
这是我有关使用Python进行自然语言处理系列文章中的第八篇。在上一篇文章中,我解释了如何使用Python的TextBlob库来执行各种NLP任务,从分词到词性标注,从文本分类到情感分析。在本文中,我们将探索Python的Pattern库,这是另一个非常有用的自然语言处理库。
Pattern库是一个多用途的库,它可以处理以下任务:
自然语言处理: 执行诸如标记、词干提取、词性标注、情感分析等任务。
数据挖掘: 它包含从Twitter、Facebook、Wikipedia等网站挖掘数据的API。
机器学习: 它包含SVM、KNN、感知机等机器学习模型,可用于分类、回归和聚类任务。
在本文中,我们将看一下上述列表中关于Pattern库用途的前两个的应用实例。我们将通过执行标记、词干提取和情感分析等任务来探索用于NLP的Pattern库的用法。我们还将看到如何将Pattern库用于web数据挖掘。
安装
你可以使用以下pip命令来安装这个库:

或者,如果你使用的是Python的Anaconda发布版的话,你可以使用以下Anaconda命令去下载这个库:

用于NLP的Pattern 库函数
在本节,我们将看一些Pattern库的NLP应用实例。
标记, 词性标注,和分块
在NLTK和spaCy库中,我们有一个单独的函数用于标记、词性标注和在文本文档中查找名词短语。相反,在Pattern库中有一个多用途的parse方法,它接受一个文本字符串作为输入参数,并返回字符串中相应的标记和词性标注。
parse方法还会告诉我们一个标记是名词短语还是动词短语、主语还是宾语。你还可以通过将lemmata参数设置为True来检索词元化的标记。parse方法的语法以及不同参数的默认值如下:
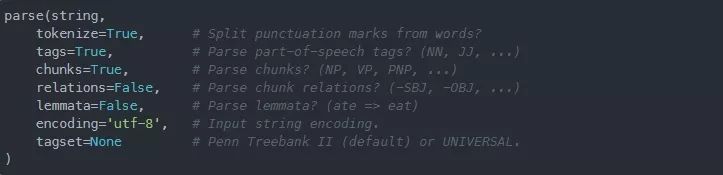
我们来实际查看一下 parse 方法:

要使用parse方法,你必须从pattern库导入en模块。en模块包含英语NLP函数。如果你使用pprint方法在控制台上打印parse方法的输出,你将会看到如下输出:
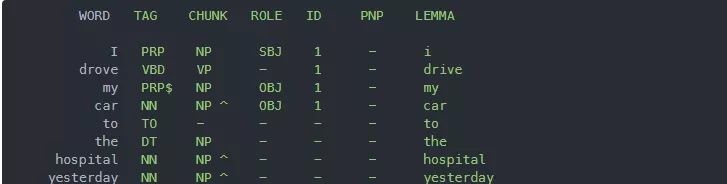
在输出中,你可以看到标记化的单词及其词性标注、该标记所属的块和角色。你还会看到这些标记的词元化形式。
如果你对parse方法返回的对象调用split方法,输出将是一个句子的列表,其中每个句子都是一个标记列表,每个标记都是一个单词列表,以及与单词关联的标记。
例如,看看下面的脚本:

上面脚本的输出如下:

复数化和单数化标记
pluralize 和 singularize 方法可分别用于将单数形式单词转换为复数形式,反之亦然。

输出如下:

将形容词转换成比较级和最高级
你可以使用comparative和 superlative方法来检索一个形容词的比较级和最高级。例如,good的比较级是better,最高级是best。我们实际来看一下:

输出:

查找N-Gram模型
N-Grams是指一个句子中 “n”个单词的组合。例如,对于句子“He goes to hospital”,2-grams将是 (He goes), (goes to) 和 (to hospital)。N-Grams在文本分类和语言建模中起着至关重要的作用。
在Pattern库中,ngram方法用于查找一个文本字符串中的所有的n-grams。ngram方法的第一个参数是文本字符串。n-grams的数字被传递给方法的n参数。请看下面的例子:

输出:

查找Sentiments(情感)
Sentiment指的是对某件事的看法或感受。Pattern库提供了从文本字符串中查找sentiment的功能。
在Pattern库中,sentiment对象是用来发现文本的极性(积极或消极)及其主观性。
根据最常见的积极形容词(good, best, excellent等)和消极形容词(bad, awful, pathetic等),文本的情感得分在1到-1之间。这种情感得分也被称为极性。
除了情感得分,也会返回主观性。主观性值可以在0到1之间。主观性是对文本中所包含的个人观点和事实信息的量化。较高的主观性意味着文本包含的是个人观点而非事实信息。

运行上面的脚本,你应该会看到以下的输出:

"This is an excellent movie to watch. I really love it "这个句子的情感得分为0.75,这表明它是非常积极的。同样,0.8的主观性值表明该句子是用户的个人意见。
检查一个语句是否为事实
Pattern库中的modality函数可用于查找文本字符串中的确定度。modality函数返回一个介于-1到1之间的值。对于事实,modality函数会返回一个大于0.5的值。
这里是一个有关它的实际例子:
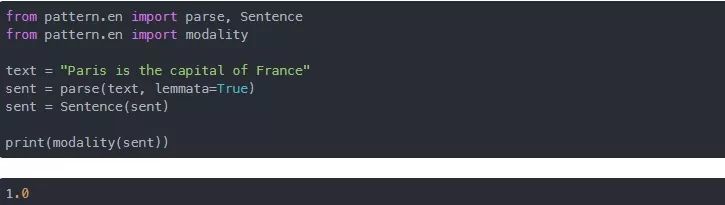
在上面的脚本中,我们首先导入了parse方法和Sentence类。在第二行,我们导入了modality函数。parse方法将文本作为输入并返回该文本的标记化形式,并将其传递给Sentence类的构造函数。modality方法接受Sentence类对象并返回该句子的模态。
由于文本字符串“Paris is the capital of France”是一个事实,所有,在输出中,你将看到值1。
同样,对于一个不确定的句子,modality方法返回的值在0.0左右。请看下面的脚本:
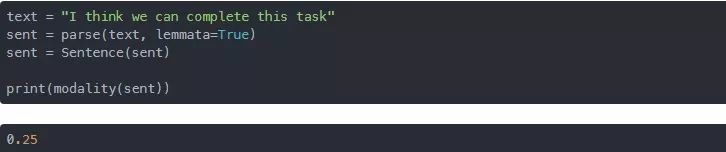
由于上面例子中的字符串不是很确定,所以上面字符串的模态为0.25。
拼写更正
suggest方法可用于查找一个单词拼写是否正确。如果一个单词拼写100%正确,suggest方法会返回1。否则,suggest方法会返回该单词的可能更正及其正确性概率。
请看下面的例子:

在上面的脚本中,我们有一个单词Whitle是拼写错误的。在输出中,你将看到这个单词的可能建议。

根据suggest方法,该单词是“While”的概率为0.64,是“White”的概率为0.29,等等。
现在我们来正确地拼写一个单词:

输出:

从输出中,您可以看到该单词拼写正确的几率为100%。
处理数字
Pattern库包含将文本字符串形式的数字转换成对应的数字的函数,反之亦然。要将文本表示转换为数字表示,可以使用number函数。类似地,要将数字转换回相应的文本表示形式,可以使用numerals函数。请看下面的脚本:

输出:

在输出中,您将看到122,这是文本“one hundred and twenty-two”的数字表示。类似地,您应该看到“two hundred and fifty-six point thirty-nine”,这是数字256.390的文本表示。
记住,对于numerals函数,我们必须提供我们想要四舍五入到的数字的整数值。
quantify函数用于获得列表中项目的字数估计,它提供了一个短语来引用组。如果一个列表有3到8个类似的项目,quantify函数将把它量化为“几个”。两个项目将被量化为一“对”。

在列表中,我们有三个apples,三个bananas和两个mangoes。这个列表的quantify函数的输出如下所示:

类似地,下面的例子演示了另一个字数估计。

输出:

用于数据挖掘的Pattern 库函数
在上一节中,我们查看了用于NLP的Pattern库中一些最常用的函数。在本节中,我们将看一下如何使用Pattern库执行各种数据挖掘任务。
Pattern库中的web模块可用于web挖掘任务。
访问Web页面
URL对象用于从网页中检索内容。它有几种方法可以用来打开一个网页、从一个网页上下载内容和阅读一个网页。
你可以直接使用download方法下载任何网页的HTML内容。下面的脚本下载了关于人工智能的Wikipedia文章的HTML源代码。

你也可以从网页上下载文件,例如,使用URL方法下载图片:

在上面的脚本中,我们首先使用URL方法与页面建立连接。接下来,我们在打开的页面上调用 extension方法,该方法会返回文件扩展名。文件扩展名会被附加在字符串“football”的末尾。调用open方法来读取此路径,最后,download()方法下载图像并将其写入默认执行路径。
查找文本中的 URL
你可以使用findurl方法从文本字符串中提取URL。举个例子:

在输出中,你将看到谷歌网站的URL,如下图所示:

对网页进行异步请求
web页面可能非常大,下载完整的页面内容可能需要相当长的时间,这可能会阻止用户在下载完整个页面之前对应用程序执行任何其他任务。但是,Pattern库的web模块包含一个asynchronous函数,它以并行的方式下载网页内容。asynchronous方法在后台运行,以便用户可以在下载网页的同时与应用程序进行交互。
让我们举一个非常简单的asynchronous方法的例子:
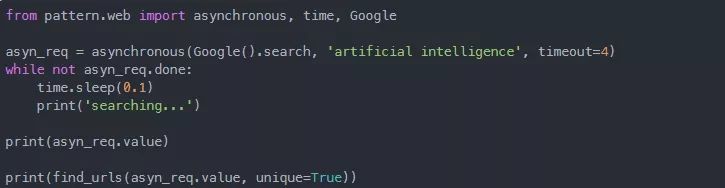
在上面的脚本中,我们检索了搜索查询“人工智能”的第1页的谷歌搜索结果,您可以看到,当页面下载时,我们并行地执行一个while循环。最后,使用asynchronous模块返回的对象的value属性打印查询后检索到的结果。接下来,我们从该搜索中提取URL,然后将其打印在屏幕上。
使用API获取搜索引擎结果
Pattern库中包含了SearchEngine类,它由一些类派生而来,这些类可用于连接并调用不同搜索引擎和网站的API,如谷歌、Bing、Facebook、Wikipedia、Twitter等。SearchEngine对象构造器接受三个参数:
SearchEngine类的search方法用于对特定的搜索查询向搜索引擎发出一个请求。search方法可接受以下参数:
继承了SearchEngine类及其search方法的搜索引擎类有: Google, Bing, Twitter, Facebook, Wikipedia, 和 Flickr。
搜索查询会返回每个项的对象。然后可以使用result对象检索关于搜索结果的信息。result对象的属性有url, title, text, language, author, date。
现在我们来看一个关于如何通过pattern库在谷歌上搜索某些内容的简单例子。请记住,要使这个例子工作,你必须使用你的谷歌API开发人员许可密钥。

在上面的脚本中,我们创建了一个Google类的对象。在Google的构造函数中,将您自己的许可证密钥传递给license参数。接下来,我们将字符串artificial intelligence传递给search方法。默认情况下,该方法会返回第一个页面的前10个结果,然后迭代这些结果,每个结果的url和文本将显示在屏幕上。
Bing搜索引擎的过程与此类似,你只需要将上面脚本中的Google替换为Bing类即可。
现在我们来在Twitter上搜索包含文本“人工智能”的最新的三条推文。执行以下脚本:
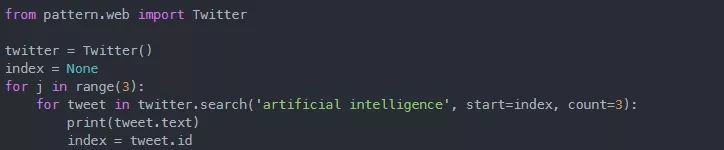
在上面的脚本中,我们首先从pattern.web模块中导入Twitter类。接下来,我们对Twitter类返回的tweets进行迭代,并在控制台上显示tweet的文本。运行上述脚本不需要任何许可证密钥。
将HTML 数据转换成纯文本
URL类的download方法会以HTML的形式返回数据。但是,如果你想对文本进行语义分析,例如,情感分类,那你就需要清洗过的没有HTML标记的数据。你可以使用plaintext方法清洗数据。该方法以download方法返回的HTML内容作为参数,并返回已清洗的文本。
看看下面的脚本:

在输出中,你会看到来自页面的清洗后的文本:
https://stackabuse.com/python-for-nlp-introduction-to-the-textblob-library/.
重要的一点是,如果您正在使用Python3,您将需要调用decode('utf-8')方法来将数据从字节转换为字符串格式。
解析 PDF 文档
Pattern库包含可用于解析PDF文档的PDF对象。PDF(便携式文档格式)是一个跨平台文件,它将图像、文本和字体包含在一个独立文档中。
我们来看看如何使用PDF对象来解析一个PDF文档:

在脚本中,我们使用download函数下载了一个文档。接下来,我们将下载的HTML文档传递给PDF类,并最终将其打印到控制台。
清理缓存
默认情况下,SearchEngine.search()和URL.download()等方法返回的结果被存储在本地缓存中。要在下载完HTML文档后清除缓存,我们可以使用cache类的clear方法,如下所示:

结论
Pattern库是Python中最有用的自然语言处理库之一。虽然它不像spaCy或NLTK那么有名,但是它包含了查找最高级和比较级、事实和意见检测等功能,这些功能使它区别于其他NLP库。
在本文中,我们研究了Pattern库在自然语言处理、数据挖掘和web抓取方面的应用。我们了解了如何使用Pattern库执行基本的NLP任务,如标记化、词形还原和情感分析。最后,我们还了解了如何使用Pattern库进行搜索引擎查询、爬取在线tweet和清理HTML文档。
英文原文:https://stackabuse.com/python-for-nlp-introduction-to-the-pattern-library/
译者:天天向上






