
向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
LightGBM是个快速的,分布式的,高性能的基于决策树算法的梯度提升框架。可用于排序,分类,回归以及很多其他的机器学习任务中。
在竞赛题中,我们知道XGBoost算法非常热门,它是一种优秀的拉动框架,但是在使用过程中,其训练耗时很长,内存占用比较大。在2017年年1月微软在GitHub的上开源了一个新的升压工具--LightGBM。在不降低准确率的前提下,速度提升了10倍左右,占用内存下降了3倍左右。因为他是基于决策树算法的,它采用最优的叶明智策略分裂叶子节点,然而其它的提升算法分裂树一般采用的是深度方向或者水平明智而不是叶,明智的。因此,在LightGBM算法中,当增长到相同的叶子节点,叶明智算法比水平-wise算法减少更多的损失。因此导致更高的精度,而其他的任何已存在的提升算法都不能够达。与此同时,它的速度也让人感到震惊,这就是该算法名字 灯 的原因。
2014年3月,XGBOOST最早作为研究项目,由陈天奇提出
(XGBOOST的部分在另一篇博客里:https://blog.csdn.net/huacha__/article/details/81029680
2017年1月,微软发布首个稳定版LightGBM
在微软亚洲研究院AI头条分享中的「LightGBM简介」中,机器学习组的主管研究员王太峰提到:微软DMTK团队在github上开源了性能超越其它推动决策树工具LightGBM后,三天之内星了1000+次,叉了超过200次。知乎上有近千人关注“如何看待微软开源的LightGBM?”问题,被评价为“速度惊人”,“非常有启发”,“支持分布式” “代码清晰易懂”,“占用内存小”等。以下是微软官方提到的LightGBM的各种优点,以及该项目的开源地址。

科普视频:如何玩转LightGBM https://v.qq.com/x/page/k0362z6lqix.html
目录
一、"What We Do in LightGBM?"
二、在不同数据集上的对比
三、LightGBM的细节技术
1、直方图优化
2、存储记忆优化
3、深度限制的节点展开方法
4、直方图做差优化
5、顺序访问梯度
6、支持类别特征
7、支持并行学习
四、MacOS安装LightGBM
五、用python实现LightGBM算法
一、"What We Do in LightGBM?"
下面这个表格给出了XGBoost和LightGBM之间更加细致的性能对比,包括了树的生长方式,LightGBM是直接去选择获得最大收益的结点来展开,而XGBoost是通过按层增长的方式来做,这样呢LightGBM能够在更小的计算代价上建立我们需要的决策树。当然在这样的算法中我们也需要控制树的深度和每个叶子结点的最小数据量,从而减少过拟合。

