对象和函数在哪里,比如Thread.start()、Thread.join()和Queue。
这些都还在那里,你可以使用它们来实现对线程运行方式的精细控制。但是,从Python 3.2开始,标准库添加了一个更高级别的抽象,称为Executor,如果你不需要精细控制,它可以为你管理许多细节。
本例中另一个有趣的更改是,每个线程都需要创建自己的request . Session()对象。当你查看requests的文档时,不一定就能很容易地看出,但在阅读这个问题(https://github.com/requests/requests/issues/2766 )时,你会清晰地发现每个线程都需要一个单独的Session。
这是threading中有趣且困难的问题之一。因为操作系统可以控制任务何时中断,何时启动另一个任务,所以线程之间共享的任何数据都需要被保护起来,或者说是线程安全的。不幸的是,requests . Session()不是线程安全的。
根据数据是什么以及如何你使用它们,有几种策略可以使数据访问变成线程安全的。其中之一是使用线程安全的数据结构,比如来自 Python的queue模块的Queue。
这些对象使用低级基本数据类型,比如threading.Lock,以确保只有一个线程可以同时访问代码块或内存块。你可以通过ThreadPoolExecutor对象间接地使用此策略。
这里要使用的另一种策略是线程本地存储。Threading.local()会创建一个对象,它看起来像一个全局对象但又是特定于每个线程的。在我们的示例中,这是通过threadLocal和get_session()完成的:
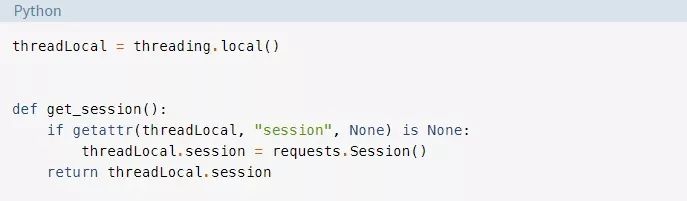
ThreadLocal是threading模块中专门用来解决这个问题的。它看起来有点奇怪,但是你只想创建其中一个对象,而不是为每个线程创建一个对象。对象本身将负责从不同的线程到不同的数据的分开访问。
当get_session()被调用时,它所查找的session是特定于它所运行的线程的。因此,每个线程都将在第一次调用get_session()时创建一个单个的会话,然后在整个生命周期中对每个后续调用使用该会话。
最后,简要介绍一下选择线程的数量。你可以看到示例代码使用了5个线程。随意改变这个数字,看看总时间是如何变化的。你可能认为每次下载只有一个线程是最快的,但至少在我的系统上不是这样。我在5到10个线程之间找到了最快的结果。如果超过这个值,那么创建和销毁线程的额外开销就会抵消程序节省的时间。
这里比较困难的答案是,从一个任务到另一个任务的正确线程数不是一个常量。需要进行一些实验来得到。
为什么 threading版本很棒
它很快!这是我测试中运行最快的。记住,非并发版本花费的时间超过14秒:

以下是它的执行时序表:

它使用多个线程同时向web站点发出多个开放的请求,允许你的程序重叠等待时间并更快地获得最终结果! 哦耶! !这就是我们的目标。
Threading版本的问题
正如你从示例中看到的,实现这一点需要更多的代码,而且你确实需要考虑线程之间共享哪些数据。
线程可以以微妙且难以检测的方式进行交互。这些交互可能会导致竞态条件,而这些竞态条件常常会导致很难发现的随机、间歇性的bug。那些不熟悉竞态条件概念的人可能需要扩展并阅读以下部分。
竞态条件
竞态条件是在多线程代码中可能而且经常发生的一类细微的bug。竞态条件的发生是因为程序员没有有效地保护数据访问,以防止线程之间相互干扰。在编写使用线程的代码时,你需要采取额外的步骤来确保数据是线程安全的。
这里发生的事情是,操作系统控制着你的线程何时运行,以及它何时被交换出去,让另一个线程运行。这种线程交换可以在任何时候发生,甚至在执行Python语句的子步骤时也是如此。举个简单的例子,看看这个函数:
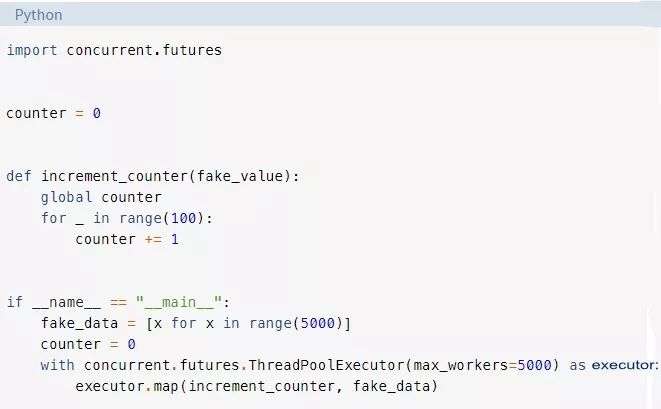
这段代码与上面线程示例中使用的结构非常相似。不同之处在于,每个线程都访问相同的全局变量counter并对其进行递增。counter不受任何保护,因此它不是线程安全的。
为了增加counter,每个线程都需要读取当前值,并向其中增加一,并将该值保存回变量。这个过程发生的代码行是counter += 1。
因为操作系统对你的代码一无所知,并且可以在执行过程中的任何时刻交换线程,所以有可能线程在读取了该值之后,但在有机会将其写回之前被操作系统交换了出去。如果正在运行的新代码也修改了counter,那么第一个线程就会有一个过期的数据副本,问题就会随之而来。
正如你所能想象的,发生这种情况是相当罕见的。你可以运行这个程序上千次,却永远看不到问题。这就是为什么调试这类问题相当困难,因为它可能非常难以重现,并可能导致出现随机查找错误。
作为一个进一步的示例,我想提醒你request . Session()不是线程安全的。这意味着,如果多个线程使用同一个Session,那么在某些地方可能会发生上面描述的交互类型问题。我提出这个问题不是为了诋毁requests,而是要指出这些问题很难解决。
英文原文:https://realpython.com/python-concurrency/
译者:Nothing










