
最近,我在写一个算法来解决一个编码难题,这个难题涉及到在一个笛卡尔平面上找到一个与其他所有点的距离最小的点。在Python中,两个点之间的距离函数可以表示为math.sqrt(dx ** 2 + dy ** 2)。但是,这个函数中的每一项都有不同的表达方法:dx ** 2、 math.pow(dx, 2)和 dx * dx。有趣的是,它们的运行结果各不相同,我想知道它们是如何以及为什么会是这样的。
计时测试
Python提供了一个名为 timeit 的模块来测试性能,这使得测试这些表达式的运行时间相当简单。将 x 设置为 2,我们就可以对上面的三个选项进行计时测试:

表达式反汇编
Python还提供了一个名为 dis 的模型,它可以对代码进行反汇编,这样我们就可以看到每一个表达式在底层做些什么,这有助于我们理解其性能差异。
乘法
使用 dis.dis(lambda x: x * x),我们可以看到以下代码被执行:

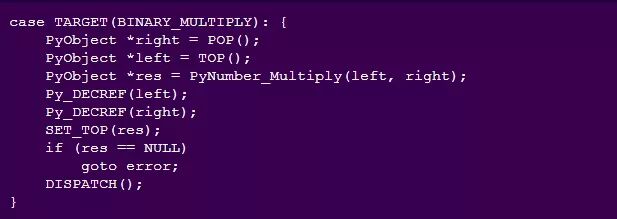
该程序将 x 载入两次,执行 BINARY_MULTIPLY 操作,并且返回得到的值。
math.pow()
使用 dis.dis(lambda x: math.pow(x, 2)), 我们可以看到以下代码被执行:
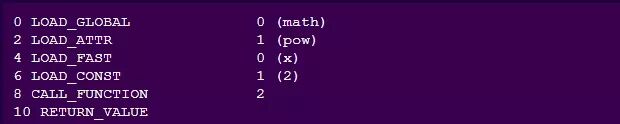
math 模块从全局空间开始加载变量,然后加载pow属性。接下来,加载两个参数并调用pow函数,该函数会返回计算值。
求幂
使用dis.dis(lambda x: x ** 2), 我们可以看到以下代码被执行:

该程序先加载 x, 再加载2,然后运行 BINARY_POWER 并返回计算结果。.
BINARY_MULTIPLY 与 BINARY_POWER
使用math.pow()函数作为一个比较点,乘法和求幂的字节码的只有一部分有所不同: 调用BINARY_MULTIPLY 与调用BINARY_POWER。
BINARY_MULTIPLY
这个函数位于这里(https://github.com/Python/cPython/blob/b509d52083e156f97d6bd36f2f894a052e960f03/Objects/longobject.c#L3645-L3665 )的Python源代码中。它做了一些有趣的事情:
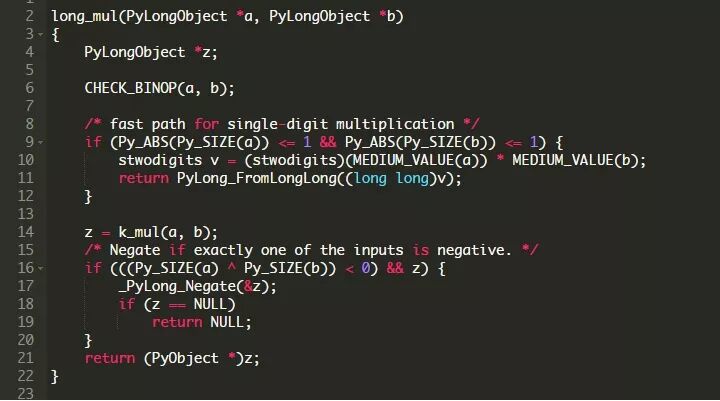
对于较小的数,这个函数使用二进制乘法。对于较大的值,该函数使用Karatsuba乘法,这是一种针对较大数字的快速乘法算法。
我们可以看到这个函数是如何在 ceval.c中被调用的:
BINARY_POWER
这个函数位于这里(https://github.com/Python/cPython/blob/b509d52083e156f97d6bd36f2f894a052e960f03/Objects/longobject.c#L4118-L4305 )的Python源代码中。它还做了一些有趣的事情:
源代码太长,所以无法完全包括进来,这在一定程度上解释了这种不利的性能。以下是一些有趣的代码片段:
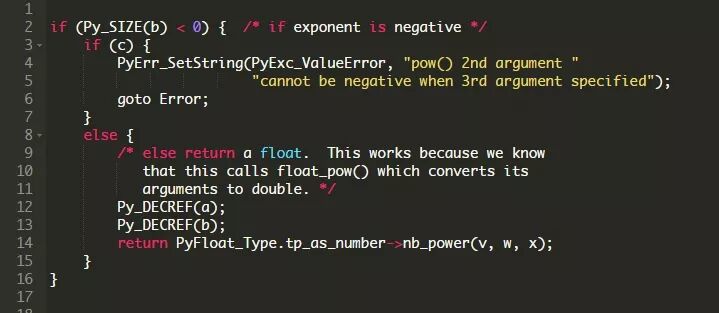
在创建了一些指针之后,该函数会检查power给出的数是浮点数还是负数,在这里它可能会出错,也可能会调用另一个函数来处理求幂操作。
如果两种情况都不是,该函数将检查第三个参数,根据ceval.c的代码来看这个参数通常是None:
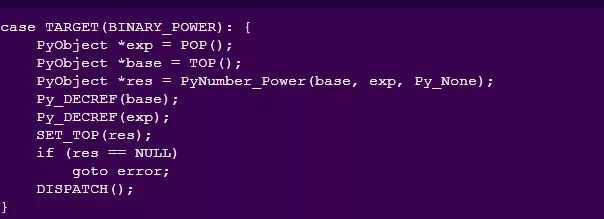
最后,该函数定义了两个例程: REDUCE用于模降,MULT用于乘法和减法。乘法函数对两个值使用了long_mul函数,这与BINARY_MULTIPLY中使用的函数相同。
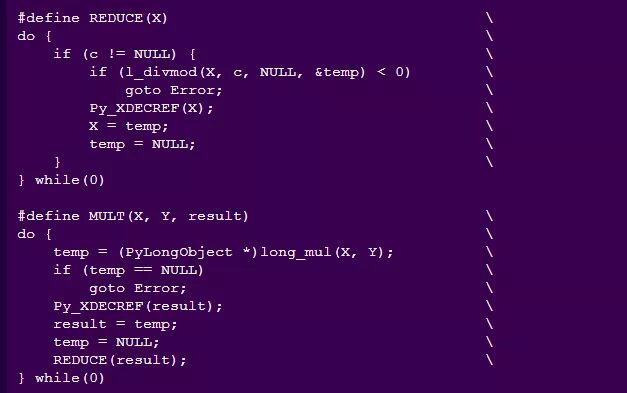
之后,该函数使用《应用密码学手册》第14.6章中定义的从左到右k次求幂方法:

图表化性能差异
我们可以使用上面的timeit库分析在不同值时的代码,并查看性能如何随时间变化。
生成函数
为了测试不同power值下的性能,我们需要生成一些函数。
math.pow()和取幂
由于这两个函数都已经在Python源代码中,所以我们需要做的就是定义一个求幂函数,并且我们可以在一个timeit调用中来调用它。“

连乘
由于每一次power发生变化时,这个函数也会发生变化。所以每一次函数中的 base 发生变化时,我们都需要生成一个新的乘法函数。为此,我们可以生成一个像 x*x*x 这样的字符串,并对它调用eval()来返回一个函数:

这样,我们就可以像这样来创建一个 multiply 函数:

如果我们调用 generate_mult_func(4), multiply函数将会是一个类似于这样的匿名函数:

查找交叉点
使用这里(https://repl.it/@reagentx/Find-Crossover )贴出的代码,我们可以决定 multiply 在什么情况下会变得比 exponent 效率更低。
我们先从这些值开始:

我们持续循环,直到该函数执行100,000次 multiply 迭代的时间比执行100,000次 exponent 迭代的时间慢。首先,这里是计时时间,使用math.pow()作为一个比较点:

当我们在repl.it上运行时, Python在1.2s内找到了交叉点:

