关系数据库帝国已经独孤求败几十年了!
自从1970年E.F.Codd 的《大型共享数据库的关系模型》论文横空出世,为关系型数据库奠定了坚实的理论基础,一众关系数据库System R,DB2 ,Oracle,MySQL,Postgres相继诞生,一举推翻了层次和网状数据库的统治。
在过去的几十年中, 对象数据库, NoSQL等相继挑战,但是依然无法撼动它的地位。
当然关系数据库也不是停滞不前,它也在进化,统一的SQL标准,强大的事务支持,更加聪明的查询优化器......
但是帝国也有一个巨大的硬伤,数据都保存在硬盘上,比起内存和CPU来,硬盘实在是太慢了。 如果说内存是火箭的话,硬盘就是驴车。
帝国想出了很多办法,但总是不能彻底解决问题,到目前为止,一个比较好的办法就是使用B+树。
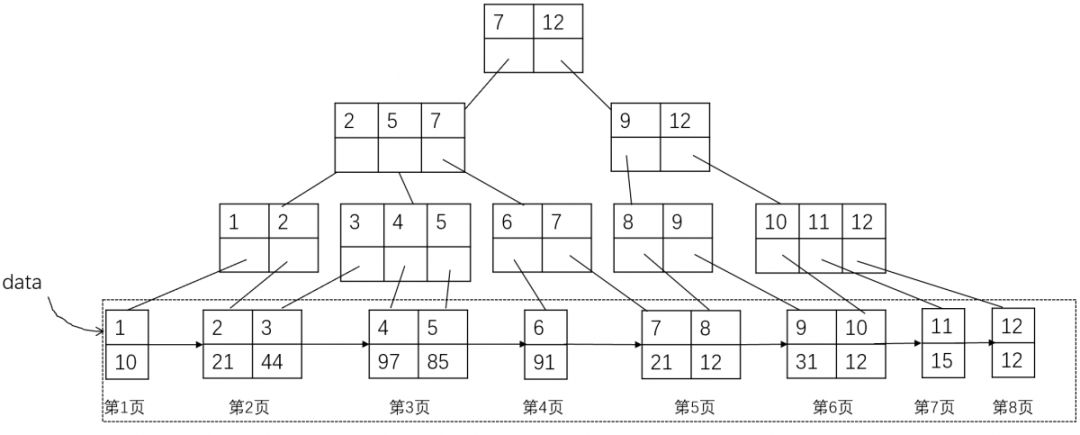
比如有一张表User, 假设它只有两列(id, age),ID为主键Key。
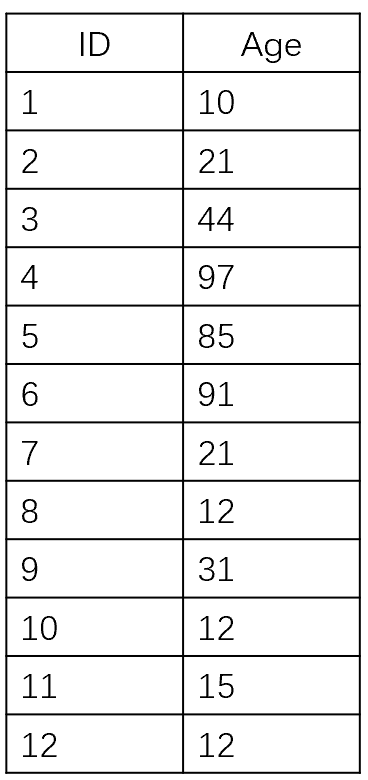
图1
那么它的B+树存储结构为:
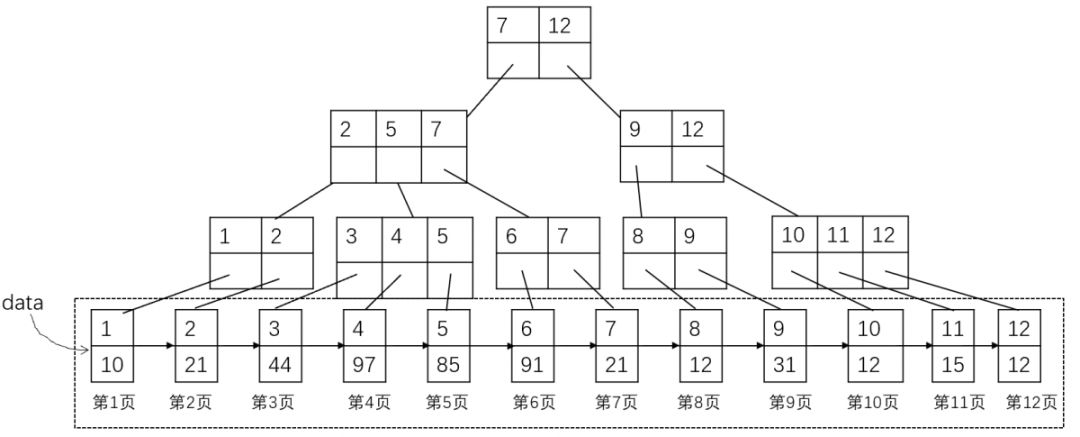
(图2:B+树中节点也保存在磁盘块中)
最后一层为有序的数据页,每个页包含指向下一个数据页的页号(也就是地址),这里假设一条记录占据一个数据页,那么第一条记录在1号数据页,第二条记录在2号数据页,依次类推。
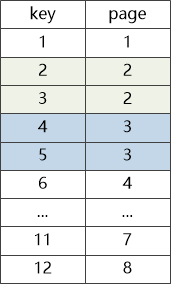
这样以来,如果用户想获取ID = 4的记录,数据库只需要读取三次磁盘就可以找到记录所在的数据的页号(page)为4。
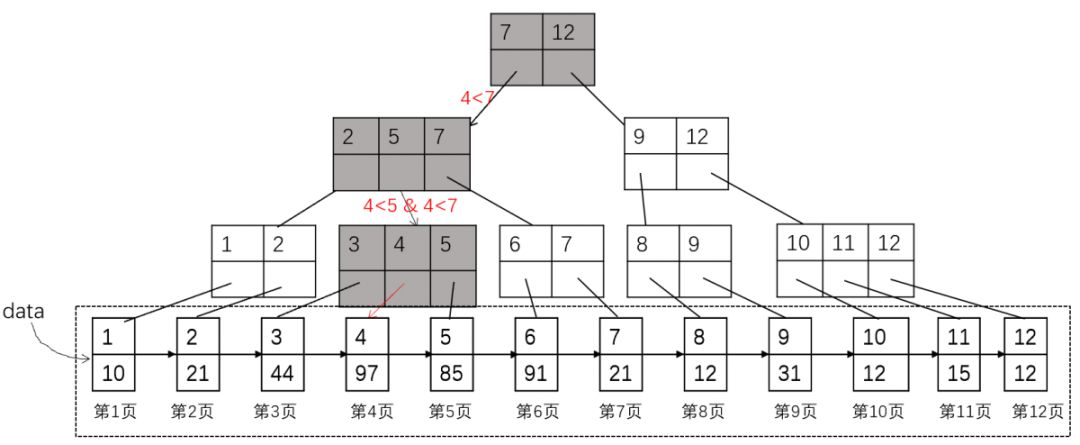
图3
这一天, 帝国的早朝上来了一位神秘的客人,号称是机器学习王国的大使,他自称带来了一个咒语,能够根据一个数据库记录的索引列的值(比如主键Key=4),瞬间定位到记录的页号( page = 4),连那三次硬盘读写都不需要。
这绝对是个革命性的技术,国王非常感兴趣,下旨让大使详细讲述。
