
KivenC,一名爱好Python编程的机械男。
GitHub:https://github.com/KivenCkl
LeetCode简介
leetcode是一个美国的在线编程网站,它收集了各大公司的经典算法面试题,用户可以选择不同的语言进行代码的在线编写、编译和调试。简单来说,它就是程序员的刷题神器。
概述
项目地址:Leetcode_Helper
https:
Python 实现的 LeetCode 仓库美化程序。爬取 LeetCode-cn AC 的题目描述和提交的最新代码,并整理至相应的文件夹,生成相应的 README 文件。
项目结构:
LeetCode_Helper/
|
| |
|
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|
|
|
|
|
|
|
本项目参考了:
https:
https:
特点
支持爬取题目列表(中英文),保存为指定目录下的 README 和 README_EN 文件
支持爬取题目描述(中英文),保存为对应 title 文件夹下的 README 和 README_EN 文件
支持爬取用户提交的代码,保存为对应 title 文件夹下的 AC 源码(可以是任意语言)
支持修改导出数据的模板
异步下载题目描述,高速并发导出文件
支持增量更新,当 LeetCode-cn 有新内容(题目/提交的代码)时,可以选择增量形式更新
核心思路
获取 LeetCode-cn 用户 cookies
class Login:
'''
登录 LeetCode-cn, 获取 cookies 值
'''
def __init__(self, username, password):
self.username = username
self.password = password
self.__cookies = ''
self.status = False
def doLogin(self):
resp = requests.get(LEETCODE, headers=HEADERS)
token = resp.cookies['csrftoken']
headers = HEADERS.copy()
headers.update({
'referer': LOGIN,
'x-csrftoken': token,
'x-requested-with': 'XMLHttpRequest'
})
payload = {
'login': self.username,
