

作者 | Yura
责编 | 胡巍巍
高尔基这话有没有道理我不知道,
咱也不敢问,
主要是现在也问不了。
那对我来说,读书有什么意义呢?
应该也是阶梯。

但是这影响是消极还是积极,
投入的时间和得到的回报到底成不成正比?
每本都不一样,
这很大情况与书的质量有关。
那么问题就来了,
我们到底该读什么书呢?
换言之,
若想阶梯又稳又长,
需要什么样的砖呢?
我知道豆瓣有评分TOP100的书籍榜单,
但是看着这一长串的列表,
我觉得不够有人情味。
我平时书荒的时候喜欢逛知乎,
那些带有“小红书”式夸张描述,
“必读,不可错过”“跪了”“强推“,
往往让我有一种马上买它!
啊,不是,
下载它的冲动!
上个月我买了个电子书下载的会员,
每天可以将书直接推送Kindle,
非常方便!
但是,会员是要钱的,
而且,是有时间限制的……
一眨眼,还有3天就到期了。
想想自己上个月顶多下载了3本书
现在还有3天就过期了
相当于白白浪费了
20本*(30-3天)-3本=537本书的下载机会。
还剩下3天,我一定要利用起来!
每天下载60本(哪年哪月能看完我们暂时不讨论了)。
但是知乎一条一条翻答案未免太麻烦了8!
而且好几条都是推荐差不多内容的,
不如爬取相关问题的所有答案,
做个汇总好啦!

数据获取
虽说知乎有个“阅读”的话题,但是我看了一下里面的问题不全是推荐书的,若是都爬取下来可能80%的数据都是与书籍推荐无关的。
所以我直接知乎搜索“书”,选取了回答热度较高的6个问题:
还是利用Python进行爬虫,
进入页面,展开答案:

点击“检查”网页,不断往下拉,
我们可以在XHR找到明显带有“answer”字样的链接:
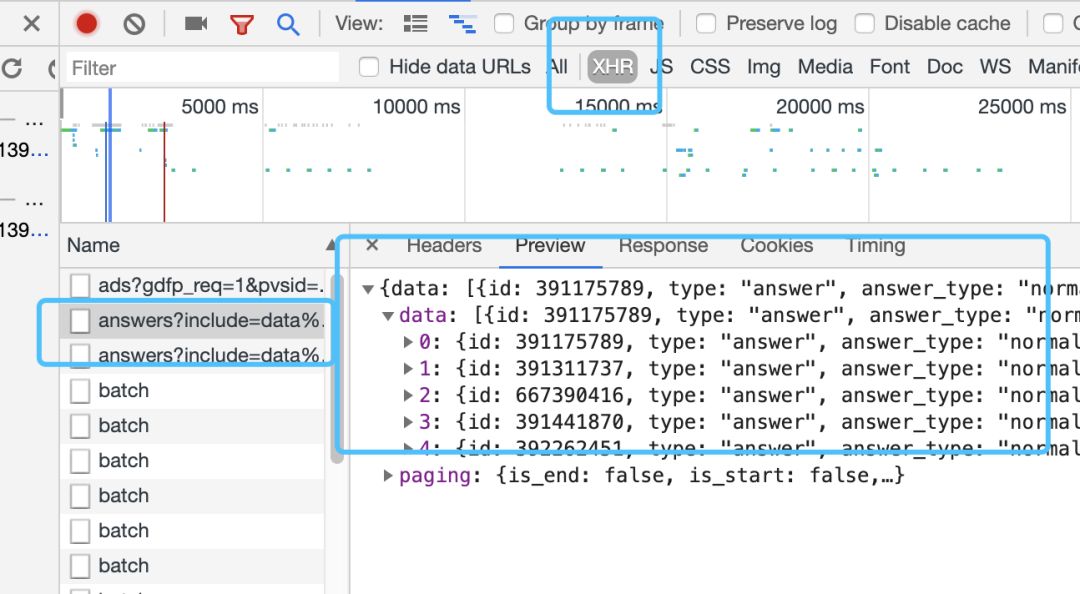
多看几个链接就能找到规律啦,
(offset:0,5,15,20……)
挑自己感兴趣的字段就能“咻咻咻”爬下来了,
其他5个问题如法炮制,得到以下:

总共获取9674个回答,基本字段如下:


数据清洗
以前总觉得爬数据最难,
只要爬下来了,一切好说!
想怎么处理怎么处理,想怎么分析怎么分析。
但是这次,
爬虫的主要目的是列出一个高频出现的书籍清单,
大家的答案有言简意赅的
(我暂且不批评这些同学会的不带书名号):
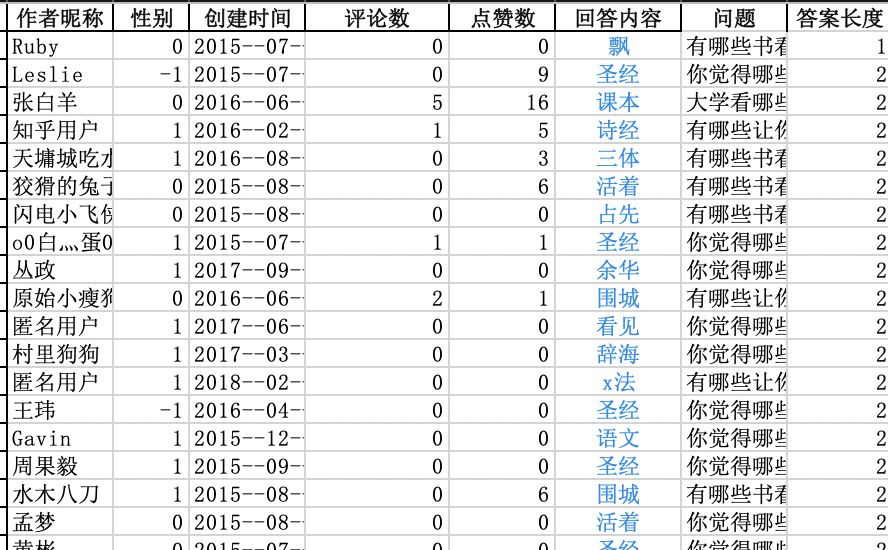
也有这样,推荐语(废话)一大堆的:
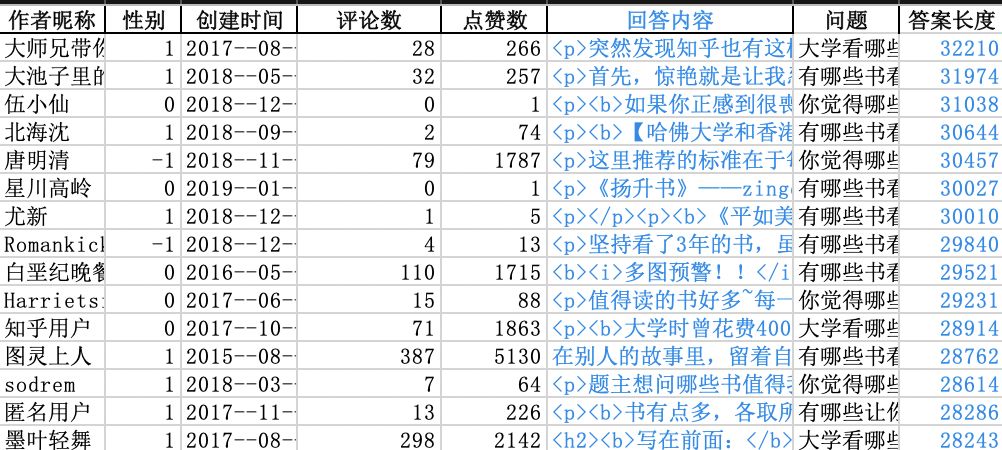
你瞧瞧,回答字数最多的可有3万多字呢!
研究爬虫大概花了我一个小时,
但是怎么分析这些答案让我头痛了三个晚上!
先看一下主要的问题:
很多答案没有带书名号,因此不能简单地用正则表达式;
知友们回答的时候会出现书名打错(“一句话顶一万句”),还有书名简写或表达方式不同的情况(比如,关于哈利波特系列书籍的说法就有11种……);
最重要的是,我还不具有“看到一个词或一句话就分辨出哪些是书名哪些不是”的能力。我自己都不知道,我怎么让Python判断提取呢……
我也曾想过干脆只用《》来正则匹配内容
结果发现:
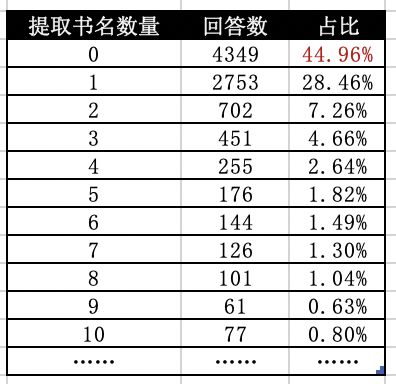
44.96%的用户回答问题的时候非常不规范,
他们在回答中没有有使用书名号!
直接这样分析的话就相当于丢失了将近一半的数据!
💡除非……除非我有一个图书库,
里面有所有书的书名,
这样我只要遍历每个答案,
如果Ta提到了这本书,
就把这个书名提取出来,
最后再统计分析就好啦!
然而,那句话怎么说来着,
想象很丰满,现实很骨感。
我并没有这样的图书库。
利用现有的数据,
我只能勉强以另外55.04%个答案中出现的书名,
进行简单处理,
得到一个简陋的书名列表……