二、在不同数据集上的对比
higgs和expo都是分类数据,yahoo ltr和msltr都是排序数据,在这些数据中,LightGBM都有更好的准确率和更强的内存使用量。
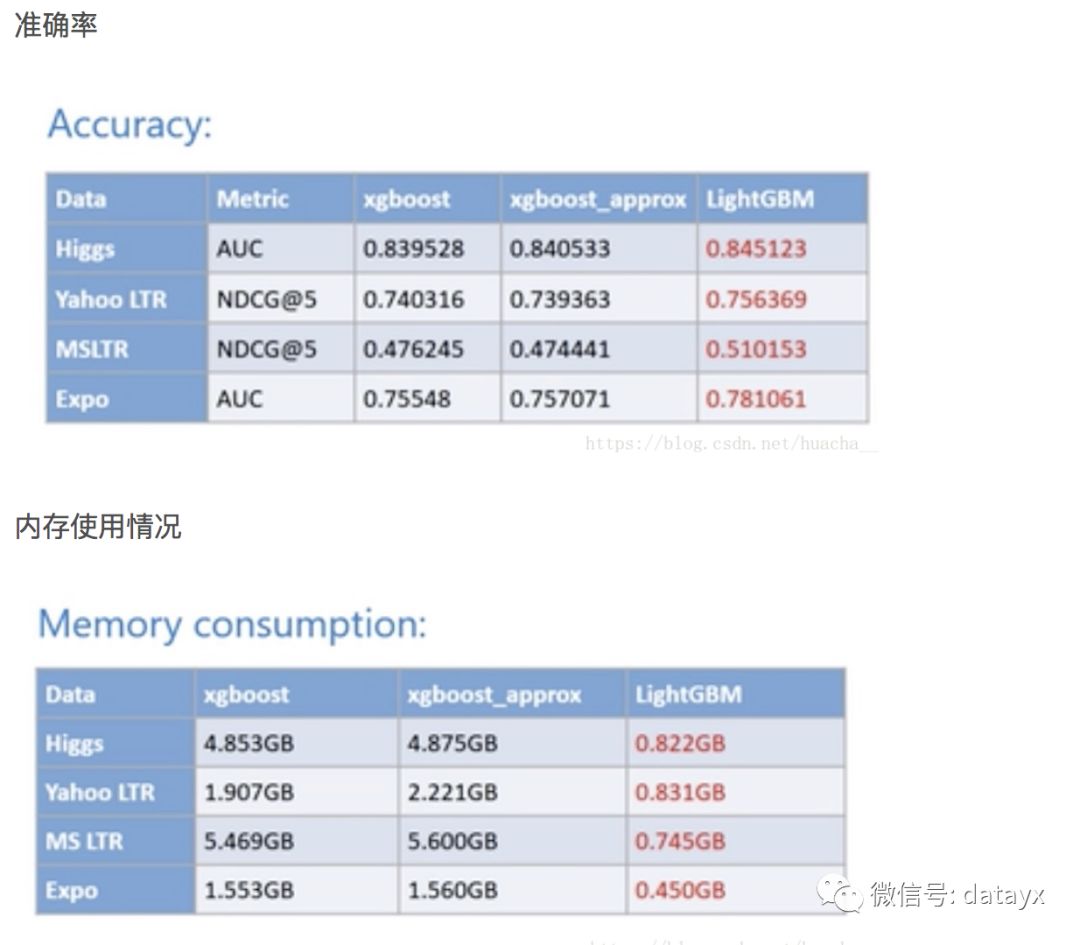
计算速度的对比,完成相同的训练量XGBoost通常耗费的时间是LightGBM的数倍之上,在higgs数据集上,它们的差距更是达到了15倍以上。

三、LightGBM的细节技术
1、直方图优化
XGBoost中采用预排序的方法,计算过程当中是按照value的排序,逐个数据样本来计算划分收益,这样的算法能够精确的找到最佳划分值,但是代价比较大同时也没有较好的推广性。
在LightGBM中没有使用传统的预排序的思路,而是将这些精确的连续的每一个value划分到一系列离散的域中,也就是筒子里。以浮点型数据来举例,一个区间的值会被作为一个筒,然后以这些筒为精度单位的直方图来做。这样一来,数据的表达变得更加简化,减少了内存的使用,而且直方图带来了一定的正则化的效果,能够使我们做出来的模型避免过拟合且具有更好的推广性。
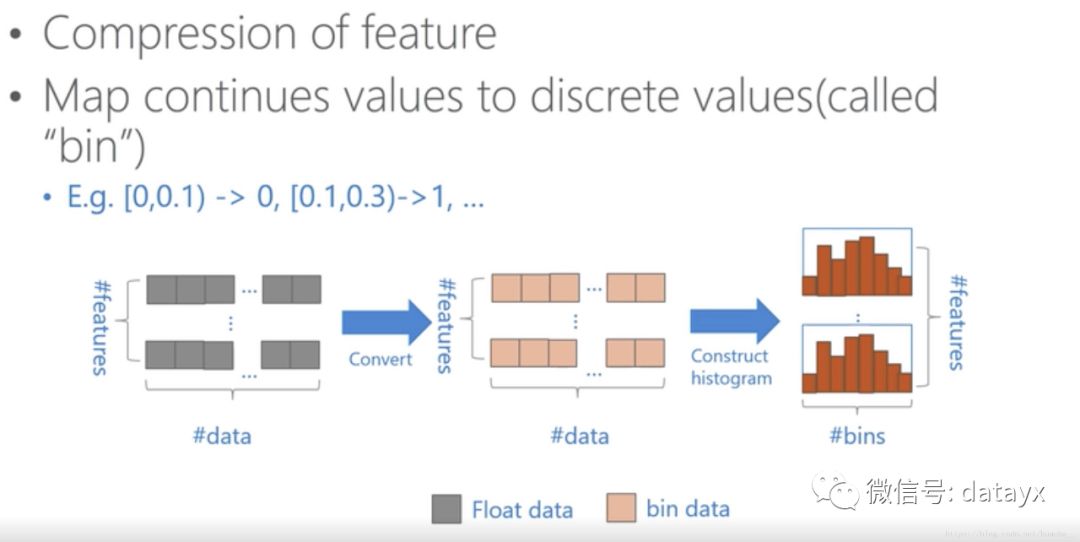
看下直方图优化的细节处理

