在平时的工作中,经常需处理字符串型数据:
如何截取字符串中的某一段内容?
如何按某个指定的分隔符将其切割开?
如何对某些值进行替换等?
在Excel里很容易操作,可以使用文本函数或者Power Query:
文本函数
Power Query
text.remove函数
text.select函数
…………
如果在Python里,该如何处理呢?
01字符串构造方法
1.三种方法构造字符串:
单引号、双引号、三引号
2.使用符号构建字符串规则:如果字符串的内容
不包含任何引号,那么单引号、双引号和三引号都可以;
-
仅包含双引号如string1,只能使用单引号或三引号;
仅包含单引号如string2,只能使用双引号或三引号;
既包含单引号,又包含双引号如string3,只能使用三引号。
注:三引号是适用情况最多的字符串构造方法,而且三引号允许长字符串的换行,这是其他两种引号无法实现的,如变量string4所示。
# 单引号构造字符串string1 = '"欢迎关注Excel知识管理微信公众号,我是数据可视化爱好者李强"'# 双引号构造字符串string2 = "'这是我的第五篇Python读书笔记,希望能帮到大家更好地入门Python'"# 三引号构造字符串string3 = ''''Tips':"如果你觉得从零开始学Python系列很好, 请分享给你的朋友们"'''string4 = '''欢迎关注Excel知识管理微信公众号,我是数据可视化爱好者李强。如果你觉得从零开始学Python系列很好,请分享给你的朋友们。'''print(string1)print(string2)print(string3)print(string4)out:"欢迎关注Excel知识管理微信公众号,我是数据可视化爱好者李强"'这是我的第五篇Python读书笔记,希望能帮到大家更好地入门Python''Tips':"如果你觉得从零开始学Python系列很好, 请分享给你的朋友们"欢迎关注Excel知识管理微信公众号,我是数据可视化爱好者李强。如果你觉得从零开始学Python系列很好,请分享给你的朋友们。
02字符串常用方法汇总及示例

字符串常用方法示例
# 获取身份证号码中的出生日期print('123456198901017890'[6:14])# 将手机号中的中间四位替换为四颗星tel = '13612345678'print(tel.replace(tel[3:7],'****'))# 将邮箱按@符分隔开print('12345@qq.com'.split('@'))# 将Python的每个字母用减号连接print('-'.join('Python'))# 删除" 今天星期日 "的首尾空白print(" 今天星期日 ".strip())# 删除" 今天星期日 "的左边空白print(" 今天星期日 ".lstrip())# 删除" 今天星期日 "的右边空白print(" 今天星期日 ".rstrip())# 计算子串“中国”在字符串中的个数
string5 = '中国方案引领世界前行,展现了中国应势而为、勇于担当的大国引领作用!'print(string5.count('中国'))# 查询"Python"单词所在的位置string6 = '我是一名Python用户,Python给我的工作带来了很多便捷。'print(string6.index('Python'))print(string6.find('Python'))# 字符串是否以“2018年”开头string7 = '2017年匆匆走过,迎来崭新的2018年'print(string7.startswith('2018年'))# 字符串是否以“2018年”年结尾print(string7.endswith('2018年'))out:19890101136****5678['12345', 'qq.com']P-y-t-h-o-n今天星期日今天星期日 今天星期日244False
True
注:
字符串的index和find方法都是只能返回首次发现子串的位置;
如果子串在原字行串中没有找到,对于 index 方法来说,则返回报错信息,对于find 方法,则返回值-1;
推荐便用 find 方法寻找子串的位置,因为即使找不到子串也不会因为错误而影响其他程序的正常执行。
03正则表达式
本节记录正则表达式完成字符串查询匹配、替换匹配和分割匹配。
有时,光靠字符串的上述“方法”无法实现字符串的其他处理功能,例如:
怎样在字符串中拢到有规律的目标值?
怎样替换那些不是固定值的目标内容?
怎样按照多个分隔符将字符串进行切割等?