然后再对每个答案进行遍历……
个中辛酸就不提了,提了也没用。
因为并不是完美的解决之道,
只能勉强满足我本次爬虫的目的罢了,
不过就我走过的一些坑,我还是列一下。
虽然前方有很多坑
但是大家能少进一个就少进一个吧:






数据分析
在得到最终TOP书单之前,
我们按照惯例看看这些答案的基本情况。
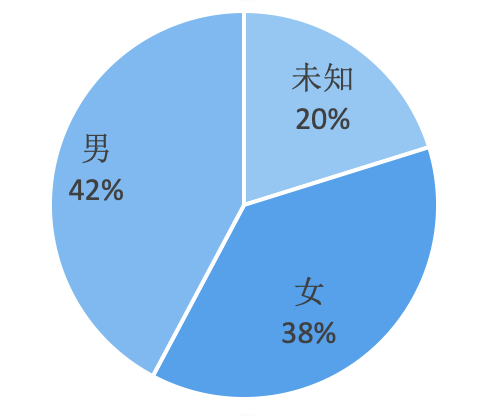
知乎后台性别显示的是0、1和-1,
通过研究具体两三个用户的资料,
我发现0表示女生,1表示男生,-1表示未知。
看样子这6个答案下面男生的比例略高于女生。

男生和女生回答问题的长度很接近,
说明大家都蛮勤奋的,
从互动角度来看,
男生答案人均点赞数略高于女生,
人均评论数却高出女生55%,
可能他们的答案比较具有争议性。
不过读书这种事嘛,
本来就是男女老少皆宜的,
因此在这种话题下区别性应该不大。
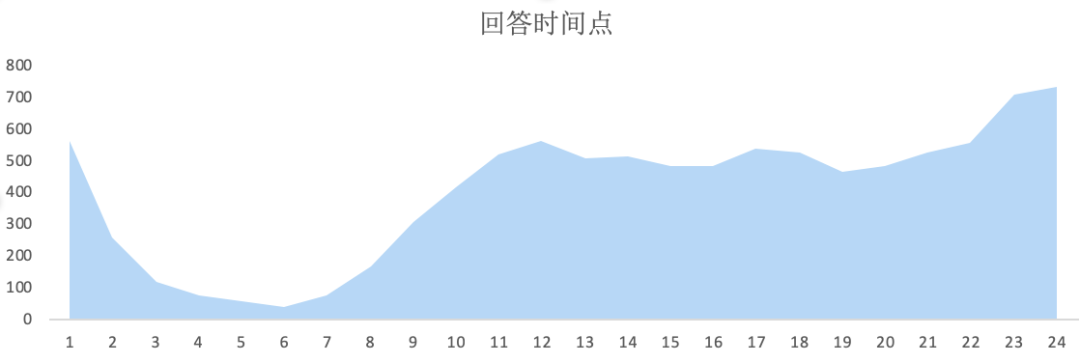
和正常(现代)人的作息很接近,
大部分答案是在白天的时候提交的,
其中有11%的用户在凌晨0到4点之间回答,
我觉得这部分人睡前肯定没有看书。
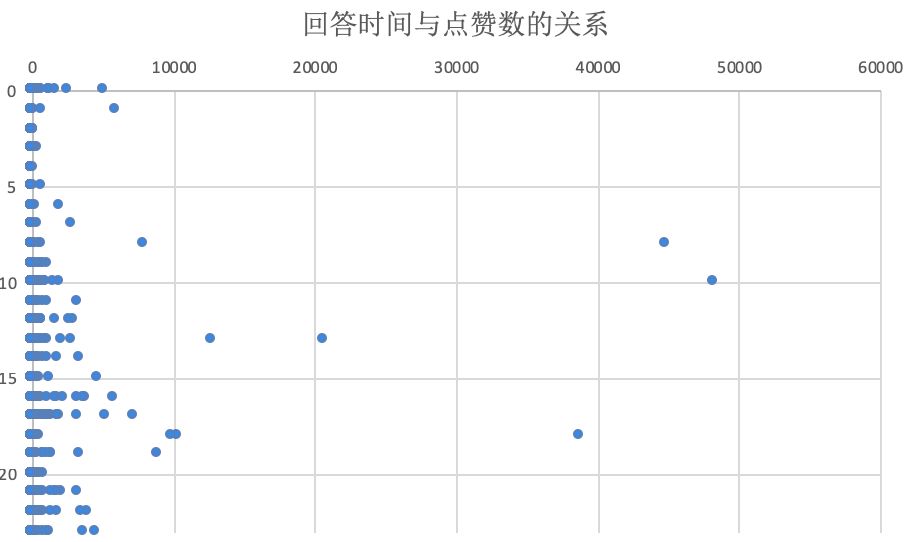
从回答时间和点赞数的散点图来看,
一些高赞答案都是出现在早上8点到晚上8点之间
这段时间大家精神充沛,
比较容易写出高质量答案,
养生Girl再次呼吁,大家一定要早睡呀!
有人问睡不着怎么办?
我上一段不是说了嘛(自行体会)。
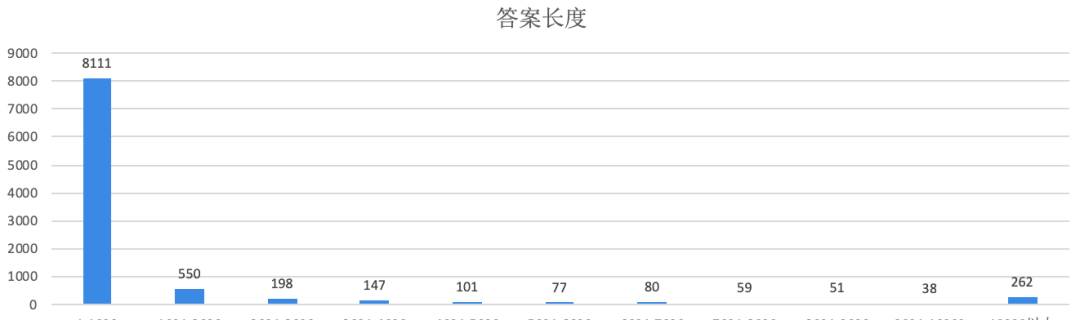
前面也提到过,
答案字数最少的回答,
只有一个字:飘。
长度最长的有32210个字
是我毕业论文长度的1.5倍。
整体统计了一下,
