
原标题 | Must know Information Theory concepts in Deep Learning (AI)
作者 | Abhishek Parbhakar
译者 | 敬爱的勇哥(算法工程师)
注:本文的相关链接请访问文末【阅读原文】

信息论是一个重要的领域,它对深度学习和人工智能作出了重大贡献,但很多人对它却并不了解。信息论可以看作是微积分、概率论和统计学这些深度学习基本组成部分的复杂融合。人工智能中的很多概念来自信息论或相关领域:

克劳德香农,信息时代之父
在20世纪初期,科学家和工程师们努力解决这样的问题:“如何量化信息?有没有一种分析方法或数学方法可以告诉我们信息的内容?”
例如,考虑以下两句话:
第二句话给了我们更多的信息,因为它还告诉布鲁诺除了是“狗”之外还是“大的”和“棕色的”。我们如何量化两个句子之间的差异?我们能否有一个数学测量方法告诉我们第二句话与第一句话相比多了多少信息?
科学家们一直在努力解决这些问题。语义,域和数据形式只会增加问题的复杂性。数学家和工程师克劳德·香农提出了“熵”的概念,它永远改变了我们的世界,这标志着数字信息时代的开始。

克劳德·香农在1948年引入了“bit”这个词
克劳德·香农提出“数据的语义方面是无关紧要的”,数据的性质和含义在信息内容方面并不重要。相反,他根据概率分布和"不确定性"来量化信息。香农还引入了“bit”这个词,这一革命性的想法不仅奠定了信息论的基础,而且为人工智能等领域的进步开辟了新的途径。
下面将讨论深度学习和数据科学中四种流行的,广泛使用的和必须已知的信息论概念:
也可以称为信息熵或香农熵。

熵是实验中随机性或不确定性的度量
熵给出了实验中不确定性的度量。让我们考虑两个实验:
如果我们比较两个实验,与实验1相比,实验2更容易预测结果。因此,我们可以说实验1本质上比实验2更不确定或不可预测。实验中的这种不确定性是使用熵度量的。
因此,如果实验中存在更多固有的不确定性,那么它的熵更大。或者说实验越不可预测熵越大。实验的概率分布用于计算熵。
一个完全可预测的确定性实验,即投掷P(H)= 1的硬币的熵为零。一个完全随机的实验,比如滚动无偏骰子,是最不可预测的,具有最大的不确定性,在这些实验中熵最大。

抛掷一枚无偏硬币的实验比抛掷有偏硬币具有更多的熵
另一种观察熵的方法是我们观察随机实验结果时获得的平均信息。将实验结果获得的信息定义为该结果发生概率的函数。结果越罕见,从观察中获得的信息就越多。
例如,在确定性实验中,我们总是知道结果,因此通过观察结果没有获得新信息,因此熵为零。
数学定义
对于离散随机变量X,可能的结果(状态)x_1,...,x_n,熵(以位为单位)定义为:
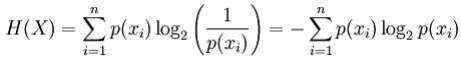
其中p(x_i)是X的第i个结果的概率。
应用
交叉熵用于比较两个概率分布。它告诉我们两个分布有多相似。
数学定义
在相同的结果集上定义的两个概率分布p和q之间的交叉熵由下式给出:
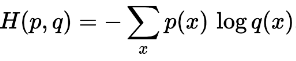
应用
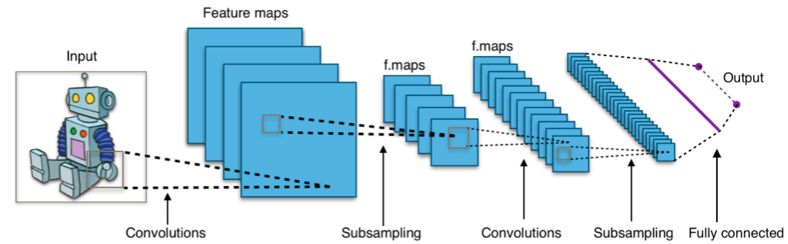
基于卷积神经网络的分类器通常使用softmax层作为最后一层,并使用交叉熵损失函数进行训练
交互信息是两种概率分布或随机变量之间相互依赖性的度量。它告诉我们另一个变量有多少关于该变量的信息。
交互信息获取随机变量之间的依赖性,比一般的相关系数更具广义性,后者只表现线性关系。
数学定义
两个离散随机变量X和Y的交互信息定义为:
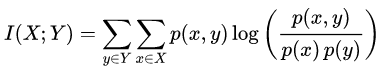
其中p(x,y)是X和Y的联合概率分布,p(x)和p(y)分别是X和Y的边缘概率分布。
应用
在贝叶斯网络中,可以使用交互信息来确定变量之间的关系结构
也称为相对熵。

KL散度用于比较两个概率分布
KL散度是另一种表示两个概率分布之间相似性的方法。它衡量一个分布与另一个分布的差异。
假设我们有一些数据,它的真实分布是P。但是我们不知道P,所以我们选择一个新的分布Q来近似这个数据。由于Q只是一个近似值,它无法像P那样准确地逼近数据,会造成一些信息的丢失。这个信息损失由KL散度给出。
P和Q之间的KL散度告诉我们,当我们试图用P和Q来近似数据时,我们损失了多少信息。
数学定义
一个概率分布Q与另一个概率分布P的KL散度定义为:
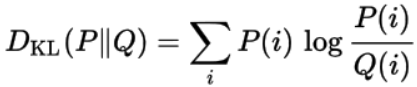
应用
KL散度通常用于无监督机器学习技术中的变分自编码器。
信息论最初是由数学家和电气工程师克劳德·香农,在1948年的开创性论文“通信的数学理论”中提出的。
注意:随机变量和AI,机器学习,深度学习,数据科学等专业术语已被广泛使用,但在不同的领域中会有不同的物理含义。
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1764
本篇编辑 | 王立鱼
原文地址:
https://towardsdatascience.com/must-know-information-theory-concepts-in-deep-learning-ai-e54a5da9769d
6月21日的赠书活动,名单已经安排好了,恭喜以下朋友获奖:
AI研习社:
@BackUp! @华 @天道酬勤
@Farmer @大白兔巧克力
AI科技评论:
@ . @远航 @☆(此处为Emoji)
注:符合条件的留言仅有三条,剩余资格调至AI研习社发放。
雷锋网订阅号:
@一江 @BaldStrong
@田园·D·司机 @贰拾雨
恭喜以上朋友,请在2019年7月3日23:59前在留言区回复指定内容,稍后会有通知告知填写信息。注意,超过有效回复时限,获奖资格将失效。
 点击阅读原文,查看本文更多内容
点击阅读原文,查看本文更多内容