此时需要用到字符串的正则表达式:从字符串中发现规律, 并通过“抽象”的符号表达出来。
常用的正则符号表
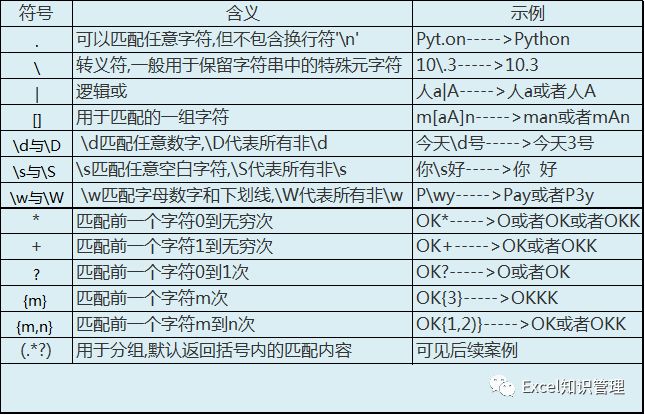
正则表达式完成字符串的查询、替换和分割操作都需要导入re模块,并使用如下几个函数。
1.匹配查询函数
findall(pattern,string,flags=0)
findall 函数可以对指定的字符串进行遍历匹配,获取字符串中所有匹配的子串,并返回一个列表结果。参数含义:
re.I的模式是让正则表达式对大小写不敏感;
re.M的模式是让正则表达式可以多行匹配;
re.S的模式指明正则符号.可以匹配任意字符,包括换行符\n;
re.X 模式允许正则表达式可以写得更加详细,如多行表示、忽略空白字符、加入注释等。
2.匹配替换函数
sub(pattern,repl,string,count=0,flags=0)
sub 函数的功能是替换, 类似于字符串的 replace 方法,该函数根据正则表达式把满足匹配的内容替换为repl。 参数含义:
pattern:同findall函数中的 pattern;
repl:指定替换成的新值;
string:同 findall函数中的 string;
count:用于指定最多替换的次数,默认为全部替换;
flags:同 findall函数中的 flags。
3.匹配分割函数
split(pattern,string,maxsplit=0,flags=0)
split 函数是将字符串按照指定的正则表达式分隔开,类似于字符串的 split方法。 参数含义:
pattern:同findall函数中的 pattern;
maxsplit:用于指定最大分割次数,默认为全部分割;
string:同 findall 函数中的 string;
flags:同findall函数中的flags;
4.通过案例加强理解三个函数:
# 导入第三方包import re
# 取出出字符中所有的天气状态string8 = "{ymd:'2018-01-01',tianqi:'晴',aqiInfo:'轻度污染'},{ymd:'2018-01-02',tianqi:'阴~小雨',aqiInfo:'优'},{ymd:'2018-01-03',tianqi:'小雨~中雨',aqiInfo:'优'},{ymd:'2018-01-04',tianqi:'中雨~小雨',aqiInfo:'优'}"print(re.findall("tianqi:'(.*?)'", string8))print(re.findall("tianqi:'.*?'", string8))
# 取出所有含O字母的单词string9 = 'Together, we discovered that a free market only thrives when there are rules to ensure competition and fair play, Our celebration of initiative and enterprise'print(re.findall('\w*o\w*',string9, flags = re.I))print(re.findall('(\w*o\w*)',string9, flags = re.I))
# 将标点符号、数字和字母删除string10 = '据悉,这次发运的4台蒸汽冷凝罐属于国际热核聚变实验堆(ITER)项目的核二级压力设备,先后完成了压力试验、真空试验、氦气检漏试验、千斤顶试验、吊耳载荷试验、叠装试验等验收试验。'print(re.sub('[,。、a-zA-Z0-9()]','',string10))
# 将每一部分的内容分割开string11 = '2室2厅 | 101.62平 | 低区/7层 | 朝南 \n 上海未来 - 浦东 - 金杨 - 2005年建'split = re.split('[-\|\n]', string11)print(split)split_strip = [i.strip() for i in split]
print(split_strip)out:['晴', '阴~小雨', '小雨~中雨', '中雨~小雨']["tianqi:'晴'", "tianqi:'阴~小雨'", "tianqi:'小雨~中雨'", "tianqi:'中雨~小雨'"]['Together', 'discovered', 'only', 'to', 'competition', 'Our', 'celebration', 'of']['Together', 'discovered', 'only', 'to', 'competition', 'Our', 'celebration', 'of']据悉这次发运的台蒸汽冷凝罐属于国际热核聚变实验堆项目的核二级压力设备先后完成了压力试验真空试验氦气检漏试验千斤顶试验吊耳载荷试验叠装试验等验收试验['2室2厅 ', ' 101.62平 ', ' 低区/7层 ', ' 朝南 ', ' 上海未来 ', ' 浦东 ', ' 金杨 ', ' 2005年建']['2室2厅', '101.62平', '低区/7层', '朝南', '上海未来', '浦东', '金杨', '2005年建']
注:如上结果所示:
例一通过正则表达式"tianqi:'(.*?)'"实现目标数据的获取,如果不使用括号的话,就会产生类似"tianqi:'晴'","tianqi:'阴~小雨'"这样的值,所以,加上括号就是为了分组,且仅返回组中的内容;
例二并没有将正则表达式写入圆括号,如果写上圆括号也是返回一样的结果,所以 findall 就是用来返回满足匹配条件的列表值,如果有括号,就仅返回括号内的匹配值;
例三使用替换的方法,将所有的标点符号换为空字符,进而实现删除的效果;
例四是对字符串的分割,如果直接按照正则'[,。、a-zA-Z0-9()]'分割的话,返回的结果中包含空字符,如'2室2厅'后面就有一个空字符。 为了删除列表中每个元素的首尾空字符,使用了列表表达式并结合字符串的strip方法完成空字符压缩。
补充阅读:关于例四中列表表达式可以查看上一篇笔记:
004从零开始学Python—控制流
整体感受:正则表达式是一个应用范围很广的存在,无论是在Python中还是在VBA中,都能派上大用场。应该属于知识中的元知识,如果攻不下这个山头,后续就无法顺畅地深入学习。
读书笔记内容来源:《从零开始学Python数据分析与挖掘》