B+树大臣马上就感受到了威胁,如果真有这个咒语,自己官位不保,于是他赶紧阻止:“陛下,老夫有所耳闻,机器学习虽然风靡IT世界,但是也有很多招摇撞骗,不着边际的故事,这个大使,很有可能就是想推销几个鬼都看不懂的数学模型来骗钱!”
国王把没有说话,把目光射向大使。
机器学习大使脸微微一沉,心中想到,不把这个老头子搞定,也就无法说服国王, 既然你送上门来,我就拿你开刀吧。
他主意打定,胸有成竹,先给B+树大臣戴高帽挖个坑: “大人误会了,小人知道您在数据库王国是绝对的中流砥柱, 您采用多叉平衡树的方式,降低了索引层次,减少了硬盘I/O时间,并在叶子节点上维护一个根据key(索引列)排序的线性表(S),获得了范围查询的能力....”
B+树微微一笑,心想这小子是有备而来啊,懂得不少。
然而大使话锋一变:“但是,说白了,它就是一个通过key获取数据记录页面(page)一个映射关系!而这和机器学习中的回归要干的事情是一样的,都是通过一些特征预测目标值,比如通过每个人的年龄,收入等信息预测你的潜力值,只不过说在数据库这个场景下key是特征,page是目标值。”
B+树不屑道:“难道机器学习只要是映射就可以学吗?有点忽悠了吧!”
大使忍住这当面的嘲讽,平心静气地说:“您要知道,这个key和page之间是有关系的!而您正是忽略它两者可能存在的强关联!。”
说到这里,大使不知道从哪里变出一块小黑板,在上面画了图2,然后说:“比如说我现在有一堆数据,每条记录占一个数据页,他们的key和page之间的关系是这样的 ”
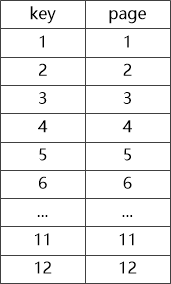
机器学习大使清了清嗓子:“对于机器学习模型,比如我用一个简单的线性回归算法,假定模型为page=a * key + b,而我们当前训练集,也就是这棵B+树中key与之对应page数据(1,1),(2,2)…(12,12),也就是说a,b必须得满足1=a+b,2=2a+b…12=12a+b这12个等式,就相当于我们小时候求解二元一次方程组一般,我们得到a = 1,b = 0, 于是乎我们得到了最终模型page = key!”