可以看到,这是按照bin来索引“直方图”,所以不用按照每个“特征”来排序,也不用一一去对比不同“特征”的值,大大的减少了运算量。
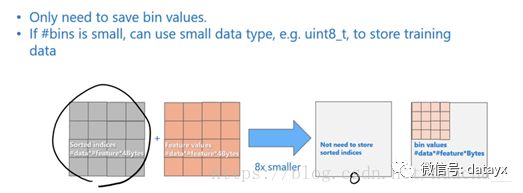
2、存储记忆优化
当我们用数据的bin描述数据特征的时候带来的变化:首先是不需要像预排序算法那样去存储每一个排序后数据的序列,也就是下图灰色的表,在LightGBM中,这部分的计算代价是0;第二个,一般bin会控制在一个比较小的范围,所以我们可以用更小的内存来存储
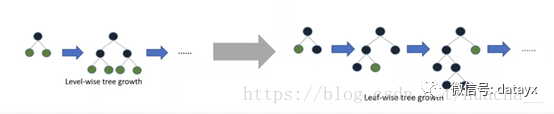
3、深度限制的节点展开方法
LightGBM使用了带有深度限制的节点展开方法(Leaf-wise)来提高模型精度,这是比XGBoost中Level-wise更高效的方法。它可以降低训练误差得到更好的精度。但是单纯的使用Leaf-wise可能会生长出比较深的树,在小数据集上可能会造成过拟合,因此在Leaf-wise之上多加一个深度限制
4、直方图做差优化
直方图做差优化可以达到两倍的加速,可以观察到一个叶子节点上的直方图,可以由它的父亲节点直方图减去它兄弟节点的直方图来得到。根据这一点我们可以构造出来数据量比较小的叶子节点上的直方图,然后用直方图做差来得到数据量比较大的叶子节点上的直方图,从而达到加速的效果。

5、顺序访问梯度
预排序算法中有两个频繁的操作会导致cache-miss,也就是缓存消失(对速度的影响很大,特别是数据量很大的时候,顺序访问比随机访问的速度快4倍以上 )。
对梯度的访问:在计算增益的时候需要利用梯度,对于不同的特征,访问梯度的顺序是不一样的,并且是随机的
对于索引表的访问:预排序算法使用了行号和叶子节点号的索引表,防止数据切分的时候对所有的特征进行切分。同访问梯度一样,所有的特征都要通过访问这个索引表来索引。
这两个操作都是随机的访问,会给系统性能带来非常大的下降。
LightGBM使用的直方图算法能很好的解决这类问题。首先。对梯度的访问,因为不用对特征进行排序,同时,所有的特征都用同样的方式来访问,所以只需要对梯度访问的顺序进行重新排序,所有的特征都能连续的访问梯度。并且直方图算法不需要把数据id到叶子节点号上(不需要这个索引表,没有这个缓存消失问题)
6、支持类别特征
传统的机器学习一般不能支持直接输入类别特征,需要先转化成多维的0-1特征,这样无论在空间上还是时间上效率都不高。LightGBM通过更改决策树算法的决策规则,直接原生支持类别特征,不需要转化,提高了近8倍的速度。