因此,在我们的表达式达到2^14时,连乘是运行最快的,而在到达2^15时, 求幂变成最快的。
图表化性能。
使用Pandas, 我们可以跟踪每一次求幂的时间:
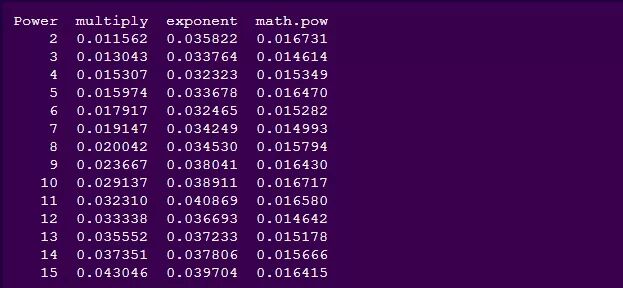
使用下面的代码来生成一条折线图是非常简单的:

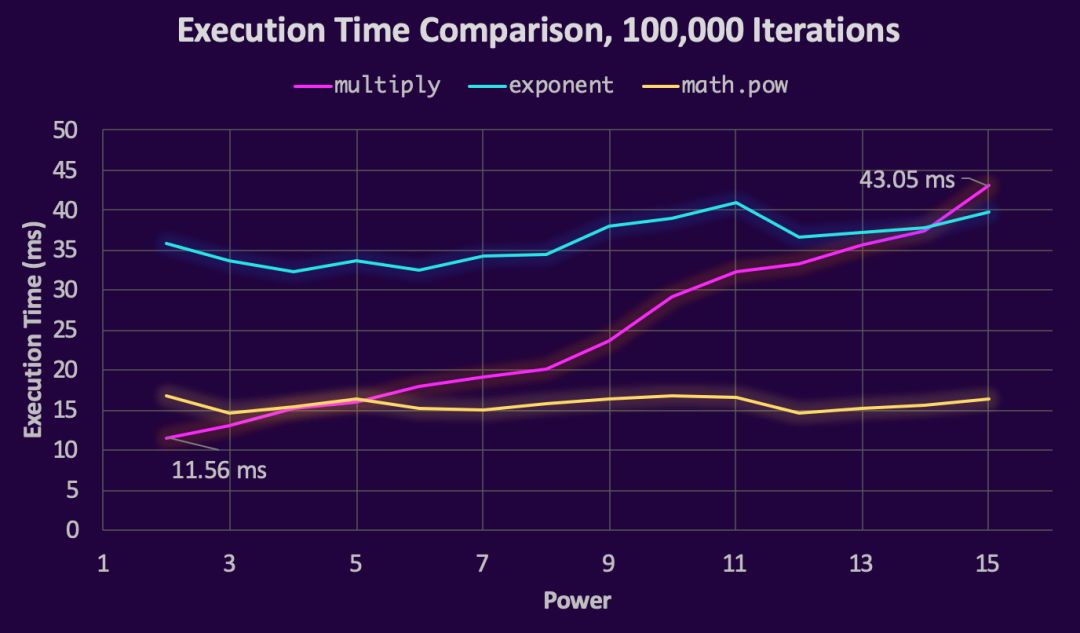
有趣的是, math.pow() 和 exponent 的大多数操作都是以相同的速率来执行的 ,而我们的multiply函数差异很大。不出所料,乘法链越长,执行所需的时间就越长。
更多的性能测试
虽然交叉很有趣,但这并没有显示幂大于15时的情况。幂上升到1000,我们得到以下趋势:
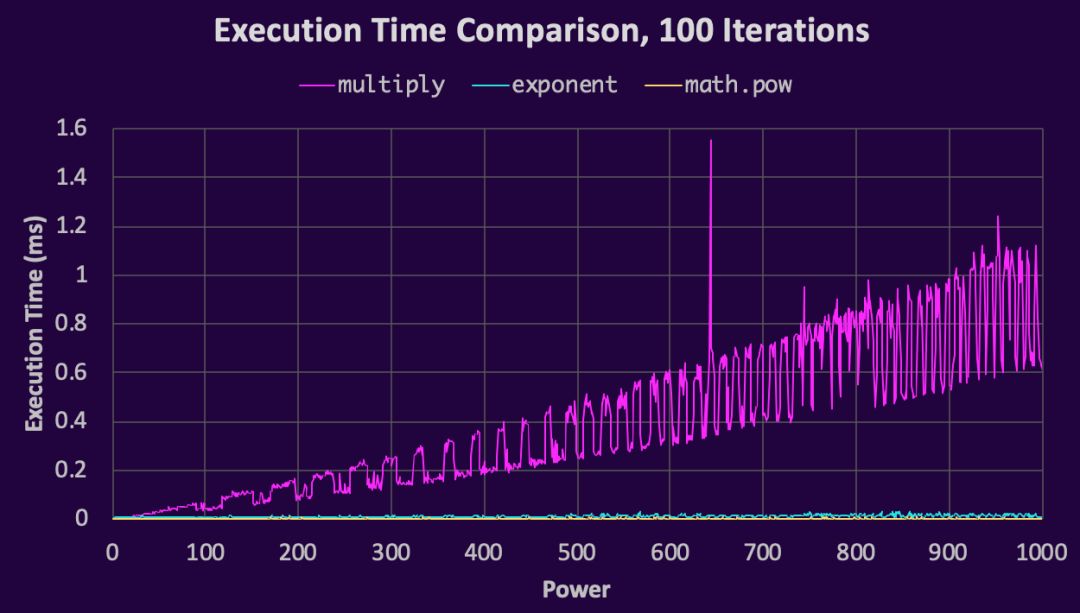