84%的答案长度在1000字以内,
很符合大家碎片化阅读的习惯。
然而,
另外的16%用户却获得了这些答案下
93%的点赞数和72%的评论数。
瞧,瞧瞧(敲黑板),
多么形象的二八法则实例,
快做笔记同学们!

后来看看,
我得到的这三天需要下载的书单
(按照知友提到的频次排序):


98本里面我看过30本,
那么我可以从剩下的68中去掉8本
我绝对不想看的。
然后每天下载20本。
有人问为什么是TOP98,不是100?
因为我觉得这样看起来比较少,
会更有动力“yes”所有书。
作者:Yura,计算机科学与技术专业大四在读,因在澳洲交换学习接触了大数据,甚感兴趣。遂开公众号“Yura不说数据说”督促自己学习数据分析!欢迎大家关注我的个人公众号,一起(监督我)学习。
【END】
作为码一代,想教码二代却无从下手:
听说少儿编程很火,可它有哪些好处呢?
孩子多大开始学习比较好呢?又该如何学习呢?
最新的编程教育政策又有哪些呢?
下面给大家介绍CSDN新成员:极客宝宝(ID:geek_baby)
戳他了解更多↓↓↓

热 文 推 荐
☞ 一顿操作猛如虎!云原生应用为何如此优秀?
☞ 开了个会:破局企业云通信,华为加速 Buff 开发者!
☞ Google 究竟是不是要用 Fuchsia OS 取代 Android?
☞ 最全 Python 算法实现资源汇总!
☞ @程序员,不加班就滚吧 | 程序员有话说
☞ 独家! 币安被盗原因找到了! 7074枚比特币竟是这样丢掉的
☞ 用对方法,开发与部署深度学习原来如此简单……
☞ 什么叫云原生应用?| 技术头条
☞ 补偿100万?Oracle裁900+程序员,新方案已出!
 点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。