7、支持并行学习
LightGBM原生支持并行学习,目前支持特征并行(Featrue Parallelization)和数据并行(Data Parallelization)两种,还有一种是基于投票的数据并行(Voting Parallelization)
特征并行的主要思想是在不同机器、在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
LightGBM针对这两种并行方法都做了优化。
特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信。
数据并行中使用分散规约 (Reduce scatter) 把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。
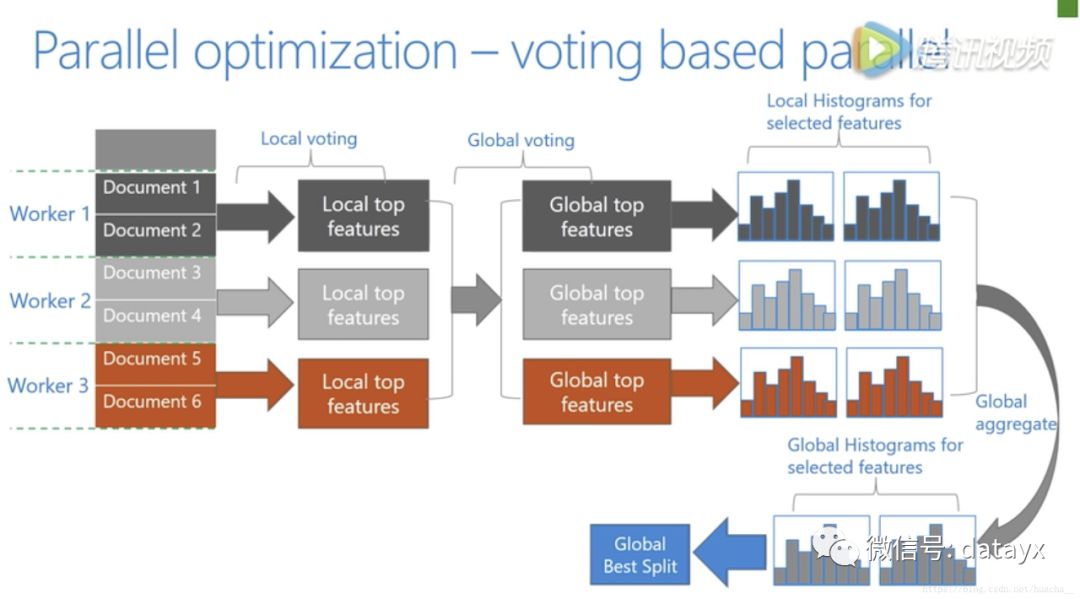
基于投票的数据并行(Voting Parallelization)则进一步优化数据并行中的通信代价,使通信代价变成常数级别。在数据量很大的时候,使用投票并行可以得到非常好的加速效果。
下图更好的说明了以上这三种并行学习的整体流程:

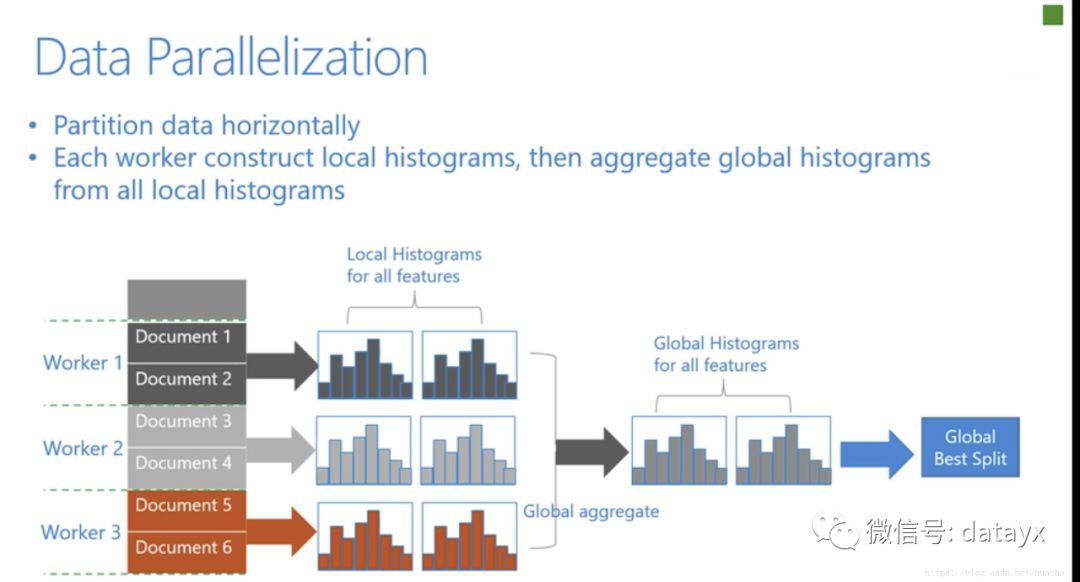
在直方图合并的时候,通信代价比较大,基于投票的数据并行能够很好的解决这一点。
四、MacOS安装LightGBM