'password': self.password,
'csrfmiddlewaretoken': token
}
cookies = {'csrftoken': token}
resp = requests.post(
LOGIN, data=payload, headers=headers, cookies=cookies)
if resp.status_code == 200:
self.status = True
self.__cookies = resp.cookies
if self.status:
print(f'{self.username} 登录成功!')
else:
print('登录失败!')
print('请检查用户名和密码!')
@property
def cookies(self):
if not self.status:
self.doLogin()
return self.__cookies
从 https://leetcode-cn.com/api/problems/all/ 获取用户解题基本信息以及问题列表
def __getProblemsJson(self):
resp = requests.get(PROBLEMS, headers=HEADERS, cookies=self.__cookies)
if resp.status_code == 200:
return resp.json()
从 https://leetcode-cn.com/graphql 异步访问获取问题描述信息
async def __getProblemDesc(self, title_slug):
payload = {
'query':
'''
query questionData(¨E123Equestion(titleSlug:ti
tleSlug:String!)¨E123Equestion(tit
leSlug:titleSlug) {
questionId
content
translatedTitle
translatedContent
similarQuestions
topicTags {
name
slug
translatedName
}
hints
}
}
''',
'operationName':
'questionData',
'variables': {
'titleSlug': title_slug
}
}
async with aiohttp.ClientSession(cookies=self.__cookies) as session:
async with session.post(
GRAPHQL, json=payload, headers=HEADERS) as resp:
return await resp.json()
从 https://leetcode-cn.com/api/submissions/?offset={offset}&limit=20 获取提交的代码信息
def __getSubmissions(self):
result = []
offset = 0
while True:
resp = requests.get(
SUBMISSIONS_FORMAT.format(offset),
headers=HEADERS,
cookies=self.__cookies)
content = resp.json()
result.extend(content['submissions_dump'])
if not content['has_next']:
return result
offset += 20
将获取到的数据进行解析,详见 node.py
用 sqlite3 将解析后的数据存储至数据库,详见 problems.py
从数据库中取出数据生成所需文件,详见 extractor.py
使用
使用 git clone 或直接下载本仓库代码至本地
本项目需要用到第三方库 requests 和 aiohttp,可通过 pip 命令安装。
运行 python run.py
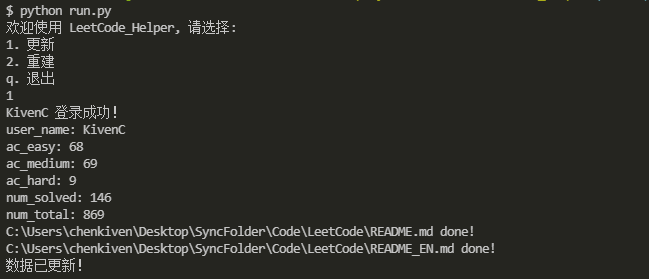
效果
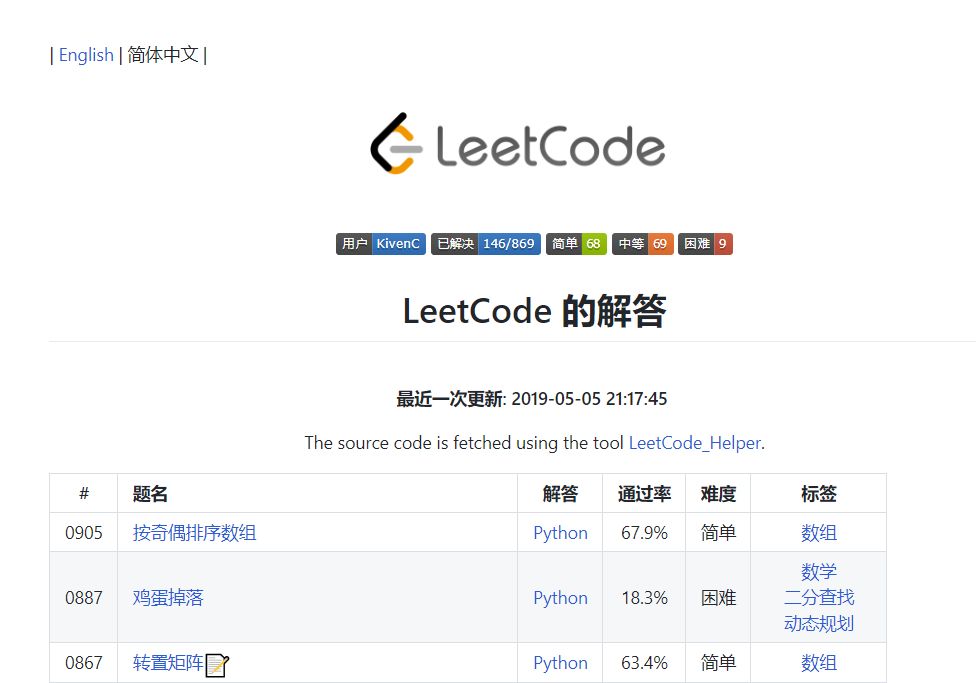
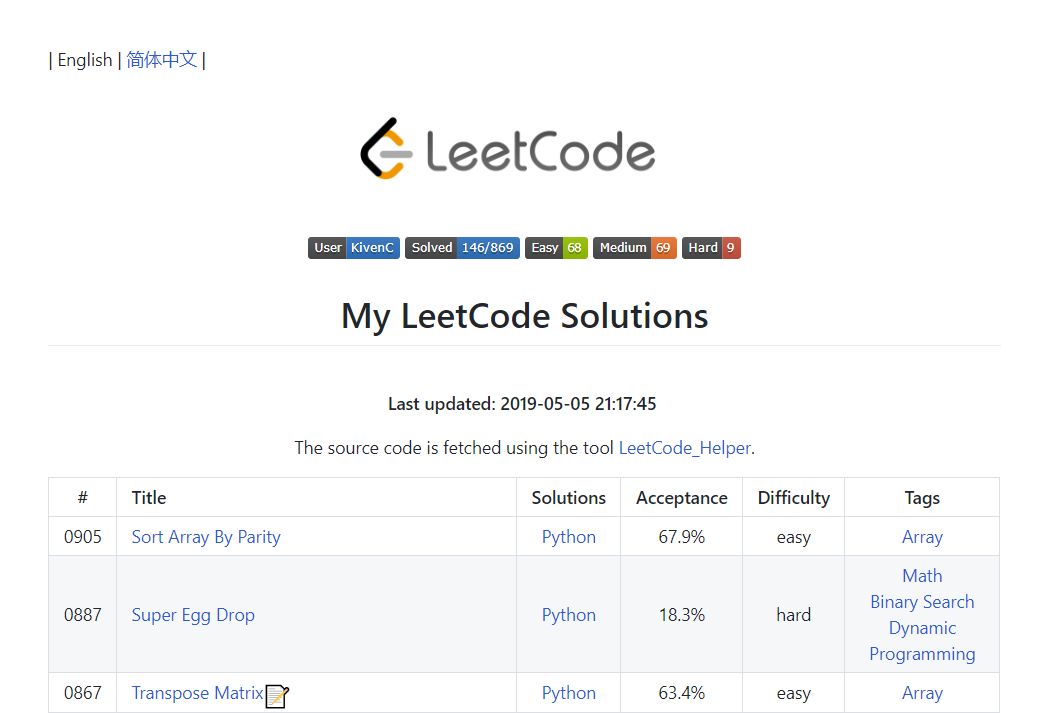
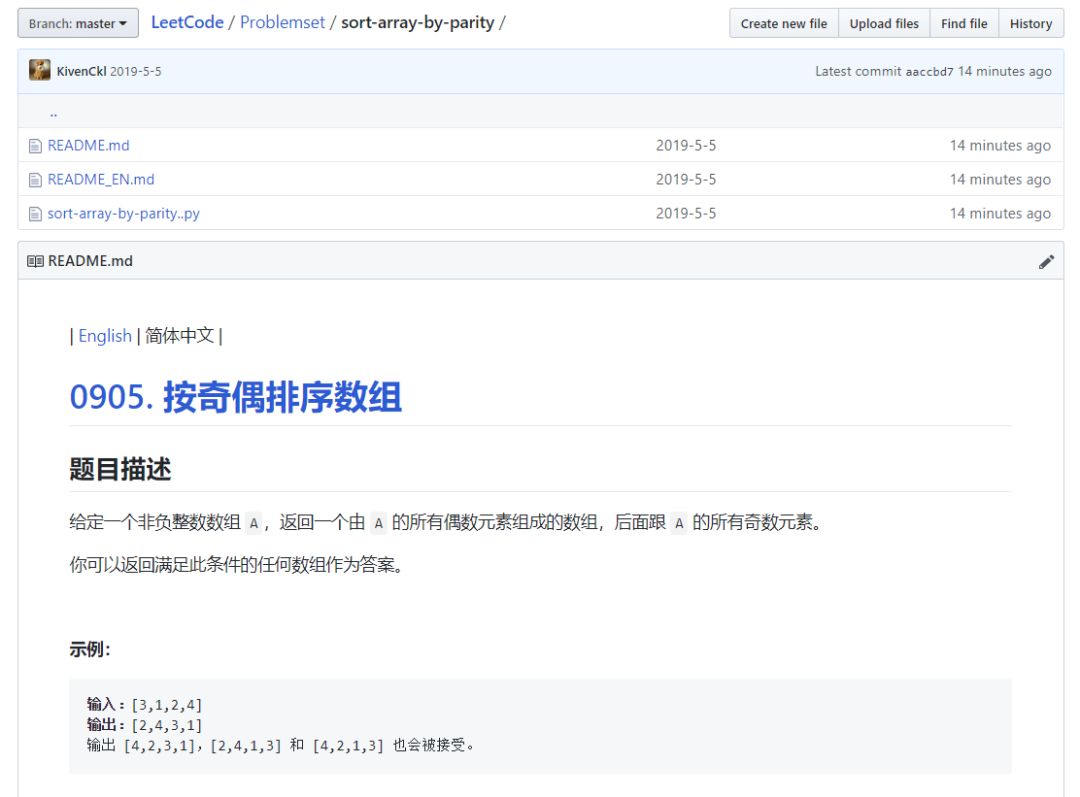
具体效果以及爬取的具体数据可参看 repo: LeetCode
https:
你可以根据你自己的需求爱好修改 templates.py 其中的模板
可以修改其根目录下的 config.json 文件:
{
"username": "leetcode-cn@leetcode",
"password": "leetcode",
"outputDir": "../LeetCode"
}

▼ 点击成为社区注册会员 「在看」一下,一起PY!