当我们放大以使math.pow()和exponent更明显时,我们看到它们有相同的性能趋势并仍在继续:
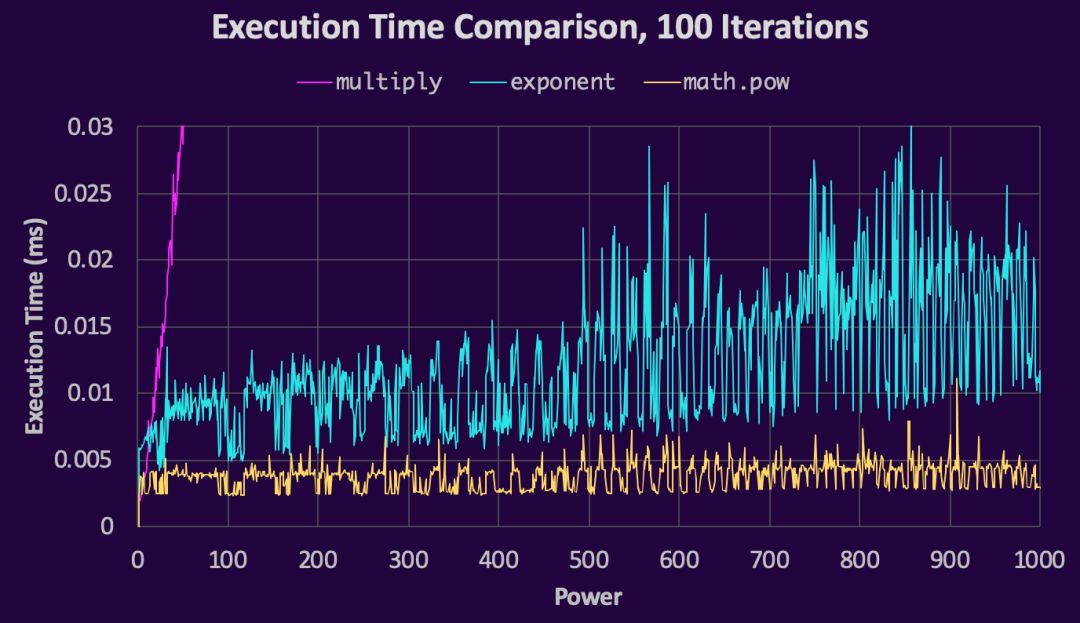
虽然使用 ** 时时间会逐渐增加,但是math.pow()通常是以相同的速度执行。
结论
当编写使用小指数的算法时,这里证明为幂小于15时,进行连乘比使用**指数运算符更快。此外,在幂大于5的情况下,math.pow()比连乘更有效,而且它总是比**操作符更有效,所以没有任何理由去使用**。
此外,在JavaScript中也是如此。感谢@juliancoleman在这里(https://jsperf.com/mult-vs-expo 0做的这个比较!
英文原文:https://chrissardegna.com/blog/posts/python-expontentiation-performance/
译者:野生大熊猫