值得注意的是:pip list里面没有lightgbm,以后使用lightgbm需要到特定的文件夹中运行。我的地址是:
/Users/ LightGBM /python-package
五,用python实现LightGBM算法
本代码以sklearn包中自带的鸢尾花数据集为例,用lightgbm算法实现鸢尾花种类的分类任务。

输出结果:
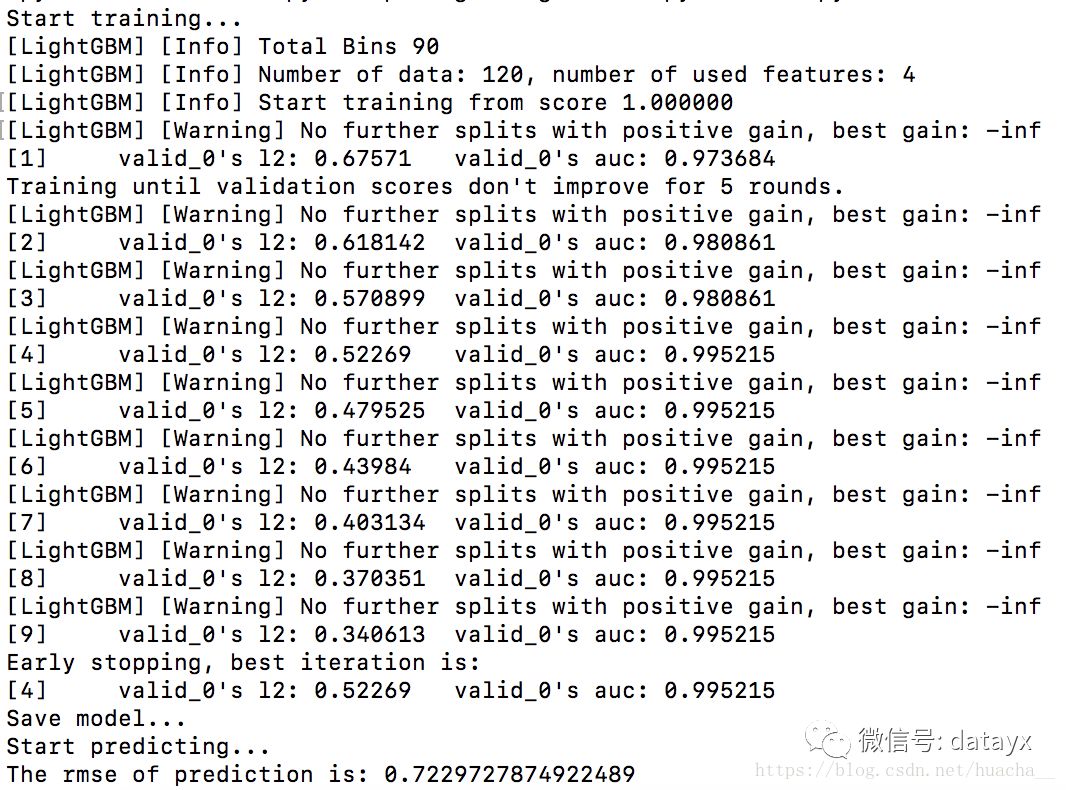
可以看到预测值和真实值之间的均方根误差为0.722972。
原文https://blog.csdn.net/huacha__/article/details/81057150
阅读过本文的人还看了以下:
分享《深度学习入门:基于Python的理论与实现》高清中文版PDF+源代码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
AI项目体验
https://loveai.tech