B+树大臣冷笑一声,转向国王:“陛下,别被他的数学公式蒙蔽,这是骗小孩的把戏!哪有page = key这么简单的情况! 再说了,这种简单的情况,还用得着机器学习? 我用肉眼都看出来他们的关系是page=key! 来来来,机器学习大使,我给你说个复杂点儿的情况,如果有些数据页能装两条记录呢?你给我说说page 和key 之间的关系是啥?”
现在的对应关系不是那么简单了。
机器学习大使不仅不慢不紧不慢地回答道:“线性模型只是我们大家族中最简单的地模型罢了,不管你一个数据页能存储几条记录, 只要给出(key,page)对应的数据集合,我们都可以训练神经网络,找到满足他们之间关系的一个函数 page = f(key)!通过这个函数,只要你给出key的值,立刻就能得出page! ”
B+树有点明白了,这机器学习就是为了找到一个key和页面之间的关系啊,以后访问起来就方便了,他背上开始冒汗了。
机器学习大使穷追不舍,亮出了最大杀招:“使用B+树, 存储开销是O(n/m)(m为树的出度),查询开销是O(log(n)), 而使用神经网络,查询开销是O(1) !”
O(1) !
听到这句话, 全场一片哗然,所有人都知道这意味着什么,这就是革命呀,革B+树的命呀!
大臣们开始窃窃私语:“这神经网络很厉害啊!”
“是啊!神经网络最擅长干这个事情了!从一堆数据中找到关联关系。”
“听说神经网络在两层的情况下就能够拟合一切函数!”
B+树大臣有点慌,语气也弱了下来:“你们机器学习是很牛逼,但像LR,GBDT,SVR,包括你说的这些神经网络,一些深度学习的方法,哪个不是有一定错误率的,位置预测错误,难道要全部扫描一遍数据不成,你们懂不懂我们索引的业务呀!”
机器学习大使早就预料到了会有这个问题, 他一字一句郑重道:“将机器学习赋能数据库,我们是认真的! 传统这些预测算法的应用场景,都是在训练数据数据集里做训练,然后对未知的数据做预测。但索引这个场景,嘿嘿,它是一个封闭场景,没有新的数据,只需要对数据库中存在的数据做预测即可,这种场景下,就像我刚才提到的神经网络完全可以胜任,直接就在当前数据上,训练到做到百分百的正确率即可。”
全场再次哗然,众位大臣齐刷刷地看着国王,似乎等待着最终的宣判。
B+树大臣顿时印堂发黑,心想几十年的风光就要今日终结吗,本来随着SSD等新型硬件的诞生我的日子就不好过了, 难道今日命丧机器学习之手?悲伤难以平复,摇摇欲坠。
这个时候,CBO(基于代价的优化器)从后面走过来,一把扶住B+树,看着这个日益苍老的老头,说道:“大人莫慌,别看他和嚣张,但是有巨大漏洞,看我来对付他。”
CBO大臣说道:“你之前说的只是查找和存储性能,索引的维护(增/删/改)代价难道不用考虑吗,如果索引发生了变化,之前的page= f(key)这个函数还有效吗? 是不是还得重新训练神经网络,找到新的函数 page = f1(key)? 这还是O(1)的时间复杂度吗?我们数据库面对的是通用场景,不要以为只考虑几个case就觉得可以替代我们了!”
机器学习大使大惊,功败垂成!自己已经隐藏的这么深,还是被发现了缺陷,顿时红了个脸:“您说的对,我们在索引的更新上还没有很好的解决方案,但我们只是想为数据库索引带来一些新鲜想法,做现在的技术选项的补充,并没有想着取代谁。”
B+树一听,立刻满血复活:“陛下,您看看,这是一个不成熟的方案,对于数据查找能做到O(1), 但是对于数据更新就完全不行了,居然还想替代我!我就说这机器学习是招摇撞骗嘛!”
数据库国王摇摇头:“爱卿所言差矣,这个机器学习的思路还是非常新奇的,我们还是要学习一下的, 来人,给机器学习大使送上白银千两,好好安顿。”
这篇文章的灵感来源于一篇论文《The Case for Learned Index Structures》,实际上真正要把机器学习应用的索引上,就算考虑只读场景,往往也会因为数量太大,关系太多复杂,导致计算量、模型复杂度方面的问题,所以提出这个论文的作者提到通过建立层次模型的方式解决:根节点的分类器将记录划分成n份,给下一层分类器进行分类,这样节点的预测器学习的数据少而简单,总体的时间成本也能够保证。






